AI Tips連載の5本目の記事となります。
はじめに
こんにちは。Strategic AI Group (SAIG) の藤井です。
GENIAC第2期事業にて採択された「日本語とソフトウェア開発に特化した基盤モデルの構築」プロジェクトに関する取り組み紹介、全2編の後編です。
前編では、開発したモデルの概要や開発の流れ、プロジェクト進行における反省点をご紹介しました。後編では、モデルの技術的特徴に関するより込み入った内容や、取り組みの中では明らかに出来なかった今後の検討課題・オープンクエスチョンを共有します。
改めて、本プロジェクトで開発したモデル Llama-3.1-Future-Code-Ja-8B はHugging Faceにて公開しております。
商用利用も可能な許容的ライセンスで公開しておりますので、ぜひ幅広く試して (遊んで) いただけると嬉しいです。
モデル学習における気づき・学び
今回のモデル開発では、① 継続事前学習、② 教師ありファインチューニング、③ 選好最適化 の3つのフェーズで学習を行いました。
ここでは、モデル学習における気づきや学びを、フェーズの順に紹介していきます。
継続事前学習
Fill-in-the-Middle (FIM) は学習時間のオーバーヘッド、性能低下ともに最小限
今回のモデル学習では Fill-in-the-Middle (FIM) と呼ばれる学習手法を導入しました。
ここで、LLMの (継続) 事前学習では、所定のコンテキスト長まで複数のドキュメントをつなぎ合わせ、詰め込んだものを1つのシーケンスとして学習することが一般的です(この操作は packing と呼ばれます)。
この時、1つの詰め込みシーケンスから prefix, middle, suffix の分割を作成する方法を “Context-level FIM”、元のドキュメント境界を尊重し、ドキュメント内で各分割を作成する方法を “Document-level FIM” と呼びます。
“Document-level FIM” は、各ドキュメントを事前に分割 → 順序を入れ替えておく処理で完結するため、実装が容易であり、学習時のオーバーヘッドも発生しませんが、packingの際に各分割が異なるシーケンスに分散してしまう可能性があることから、精度面では “Context-level FIM” に軍配が上がることが論文中で述べられています。そのため、今回はMegatron LM上に “Context-level FIM” の実装を追加して学習を進めることとしました。
Megatron LMを用いる場合、前処理の段階でコーパスはtokenize (トークン化) されます。packingの処理は、前処理済の トークンID を所定のコンテキスト長まで取得する形で実現されるため、テキストを任意の箇所で3分割するためには、一度detokenizeして文字列に戻した上で改めてtokenizeする という処理が必要になります。このように、学習時に追加の処理が加わることとなるため、学習速度の低下が懸念されたのですが、今回の開発環境 (p5.48xlarge × 4ノード) では速度面の影響はほとんど見られませんでした。
また、論文でも FIM-for-free と呼ばれているように、FIMの導入前後で一般的なLeft-to-Right生成タスクの到達点が顕著に下がるような現象は確認されませんでした。しかしながら、リソース制約により厳密な比較実験ができておらず、確かなことはまだ分からないというのも事実です。
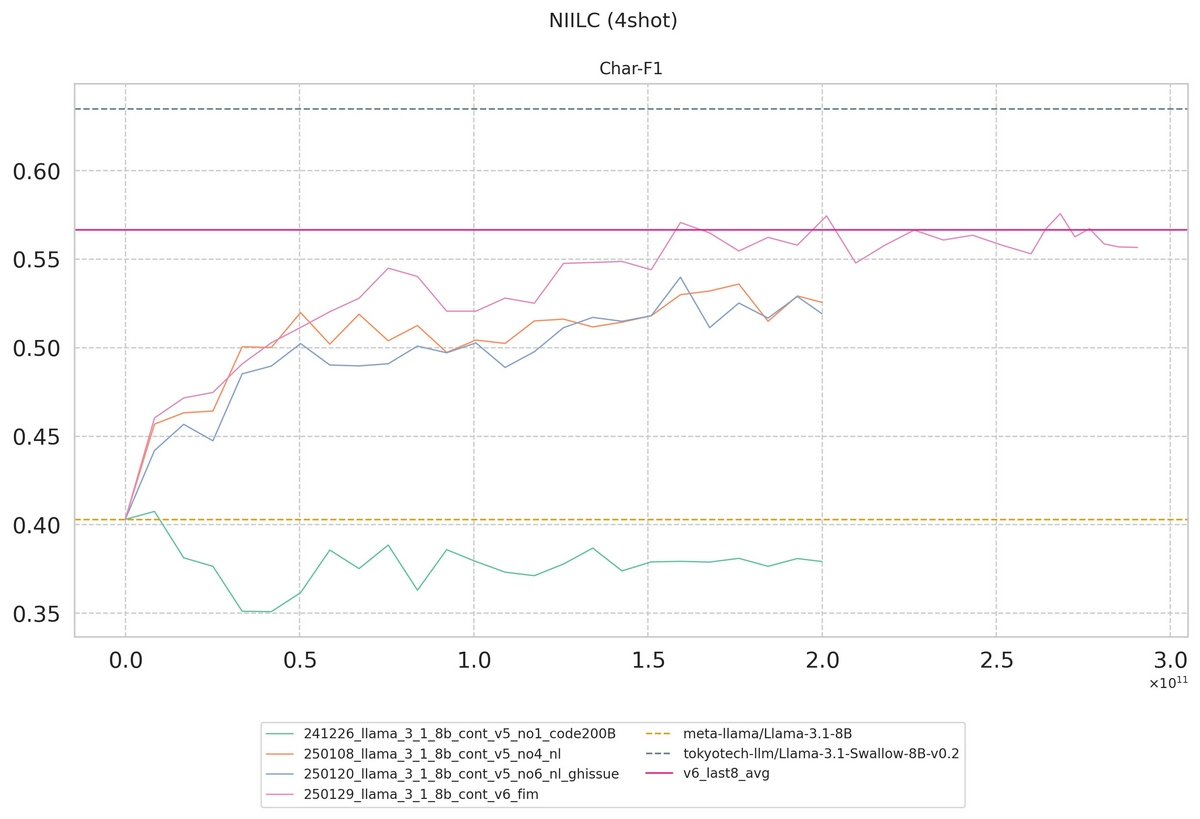
↓ FIM導入前後のスコアの比較 (NIILC)
桃色がFIM導入後、その他の線は導入前のもの (※ ただし、桃色線とそれ以外では学習データの総量、組成も異なる)。
FIM導入後 (桃色線) の到達点は、学習データの組成が類似するFIM導入前のモデル (青・橙線) と同等以上をキープしている。
事前学習時に学んだ “嫌な形質” は増強するのは簡単だが、取り除くのは困難
継続事前学習では、学習データに適用するフィルタを段階的に実装して、出力の定量・定性的な変化を確認していきました。
その過程で、特に初期のモデルに特徴的な傾向として # TODO: implement this function 等、ユーザに追記を促すような出力が顕著に増加する、(それに起因してか) 出力の平均長が学習前より短くなる現象が確認されました。Web上には教育目的で書かれたソースコードも多く存在しており、上記以外にも Write your solution, Implement me 等の派生が多数見られます。しかし、ソフトウェア開発 (コーディング) を支援するLLMにおいて、このような出力が望ましいケースというのはそう多くありません。
そのため、今回は学習データから数百万件のソースコードをサンプリングし、考えられる表現パターンを grep で洗い出した上で、いずれかの表現とマッチする場合には「ドキュメントごと」学習対象外とする対応を取ることとしました。しかしながら、そのような厳格な対応を取ってなお、# TODO: implement this function 問題は完全には解決しませんでした。
学習データで数百万件に1度と出現しない程度の頻度でありながら、そのような表現が生成されてしまう理由として、今回は「継続」事前学習であったことが考えられます。今回、学習に用いたトークン数 (約290B) は決して小さくありませんが、それでもLlama-3.1の事前学習におけるトークン数 (15T) と比較すると極めて小規模です。
手元の学習データにない入力# TODO... を出力するよう、モデルが既に学んでしまっていたとすれば、仮に手元の学習データで出現数を0に抑えられたとて生成を抑制することはできません。Next Token Predictionでモデルが学習するのは、手元のデータセットに対する Do’s であり、Don’ts の抑制はここでは困難である (選好最適化で対応するか、スクラッチからの学習時に徹底的に綺麗にするべき) というのは学びでした。
教師ありファインチューニング
LLMによる疑似データ生成はモデルが既に知っているタスクにbiasedな可能性が高い
今回の取り組みでは、 Magpie の手法を適用することで、ソフトウェア開発に特化したinstructionを「より優れたモデルから引き出して」学習を行いました。
この時、instructionを生成するための (システム) プロンプトは論文のAppendixに記載のものをベースとしたのですが、オリジナルのプロンプトを愚直に用いた場合では生成されるinstructionの多く (7割以上) がPythonに関するものとなってしまいました。
そのため、今回は The user will ask you a wide range of coding questions about the {language} programming language. のように、ユーザがアシスタントに求める役割として、関連するプログラミング言語を明示することでタスクに多様性を持たせることとしました。
このような「偏り」が存在する理由としては、Code LLMに関する既存の評価ベンチマークが極めてPythonに寄っているということが挙げられます。この状況は望ましくありませんが、そうなってしまっている以上、既存のモデルの多くがPythonに力を入れているのは当然であり、それらから抽出されるinstructionもまたPythonに偏ってしまいます。
さらに、この「偏り」はプログラミング言語の分布に限った話ではなく、生成されるタスクの種類についても同様に考えられます。今回の取り組みの過程で調査していて驚いたことですが、to code (生成する対象がコード) では様々なベンチマークが提案されている一方、コードを説明する・レビューをするなどの to 自然言語 のタスクには、ほとんどといって良いほどベンチマークが存在しません。
また、to code のタスクにおいても、純粋なコード生成 (補完) のベンチマークは多数存在する一方で、言語間翻訳などは盛んには取り組まれていない印象です。これには、評価方法が確立されていない、データの作成が困難であるなど様々な要因が考えられ、一朝一夕解決するようなものではないのですが「富める者は富み」の状況になってしまっていることは間違いないでしょう。
実際に、前編に記載のように、今回学習したモデルはベースライン (Llama 3.1-8B) と比較して高いコード補完性能を実現していますが、その一方でバグフィックス (HumanEvalFix) や仕様変更対応 (CanItEdit) に関するベンチマークではLlamaと同等の性能に留まってしまいました。
LLMの生成する疑似データには偏りが存在することを認識したうえで、より明示的なタスク誘導を入れる、他のスキーム (Evol-Instruct など) と組み合わせる、Human-in-the-Loopを検討するなど柔軟な対応が求められそうです。
| モデル | HumanEvalFixTests (Python) | CanItEdit (Descriptive) | CanItEdit (Lazy) |
|---|---|---|---|
| Llama-3.1-Future-Code-Ja-8B | 0.4698 | 0.4462 | 0.3857 |
| Llama-3.1-8B-Instruct | 0.4707 | 0.4648 | 0.3738 |
| Llama-3.1-Swallow-8B-Instruct-v0.3 | 0.3250 | 0.3329 | 0.2329 |
| Qwen2.5-7B-Instruct | 0.5415 | 0.4914 | 0.4138 |
| Qwen2.5-Coder-7B-Instruct | 0.5857 | 0.5395 | 0.4533 |
| Qwen3-8B | 0.5622 | 0.5833 | 0.4319 |
| gemma-2-9b-it | 0.4509 | 0.4643 | 0.3833 |
選好最適化
モデルベースのフィードバックでは報酬スコアのノイズに関する一定の考慮が必要
今回、各instructionに対し4件のresponseを生成し、それぞれを報酬モデル (Llama-3.1-Nemotron-70B-Reward-HF) で評価することで、DPO用の学習データを作成しました。この時、正例 chosen については「最もスコアの高いものを選択する」で基本的に問題ないと思われますが、負例 rejected の選び方についてはいくつかのバリエーションが考えられます。
検証では、① 最もスコアが近いもの (=2位) ② 最もスコアが遠いもの (≒4位) ③ chosen 以外からランダム選択 の3つのパターンで学習を行い、各モデルのベンチマーク性能 (コード補完性能) を確認しました。その結果、② スコアが遠いもの と ③ ランダム選択 の優劣はまちまちであるものの、① スコアが近いもの では他の設定を明確に下回るケースが多く見られました。
モデルベースの報酬は採点基準に沿った加点法ではないため、あるresponseがより高いスコアを獲得したとからいって、必ずしもそのresponseがユースケースに沿って「より優れている」ことを意味しません。コード生成を例にあげると、responseが満たすべき観点の1つには「機能的に正しく動作すること」があげられますが、モデルベースの報酬は「コードとは一切関係しない何らかの観点で優れている」ことを機能的正確性よりも重く評価する可能性があります。特にスコアの近い出力どうしのペアでは、このような非本質的観点による良さの逆転 (ノイズ) により良い学習シグナルが得られなかったことが考えられます。
↓ DPO時のペア選択法によるスコアの違い (予備実験)
青線 (②) と 赤線 (③) の優劣はタスク依存だが、緑線 (①) は明確にスコアが低い傾向
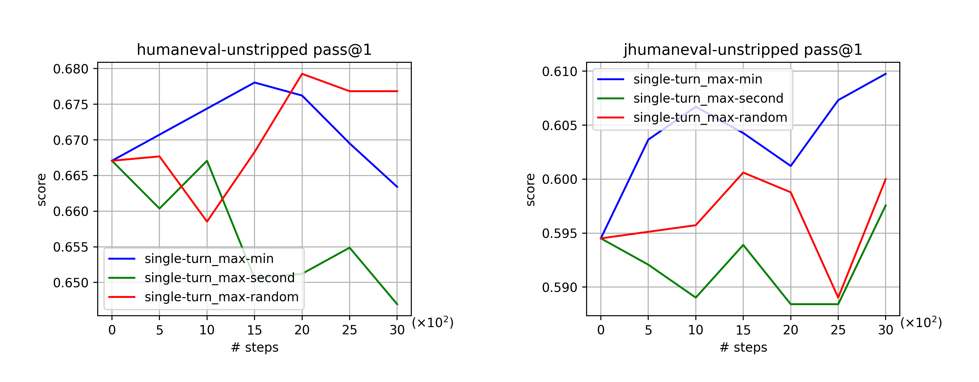
各responseは、報酬モデルで評価される前にルールベースのフィルタで事前に選別されます。そのため、生成時点では各instructionに必ず4件の候補が存在しますが、ペアデータ作成時には最もスコアの遠いもの = 4位であるとは限りません。
なお、選別の結果responseが1件しか残らなかった場合、該当のデータはSFTで用いることとしました。
モデル評価における気づき・学び
続いて、モデル評価における気づきや学びを紹介していきます。
また、ここでは「今後の」モデル開発における有力な方向性にも触れたいと思います。
コード補完タスクの評価は「怪しい」
不穏な見出しですが、HumanEval, MultiPL-Eなどのコード補完タスクについては「同一の環境で比較実行した結果」以外の結果は比較不能だと思った方が良い、という話になります。
これには、temperature (サンプリング温度) などハイパーパラメータの問題もありますが、より大きな問題としてsanitizeの問題が挙げられます。コード補完の評価では、補完対象の関数 (やメソッド) のみを評価するため、モデル出力の不要な部分を後処理で削除する手順があり、この処理はsanitizeと呼ばれます。例えば Code Generation LM Evaluation Harness のHumanEvalでは、\nclass, \ndef 等いくつかのストップワードを定義し、これらが出現したら補完対象の関数は閉じているだろう (切り詰めてもよいだろう) という判断をしています。
一方で、プログラミング言語によってはこのような単純な文字列マッチでは対応が難しいこともあります。
これに対して EvalPlus では、より正確な評価に向けて、AST (抽象構文木) を用いた高度なsanitize処理を実装するなどの対応を取っています。
しかしながら、問題は sanitize処理が統一されていない という点です。たとえ同じ評価ベンチマークを用いていても、異なる処理を実装したライブラリで評価した結果を直接的に比較することは適切ではありません。さらにいえば、同一のライブラリであっても開発の過程で処理が変化している場合があり、より厳密にはcommit hashのレベルまで統一されて初めて比較可能となります。
実際に、主要なオープンソースモデルについて手元の環境で評価を行った際、公称値とは10ポイント以上異なるようなケースも確認されました。
日本語 × ○○ に強いモデル構築は、特化モデルへの日本語学習が確かな方向性?
ソフトウェア開発タスク (特にコーディング) 特化のQwen2.5-Coder (以後Qwen) と、汎用モデルであるLlama 3.1 (以後Llama) を比較すると、しばしば、”英語タスク指示におけるLlamaのスコア” < “日本語タスク指示におけるQwenのスコア” であることが分かりました。
これはつまり、汎用モデルを起点に 日本語 × ○○ に強い、今回で言えば 日本語 × ソフトウェア開発 に強いモデルを目指そうとすると、もともと英語で出来ていたレベル以上の性能を日本語で達成しなければならない、というハードモードになってしまいます。
殊にCode LLMに関しては、Claude, GPT, Qwenをはじめとして世界中のモデルプロバイダがしのぎを削ってその性能を競い合っています。このような背景において、世界一のソフトウェア開発データを作ることは困難ですが、日本のLLM開発者・研究者にとって、世界一の日本語データを作ることはこの苦難と比べれば幾分容易いと言えます。
また、今回Python以外にも多くのプログラミング言語で評価を行ったことで、<10B (7~9B) の比較的小規模なモデルでは継続学習時に見ていない言語を忘れがちであるのに対し、70B等の大規模モデルでは学習していないことがビハインドになりにくいということも見えてきました。
これらの観測を踏まえると、コーディングや数学など、ドメインに特化した大規模モデルを起点に高品質な日本語を学習し、それらの蒸留を通して小規模モデルを作成することが有望な方向性であるように感じます。
今後の検討課題
ここでは、今回の取り組みの中では明らかに出来なかった今後の検討課題、今後明らかにしていくべきオープンクエスチョンに触れたいと思います。
(継続) 事前学習においてlinterやformatterを活用すべきか
PythonのPEP 8のように、プログラミング言語にはしばしば「こう書くべき」を定義したコーディング規約が存在します。linterやformatterは、ルール・スタイルに従わない不適切なコードの検知や修正を行うツールであり、LLMの学習データに適用すれば自然と (一般的な) ベストプラクティスに沿った良いコードを出力することが期待されます。
しかしながら、実際の利用シチュエーションを想定すると「綺麗なコードしか見たことがない」というのは問題です。例えば、構文エラーについて一切知らないモデルは、構文エラーを含む入力に対して「バグを修正してください」というリクエストには応えられないでしょう。
「知らない」は回避しつつ、望まない出力は「出さない」を実現するために、静的解析ツールを含めた諸々のフィルタリングルールを如何に組み込むべきか、という点はさらなる検討が必要と考えます。
LLMで作成したデータを (継続) 事前学習 から取り込むべきか
今回、継続事前学習のフェーズでは、GitHubやCommonCrawlに由来するウェブ上の生データのクリーニングに注力し、instruction tuningで用いるようなタスク指示と応答のデータや、LLMで作成したデータ (疑似データ) は用いませんでした。
しかし、このような「LLM時代のデータ」を事前学習時に混ぜておくことが、”ベースモデル” のタスク遂行性能の向上につながることも明らかになっています。ここで疑問に上がるのは、この「タスク遂行性能の向上」が、SFT以降で獲得される能力の先取りに過ぎないのか、SFT (DPO) 後の最終到達点を上げるポテンシャルを有するものなのか、ということです。
今回の取り組みから得られたベースモデルのコード補完性能は、純粋なウェブ上のデータのクリーニングで到達できる性能としてはアッパーバウンドに近いと考えています。主要なオープンソースモデルを評価した結果、同規模のモデルで比較すると、Llama, gemma系のベースモデルのスコアは今回の学習モデルと同等 ~ やや学習モデルの方が優れている程度である一方、Qwen系のベースモデルはベースモデルのスコアが非常に高いことが分かりました。このことから、おそらくLlama, gemma系とQwen系はベースモデルに対するスタンスが異っており、Qwenはより早期から積極的に疑似データを採用していると推察されます。
instructモデルの性能で比較した時、コード補完タスクにおいては多くのケースでQwen系が優れています。
しかしながら、Llama, gemma系はベース → instructの伸び率がQwen系と比較して顕著に高く、ベースモデルでの両者の差ほど最終性能には差がないというのも事実です。また、最終性能の差は (SFT以降の) 事後学習データの差にも起因します。
仮に同じ事後学習データを用いたとして、事前学習時から疑似データを見た方が良いのか?は未だ明らかになっておらず、今後の調査に値すると考えます。
おわりに
さて、ここまで2回に分けて「日本語とソフトウェア開発に特化した基盤モデル」Llama-3.1-Future-Code-Ja-8B の開発に関する取り組みをご紹介してきました。
本記事の内容が、LLMを作る・使う多くの方々に少しでも響いてくれたなら嬉しいです。
フューチャーではともに働くメンバーを募集しています。
自然言語処理 (NLP) 分野では基礎研究から最先端技術の社会実装まで、幅広いキャリアパスの選択肢をご用意しています。
ご興味を持っていただいた方は、ぜひ キャリア採用サイト からのご応募をお待ちしております。
また、本取り組みに関して詳細を聞きたい、フューチャーのNLP, AIの取り組みについて気軽に聞きたいという方は、以下もご活用ください。
- 本取り組みについての問い合わせ : pj-geniac at future.co.jp
- SAIG NLPチームへの問い合わせ : gr-saig-llm at future.co.jp
ご覧いただきありがとうございました!