AI Tips連載の4本目の記事となります。
はじめに
こんにちは。Strategic AI Group (SAIG) の藤井です。
GENIAC第2期事業にて採択された「日本語とソフトウェア開発に特化した基盤モデルの構築」プロジェクトについて、開発の過程で得られた知見や学び、今後の課題を共有します。
みなさまご存じの通り、生成AI技術を取り巻く状況は日進月歩であり、殊にコーディングをはじめとしたソフトウェア開発ドメインでは、(人間を含む) 環境のフィードバックを受けながら自律的に問題解決を行うエージェントなど日夜新たなツールが登場しています。その意味で「ソフトウェア開発×基盤モデル」は血の海であり、どのような方針・立ち位置を取るかという部分に非常に頭を悩ませました。
本稿は前後編の2本立てで、前編は開発したモデルの概要や開発の流れ、プロジェクト進行における反省点について、後編ではモデルの技術的特徴に関するより込み入った内容や、今後明らかにすべきオープンクエスチョンなど次のチャレンジャーに向けたメッセージを著したいと思います。
本プロジェクトで開発したモデル Llama-3.1-Future-Code-Ja-8B はHugging Faceにて公開しています。
開発のベースとした Llama-3.1 モデルに起因するもの以外では、利用に際する条件など設けておりませんので、ぜひ幅広く試していただけると開発者冥利に尽きます。
GENIACプロジェクトについて
GENIAC (Generative AI Accelerator Challenge) は、経済産業省、および国立研究開発法人新エネルギー・産業技術総合開発機構 (NEDO) が実施する日本国内の生成AI開発力強化プロジェクトです。
これまでに2024年2月に開始した第1期、同年10月に開始した第2期の2サイクルが完了し、フューチャーは第2期公募において「日本語とソフトウェア開発に特化した基盤モデルの構築」のテーマで採択されました。
開発の背景
これまで、日本語に強みを持つとされたモデルでは、コーディングやそれを包含するソフトウェア開発のタスクにあまりスポットが当てられてきませんでした。
しかしながら、日本語で記載した仕様に沿って関数を設計するなど、国内では日本語をコンピュータと人間の橋渡しに使いたいというニーズは根強いと考えられます。また、コーディングに特化した大規模言語モデル (Code LLM) の文脈では、従来コードの途中までが与えられた状態での後方補完 (code completion) タスクが活発に取り組まれてきましたが、ソフトウェア開発においてはコードを理解して自然言語を生成するようなタスク、例えばコードレビューなども対象となり得ます。
そのようなタスクにおいて、自然な日本語を扱えることはメリットであり「日本語」と「ソフトウェア開発」の双方において強味を持つモデルの構想に至りました。
開発の流れ
前述のとおり、本プロジェクトは2024年10月に開始し、翌年4月までの6か月間をメインに実施しました。
大規模言語モデル (LLM) の学習は主に、① 事前学習 ② 教師ありファインチューニング ③ 選好最適化 の3つの段階に分かれます。
なお、今回はスクラッチ (ランダムな初期値) からの学習ではなく、Meta社の Llama-3.1 8B モデルの重みをベースに学習を行ったため、ステップ①は「継続」事前学習 (continual pretraining) となります。
今回のモデル開発では、結果的に2/3以上の期間を継続事前学習、その後各1ヶ月程度で後続のフェーズを検討するというスケジュールとなりました。
プロジェクト体制
GENIACでは週次・月次での事務局への進捗報告をはじめ、対社内外のやり取りが多く発生します。今回のプロジェクトでは社内事務局を設置することで、開発者がモデル開発に専念できる体制を整えていただけたのが良かったと感じます。しかしながら、開発側も決して潤沢なリソースがある状況ではありませんでした。特に、継続事前学習パートでは手を動かせる定常メンバが一人という状況にあり、打てる試行錯誤の数としても限られてしまったと感じます。
GENIACコミュニティでは採択事業者向けのイベントがしばしば企画されるのですが、第2期ではMeta社やAnthropic社など生成AI領域をリードする企業を訪問する米国視察イベントもありました。参加された方から伺ったところでは、そのような企業は数百人~数千人という規模でモデル開発を行っているようです。各組織の限られたメンバーに知見が閉じているような状況ではいけない、というのも、今回開発したモデルの許容的ライセンスでの公開、および本記事の執筆に至った経緯です。
各フェーズの概要
各フェーズの取り組みをダイジェストにてご紹介します。
より詳しい内容については、ぜひ後編をご覧ください。
フェーズ1 : 継続事前学習
ウェブ上のソースコード、日英テキストのデータクリーニングに注力し、ソースコード約205Bトークン、日英テキスト約86Bトークンの混合データで継続事前学習を行いました。
LLMの学習でしばしば見られるloss spikeは発生せず、以下のように安定した学習曲線で推移しました。
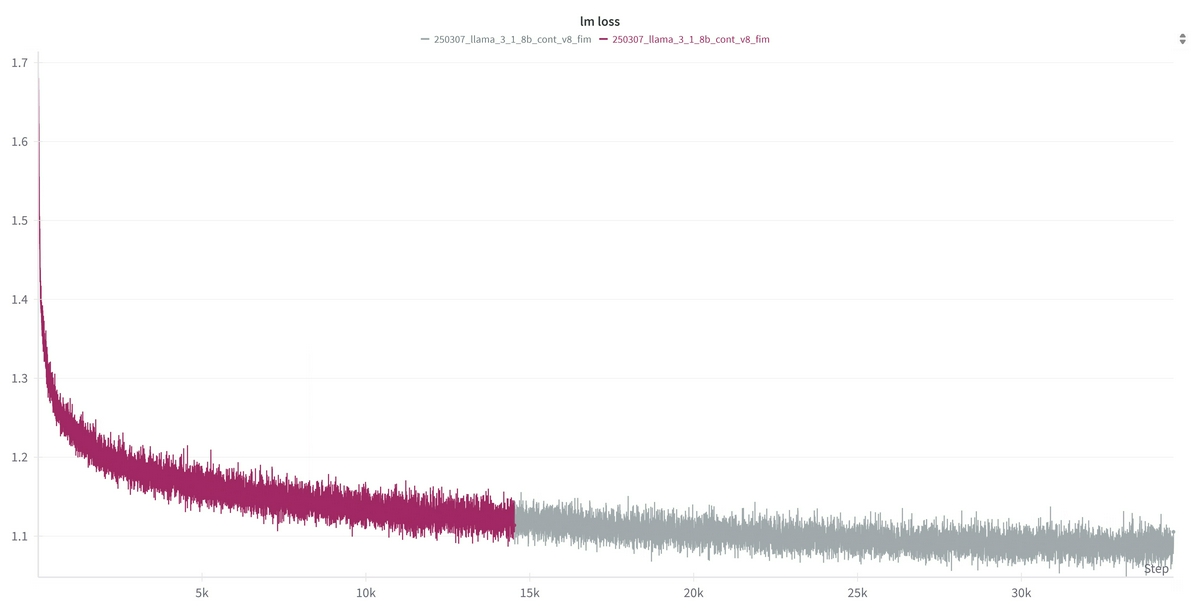
データクリーニングでは非常に多くの困難がありましたが、GitHub由来のソースコードのみでも、堅実なフィルタリングルールの設計でベースモデルから一定のコード補完精度向上が見られるというのは学びでした。
フィルタの実装には、tree-sitter-language-pack, lizard といったOSSの静的解析ツールも積極的に採用したのですが、前者が内部で依存するparser (構文解析器) が数百万件に一件レベルで踏むバグで退勤前に仕込んだ処理が翌朝コケているのには参りました。
また、今回のモデル学習では、通常のNext Token Predictionに加えて、Fill-in-the-Middle (FIM) と呼ばれる学習手法を採用しました。
FIMとは「途中補完」を意味しますが、これはIDE上でカーソルの前後「双方」の文脈を考慮してカーソルの後ろ側を補完するかのように、前後の文脈から中間部分を予測するタスクとなります。
言語モデルのデファクトである Transformer のアーキテクチャには大きく、Encoder-Decoder型、Encoder型、Decoder型の3つのパターンが存在しますが、GPTやLlamaなどのモデルはDecoder型のアーキテクチャを取っており、これはそれ以前の文脈から次に続くトークン (≒ 言語モデルにとっての単語のようなもの) を予測するもの (Causal LM) です。
後方の文脈を考慮する方法として、補完箇所に [FILL_ME] 等を配置し、プロンプトで例示して穴埋めタスクとして解くというアプローチも考えられますが、今回「途中補完」は明確なユースケースのひとつとして想定されるため、明示的にサポートすることとしました。
フェーズ2 : 教師ありファインチューニング (SFT)
今回のモデル開発では、基本的な指示追従・汎用的なタスク遂行能力の獲得にはモデルマージを活用し、ソフトウェア開発関連タスクに特化したinstruction-tuningデータセットのみを用いて学習を行いました。
モデルマージ手法にも多種多様なものが提案されていますが、今回は Task Arithmetic と呼ばれるシンプルな手法を採用しました。この手法では、あるモデルと、そのモデルを何らかのタスクでファインチューニングしたモデルの2つのモデルに対して、ファインチューニング前後のパラメータの差分 (タスクベクトル) を「そのタスクを解く能力」と考えます。
そして、任意のモデルにこの「タスクベクトル」を足し合わせることで、後天的に (再学習することなく) 当該タスクを解く能力を身につけることを期待します。
今回は、継続事前学習後のモデルに「Llama 3.1 8B と Llama 3.1 8B Instruct の差分」を足し合わせることで、一定の指示追従能力が獲得されることを確認しました。
厳密にはマージ元 / 先のモデルは同一のアーキテクチャである必要があり、「任意」のモデル間でTask Arithmeticを適用することはできません。
また、一般には同一のベースモデル (今回の例では Llama 3.1 8B) からファインチューニングされたモデル間で上手く働くと考えられています。
instruction-tuningデータの作成には Magpie と呼ばれる手法を用いています。
Magpieについて簡単に説明すると、本来LLMの推論では “システムプロンプト” と “ユーザプロンプト” に続いて【アシスタントここから生成】 (※イメージ) のようなトリガーが与えられ、システムはAIアシスタントとしての応答を生成しますが、これを “システムプロンプト” に続けて【ユーザここから生成】と渡すことでユーザが聞きそうな指示文をモデル自身から引き出してしまおう、という考え方になります。
テクニカルな話をすれば、通常、SFTでは最後のアシスタント応答部分以外にはlossを流さないため、モデルはユーザ指示部分のNext Token Predictionを学習しておらず、Magpieが成立する理由は謎なのですが、シードデータを要することなく「無」から大量に、かつ定性的にも妥当な学習データを生成できる手法として今回の採用に至りました。
Magpieのデータ作成は比較的スケールし、Llama 3.3 70B Instruct で1万件のinstructionを作成後、各4件のresponseを生成するケースでは10 (H100) GPU時間以内で実現できます。 (執筆時点でAWS東京リージョンにおける p5.48xlarge = H100×8 のオンデマンド単価は$68.80ですので、100ドル未満で1万件のデータを生成できるということになります)最終的に、今回の取り組みでは約1,200万件のinstruction-tuningデータを用いて学習を行いました。
なお、マージ直後のモデルについて、対話形式の入力では問題なくターンを終えることができましたが、FIM形式の入力では途中補完として妥当な出力を始めた後、必要な内容の出力が終わっても生成を止められないという現象が見られました。今回のモデル開発では、SFTの学習データにFIM形式のデータを少量混ぜることで対話能力とFIMを両立させることができました。
この現象に関する説明として、Llama 3.1では、事前学習時は <|end_of_text|>、SFT時は <|eot_id|> と異なるトークンを「区切り」に用いることから、FIMにおいて <|end_of_text|> で終わることをモデルが忘れてしまったものと考えています。
フェーズ3 : 選好最適化
前述のMagpieで作成したinstruction-tuningデータセットの一部を用いて DPO (直接選好最適化) を行いました。
DPOではある入力 prompt に対して、良い出力 chosen と悪い出力 rejected のペアを用いて、chosen を出力しやすく、 rejected を出力しにくくするように重みの更新を行います。今回は作成したinstruction1件に対して4件のresponseを生成しましたが、各responseに Llama-3.1-Nemotron-70B-Reward-HF で報酬 (良さのスコア) を付与し、最もスコアの高いものを chosen、最もスコアの低いものを rejected として学習を行いました。
当初、DPOにはSFT用のデータと重複しないよう100万件のinstructionを取り分けて進めていましたが、コード補完ベンチマークのスコアをモニタリングした結果、学習初期にピークを迎えた後にスコアが低下する傾向が認められたため、最終的には10万件にサンプリングして学習を行うこととしました。
全量で1000万件超のinstruction × 4件のresponseについて、そのすべてを大規模な報酬モデルで評価することは時間的制約から困難であったため、DPO用のサブセットに対してのみ70Bの報酬モデルで評価を行いました。
SFT用のサブセットでは軽量な ArmoRM-Llama3-8B-v0.1 (8B) で評価を行い、最もスコアの高かった1つを正解として学習を行っています。
モデルの評価
ここでは、開発したモデルについて、いくつか特徴的な評価結果に触れ、そこから考えられる強み・可能性について考察したいと思います。
評価結果の完全な表は Hugging Faceのモデルページ をご参照ください。
以下は、日本語タスク指示文を含むコード補完ベンチマークの評価スコアです。
表中のスコアは pass@1 という評価指標によるもので、「1度の生成で単体テストを通過する “機能的に正しい” コードを生成できる割合の期待値」です。この表の結果から、主要なプログラミング言語において、開発したモデルのコード補完性能は学習元の Llama-3.1-8B-Instruct を大きく上回り、同規模のオープンソースモデルの中では高い水準にあることが分かります。
しかしながら、ドメイン特化モデルである Qwen2.5-Coder との比較では劣後しており、コーディングタスクにおいて、当該モデルが非常に強力であることを改めて実感しました。
| モデル | Python | C++ | C# | Java | JavaScript |
|---|---|---|---|---|---|
| Llama-3.1-Future-Code-Ja-8B | 0.6335 | 0.5267 | 0.3633 | 0.4696 | 0.5528 |
| Llama-3.1-8B-Instruct | 0.5061 | 0.4391 | 0.2835 | 0.3753 | 0.4640 |
| Llama-3.1-Swallow-8B-Instruct-v0.3 | 0.4213 | 0.3329 | 0.2456 | 0.3468 | 0.3112 |
| Qwen2.5-7B-Instruct | 0.6018 | 0.5106 | 0.3601 | 0.5044 | 0.5416 |
| Qwen2.5-Coder-7B-Instruct | 0.6695 | 0.6379 | 0.4601 | 0.5468 | 0.6696 |
| Qwen3-8B | 0.6256 | 0.5683 | 0.3709 | 0.4778 | 0.5814 |
| gemma-2-9b-it | 0.5549 | 0.4590 | 0.3608 | 0.4601 | 0.2863 |
ベンチマークの一部 (JMultiPL-E) はフューチャーと東北大学の共同研究で作成されたものです。
代わって、以下は日本語を生成するタスクの評価スコアとなります。
ここで「日本語を生成する」とは、”A”, “B”, … , “ポジティブ”, “ネガティブ” のようなラベルではなくフリーフォームでの生成が求められるものと考えます。
表中には質問応答 (NIILC)、要約 (XL-Sum)、翻訳 (WMT)と性質の異なる3つのタスクのスコアを記載しました。
各タスクの評価指標については割愛しますが、いずれも「高いほど良い」指標であり、これらのタスクについてもまた、開発したモデルは学習元のモデルと比較して高い性能を達成していることがわかります。また、ここで特筆すべき点としてQwen系のモデルのパフォーマンスが相対的に低く留まっているという点が挙げられます。
これらの結果を総括すると、今回開発したモデルは 高度なコード理解と日本語の生成の双方が求められるようなタスク 、すなわちコードレビューや仕様書の逆生成において光る可能性があるのではないかと考えています。
| モデル | NIILC | XL-SUM | WMT20 en-ja |
|---|---|---|---|
| Llama-3.1-Future-Code-Ja-8B | 0.5118 | 0.1779 | 0.2624 |
| Llama-3.1-8B-Instruct | 0.4050 | 0.1486 | 0.2195 |
| Llama-3.1-Swallow-8B-Instruct-v0.3 | 0.5805 | 0.1920 | 0.2818 |
| Qwen2.5-7B-Instruct | 0.3998 | 0.1690 | 0.2091 |
| Qwen2.5-Coder-7B-Instruct | 0.3045 | 0.1533 | 0.1816 |
| Qwen3-8B | 0.4197 | 0.1882 | 0.2450 |
| gemma-2-9b-it | 0.5306 | 0.0873 | 0.2305 |
プロジェクト進行における反省点
試行錯誤の回数を増やすために
今回、モデルの学習には Megatron-LM を用いましたが、評価のためにはチェックポイントをHuggingface Transformersで扱える形式に変換 → 評価スクリプトを実行という手順を踏む必要がありました。
Megatronのチェックポイントはインスタンスに備え付けのNVMeストレージに一時保存後、自動的にs3にアップロードされるよう設定を組んでいたのですが、変換・評価については自動化の構成検討まで手が回らず期間を通して手動実行することとなってしまいました。毎回の作業はさほど大きくはないのですが、何度も発生することによるチリツモの影響、評価スコアが早く見えることによる判断早期化への期待から、腰を据えて学習に取り掛かる前に自動評価を整備すべきだったと感じます。
より小規模なモデルを用いる、学習途中で打ち切って判断を行うというのも魅力的なオプションに見えますが、個人的にはあまりおすすめしません。
というのも、学習初期は低空飛行であっても、最後まで伸びてこないかといえば必ずしもそうとは限りませんでした。小規模モデルや学習初期の観測だけでも、あるデータやハイパーパラメータが明確に「良い」ということは言えるかもしれません。しかしながら、それらが「良くない」、芽が出ない設定であるということは本番と同等の設定で、できるだけ最後まで学習して判断すべきだと感じました。そのためにも、繰り返し発生する定型作業の省力化は特に意識しておきたいポイントです。
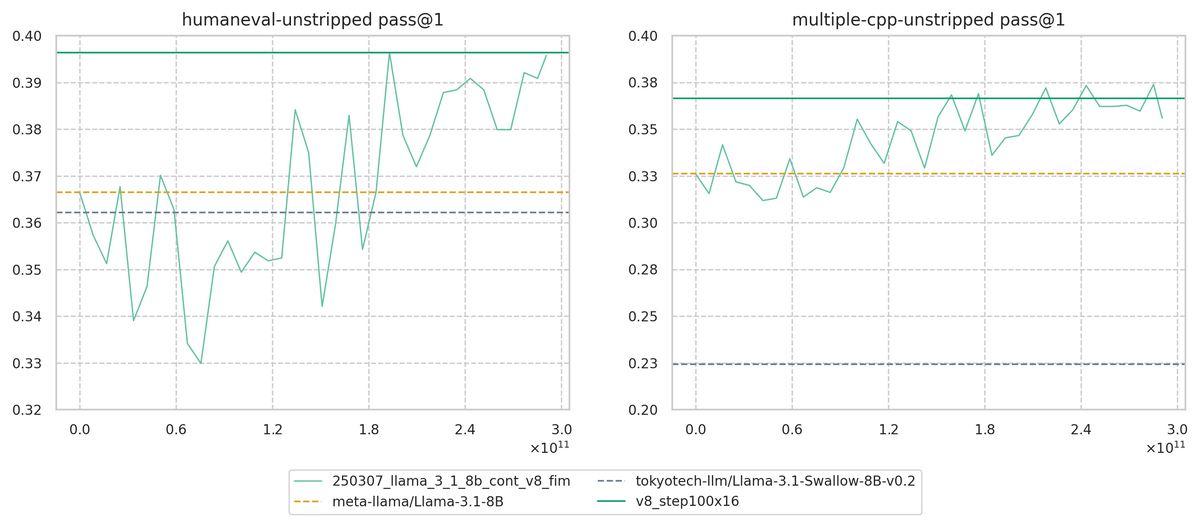
↓ ベースモデル学習時の評価曲線
学習序盤ではベースライン (黄破線) を下回っている
モデルに「色」を持たせるために
今回の開発において頭を悩ませた点のひとつが 「基盤モデルに何を求めるか」 です。
ここまで読んでいただいた方は薄々お気づきかと思われますが、今回のモデルが「これまでのモデルに出来なかった新たな領域 (タスク) 」に強みを持つかといえばそれはNoです。
先述の通り、ソフトウェア開発においてコーディングタスクは氷山の一角に過ぎず、Code LLMの切り込む余地はまだまだ残されているはずです。しかしながら、レビュータスクひとつを例にとっても、基盤モデルが持っていて嬉しい特徴とは何か、というのは突然ひらめくものではありませんでした。もちろん、社内で日々行われるレビューの情報をin-outに学習すれば、社内で使う分にはそれらしいレビューを生成することはできるかもしれません。
一方で、レビューの方法、仕様書の書き方などは、全世界的に標準が定まっているものではなく、それらに対するある一つの「方言」である社内 (組織内) 標準はファインチューニングで学ぶべき特徴に思われます。そのため、今回は「日本語」や「ソフトウェア開発」の領域でこれまでデファクトとして評価されてきたベンチマークを評価指標に定めて開発を推し進めていくこととなりました。
しかし、このようなタスクを想定した時、基盤モデルにできることはないのか、といえばこれもNoであると考えます。目下モデル開発の終了を受けて、今回のモデルを含めた複数のLLMを社内のコードレビュー補助に使えないかという実応用の検討が進んでいます。その過程で実際にどのような使い方が想定されるのかを見れば、例えば「指摘に該当する行番号を指摘内容と合わせて出力したいのだな」といったニーズをくみ取ることができ、パッチファイルのようなデータを重く学習するなど一定の工夫は取れたと思われます。石橋を叩いて渡る慎重さも必要ですが、殊にLLM時代においては、 積極的なアルファ・ベータテストとFBを回していくべきだった と考えます。
おわりに
今回は「日本語とソフトウェア開発に特化した基盤モデル」Llama-3.1-Future-Code-Ja-8B の開発について、その概観をお伝えしました。
個人としても、組織としても初めての基盤モデル開発プロジェクトであり、振り返ってみると反省すべき点も多かったと感じます。
しかし、こうして書き起こしてみると、どうすればより価値のあるものを作れるか、半年間1つのモデルと向き合うことで得られた学びも多々あったと実感しました。
フューチャーではともに働くメンバーを募集しています。
自然言語処理 (NLP) 分野では基礎研究から最先端技術の社会実装まで、幅広いキャリアパスの選択肢をご用意しています。
ご興味を持っていただいた方は、ぜひ キャリア採用サイト からのご応募をお待ちしております。
後編では、より詳細な技術的特徴・工夫や、今回の取り組みでは明らかに出来なかった今後の検討課題などをご紹介できればと思いますので、もしよろしければそちらもぜひご覧ください。
ありがとうございました!