
夏の自由研究2025ブログ連載の3日目です。
こんにちは!Energy Transformation Groupの大前七奈です。
dbtは、データエンジニアリングの現場に革新をもたらしましたが、プロジェクトが大規模になるにつれて、いくつかの課題も浮き彫りになってきました。
本記事では、その課題を解決するために開発された次世代のエンジン「dbt Fusion Engine」について、実際に試してみた所感を交えながら、その凄さや移行方法、そして今後の展望について詳しくお話ししたいと思います。
改めてdbtすごいところ
dbt(Data Build Tool)は、データエンジニアリング界隈に革命をもたらしたELT(Extract, Load, Transform)ツールです。Gitバージョン管理システムで、SQLでデータ変換を管理でき、さらにデータ変換のステップを複数の小さなSQLファイルに分割して管理することで、コードの再利用が容易になり、メンテンス性も向上します。
また、データ品質を保証するためのテスト機能と、データのドキュメントを自動生成する機能が組み込まれています。dbtは、データパイプラインをより効率的に構築・管理できるようになりました。
既存のdbt-coreの問題点
しかし、プロジェクトが大規模になるにつれて、dbt開発チームには以下のいくつかの課題に直面しました。
- 遅いコンパイル時間
- 開発当初に完了時間が1分のバッチジョブが、データモデルの数とデータ自体の増加により10分までに増加しました
- Pythonの依存関係の競合
dbt-corev1.8.xがprotobuf<5.0.0を要求するのに対して、データサイエンス系のscikit-learnやtensorflowの最新バージョンならprotobuf>=5.0.0を要求する場合
- 冗長なウェアハウス実行
- デバックはdbt実行してデータウェアハウスにアクセスする手段しかない
- 限定的なIDEサポート
- リアルタイムかつローカルなバリエーションができない
dbt fusion engineが起こす革命
以上の課題を解消するために、dbt LabsがRustで、dbt-coreを書き直して、2025/5/28に、dbt fusion engineをリリースしました。dbt Fusionのリリースと同時に、データエンジニアが待ちに待ったVS Code拡張機能も新たに導入されました。
Pythonベースのdbt-coreと異なり、SQLをデータウェアハウスに送信する前に、dbt Fusion EngineがSQLをローカルでパースし、コードを分析・検証し、リアルタイムにエラーを教えてくれます。データウェアハウスにアクセスすることなく、つまり、時間とコストの両方を節約できます。
- 入力中のライブエラー検出
- データモデルを理解するスマートなオートコンプリート
- カラムやモデルへのGo-to-definition機能
- クエリを実行せずにインラインCTEをプレビュー
- ホバーでモデルのメタデータを表示 などなど
詳しくは、dbt VS Code拡張機能の紹介動画がありますので、ご参考ください
移行方法
0.利用するバージョン
- dbt fusion engine beta: 2.0.0-preview.6 (2025/8/28時点)
- dbt-adpater: 1.16.3
- dbt-bigquery: 1.8.1
1.インストール(MacOs, Linuxの場合)
MacOs, Linuxの場合は、dbt VS Code拡張機能をインストールすると、Fusionをインストールするポップアップが出てくるので、「はい」とクリックすると、自動的にFusionがインストールされます。
詳しい手順は、公式サイト(dbt VS Code拡張をインストールする)をご参考ください。
Windowsにおけるインストール
Windowsの場合は、VS Code拡張機能を経由してFusionのインストールできなかったため、PowerShellで以下のコマンドをたたき、dbt.exeのパスを通すと、上記と同じようにdbt fusionを利用することができました。
2.インストール後の対応
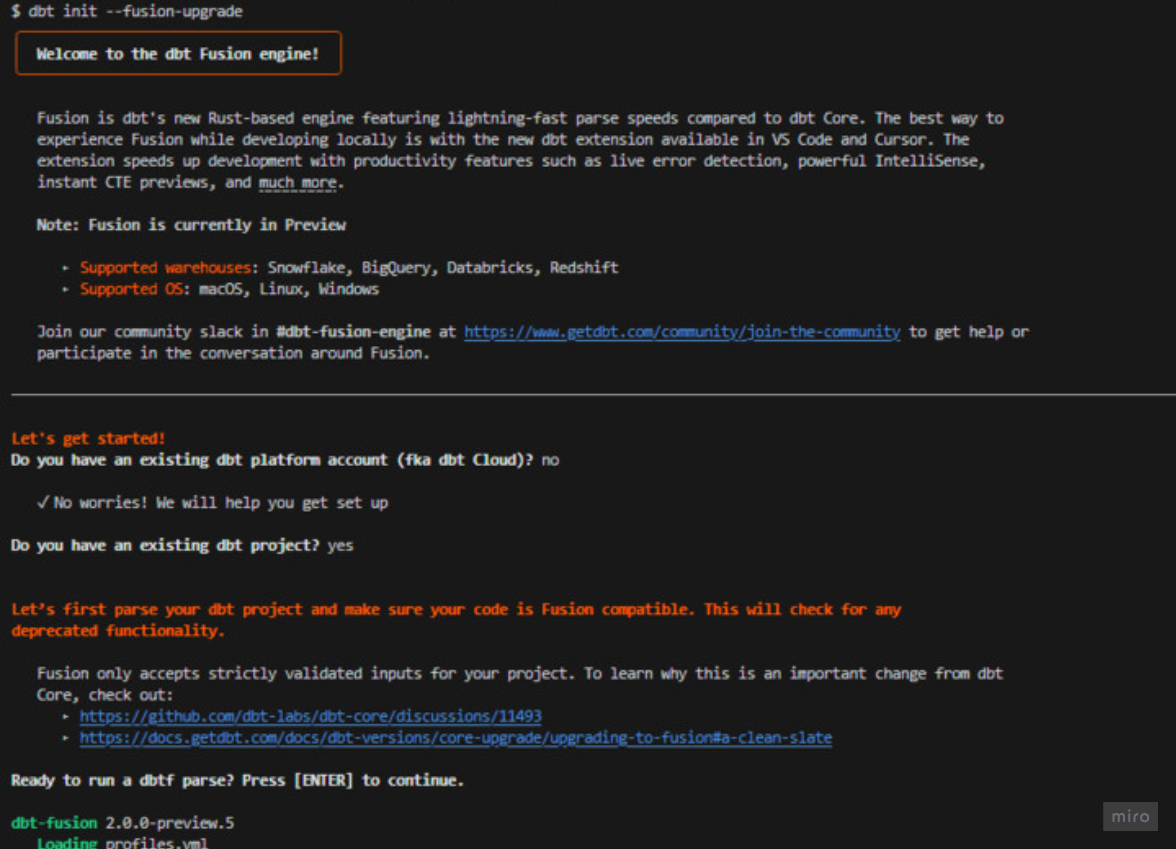
dbt-coreからの移行手順もとても簡単です。以下のコマンドをただくと、画像のとおり、いくつかの質問に答えると、自動的にdbt-autofixまで適用して移行のためのファイルの書き換えを行ってくれます。
dbt init --fusion-upgrade |
実際の移行時のログ:
dbt fusion engine使ってみた所感
良かった点
目論見通り体感できるほど高速化しました。ただし、最大30倍高速になるという謳い文句ほどではありませんでした。
例えば、過去に3分実行時間が必要なパイプラインがおおよそ1分で終わりました。
よくよく考えてみると、dbt fusionはあくまでSQL実行計画をしてくれるツールであり、30倍早くならなかった理由は以下の様に考えられます。
- そもそもSQL自体の最適化が徹底されていない
- そもそもSQLの依存関係が複雑すぎる
- marcos テンプレートの多用により解析時間がかかる
気になった点
dbt-autofixで差分が大量に発生しました- 事前にブランチを切って移行による変更点を分けると良いです
- 特に
{{ ref("table_name") }} -> {{ ref("source", "table_name") }}などJinjaテンプレートへの変更の割合が多かったです
dbt-autofix後にSyntaxの違いによる手動変更が必要です- dbt hubの外部パッケージ未対応です
- プロジェクト内でカラムの
descriptionが伝播されるようにdbt-osmosisを利用していますが、fusionの現バージョンで未対応のため、一旦profiles.yml内の関連記述をコメントアウトしてからようやくdbt runを実行できました
- プロジェクト内でカラムの
- バグがまだまだあります
- たとえば、データウェアハウス内にデータがない場合、今までdbt-coreではエラーが出なかったのに、Fusionで同じ実行すると、
Parquet ArrowWriter Errorが出ました
- たとえば、データウェアハウス内にデータがない場合、今までdbt-coreではエラーが出なかったのに、Fusionで同じ実行すると、
上記のエラーが公式GithubのIssueとして発行されておりました。もし謎のバグに出合った際、Issue一覧から類似するバグがないか、一度調べてみるとよいです。
いつ正式運用できるか?
以下の公式ドキュメントによりますと、以下の何点か未対応だそうです。ただ、具体的な完了時期が言及されていません。
- マテリアライズ機能を利用しているモデル
- Fusionのロギングシステムは、現在不安定で不完全です
- dbtプラットフォームの補完的な機能(モデルレベルの通知、高度なCI、およびセマンティックレイヤーなど)に依存するワークフロー
参考:GAへの道
以上で、dbt fusion engineの使ってみた所感でした!個人的にマテリアライズ機能やCI機能が揃ったら導入をしてもよいかと思いました。しばらく公式サイトのIssueの消化具合を見つつ、導入時期を判断していきたいです。