.png)
AI Tips連載の9日目の記事です。
こんにちは!Energy Transformation Groupの大前七奈です。
最近、Google Agent Development KitやLangChainエコシステムを触る機会が増える中で、多くの企業や研究機関、政府機関が、契約書、報告書、マニュアル、論文、請求書などの重要な情報をPDF形式で保存・配布していることに改めて注目しています。
これらの膨大な情報源から、LLM(大規模言語モデル)が直接情報にアクセスし、理解できるようになることは、実用的なAIソリューションを構築する上で不可欠だと考えています。
PDFとは
PDF(Portable Document Format)は、文書をアプリケーションやOS、デバイスに依存せずに表示・印刷できるようにするためのファイル形式です。PDFは「PostScriptの描画モデルに基づき、印刷だけでなく、電子的な文書交換に最適化された静的なファイルフォーマット」として広く利用されています。
PDFの内部構造について、zawakinさんの僕「PDFとは何か知りたい」のQiita記事も参考になります。
課題感
しかし、PDFの内部構造が「グラフィックコマンドの集合体」であるため、単純なコピー&ペーストではテキスト情報を正確に抽出することが難しいという課題があります。
特に、スキャンされたPDF(画像PDF)の場合はOCR(光学文字認識)が必須となり、この抽出精度がRAG(Retrieval-Augmented Generation)システムの性能に直結します。
PDF抽出フロー
このような課題を解決し、PDFから効率的かつ正確に構造化されたデータを抽出するために、以下のフローを考案しました。このフローでは、特にプロンプト設計とBigQuery MLを活用しています。
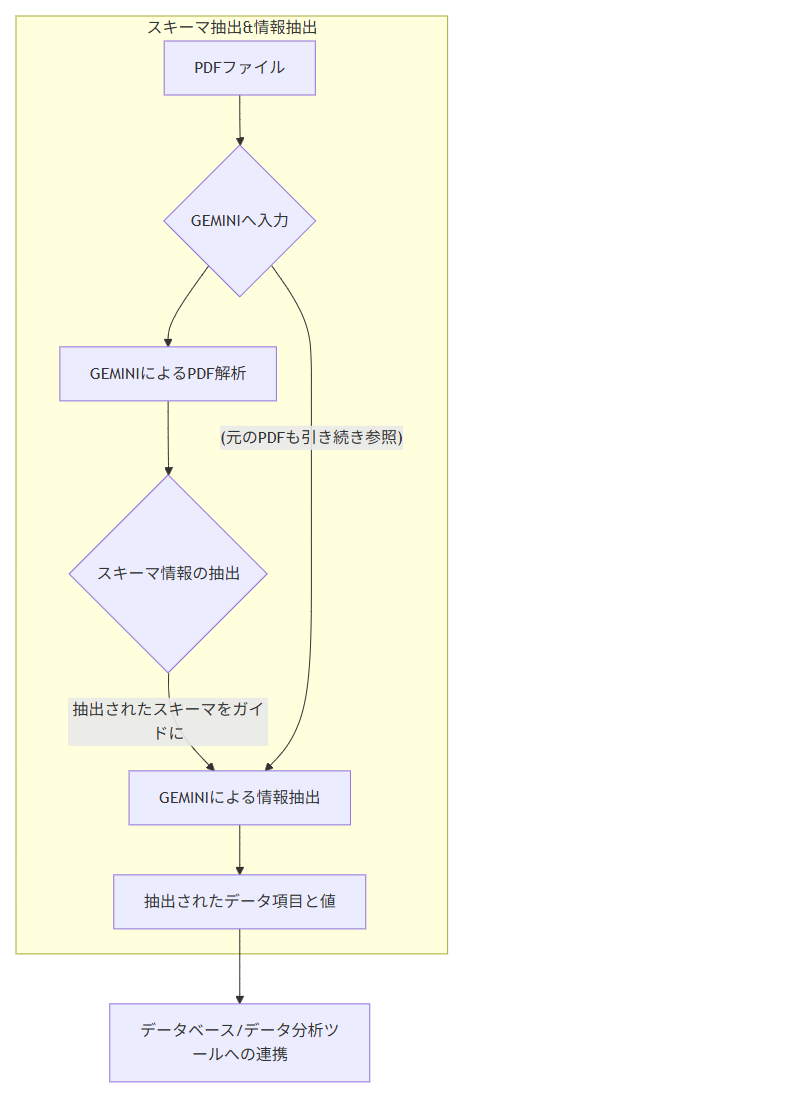
シーケンス図 (クリックでコードを表示)
graph TD |
プロンプト設計
LangChainの公式ドキュメントでは、PDFから構造化データを抽出する際に、Pydanticの型をセットでLLMに渡すことが推奨されています。
しかし、社内文書は必ずしもすべて同じスキーマになっているわけではありません。そこで、プロンプト設計の段階で、スキーマ抽出自体もLLMに任せることにしました。これにより、様々な形式のPDFに対応できる柔軟な抽出システムを構築することが可能になります。
以下に示すプロンプトは、PDF解析からJSONデータ抽出までを自動で行うためのものです。
スキーマ抽出と、スキーマに沿った情報抽出の2つタスク分解することで、より汎用性を高めるプロント設計となります。
あなたは高度なPDF解析とJSONデータ抽出を行うAIです。以下のタスクを順番に実行してください。 |
**タスク2: タスク1のスキーマでPDFからデータ抽出** |
今回利用するPDFサンプル
来月開催されるGoogle Next Tokyoの登録済みセッションのPDFです。

準備完了!さて、BigqueryMLで抽出しよう
上記のプロンプト設計とPDF抽出フローが整えば、いよいよBigQuery MLを使ってPDFからのデータ抽出を実行できます。BigQuery MLは、SQLインターフェースを通じて機械学習モデルを利用できるため、データエンジニアやアナリストが手軽にLLMを活用したデータ抽出パイプラインを構築できます。
以下のBigQuery MLのクエリは、PDFを格納したGoogle Cloud Storageのバケットからデータを読み込み、LLM(Gemini 2.0 Flash Experiment)を使って構造化データを抽出する例です。
CREATE OR REPLACE MODEL `gemini_us.gemini-flash-connection` |
現時点、Gemini利用可能なリージョンはUSのみです。それ以外のリージョンを選択してモデルすると、エラーが出ます。
CREATE EXTERNAL TABLE gemini_us.pdf_table |
SELECT ml_generate_text_llm_result |
ML.GENERATE_TEXT関数のMAX_OUTPUT_TOKENSがデフォルトで1024です。ユースケースに応じてMAX_OUTPUT_TOKENSを明示的に定義しました。
こちらでGENERATE_TEXTのsyntaxを確認できます。
https://cloud.google.com/bigquery/docs/reference/standard-sql/bigqueryml-syntax-generate-text#syntax_for_standard_tables
PDF抽出結果
タスク1: PDFスキーマの抽出
{ |
タスク2: タスク1のスキーマでPDFからデータ抽出
{ |
今回の出力結果から、以下の重要な点が確認できました。
- 動的なスキーマ生成の有効性
- タスク1で生成されたJSONスキーマは、PDFの内容を適切に反映しており、各フィールドのデータ型、必須・オプションの指定、さらには列挙型(enum)まで詳細に定義されています。これにより、PDFの内容が多様であっても、LLMが自動的に最適なスキーマを推論できる柔軟性が示されました
- 正確な情報抽出
- タスク2では、生成されたスキーマに基づいてPDFからデータが正確に抽出されています。特に、複数のセッション情報がsessions配列として正しく構造化されている点、およびセッションステータスが「登録済みセッションから削除」の場合とnullの場合が適切に処理されている点に注目できます。これは、LLMが複雑な構造を持つドキュメントから必要な情報を正確に識別し、指定されたフォーマットで出力する能力が高いことを示しています
- BigQuery MLとの連携の容易さ
- BigQuery MLのML.GENERATE_TEXT関数を利用することで、SQLインターフェースから直接LLMを呼び出し、構造化データを取得できることが確認できました。これにより、データパイプラインへの組み込みが非常に容易になり、データ分析環境内でシームレスにPDFからのデータ活用が可能になります
これらの結果は、LLMとBigQuery MLを組み合わせることで、これまで手作業や複雑なスクリプトが必要だったPDFからのデータ抽出を、効率的かつ柔軟に自動化できる可能性を強く示しています。
まとめ
PDFからの効率的な情報抽出を実現するため、LLMとBigQuery MLを組み合わせたソリューションを紹介しました。特に、動的にPDFのスキーマをLLMに抽出させることで、様々な形式の社内文書に対応できる柔軟性の高いシステムを構築できることがご理解いただけたかと思います。
このアプローチにより、PDFに埋もれた貴重な情報をRAGシステムなどで活用できるようになり、より実用的で強力なAIソリューションの構築に繋がるでしょう。