はじめに
こんにちは!フューチャーでアルバイトをしている仲です。Rust 製 SQL フォーマッター uroboroSQL-fmt の開発に携わっています。
先日リリースされた uroboroSQL-fmt ver.1.0.0 では、フォーマッターの中核機能であるパーサーが新しい実装へと切り替わっています。
本記事では、実に半年ほどかけて実現したパーサーの移行の裏側についてお話しします。なぜパーサーを置き換えるに至ったのか説明したのちに、どのようにして安全に移行したのか、具体的な設計や検証の戦略を交えて紹介していきます。
旧パーサー vs. 新パーサー
これまでの uroboroSQL-fmt ではパーサーとして tree-sitter-sql を利用していましたが、開発を進める中でいくつかの課題が明らかになっていました。そのため、今回リリースされた Ver.1.0.0 では postgresql-cst-parser という新しいパーサーへ移行しています。
今回のアップデートについては以下のシリーズ記事でも詳しく解説しています。
- リリース概要: Pure Rustで生まれ変わったPostgreSQL公式構文準拠SQLフォーマッター「uroborosql-fmt」をリリース🎉
- 新パーサーの技術詳細: PostgreSQL 全構文対応の Pure Rust な CST パーサーを作ってみた
移行先の新しいパーサーである postgresql-cst-parser は、 PostgreSQL が内部に持つ Bison の文法定義を利用して Rust のパーサーとして利用できるようにしたツールです。フューチャー社員である山田さんによって開発されました。詳しくはPostgreSQL 全構文対応の Pure Rust な CST パーサーを作ってみた をご覧ください。
本節では、旧パーサーの課題と新パーサーの利点について次に示す3つの観点に基づいて説明します。以下で詳しく説明しますが、新しいパーサーに移行することで、表のとおりすべての課題が解決しています。
| 観点 | tree-sitter-sql | postgresql-cst-parser |
|---|---|---|
| 文法追従コスト | 逐一修正が必要 | PostgreSQL バージョンアップ時のみ対応すればよい |
| WebAssembly 化の容易性 | 低い(ビルドが複雑) | 高い(ビルドがシンプル) |
| パーサーのサイズ | 構文追加で膨れ上がりやすい | 現実的なサイズに収まる |
1. 文法追従コスト
旧パーサーの課題
tree-sitter-sql は PostgreSQL が持つ全ての構文を網羅しているわけではありません。そのためフォーマッターが新しいSQL構文に対応しようとすると、まずパーサー(tree-sitter-sql)自体にその構文を追加する修正が必要でした。これには既存の文法を壊さないよう慎重な検討が求められるだけでなく tree-sitter へ知識も必要となるため、開発におけるボトルネックとなっていました。
新パーサーによる解決策
postgresql-cst-parser はPostgreSQL本体の文法定義から生成されているパーサーです。そのため、原理的に PostgreSQL のほぼ全ての構文を最初からサポートしています。これにより、フォーマッターに新機能を追加する際にパーサーへ手を入れる必要がなくなり、開発者はフォーマット処理そのものに集中できるようになりました。
2. WebAssembly 化の容易性
旧パーサーの課題
uroboroSQL-fmt は WebAssembly 版を提供していますが、tree-sitter は内部に C 言語への依存があるため、wasm-bindgen に代表される Rust 向けのお手軽かつ一般的なツールチェーンをそのまま適用することができません。
そのため旧版では WebAssembly 版を提供するために Emscripten を利用していましたが、ビルドには tree-sitter-sql とフォーマッターを個別にビルドするという複雑な手順が必要でした。(詳細については C/C++を呼び出しているRustのWASM化 をご覧ください。)
新パーサーによる解決策
postgresql-cst-parser は 100% Rustで実装された Pure Rust のライブラリです。そのため、 Rust の標準的なツールチェーンで WebAssembly 化でき、 wasm-bindgen も利用可能です。wasm-bindgen を利用する場合、ビルドプロセスは cargo build と wasm-bindgen の実行だけで完結する単純な構成になるうえ、 JavaScript から呼び出す場合のコードも大幅に簡素化できます。
3. パーサーのサイズ
旧パーサーの課題
tree-sitter-sql は、対応する構文を増やすほど生成されるパーサーのファイルサイズが際限なく大きくなるという問題を抱えていました。フォーク元である m-novikov/tree-sitter-sql では現在挙がっている PR をすべてマージするとパーサーのサイズが 83MB にもなるという指摘がなされており、パーサーのサイズに悩まされている様子がうかがえます。このような事情もあり、uroboroSQL-fmtでは使われない一部の構文を削ることでサイズを抑制しつつ、必要な構文への対応を追加するという構成をとっていました。
新パーサーによる解決策
postgresql-cst-parser は、PostgreSQLの全構文をサポートしながらも、パーサーのサイズを現実的な範囲に抑えることができます。これにより、ファイルサイズを過度に心配することなく、全てのSQL構文をフォーマット対象とすることが可能になりました。
移行を実現した実装戦術
ここからは、新しいパーサーへの移行をどのように実現したのか、具体的な実装レベルでの戦術をご紹介します。影響範囲の大きいパーサーの置き換えを安全に進めるため、「互換API層の実装」「CSTの整形」「独立した並走実装」という3つのアプローチを取りました。これらの戦術が奏功し、移行作業時に大きな問題は発生しませんでした。また、リリースから3週間が経過した現在も移行に起因する不具合は1件も確認されていません。
1. 互換API層の実装
パーサーが持つインターフェースの差異が移行作業に及ぼす影響を低減するため、 postgresql-cst-parser に tree-sitter 互換の API を用意しました。
フォーマット処理の実装にあたり頻出する処理を tree-sitter の場合とできるだけ同じ手触りになるようにしています。
具体的には、goto_parent・goto_first_child・goto_next_siblingといった命令的なノード走査用の API を新たに実装したり、ノードのソースコード上の位置を示す形式を tree-sitter と統一したりしました。
2. CSTの整形
postgresql-cst-parser は Bison の文法定義とほとんど同一の構造を持つCSTを返すため、そのままではフォーマッターとして扱いづらいことがあります。その場合はパーサーが返す木を整形しています。
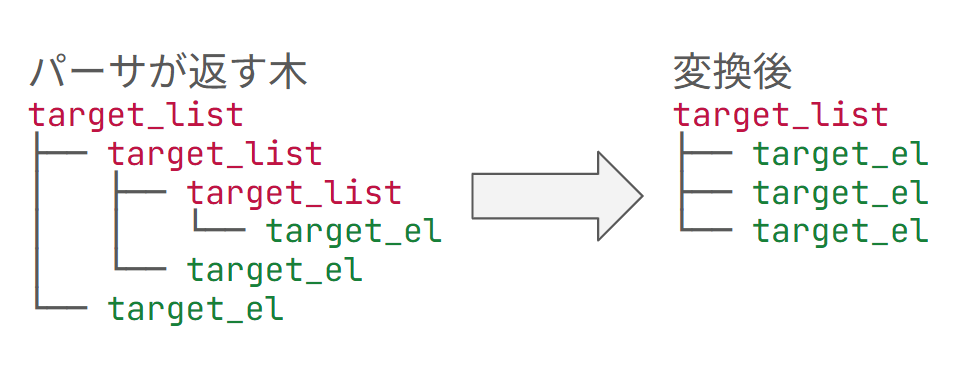
例えば target_list のようなリストを表す構文は、grammar では再帰的に定義されます。
target_list: |
パーサーはこの文法定義に従って再帰的な構造によってリストを表現しますが、このような場合は CST をフラット化することでフォーマッター側から扱いやすくしています。
3. 独立した並走実装
移行作業中は旧パーサー用の処理を丸ごと消して書き換え始めたりはせず、旧パーサーを扱う処理と新パーサーを扱う処理を共存させて実装を進めていきました。これには、次のような意図がありました。
- フォーマットオプションによって新旧パーサーの切り替えを可能にすることで挙動の比較を簡単にする
- パーサー関連の処理以外のバグ修正などを取り込みやすくしておく
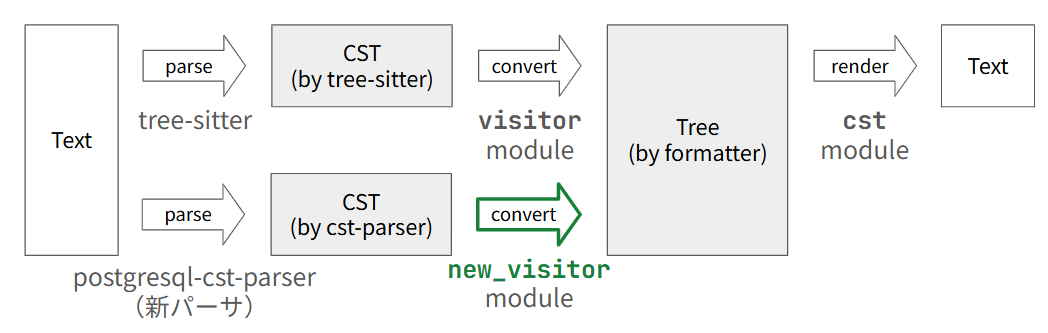
uroboroSQL-fmt の処理の流れは次のようになっており、主な処理はモジュールとして分割されています。基本的にはパーサーが返す CST を走査してフォーマッター用の木構造に変換する visitor モジュールと、フォーマッター用の木構造を定義し、フォーマット結果の書き出しまで行う cst モジュールから構成されます。(図はパーサー置き換え前のものです)

次の図は、パーサー移行中の構成を示したものです。移行にあたっては、visitor モジュールと並ぶ new_visitor モジュールを新たに作成し、新パーサーに依存する処理はこのモジュールに閉じる形で実装しました。これにより移行中は新旧版のフォーマッターを共存させてフォーマットオプションでのパーサー選択を可能にする構成としていました。
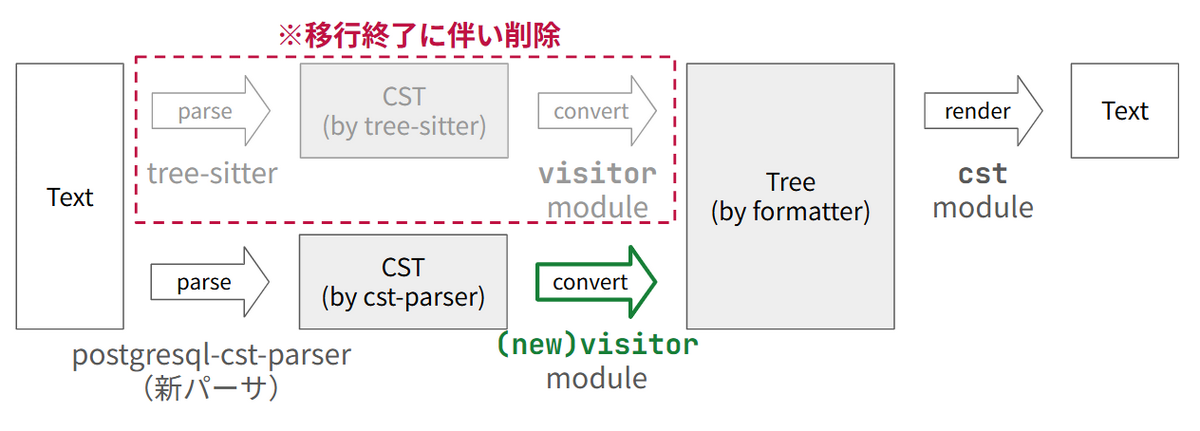
また、移行作業終了時には旧パーサー用のモジュール(visitor)を丸ごと削除することで簡単にクリーンアップができます。
安全に移行を進めるための検証設計
前節で述べたような実装戦術と並行し、移行の安全性を担保するための検証も入念に行いました。
パーサーという根幹部分の置き換えでは意図しないリグレッション発生のリスクが常に伴います。そこで、実装によって生じうるリスクを確実に潰していくため、「安全に小さく進める」という方針のもとで検証プロセスを設計しました。
具体的には、次のような三段構えとしました。
- 段階的なE2Eテストで外部仕様を固定する
- カバレッジ計測で進捗と抜け漏れを可視化する
- 実データ(社内の複数プロジェクトに存在する大量のSQL)でリグレッションを洗い出す
それぞれについて以下で詳しく説明します。
1. 段階的なE2Eテストの利用
移行作業を安全かつ着実に進めるため、既存のテストケースとは独立した移行用のテストを新設し、それを起点にテスト駆動での実装を進める方針を取りました。
このテストでは入力と期待値にそれぞれ SQL 文を用意し、フォーマッターの挙動をエンドツーエンドで確認しながら実装に伴ってテストケースを増やしていきます。小さくはじめて、徐々に対応範囲を広げていくイメージです。
具体的には select のような最も単純なSQLから始めて、 select 1; → select a; → select a,b; → select a,b from t; のように機能を一段ずつ拡張していきました。それぞれのテストケースはこのように独立したファイルとして管理し、テストから読み込んで利用しています。
また、テストごとの結果を個別に表示して、すでに実装した機能に及ぼす影響を確認できるようにしています。
Testing: 001_select |
さらに、フォーマット結果の差分がすぐに把握できるよう、 similar クレートを活用した Diff 表示機能なども導入していました。
2. カバレッジ管理
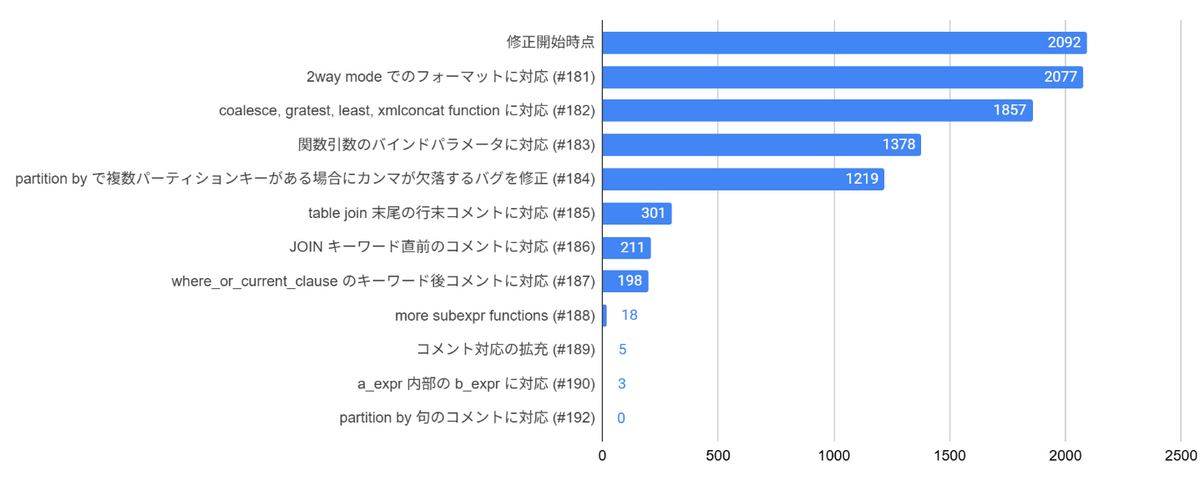
移行の拡大に伴い、進捗報告とタスクの整理が課題になることが見込まれました。そのため「現在の進捗がどの程度か」や「次に何を実装すべきか」の目安を判断する指標としてカバレッジ計測を取り入れました。
ここでのカバレッジは「既存のテストケースを新パーサーの実装がパスする割合」のことを指しています。既存のテストケース群に対して新パーサーでのフォーマット処理を実行し、その結果を逐一集計していました。
次のようなカバレッジレポート表示を実装することで進捗が一目でわかります。
Coverage Report: |
また、カバレッジ計測時に生じたエラーの原因を収集・分類することで次に対応すべき機能を決めたりしていました。
Failed Cases (by error type): |
3. 実データでの検証
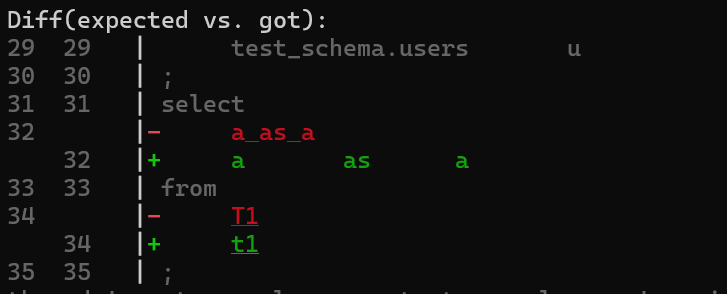
移行作業の最終段では、社内で実際に利用されている SQL を用いてリグレッションの検証を行いました。5400 件ほどのSQLファイルを新旧フォーマッターでそれぞれフォーマットしてしてエラーを集計・分析し、デグレを洗い出しつつ修正対応を進めました。
パーサーが違えば返すCSTも異なるため既存のテストケースでは不足だろうとの試算はあったものの、実際の検証では実に半数ほどのSQLで1つ以上のエラーが見つかりました。
修正の都度検証を実施し、発生したエラーを集計して確認して影響範囲の大きいものから対処していくことで着実にリグレッションを減らしていきました。
新旧フォーマッターの比較
最後に、新旧フォーマッターの実行ファイルのサイズとパフォーマンスについて比較した結果を報告します。
1. 実行ファイルのサイズ
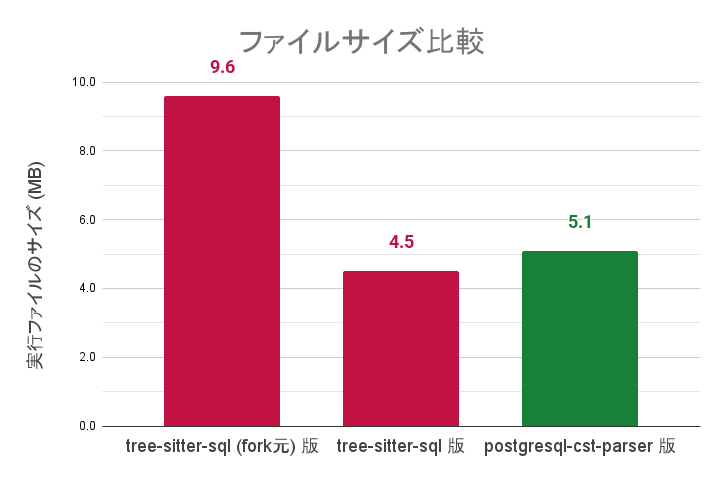
実行ファイルのサイズ比較結果を以下に示します。新パーサーを利用しているバージョンのフォーマッター(グラフ右)では、旧パーサーの場合(グラフ中央)に比べて0.6MBほど増加しています。
ただし、旧パーサーである tree-sitter-sql は対応文法追加のためにあまり使われない構文を削ることでサイズを抑えている事情があります。サイズを抑える前の tree-sitter-sql を利用する場合は9.6MB(グラフ左)となり、2倍近い数値です。この点を踏まえれば、ファイルサイズを大幅に増やすことなくすべての文法に対応できたという意味で好ましい現象であると考えています。
2. パフォーマンス
フォーマッターの性能をより実態に即して評価するため、社内で実際に使われているSQLファイル約5400件を用いて、新旧パーサーの1ファイルあたりの処理時間を比較しました。
計測結果の統計値は以下の通りです。
| 旧版 (ms) | 新版 (ms) | 新版 / 旧版 | |
|---|---|---|---|
| 平均値 | 1.822 | 3.744 | 2.1 倍 |
| 中央値 | 0.872 | 1.965 | 2.3 倍 |
| 最小値 | 0.033 | 0.224 | 6.8 倍 |
| 最大値 | 78.587 | 160.410 | 2.0 倍 |
結果を見ると、平均値・中央値ともに新パーサーは旧版に比べ処理に約2倍強の時間がかかる傾向が見られます。
最も性能差が大きかったケース(最小値)では約6.8倍の時間がかかっていますが、これはもともとの処理時間が非常に短いSQLのため比率が大きくなったもので、絶対時間としては0.224ミリ秒とごくわずかです。また、最も時間のかかったケース(最大値)でも処理時間は約160ミリ秒でした。
このような結果は PostgreSQL の全構文への対応に対するトレードオフであると捉えています。多数のファイルで計測した結果からも実用上のパフォーマンスは十分に維持できており、ユーザー体験を損なうものではないと考えています。
さいごに
本記事では、uroboroSQL-fmt のパーサーを tree-sitter-sql から postgresql-cst-parser へと移行したプロジェクトについてご紹介しました。
テストや継続的な計測・検証について工夫して実装しながら実現していく作業は技術的にも非常に面白く、大規模な書き換えを楽しみながらやり遂げることができました。
パーサーの問題を克服した uroboroSQL-fmt ですが、フォーマッターとしてはまだまだ対応できていない構文も多く残っています。バグ報告や機能要望など GitHub にて歓迎していますのでぜひ一度お試しください。