はじめに
こんにちは、Core Technology Groupの山田です。
PostgreSQL のフォーマッターである uroborosql-fmt1 の開発に携わっています。
先日リリースされたuroboroSQL-fmt ver1.0.0では、過去バージョンの課題を解決するために、新たに自作したパーサーを利用するように変更しました。
自作したパーサーであるpostgresql-cst-parserはこちらのリポジトリに置いています。
個人リポジトリの方は実験的に作成していた際のリポジトリで汎用的なパーサーとしての機能のみ実装されており、当社の organization 配下の方はフォーマッターへ組み込むために機能拡張したものです。
今回は過去uroborosql-fmtで使用していたパーサーの課題の紹介と、その課題を解決するためにパーサーを自作した話を紹介します。
今回のアップデートについては、以下のシリーズ記事でも詳しく解説しています。
- リリース概要: Pure Rustで生まれ変わったPostgreSQL公式構文準拠SQLフォーマッター「uroborosql-fmt」をリリース🎉
- パーサーの置き換え戦略: 半年がかりのパーサー移行を成功に導いた戦略 ~Rust製SQLフォーマッター開発の裏側~
本記事のAppendixではflex・bisonの定義ファイルの構造、2WaySQLのエラー回復について説明していますが、発展的な内容であるため、興味のある方以外は読み飛ばしていただいて問題ありません。
背景
uroborosql-fmt では tree-sitter-sql という CST パーサーを用いてパースしていました2。
開発初期には当時存在したパーサーを調査し最も有望そうなものを選定しましたが、開発を進めるにつれて tree-sitter-sql の課題3が浮き彫りになってきました。
1. サポートされている文法が少なく grammar の改善にも工数がかかる
tree-sitter-sql でサポートされている文法が少なく、フォーマッター改修の際に tree-sitter-sql の変更が伴うことによる工数増や、そもそも tree-sitter-sql に手を入れられる人でないと uroborosql-fmt の改善ができないといった問題がありました。
2. wasm にコンパイルする際に wasm-bindgen を使用できない
tree-sitter は C のコードを出力するため、 FFI で uroborosql-fmt からCの関数を呼び出すつくりになっています。 C への FFI を含むため wasm32-unknown-unknown ターゲットでビルドすることができず、 wasm-bindgen を利用できませんでした。そこで emscripten でビルドすることで wasm にコンパイルしていますが、以下の2点の理由でいまいちでした。
- emscripten でビルドしているのでjavascriptから呼び出す際にシンプルにかけない
- uroborosql-fmt 全体をemscriptenターゲットでビルドするとエラーになるため、tree-sitter-sqlパッケージのみ単体で先にビルドしておくという特殊な手順で何とか回避している
これらの課題を満たすライブラリが存在しなかった4ため自作してみました。
方針
PostgreSQL のパーサーを Rust に porting することで全ての文法をカバーするパーサーを作成することができるのではないかと考え、その方針で進めました。
PostgreSQLのパーサーの流れ
PostgreSQL のパーサー5はこのような構成だと認識しています。
パース過程のイメージ画像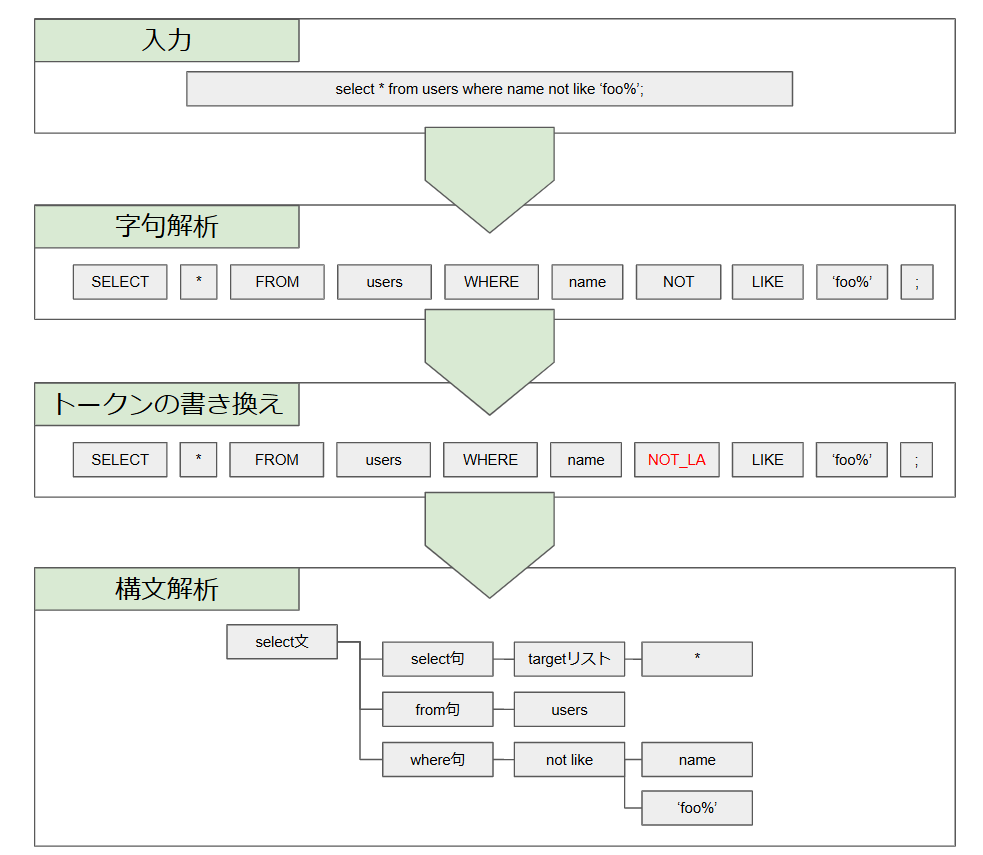
porting の方針
以下の方針で porting を行いました。
- 字句解析器の定義ファイル (scan.l) は規模が小さく更新頻度も高くないため、手で Rust に porting
- トークンの書換え処理も同様に手で Rust に porting
- 構文解析器は定義ファイル (gram.y) をパースし、文法定義から構文解析表を生成しパーサーを生成
- 構文解析表は比較的大きいサイズなので、wasmにした際のサイズを抑えるために圧縮
対応
具体的な対応内容を紹介します。
1. PostgreSQL のソースにパッチ適用
PostgreSQL の素の字句解析器ではコメントはスキップされてしまうため、コメントもトークン化できるよう PostgreSQL のソースに libpg_query のパッチを適用しました
2. 字句解析器の C のソースを porting
字句解析器の定義ファイル (scan.l) に含まれる C のコードを Rust に porting していきました。また、字句解析器の処理で キーワードか否かを判定しているところ があるため、kwlist.hをパースしキーワードの一覧を作成なども行っています。
その後、定義やルールを読み込んで、porting した Rust コードとあわせて字句解析器を生成しました。
flex の定義ファイルの構造についての簡単な説明は、Appendix.1 flex の定義ファイルの構造をご覧ください。
3. 構文解析器の porting
構文解析器の定義ファイル (gram.y) については一切変更を入れず、ファイルの内容を読み込んで構文解析表9を生成しました。
また、構文解析表を基にLR構文解析を実施する処理は bison の porting ではなく独自にLALR法を実装しました。
bison の定義ファイルの構造についての簡単な説明は、Appendix. 2 bison の定義ファイルの構造をご覧ください。
4. 構文解析表の圧縮
構文解析表はサイズがやや大きく、wasm のサイズを小さくするために圧縮して埋め込み、実行時に展開しています。
完成
こちらでデモを用意しているので、興味のある方はぜひ試してみてください。
gram.y で定義された grammar 通りの CST が出来るため決して使い勝手のよい形のツリーではありませんが、PostgreSQLの全ての構文をカバーしており、フォーマッターに利用するものとしては十分なものが出来たと考えています。
また当初想定していなかったメリットとして、2WaySQL で出てくる通常のパーサーではパースエラーとなるような SQL も自然とパースする仕組みを作れるようになりました。
興味があれば Appendix.3. 2WaySQL のエラー回復をご参照ください。
さいごに
最初は実験的なコードの予定でしたが、uroborosql-fmt をより発展させていくためにパーサーを置き替えることになり、約半年かけて置き換えを実施しました。自作のパーサーに置き替えることで PostgreSQL のバージョンアップに追従するコストや保守コストなどがかかってくるため負の側面が大きいことも理解していますが、よりよいツールを開発し、生産性や品質を高めるために頑張っていきたいと思っています。
crateもリリースしておいたので、興味があればぜひ使ってみてください。
Appendix
1. flex の定義ファイルの構造
flex の定義ファイルは以下のような構造になっています。
※ PostgreSQL の定義ファイルの雰囲気を理解できる最低限の内容に絞っています。
定義セクション |
定義セクション
定義セクションでは、字句解析器の状態の定義と、ルールセクションで使用するパターンの定義を行うことができます。
%x で始まる行は字句解析器の状態定義です。
各状態の説明は以下に記載があります。
postgres/src/backend/parser/scan.l at REL_16_STABLE · postgres/postgres
%x xb |
ルールセクションで使用するパターンの定義は以下のように行うことができます。
この例では、数字一桁と数字複数桁の定義である decdigit, decinteger の定義が行われています。
decdigit [0-9] |
ルールセクション
ルールセクションは字句解析器のメインの部分で、状態ごとにルールにマッチした際のアクションを定義することができます。
アクションはCのコードになっており、この中で字句解析器の状態を変更したり、トークンを受理することができます。
特に状態が指定されていない場合は、INITIALというデフォルト状態のパターンとして認識されます。
/* 単一パターンの書き方 */ |
状態遷移の例
アクション部で BEGIN(遷移先の状態) と書くことで、別の状態に遷移することができます。
以下の例では {xcstart} のパターンにマッチした際に、BEGIN(xc) を呼び出すことでC形式のコメント内部を表す xc に遷移しています。
{xcstart} { |
余談
定義ファイルを見ると、これまで知らなかった書き方を知ることがあります。
一例ですが select n'1'; のように文字列の前に n というプレフィックスを付与することが定義できるというのは、この作業を通じて知りました。
この仕様はドキュメントでは見つけられませんでしたが、flex の定義ファイルの以下の部分を眺めることで知ることができ、こういったマイナーな書き方の発見もパーサー作成の面白さの一つだなと感じました。
/* National character */ |
参考
- Lexical Analysis With Flex, for Flex 2.6.2: Format https://westes.github.io/flex/manual/Format.html#Format
- Flex: 3. Flex記述言語 https://web.sfc.wide.ad.jp/~sagawa/gnujdoc/flex-2.5.4/flex-ja_3.html
- Flex - Flex記述言語 https://www.asahi-net.or.jp/~wg5k-ickw/html/online/flex-2.5.4/flex_5.html
2. bison の定義ファイルの構造
bison の定義ファイルは以下のような構造になっています。
※ PostgreSQL の定義ファイルの雰囲気を理解できる最低限の内容に絞っています
%{ |
上の構造はこちら に記載されています。
Bison宣言部
1. tokenの宣言
パーサーで使用するトークンの宣言を行うことができます。
%token <str> IDENT UIDENT FCONST SCONST USCONST BCONST XCONST Op |
2. 結合性の宣言
結合性の宣言を行うことができます。
%leftで左結合、%rightで右結合、%nonassocで無結合を宣言できます。
また優先度が低い順に記載されており、この例では OR より AND の方が優先度が高いことがわかります。
/* Precedence: lowest to highest */ |
文法規則部
以下のような形式で文法規則が与えられます。
非終端記号: ルール1 { アクション1 } |
具体例は以下のようになります。
parse_toplevel: |
各ルールは優先度を持ち、優先度はそのルールにでてくる最後の終端記号と同じになります。
デフォルトとは異なる優先度を設定する場合、以下のように %prec で指定することができます。
SelectStmt: select_no_parens %prec UMINUS |
参考
- Bison 3.8.1 https://www.gnu.org/software/bison/manual/bison.html
- Bison 1.28 - Bison文法ファイル https://guppy.eng.kagawa-u.ac.jp/2019/Compiler/bison-1.2.8/bison-ja_6.html
- Bison入門: 1. Bisonの概念 https://web.sfc.wide.ad.jp/~sagawa/gnujdoc/bison-1.28/bison-ja_4.html
3. 2WaySQL のエラー回復
2WaySQLとは
コメントで制御フローやバインド変数などを記述し、動的に SQL を生成するような実行方法です。動的生成に関わる部分がコメントで記載されており、単体の SQL 文としても実行できるため 2Way と呼ばれています。
上述の通り 2WaySQL は基本的には単体の SQL ファイルとして実行可能になっていますが、時に単体では SQL として実行できないようなケースも存在します。
当社で開発、公開しているOSSである uroboroSQL も 2WaySQL が利用可能なライブラリで、uroborosql-fmt は 2WaySQL のフォーマットもサポートしています。以下の説明では uroboroSQL の 2WaySQL 前提としています。
1. バインドパラメータのサンプル値漏れ
uroboroSQLでは、以下のようにバインドパラメータをセットすることができます。この SQL を uroboroSQL を使わずに実行した場合は name カラムに foo という値がセットされ、uroboroSQL で実行した場合には ‘foo’ は無視され name にバインドした値で置き替えられます。
select |
この ‘foo’ のように、バインドパラメータ等の直後の仮置きの値のことをサンプル値と呼んでいます。
サンプル値が無くても uroboroSQL では実行できてしまうため、以下のようにサンプル値のないSQLが作成されてしまうことがあります。サンプル値漏れのSQLは一般的なパーサーではエラーになってしまいますが、新パーサーではサンプル値漏れでエラーになるケースでエラー回復することができます。
select |
2. 置換文字列のサンプル値漏れ
以下のような置換文字列でも同様にサンプル値が漏れていることがありますが、こちらも同様にエラーを回復することができます。
select |
3. 不要なカンマ
uroboroSQL では、以下のようにselectやorder byの直後に余計なカンマがあっても実行できます10。サンプル値漏れと同様に通常のパーサーではエラーになりますが、新パーサーではこちらもエラー回復し、さらに余計な , を保持した CST を構築することができます。
select |
4. 不要なand/or
uroboroSQL では、以下のように where の直後に余計な and/or があっても実行できます。新パーサーではこちらもエラー回復し、余計な and/or を保持した CST を構築することができます。
select |
- 1.新しいSQLフォーマッターであるuroboroSQL-fmtをリリースしました | フューチャー技術ブログ ↩
- 2.Engineer Camp2022 RustでSQLフォーマッタ作成(前編) | フューチャー技術ブログ ↩
- 3.ANTLR や tree-sitter などを見ると様々な言語のパーサーやグラマーはインターネットには溢れており、パースすることは一軒容易に見えるかもしれません。しかし私の所属するチームでの経験から考えると、対象言語の文法を網羅し実用的なパフォーマンスで動作するパーサーは、公式で提供されているパーサー以外では非常に少ないのではないかと思います。(少なくとも私は出会ったことがありません) ↩
- 4.本パーサーの開発当時、PostgreSQL の CST パーサーでデファクトと言えるものは存在しないようで、 supabase でも独自に CST パーサーを開発 しているようです。ただ、こちらは PostgreSQL の C ソースを含むpg_query.rsを利用していることから wasm にビルドするのは容易でないと考えています。 ↩
- 5.PL/pgSQL は別の grammar が存在するので、本パーサーでは現在サポートしていません。 ↩
- 6.字句解析器は flex を用いて scan.l から生成 ↩
- 7.書換え箇所はこちらです postgres/src/backend/parser/parser.c at REL_16_STABLE · postgres/postgres ↩
- 8.構文解析器は bison を用いて gram.y から生成 ↩
- 9.アクションは無視しているため本来はエラーになるべきSQLがエラーにならなかったりするのですが、それは許容しています ↩
- 10.詳しくは uroboroSQL のドキュメントを参照ください。 ↩