はじめに
はじめまして。2023年10月にキャリア入社した篠原です。
これまではシステム開発がメインでしたが、最近データ分析の業務に関わらせていただく機会がありました。そこで求められる成果物、注力すべきポイント、そして技術選定の観点など、従来のシステム開発とは異なる部分が多く、様々な気づきがありました。
自身の振り返りも兼ねて、その知見を共有したいと思います。
なお、データ分析の目的と流れについてはこちらの過去記事も併せてご覧ください。
データ分析で求められるものと意識すること
会社や組織が意思決定を行う上で様々な手法がありますが、データを用いた定量的分析は重要な判断材料となります。
- 「どこに施策を打つのが効果的だろうか」
- 「施策を打った結果、どのような効果があったのか。その結果を元に今後の動きを考えたい」
こうした問いがある際、「正確さ」はもちろんですが、次のアクションへ繋げるために「スピード」も重要になる場面が多いです。これらの問いに正確かつスピーディーに答え、提案するには、分析そのものに全力を注ぐべきであり、ツール選定や環境構築、分析の実装における「不安定な要素」は極力取り除くべきです。
実際にデータ分析を通して、これらの不安要素を取り除くために気をつけるべき点をお話しします。
検証環境:
OS: Ubuntu 22.04.5 LTS (WSL使用) |
分析で使用するツール(言語)の特徴を理解して使い分ける
データ分析に使用される技術としては Python (pandas)、R、RDB (PostgreSQL、SQL) などが挙げられます。
これらは「分析ができる」という点は共通していますが、得意分野が異なるため、状況に応じて使い分けることが重要だと感じました。代表として Python と RDBの特徴を比較します。
| 観点 | Python | RDB |
|---|---|---|
| 構築の手軽さ | 非常に手軽。Python導入済みなら pip install のみ。 |
RDB自体のインストールとデータ投入(DDL/DML)に手間がかかる。 |
| 分析の手軽さ | Notebookを使用することで、読み取ったデータを逐次実行しながら試行錯誤が可能。 | 基本的に1つのSQLで処理を書き切る必要があるため、試行錯誤のサイクルは少し重い。 |
| 大規模データの分析 ※ | メモリに全データを載せるため、大規模データではメモリ不足に陥りやすい。 | ディスクベースで処理し、必要分をメモリに載せるため、メモリ不足に陥りにくい。 |
| 計算速度 | 高速(ただし書き方に依存)。 | Indexを活用できれば非常に高速。 |
| 使用難度 | 低。CSV等をDataFrame化し、都度加工が可能。 | 中。複雑な集計を1SQLで完結させる必要があり、クエリが複雑になりがち。 |
| データ型の管理 | 推定で判断されるため、意図しない型変換による結合エラー等が起きうる。 | テーブル定義で型が厳密に管理されているため、堅牢。 |
| 他ツールへの連携 | DataFrameをそのまま機械学習や可視化ライブラリへ連携可能。 | 別途考慮が必要。 |
※なお、PythonでTB級などのさらに大規模なデータを扱う場合は、DaskやPySparkといった分散処理ライブラリの利用が選択肢に入ります。今回はローカル環境(メモリ16GB程度)で完結する規模の分析を前提としていることと、DaskやPySparkにもある一定のキャッチアップが必要ということも考慮し、既にメンバーの経験があるpandasを使用しています。
以上の特徴を踏まえて、pandas と RDB は下記のように使い分けると分析がスムーズでした。
- RDB を使用すべき場面
- 分析対象や期間が定まっておらず、大容量データに対して探索的に分析する場面
- 詳細な分析の前に、大規模なマスタやトランザクションデータを結合し、中間データを準備する場面
- pandas を使用すべき場面
- データの準備が整ってからの、詳細な加工や分析が必要な場面。
- データ規模が小さく、複雑な結合が不要な場面。
- 可視化や機械学習へのパイプラインとして使用する場面。
データ型については、pandasでCSVを読み取る場合も、dtypeで型を指定できますが、多くのカラムに対しての指定する場合、小規模の分析の場合でもコード数が増えやすいです。
m_product_df = pd.read_csv( |
そのため、型定義が重要かつ、複雑な局面はなるべくRDBで実装をする方が、考慮すべき点も少ないと感じました。
当初は「早く結果を出したいので、慣れている pandas を使おう」という判断で進めていましたが、大規模データの分析では考慮すべき点が増え、かえって時間がかかってしまうことがありました。
また、小規模な分析であれば Excel の方が直観的に操作でき、可視化まで完結する場合もあります。分析を始める前に、チーム内で適切な技術やツールを検討することをお勧めします。
これまでの分析の流れを図示しておく
分析業務では詳細な設計書を作成する時間は確保しにくいですが、データの流れを図示してチーム内で共有することをお勧めします。
データ分析では、分析した結果を基に話し合いそれを受けてさらに詳細な分析や、別角度からの分析を重ね最終的な結論を出すというパターンが多いと思います。
ER図としては複雑ではなくとも、仕様変更や追加の要望が来る頻度は高く、それが重なってくると今までの経緯が抜け落ちやすくなり、「この値は何のために出すんだっけ?」と目的がわからなくなってしまうこともあります。
それを防ぐためにも簡易的な図示でも良いので、これまでの分析の経緯と決定事項、PGのデータの流れを記載しておくことは非常に有効と考えます。図の体裁の善し悪しは重要でなく、メンバー全員が1つの図を指しながら、今までの決定事項と立ち位置を理解して次のアクションを考えることが重要です。
処理速度に固執しすぎず、一般的に速くなる技法を持っておく
分析コードやクエリの実装において、パフォーマンスは重要です。システム開発同様、処理が遅すぎると業務に影響が出ます。
しかし、データ分析のコードは「毎日頻繁に実行される」とは限らず、「1回きりの実行」になることも多々あります。
パフォーマンスチューニングは突き詰めるとキリがありません。全ての処理を限界まで高速化しようとすると膨大な工数がかかってしまいます。そのため、「これをやっておけば間違いなく速くなる」という定石テクニックの適用にとどめ、特に1回きりの分析であればそれ以上の深追いはしないという割り切りが重要です。
その技法を一通り実装し、それでも許容できないほど遅ければ初めて追加のチューニングを検討する。このスタンスが、工数とパフォーマンスのバランスとして最適解だと感じました。
内容はpandasに寄っていますが、その技法を一部ご紹介させていただきます。
1. 取得するカラムは必要なもののみに絞る
取得するカラムを絞ることの必要性は、SQLだけではなく、pandas でも同様です。
pandas は読み取ったデータをメモリ上に展開し、処理の過程で新たな変数を生成します。そのためメモリが枯渇しやすい傾向にあります。速度面だけでなく、メモリ使用量の観点からもカラムの絞り込みは意識すべきです。
例えば、5000万レコード・20カラムのデータを全件読み込むと、以下のようにメモリ不足でプログラムは落ちることがあります。
import psutil |
usecols を使用して必要なカラムのみ読み込むことで、メモリを節約できます。
# 時間やメモリ計測の関数やラッパーは省略 |
出力結果(例):
[BEFORE LOAD] RAM Status: |
2. ループ処理は避け、集約関数を活用する
pandas において、for ループによる行ごとの処理は非常に低速です。
以下は、10万レコードのデータに対して product_id ごとの集計する比較です。
【for文を用いて行う場合】 実行時間: 約91.37秒
# merge_df: 結合済みの元データ |
【集約関数 (groupby) と merge を用いて行う場合】 実行時間: 約0.06秒
result_df = merge_df[ |
pandas は Python の構文(for文やif文)を使っても実装できますが、集約関数を用いた計算は圧倒的に高速です。
チームメンバーが pandas に不慣れで groupby を自由に扱えなくても、多少の時間を割いてでも扱えるようになることはデータ分析では重要となります。
出力すべき粒度を意識する
分析の実装に没頭すると、目の前のデータ処理にリソースが割かれ、本来の目的と逸れて分析してしまうこともあり得ると思います。
これを防ぐために、常に「出力すべき粒度(分母)」の認識合わせを行うことをお勧めします。
具体例として、「クーポンを発行すべき商品」を選定するケースを考えます。
- 売れている商品は、さらにクーポンを発行して販促する。
- 全く売れていない商品も、試験的にクーポンを発行して効果を見る。
この方針に対し、単に売上データだけを集計してしまうと、落とし穴があります。
# 売上データ(sale_df)のみをベースに集計 |
出力結果:
| product_id | total_qty | mean_price | total_coupon_sale_qty | coupon_sale_ratio |
|---|---|---|---|---|
| 33 | 1 | 6879 | 0 | 0 |
| 197 | 1 | 32302 | 0 | 0 |
| 322 | 1 | 14283 | 0 | 0 |
| 977 | 1 | 14648 | 0 | 0 |
| 994 | 1 | 43825 | 0 | 0 |
| 1711 | 1 | 46073 | 0 | 0 |
| 1825 | 1 | 49039 | 0 | 0 |
| 2138 | 1 | 18128 | 0 | 0 |
| 2484 | 1 | 4507 | 0 | 0 |
| 2890 | 1 | 4466 | 0 | 0 |
この結果には、「一度も売れていない商品」が含まれていません。売上テーブルには実績があるデータしか存在しないためです。
これでは、「全く売れていない商品にクーポンを発行してみる」という施策の対象が抜け落ちてしまいます。
正しくは、「全商品マスタ」を主軸(左側)に置き、そこに売上データを結合(Left Join)する必要があります。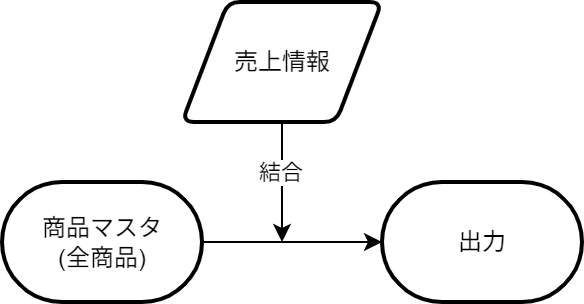
# 検証対象とすべき粒度の全データの枠(商品マスタ)を作成 |
出力結果(マスタ主軸):
| product_id | regular_price | total_qty | mean_price | total_coupon_sale_qty | coupon_sale_ratio |
|---|---|---|---|---|---|
| 50 | 77052 | 0 | 0 | 0 | 0 |
| 151 | 80856 | 0 | 0 | 0 | 0 |
| 319 | 91912 | 0 | 0 | 0 | 0 |
| 325 | 86916 | 0 | 0 | 0 | 0 |
| 425 | 23177 | 0 | 0 | 0 | 0 |
| 435 | 93272 | 0 | 0 | 0 | 0 |
| 461 | 26445 | 0 | 0 | 0 | 0 |
| 466 | 52490 | 0 | 0 | 0 | 0 |
| 713 | 24460 | 0 | 0 | 0 | 0 |
| 825 | 22449 | 0 | 0 | 0 | 0 |
このようにマスタを主軸にすることで、売上実績がない商品もリストアップされました。これにより、「売れていない商品群」を正しく把握し、施策検討のテーブルに乗せることができます。
この意識を持って実装すると、コードの構成は自然と出力すべき粒度のベースリストを作成し、そこに各指標を順次結合していくという形になると思います。
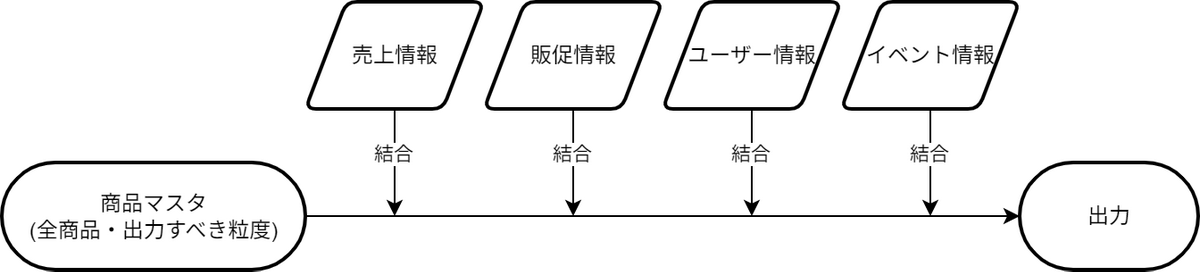
このスタイルの利点は、第三者が見ても「最終的に何の粒度で集計したいのか」が一目瞭然であることです。また、分析項目の追加要望があった際も、複雑な加工を経た変数の状態を追いかける必要は無く、常にこの「ベースリスト」に対して新たな計算結果を結合するだけで済むため、変更に強く拡張性の高いコードになります。
話を聞くと単純なことかもしれませんが、いざ分析に入ると陥りやすい内容となりますので、ぜひ意識をしてみてください。
まとめ
データ分析での業務を振り返り気づいた、品質高くスピーディーに結果を出すために技術的に留意すべきことをまとめました。
システム開発とは異なり、事前に入念なインフラやPGの設計がされているわけではなく、その状況下で大量データを分析し、より一層スピーディーに結果を出すことは難しいと感じるかもしれません。
そういった場合でも、焦ってすぐに分析に取り掛かるのではなく一度立ち止まり、現在は何を知りたい場面か・何を出力すべきか・そのために何を使用すべきかを、考えてから動くことが結果を出す近道だと感じました。