夏の自由研究連載2025のラスト、10日目での記事です。
はじめに
SAIGの小橋です。最近、間違って冷凍庫のドアを開けたまま外出してしまい、中身が全部解凍されてしまったので凹んでいます。
さて、今回は、AIと社会格差について、論文を読んで記事を書きたいと思います。
GPT-5がリリースされた際、#keep4o という運動が起きました。旧モデルのGPT-4oは暖かさや共感力があったが、新しいGPT-5は冷淡で機械的だと、一部ユーザーから批判の声が上がりました。
それに関連してこの論文を思い出しました。ただ、腰を据えて読んだことが無かったので、これを機に読むことにしました。
概要と注意点
この論文では、1000人にアンケートを実施して収集したデータを分析し、個人のSES(社会経済的状況)とAIの使い方には関連性があることを示しています。
今回のSESは、IT企業でよく登場するSES契約(System Engineering Service)の話ではなく、「社会経済的地位」の意味です。分かりやすくいうと、「SESが高い」とは、高学歴・高収入で良い暮らしをしている人を指します。
注意点として、私が気になった箇所を特に注目して掘り下げて考察しています。全体の概要を知りたい人は、先に他の記事を読んだ方がいいかもしれません。例えばこちらの記事などがあります。
AIを活用した論文の読み方
私は研究開発職ではないので、論文を日常的に読んでいるわけではなく、いきなり論文を頭から読んでいくのはちょっと大変です。そこでAIの力を借りて、alphaXivというツールを使うことにしました。
会員登録が必要ですが、無料で論文をブログ記事として読むことができます。しかも、英語だけではなく、日本語に変換した記事も読むことができます。(原文の日本語訳はありません)
またこのサイト上ではLLMのチャットボットのシステムがあり、論文の内容について質問すると原文を適宜参照して答えてくれます。いわば、論文を取り込んだnotebookLMのようなものです。便利な世の中ですね。
なお、以下の文章中では、alphaXivのチャットボットの回答が一部含まれています。
調査におけるデータ収集方法
まず私が気になったのは、著者らがどうやってデータを収集したかという点です。
著者らは、Prolificというクラウドソーシングサイトを使って回答を収集しました。
サイトを見ると、(特定の成果物を作成してもらうタイプのクラウドソーシングではなくて)データ収集に特化したサイトのようです。つまり仕事を発注する側は何らかのアンケート(データ収集用フォーム)を準備して回答者を募集します。受注者はそのアンケートに回答して報酬を得るという形だと思います。
研究者たちは、Prolificを通じてデータを収集したことにより、偏りや歪みが生じた可能性があると考えています。この点については、論文の「制限事項」の章に説明があります。
- 対象者が広い集団を代表していると言えるか: この研究は、Prolificプラットフォームの米国および英国のクラウドワーカーに限られているため、広い人口を代表していない可能性があります。社会経済的地位に関して、Prolificの利用者は中流階級から下流階級に偏っていると研究者たちは予測しています。
- 言語技術への親和性: クラウドワーカーは一般の人口と比較して、技術、特に言語技術に詳しい可能性が高く、そのため言語技術をより頻繁に利用している傾向があるかもしれません。
SESとは何か、どのように測定したか
次に私が気になったのは「回答者のSESをどのように測定したか」という点です。結論から言うと、Macarthurスケールというものを使用していて、「自分の社会経済的地位を1〜10の中で評価してください」という質問をしています。
SESはSocioeconomic Statusの略で、日本語では「社会経済的地位」と訳されます。論文では、SESを個人またはグループの社会経済的な位置を指すと定義しています。具体的には、個人の経済的、社会的、文化的な資本の関数であり、収入、教育、職業、富といった要素がSESに影響を与えると説明されています。
SESの測定方法としては、Macarthurスケールを使用しています。下図の通り、参加者にはしごの絵を見せて、「自身は、社会経済的はしごの1から10までの間でどの位置に該当するか?」という質問をしています。
その後、1〜3と答えた人を低SES、4〜7を中SES、8〜10を高SESと分類しています。
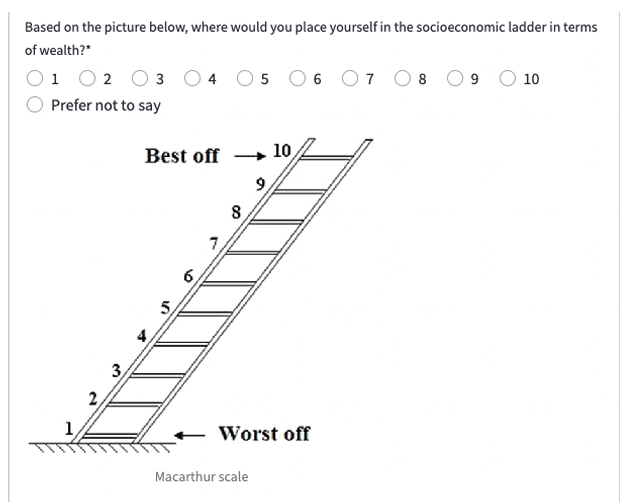
この方法は結構意外でした。学歴や年収などの客観的な指標を聞くのかと想像していましたが、「主観的な質問1問だけで良い」と考えて、SESを測定するというのはいい加減な手法ではないかと思いました。ただ、調べてみるとMacarthurスケールはよく使われる手法らしいです。
著者らもこの手法の限界については気づいていて、以下の通り述べています。「我々はSESを測定する上でマッカーサスケールを使用しました。主観的な尺度は曖昧さや偏りが生じやすい傾向があります。しかしながら、自分自身のSESに対する認識が行動や態度に重要な役割を果たすことも認識しているため、このため本調査ではこの尺度を用いることにしました」
なお学歴や趣味などもアンケートで収集していますが、SESを分類する際には使用していません。完全に蛇足ですが、趣味の選択肢に “Visit to stately homes” という項目があるのが不思議でした。イギリスなどにある昔からの貴族の屋敷を訪問することを指しているようですが、もっと一般的な「travel」のような項目が無いのに、こんな特定の項目があるのはなぜ……?
SESとプロンプトの長さの関係
それでは分析の方に移りましょう。論文中の分析は大きく分けて「言語関連の技術の使用状況について」「プロンプトの言語学敵分析(長さや語彙など)」「プロンプトのクラスタリングによる内容分析」「ユーザーがAIをどう認識しているか」の4つです。
ここでは特に興味深い2つの側面に焦点を当てて考察してみたいと思います。まず最初に、プロンプトの長さとSESの関係について見ていきましょう。次に、AIとの日常会話とSESの関係についても触れます。
社会階層が高い人々ほどプロンプトが短く簡潔になるらしいです。プロンプトの平均単語数は以下の通りです。
- 低SES層: 27.0語
- 中SES層: 22.3語
- 高SES層: 18.4語
この違いは、統計的に有意であると書かれています。この違いは、高SES層の個人がより広い語彙を持ち、少ない単語で自分自身を表現できることに起因するのではないかと研究者たちは推測しています。
調査方法への疑問
一見納得できる結果のようですが、立ち止まって考えてみると、この具体的な数値(20〜30単語)が私個人の実感と全く合致しないのでどうも腑に落ちません。
著者らはこの論文のcontributionとして
The first dataset of real prompts annotated with fine-grained sociodemographic information, including SES
と述べていますが、この内容がどこまで「リアル」なのかは注意すべきでしょう。正確な(実際に入力したものと全く同じ)プロンプトではないと推測されます。
第一に、自分が望む回答を得るために質問をどんどん具体的にしていったら語数は増えていき、上記に全く収まらないのではないでしょうか。例えば論文中には「Create a cover letter for a new role as a communication manager」という例が載っています。これをそのまま入力してもChatGPTなどは回答を出力しますが、その内容が自分の職歴に合致しているとは限りません。したがって回答の精度を上げるためには自分の職業内容や応募先の職務内容を入力するのが望ましく、そうするとプロンプトの語数は30単語どころではなくなります。
第二に、ある種の質問は対象となる文章が必要なので、明らかにプロンプトが長くなります。具体的には翻訳、要約、文章校正などです。「以下の文章を翻訳してください。(翻訳対象の文章)」というプロンプトの場合、ゆうに数百語、数千語になる可能性があります。要約や文章校正についても同じです。先の例であれば「カバーレターを書いてみたがこれでよいかレビューしてください」のようなプロンプトならば語数は多くなります。
このアンケートでは、回答者にプロンプトを入力してもらう際に「できれば、会話から直接コピーペーストしてください(Perferably, copy and paste the questions directly from the conversation.)」と依頼しています。したがって回答者はその場でプロンプトを書くこともできるし、コピーペーストすることもできます。しかし、上記の点を考えると、本当のプロンプトを入力したにしては平均単語数が少なすぎます。回答者は正確なプロンプトをコピー&ペーストする代わりに、回答者が改めて一から新しくプロンプトを書いた可能性があるのではないでしょうか。
また、前処理についての記載を調べました。例えば極端に長いプロンプトを除外するなどの処理をしれから平均長を計算したのかとも予想しましたが、前処理について何ら記載はありませんでした。論文の記載を見る限り、特に前処理をせずにアンケートの回答結果をそのまま用いたようです。
SESと日常会話の関係
低SES層のユーザーは、生成AIを人間のように扱い、一般的な会話をしているという結果も見られました。その内容を詳しく見ていきましょう。
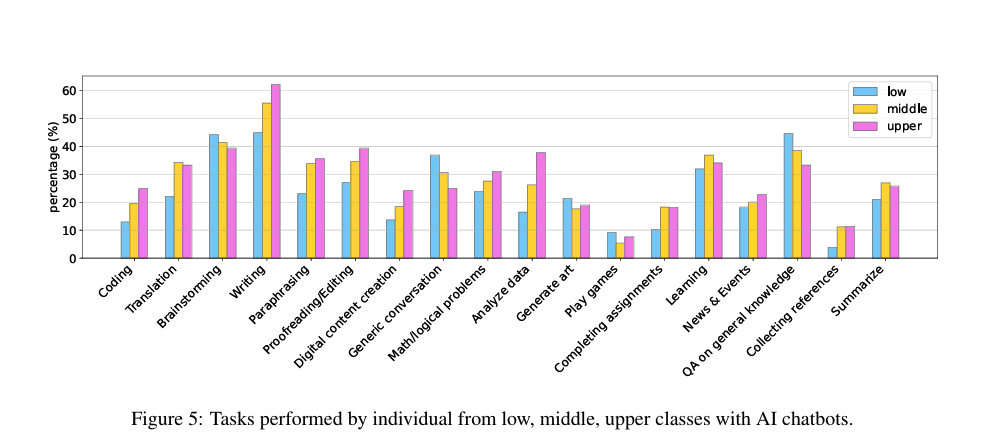
まず、アンケートでは、どのような用途でチャットボットを使用したかを質問しています。低SES層の方が利用割合が高かった主な項目は以下の2つです。
- Generic conversation(一般的な会話)
- QA on general knowledge(一般的な知識についての質問と回答)
この結果の解釈は慎重に行う必要があります。まずアンケートの結果はプロンプトに基づいたものではなく自己申告であるため、回答バイアスの影響が考えられます。例えば、高SES層の方々は実際には「一般的な会話」をしていても、見栄を張って「一般的な会話はしていない」と回答をした可能性も否定できません。
また、「一般的な会話」が具体的にどのようなものを指すのか知りたかったですが、論文中に具体的なプロンプト例が示されていません。なお、今回のプロンプトの分類はアンケートに基づいた結果であり、実際のプロンプトの内容分析はクラスタリングを使用しており、両者が別々に実施されていることにも留意する必要があります。
次に、「ユーザーがAIをどう認識しているか」についてです。Anthropomorphism(擬人化)という単語は論文中に登場し、4種類の条件を満たす割合を求めています。4種類のうち「Phatic expression(挨拶的表現)」については「thank, thanks, please, hi, hello」を含むプロンプトの割合を計算しています。これが低SES層のほうが使用率が高かった(統計的に有意ではない)ようです。
ただ、前述の通り、分析対象は正確なプロンプトではないと考えられます。そのため、この分析の妥当性には疑問が残ります。
仮に実際のプロンプトからコピーペーストせずに自分で改めてプロンプトを書く場合、「thank you」や「hello」などの挨拶的表現は真っ先に省略される可能性が高いでしょう。「挨拶的単語の使用割合」について有意義な議論をするためには、ユーザーが実際に入力したプロンプトを一字一句正確に収集する必要があります。この点で調査方法に課題があるため、この分析結果の解釈には慎重になるべきだと考えます。
2つの点について分析結果を見てきましたが、この分析では生成AIとの会話内容の一側面しか分からないでしょう。例えば極端な例として、ChatGPT(4o)と結婚した人のニュースがありました。本論文は、AIに人格を与えたり、回答のスタイルを大きく調整するような話には全く言及していないことには注意が必要です。
AIの性能評価は一面的な尺度だけを見ている?
ここまで論文の分析内容を見てきましたが、調査方法や結果の解釈には慎重に検討すべき点がいくつかあることがわかりました。最後に、論文の議論の部分で特に興味深い指摘があったので、それを紹介して締めくくりたいと思います。
高SES層のユーザーが行うような、言い換え、要約、数学的問題解決といったタスクは「ground-truth(正解)のある評価」には適している。一方で、低SES層のユーザーがより頻繁に行うようなタスクは、人間の好みによる評価に大きく依存しているため、既存のベンチマークでの評価が不十分である。将来の研究では、全てのSES層を代表するような現実的なシナリオに対してモデルの性能をベンチマークすることに焦点を当てるべきだと、著者らは述べています。
確かに、例えば私が「技術ブログを書いているけど、なかなか書き終わらないしもう疲れてきた」と弱音を吐いた場合に、AIが「もう少しだけ頑張ってみましょう」と励ますのが正解なのか、それとも「そうですね、疲れているならば今日はもう寝て、続きは明日にしましょう」と休憩を促すのが正解なのか、これは難しい問題です。時と場合によって正解は変わりえるからです。(AIの回答が当初の予想と違うものだったけど結果的にOK、という場合さえあります)
この指摘は、AIの性能評価のあり方について考えさせられます。現在のAIの性能は、「数学オリンピックの問題を何%解けたか」といった、いわゆる「ground-truth(正解)のある評価」で語られがちです。しかし、AIの良し悪しを判断する材料は、それだけで十分なのでしょうか。
大学院や専門家レベルの難問を解く能力よりも、人間と楽しく会話できる能力の方が重要だという側面もあるはずです。正解のあるタスクの評価だけでは、こうした側面を見逃してしまうかもしれません。その結果として、例えば「GPT-4oがおべっかばかりで気持ち悪い」と批判されたり、「GPT-5のモデルが冷淡すぎるから以前のバージョンに戻してほしい」と言われたりするような問題に繋がっていくのかもしれない、と感じました。
おわりに
この記事では、論文をきっかけに、社会経済的地位(SES)とAIの使われ方の関係、そして現在のAI性能評価のあり方について考えてきました。特にAIの性能評価というテーマは、今後どのように発展していくのか興味深いところです。単純な正解・不正解だけでなく、ground-truth(正解)のない問題に対してどのような評価指標を設計していくのか。これは、これからのAI開発における大きな課題と言えるでしょう。
記事の冒頭で触れた「#keep4o」の運動を思い返すと、今回の論文が示唆するテーマとの繋がりが見えてきます。GPT-4oに「暖かさや共感力」を見出したのは誰だったのか。人が生成AIに何を求め、そのニーズが個人の属性によってどう変わるのか。今回読んできた論文は、これらの問いの一部に答えているに過ぎません。今後、この分野のさらなる研究が登場することを待ちたいと思います。
(論文を読んでいて気づいたのですが、このアンケート結果はhuggingfaceに公開されているようです。せっかくの自由研究ならそのデータを使って何か分析すれば良かった……)