PostgreSQL18連載の5本目の記事です。
はじめに
こんにちは、CSIG (Cyber Security Innovation Group) の市川です。
本記事では、私が現場で行った PostgreSQL のパフォーマンスチューニングについて、原因調査から解決までのプロセスを共有します。この記事が、「なぜか適切な実行計画が選ばれない、インデックスが使われない」といった同様の問題に直面している方の助けになれば幸いです。
また、今回の鍵となった n_distinct という統計情報の計算方法について、Appendix に考察を記載しているので、合わせてご一読ください。 (不適切な記載がある場合は、ご指摘いただけますと幸いです)
まず本記事の要点として、発生した問題と解決策の要約を紹介します。
発生した問題と解決策の要約
- 問題: 4 億件のレコードを持つ
childsテーブルをスキャンする際、インデックスがあるにも関わらずSeq Scanが実行され、特定のクエリがタイムアウトしていた - 原因:
ANALYZEで収集される統計情報であるn_distinct(カラム内のユニークな値の数)が、実態と大きく乖離していた。この乖離により、PostgreSQL が「1 つのparentに大量のchildが紐付いている」と誤認し、その誤認に基づいてクエリ実行のコストを計算してしまったため。 - 解決策:
- 採用した案:
random_page_costを下げて、相対的にIndex Scanが選ばれやすいようにコストを調整する。n_distnctを手動変更し、統計情報を直接実態に近づけることで、根本原因を解消する
- 不採用とした案:
- hint 句を用いて、Index Scan を強制する
- 統計情報を計算する際にサンプリングされる行数を増やす (= stats target を増やす)
- 採用した案:
前提の説明
前提1 : 本記事の問題が発生した環境
- バージョン : PostgreSQL 15.5
- 環境 : Amazon Aurora
前提2 : 本記事に登場するテーブル
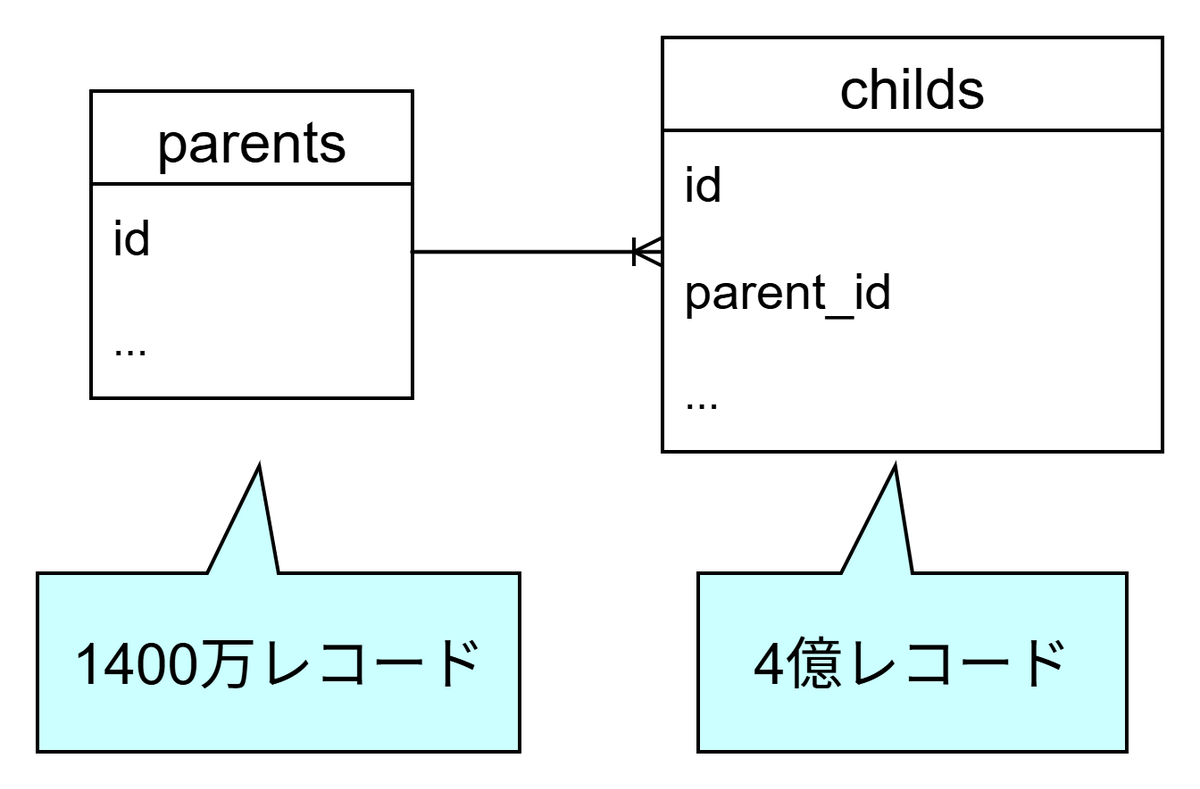
今回の話では、 parents テーブルと childs テーブルが登場します。
大体のレコード数とカラム名だけ頭の片隅に置いておいていただけると、この後の話が入ってきやすいかと思います。
本題: 発生していた問題の原因と、解決するためのアプローチの比較検討
本節では、
- ① 発生していた問題
- ② 問題が発生していた原因
- ③ 解決策の選択肢
- ④ 各案の比較検討と、最終的な選択
を順に説明します。
① 発生していた問題
問題となっていたのは、複数の parent_id に紐づく child を一括で取得する、以下のような単純なクエリでした。 (ARRAY 内には、 parent_id の可変長配列が入ります)
SELECT * FROM childs WHERE parent_id = ANY (ARRAY[...]); |
parent_id カラムにはインデックスが設定されていましたが、なぜか Index Scan や Bitmap Heap Scan ではなく、 Seq Scan が走ってしまっていました。
結果、クエリの実行に約 68 秒もかかってしまっていました。
hoge=> explain (analyze, buffers) select * from childs where parent_id = ANY (ARRAY[:parent_ids_array]::bigint[]); |
ちなみに、Seq Scan を off にすると、 1 秒程度でクエリ実行が完了しました。
このことから、Seq Scan は不適切な実行計画だったことが分かります。
hoge=> set enable_seqscan = 'off'; |
上記の結果は、オプティマイザが「インデックスを使うよりもテーブルを全件スキャンする方がコストが低い」と誤って判断してしまったことを意味しています。
なぜオプティマイザが誤った判断をしてしまい、適切な実行計画が選択されなかったかを突き止める必要がありました。
② 問題が発生していた原因
調査の結果、Seq Scan が過度に選ばれてしまった原因は、 n_distinct と呼ばれる統計情報が実際の値と乖離していることであると分かりました。
n_distinct とは
テーブル内でのユニークな値の個数を表す統計情報です。
詳細は、 pg_stats のドキュメント をご覧ください。
n_distinct が正の値の場合、その値がそのまま列内のユニークな値の推定数を示します。n_distinct が負の値(-1.0 ~ 0) の場合、(実際のユニークな値の数 / 全行数) * -1 の値、つまりテーブル全体に対する割合として扱われます。例えば、 n_distinct=-0.1 の場合、ユニークな値の数は全体のレコード数の 1/10、と推測されます。
childs.parent_id カラムの n_distinct は以下の通りでした。
hoge=> SELECT n_distinct FROM pg_stats WHERE tablename = 'childs' AND attname = 'parent_id'; |
PostgreSQL のオプティマイザは、「この parent_id カラムには約 6.7 万個しかユニークな値が存在しない」と認識していました。つまり、各 parent に 4 億/6.7 万 ≒ 6000 個の child が紐づいている、と認識されていた訳です。
実際に、1 個の parent に紐づく child を取得する SQL の実行計画を見てみると、 rows=5951 と予想されています。これは、「1 つの parent に紐づく child を取得する場合、5951 個の child が取得される」とオプティマイザが予測していることを意味しています。
hoge=> EXPLAIN SELECT * FROM childs WHERE parent_id = 8887212; |
一方で、実際の parent_id のユニーク数は約 1400 万 (= 1 parent あたりの child 数は約 25 個) であり、統計情報の値と大きく乖離していました。
hoge=> select count(distinct parent_id) from childs; |
この不正確な n_distinct の値により、オプティマイザによって seq scan が過度に選ばれやすい状況になってしまっていました。
③ 解決策の選択肢
根本原因が統計情報の不正確さにあると分かったところで、いくつかの解決策を考えました。
A 案: random_page_cost の調整
この案は、 Index Scan が選ばれやすくなるように、 random_page_cost と呼ばれる値を下げる方向に調整するアプローチです。
PostgreSQL のコスト計算には、ディスクアクセスのコストを以下のパラメータで制御しています。
seq_page_cost: シーケンシャルアクセスのコスト(デフォルト: 1.0)random_page_cost: ランダムアクセスのコスト(デフォルト: 4.0)
ランダムアクセスのコストがシーケンシャルアクセスのコストよりもかなり大きめに設定されているのは、デフォルト値が HDD を想定しているためです。 (HDD は、ランダムアクセスのコストが大きい)
しかし、データベースのディスクが SSD の場合、実際のところランダムアクセスのコストとシーケンシャルアクセスのコストの差はそこまで大きくありません。
そのため、SSD の場合は random_page_cost を 下げる(例: 1.1)ことによって、より実際のディスクアクセスコストに即した実行計画が選ばれるようになります。
random_page_cost を下げると、ランダムアクセスのコストが低く見積もられるようになるため、 Index Scan が選ばれやすくなります。そのため、データベースのディスクが SSD の場合は、変更を検討する価値があるパラメータです。
seq_page_cost と random_page_cost について、詳しくは PostgreSQL 公式ドキュメント: 問い合わせ計画 を参照してください。
B 案: stats target の引き上げ
stats target とは
stats target とは、「統計情報」を取得する際にサンプルする行数を示す値です。
0~10000 まで設定でき、デフォルトは 100 です。 ANALYZE の際にサンプリングされる行数は stats target * 300 で決定されます。
この案は、ANALYZE 時のサンプル数を増やすことで、 n_distinct の精度を上げ、実際のユニーク数に近づけるアプローチです。
以下のような SQL を実行することにより、変更した stats distinct に基づいて統計情報が計算されるようになります。
ALTER TABLE childs ALTER COLUMN parent_id SET STATISTICS 1000; |
C 案: n_distinct の直接設定
この案は、 n_distinct を実際のユニーク値に近い値に直接書き換えてしまおう、というアプローチです。
PostgreSQL では、n_distinct の値を直接上書きすることも可能です。
詳しくは ALTER TABLE のドキュメント > SET (attribute_option) の項 を参照してください。
-- n_distinctを正の値にすると、その値が採用される |
② 問題が発生していた原因 節の再掲にはなりますが、n_distinct を負の値 (-1.0 ~ 0) に手動変更することで、テーブル全体に対するユニークな parent_id 数の割合を示すこともできます。例えば、 n_distinct=-0.1 に設定することで、「ユニークな parent_id の数は全体のレコード数の 1/10 である」、とオプティマイザに推測させることができます。
D 案: pg_hint_plan を用いて、スキャン方法をを強制する
この案は、「ヒント句」を用いて特定のクエリに対してスキャン方法を強制するアプローチです。
pg_hint_plan は、ユーザー側で実行計画を制御するためのツールです。pg_hint_plan というエクステンションを導入した上で、SQLコメント内にヒント句 (/*+ IndexScan(childs) */ など) を書くことで、スキャン方法や JOIN の方法を強制することができます。
詳細は pg_hint_plan のドキュメント > スキャン方法 などを参照してください。
-- 以下のようなコメントを付すことで、 childs のスキャン時に Index Scan が使用されるよう固定される |
④ 各案の比較検討と、最終的な選択
[不採用] D 案 (ヒント句) について
D 案は、オプティマイザの挙動に拠らずスキャン方法を指定できるため、想定している実行計画をオプティマイザに選ばせやすく便利ですが、以下の理由から不採用としました。
- 現在使用している ORM に組みこむのが難しかった。現状のアプリケーションコードに組み込むには、 ORM を最大限利用した現在の書き方から生の SELECT 文に書き換える必要があり、アプリケーション側の変更が大きくなってしまいそうだった。
- 統計情報を改善しないと、別の箇所で
childsをスキャンする際にも同様の問題が発生する可能性がある。そのため、統計情報の改善によって根本的に解決できるのであれば、統計情報の改善の方が望まれる。
[採用] A 案 (random_page_cost の調整) について
現在稼働しているシステムでは SSD ボリュームの DB を使用しています。A 案は SSD ボリュームで実施する分にはデメリットが特になさそうだったため、開発環境でしばらく運用して問題が発生しないことを確認した上で、採用することにしました。
ただし、A 案を採用しても Index Scan が選ばれやすくなるだけで、統計情報自体が改善される訳ではありません。そのため、指定される parent 数が多いと結局 Seq Scan が選ばれてしまう、という状況でした。
よって、統計情報を改善する施策である B 案と C 案についても検討し、いずれかの方法も合わせて採用する必要がありました。
B 案 (stats target の引き上げ) の現実性について検討
B 案 による解決が可能かを判断するため、 childs テーブルで、 stats target にさまざまな値を指定して、実際の n_distinct と ANALYZE の時間を計測しました。以下がその結果です。
| stats target | n_distinct | ANALYZE に かかる時間 |
|---|---|---|
| 100 (デフォルト) | 6.7 万 | 25 秒 |
| 200 | 9 万 | 45 秒 |
| 500 | 15 万 | 62 秒 |
| 1000 | 22 万 | 114 秒 |
| 2000 | 24 万 | 362 秒 |
| === | === | === |
| 実際のユニーク数 | 1400 万 | - |
stats target を大きくしていくことで n_distinct が実際のユニークな数に近づいてはいますが、依然として大きな乖離があることが分かります。
ただ、 stats target を 2500 まで引き上げると、現状実行されうるすべてのクエリに対して Index Scan が選ばれるようになることはわかりました。 (stats target を 2500 にしたの際のデータは掘り起こせなかったため載せていません。申し訳ありません。)
なお、この「可能か」というポイントに加えて、stats target を大きくすると ANALYZE の時間が伸びてしまう、というデメリットも検討に入れる必要のあるポイントです。
C 案 (n_distinct 手動変更) による保守性の低下についての検討
この案は、統計情報を手動で無理やり変更する方法なので、テーブルの肥大化により実際のデータと乖離が生じる可能性がある、というデメリットを抱えていました。
ただ、今回のケースは少し特殊で、 「将来データが増加した場合でも、parents と childs のレコード数の比率は大きく変動しない」という特徴を持ち合わせていました。このデータ特性は、 n_distinct を割合として設定できれば、ある程度の保守性を担保できることを意味しています。
この考察から、 n_distinct に負の数 (=割合) を設定すれば、データが増えてもある程度の保守性を担保できると判断しました。
B 案 (stats target) と C 案 (n_distinct 手動変更) の比較
上記の B 案と C 案の検討を元に、統計情報自体を改善する方法として、 B 案 と C 案の採用についてそれぞれ検討しました。
以下のようにメリデメを整理しました。
| 方針 | 解決可能か | 保守性 | analyze の時間 |
|---|---|---|---|
| B 案: stats target を大きくする (< 2000) | △ (parent_id が多いと Seq Scan が 選ばれてしまう) |
△ (自動更新だが、将来のデータ増で再調整の可能性あり) |
増加する |
| B 案: stats target を大きくする (> 2500) | ○ | △ (自動更新だが、将来のデータ増で再調整の可能性あり) |
大幅に増加する |
C 案: n_distinct の手動変更 (正の数) |
○ | × (手動設定。データ増で実態と乖離する) |
変化なし |
C 案: n_distinct の手動変更 (負の数) |
○ | △ (手動設定だが、割合指定なのでデータ増に強い) |
変化なし |
最終的な選択
上記のメリデメの表と n_distinct に関するデータモデルの考察より、最終的に「A 案: random_page_cost の調整」に加えて、 「C 案: n_distinct の手動変更 (負の数)」を採用することにしました。
実施内容と効果
上記の案を実施したことで、 parent_id が多い場合でも Index Scan が選ばれるようになりました。
まとめ
本記事では、4 億件超のレコードを持つテーブルで発生したパフォーマンス問題について、調査から解決までのプロセスを共有しました。
今回の問題の核心は、PostgreSQL の統計情報(特に n_distinct)が実態と乖離していたことでした。
この問題を解決するための策を複数列挙し、比較検討を行いました。
今回は 「C 案: n_distinct の手動変更」を最終的な解決策としましたが、アプリケーションやテーブルの規模によって、「B 案: stats target を大きくする」や「D 案: pg_hint_plan を活用する」も最善の改善策になりうると思います。
改善策を複数考え、その場の状況に最も即した改善策を取ることが重要だと思います。
本記事が、同様の問題に直面している方の一助となれば幸いです。
Appendix: n_distinct の計算方法についての考察
(以下の考察は統計学に基づいたものではないため、不正確な記述を含んでいる可能性があります。間違いや不適切な記述がある場合は、ご指摘いただけると幸いです)
n_distinct は、 ANALYZE を実行した際に以下の式で計算されます。(コード内の stadistinct が n_distinct を表しています)n_distinct の計算方法について、詳細は postgres/~/analyze.c のコード を確認してください。
/* Count the number of values we found multiple times */ |
この計算式では、以下のようなデメリットがあるように感じました。
Nが分母に含まれないため、Nの大きさがn_distinctに反映されにくいf1が相当大きくないと、上限がnの整数倍で抑えられてしまう- 例えば、
f1=(9/10)*nだった場合、n_distinct≦10d≦10n
- 例えば、
以下のページの著者も同様の課題を報告しており、 「n_distinct=d*N/n というナイーブな式の方が精度が高いのでは」と提言を行っています。
https://www.postgresql.org/message-id/4338f834-dee9-2eb8-0577-10abe9d39e2d%40postgrespro.ru
この式をそのまま利用することは難しいと思いますが、少なくとも d がある程度大きいのであれば、上記のナイーブな式を用いた方が精度が良くなるのではないかと感じました。