はじめに
こんにちは。Strategic AI Group (SAIG) の藤井です。
この度、3/9 (月) 〜 3/13 (金) に栃木県は宇都宮市で開催された言語処理学会第32回年次大会 (NLP2026) において、光栄なことに主著論文 TimeMachine-bench: LLMは「あの日」のコードを最新環境に適応できるか? が若手奨励賞に選出されました。
論文の審査を担当いただきました関係者の皆様にこの場をお借りして感謝いたします。
本記事では、当該論文、およびその拡張版であるEACL2026 (Main Conference) 採択論文 TimeMachine-bench: A Benchmark for Evaluating Model Capabilities in Repository-Level Migration Tasks (3/24 〜, モロッコ・ラバトにて開催) を著者として解説します。
背景
研究や業務でプログラムを書く人であれば、誰しもがこんな経験をしたことがあるのではないでしょうか?
あれ、昨日までは動いていたのに… 何もしてないのに壊れたー!
我々 (あるいはAI) が日頃書くプログラムは、その多くが外部のライブラリに依存しています。例えば、 transformers や pytorch、openai といったライブラリにお世話になっている人も多いのではないでしょうか?
しかし、ソフトウェアというものは常に進化しています。
これには、より便利な機能を追加するといったポジティブな側面はもちろん、セキュリティ脆弱性や、サポート切れ (EOL) への対応といったものも含まれます。そして、そのような進化は時として「破壊的変更」(breaking changes) をもたらします。
すなわち、なんらかの関数が削除されたり、取りうる引数が変わるなど、引き続き使い続けるためには、それらを利用する側のコードにも修正が必要になるような変更が度々発生します。そうした変更は「利用者の望む望まざるに関わらず」依存ライブラリのどこかで突然発生しうることから、冒頭に述べたような (我々は)「何もしてないのに壊れたー!」が生み出される原因となるわけです。
このような「不可抗力」的な性質も相まって、ユーザコードを新たな環境に適応させるタスクである「ソフトウェアマイグレーション」はエンジニアの悩みの種となっています🌱。
さて、世はLLM時代。
もはや人間が一からコードを書くことは少なくなった今、LLMは「マイグレーション」もそつなくやってのけるのでしょうか?
本研究はそんな疑問から出発しました。
先行研究のギャップ
static vs. dynamic
数年前には短い関数の補完すらままならなかったCode LLMsも、今や日頃の開発パートナーとして欠かせない存在となっています。
このような急速なモデルや手法の進化を支えているのが、モデルの性能を評価するベンチマークの存在です。初めはHumanEvalやMBPPといった関数レベルのコード補完タスクが中心でしたが、それらが徐々に解けるようになり、現在ではエンジニアの日常業務を模したより実世界的なタスクにフォーカスが移行しています。例えば、現在Code LLMs評価のデファクトであるSWE-benchは、GitHubのissueを読み、issueに記載された問題を解決するためのパッチを作成するという非常に実用的な課題を対象としています。
しかしながら、そうした先行研究はソフトウェアのある重要な側面を軽視してきました。それが冒頭に述べた「進化」です。
言葉の使われ方が時を経て変化するように、ある機能を実現するために正しいプログラムもバージョンの変遷とともに変化します。近年では、このように「進化」する環境におけるコード生成・マイグレーション能力にも注目が集まってきています。
一方で、それらの先行研究はしばしばスケーラブルではなく、タスクの内容も「新旧の対応を知っているかを問う一問一答」のような形式となっており、現実的なマイグレーションタスクのベンチマークとしては不足感が否めない状況にありました。
手法の限界
では、なぜそのような課題が生じるのか。
これは、主に先行研究がどのようにタスクを作成していたか、という手法の限界による部分が大きいと考えます。例えば、ある先行研究 では、バージョンごとのソースコードを収集し、その差分から破壊的変更が発生したバージョン (例えばpandasのv2.0で df.append() が削除された) を特定することで、Q. pandas v2.0 では? df = [WRITE_HERE] といった問題を作るといった方法を取っています。また、他の研究 では、ライブラリのドキュメンテーションをデータソースとして取り扱っています。
しかしながら、このような手法こそが先に述べた2つの欠点をもたらす元凶となっています。
例えばソースコードの差分比較を行う場合、その解析コストは「ライブラリ数×バージョン数」の速さで増大します。世の中に (Pythonに限定しても) 数十万と存在するライブラリに対して、そのような解析を行うことは現実的ではなく、事実、先行研究でも対象は主要な300ライブラリに限定されています。
また、ドキュメンテーションを用いる方法では、そもそも世の中の多くのライブラリは十分なドキュメントが整備されていないという点にも留意が必要です。
さらに、個々の破壊的変更の情報から、多段階のエラー解決や複数ファイルの修正を含むリポジトリレベルの課題をボトムアップに作成することは困難であることから、タスクは必然的に局所的、シングルステップのいわば「一問一答」と呼べるものに限定されていました。
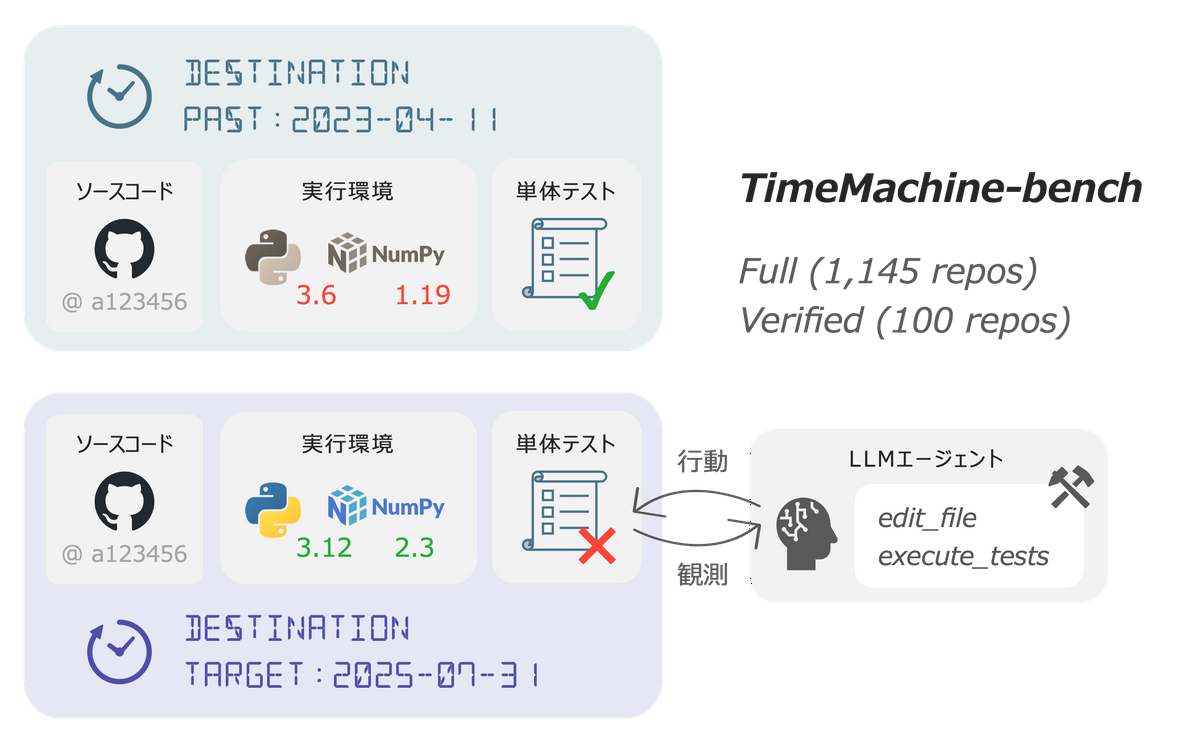
TimeMachine-benchの提案
コアアイデア
さて先行研究では、マイグレーションを「あるバージョンで動いていたものが、別のあるバージョンでは動かなくなった」ものを探すというように「バージョン」のカットで捉えていました。
しかし、これは少し視点を変えれば、それまで正しく動いていたものが「ある日を境に」動かなくなるという「時系列」の問題に読み替えることができます。つまり、過去のある日の (を再現した) 環境では正しく動作するが、今はもう動かない、といったものを、日付の指定のみで抽出することができれば、「どのライブラリの、どのバージョンが犯人か」を知らずとも、つまりライブラリごとの解析をすることなく、マイグレーションタスクを構築できるのではないか?というのが本研究のコアアイデアです。
では、どのように過去の環境を再現するのか?
ここに本ベンチマークが “TimeMachine-bench” たる所以があります。
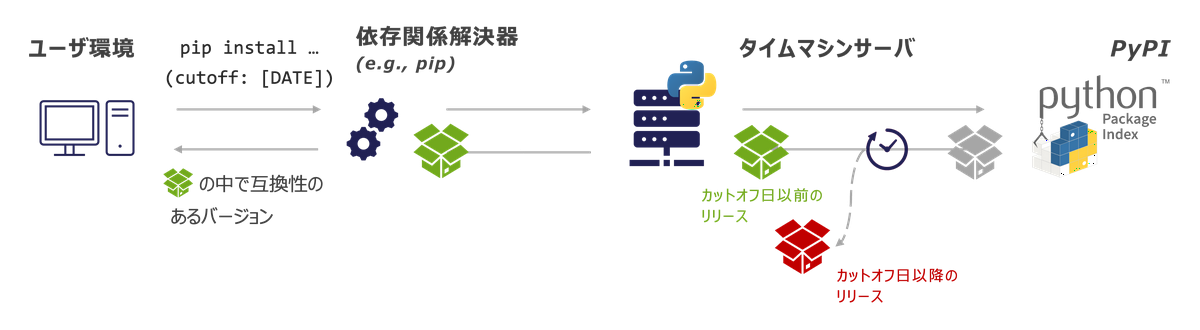
まず、Pythonのパッケージマネージャである pip がどのように依存関係を解決するかを簡単に説明すると、pip は pip install ... でインストールのリクエストを受けると、Pythonの公式パッケージリポジトリである PyPI (The Python Package Index) にパッケージのメタデータをリクエストします。このメタデータには、当該ライブラリのバージョン情報と各バージョンが要求する依存ライブラリのバージョン情報などが含まれており、 pip は受け取ったメタデータを元に、バージョン指定子の条件 (==や>=など) や他ライブラリとの整合性を判断して最終的にインストールするバージョンを確定します。
ここで、もしPyPIが例えば 2025年7月までのリリース情報しか持っていない としたらどうなるでしょうか?この場合、pip は2025年7月までにリリースされていたライブラリのバージョンと、それらが依存するライブラリの、同じく2025年7月までのバージョン情報をもとに、最終的にインストールするバージョンを決定します。
つまり、所定のカットオフ日以降の情報をフィルタしたパッケージリポジトリを経由すれば、 pip の依存関係アルゴリズムや環境構築手順に一切のテコ入れをせずとも、あたかもその時点にいるかのように (タイムトラベルしたかのように) 過去の環境を再現できるわけです。
本研究ではこのアイデアの具現化に際して、pypi-timemachine という素晴らしいOSSを活用させていただきました。具体的には、環境構築の際 PIP_INDEX_URL (パッケージメタデータの問い合わせ先) を公式のPyPIサーバではなく、dockerで構築したローカル環境のタイムマシンサーバに向けることで、PyPIへのリクエストをプロキシし、過去の指定日における環境の (ほぼ*) 厳密な再現を実現しました。
「ほぼ」厳密の理由として、レアケースではありますが、PyPIから過去のバージョン情報が削除されるなどが考えられます。
例えば、2025年7月にv1.1がリリースされた場合、同時期に pip install したケースではバージョン指定を行わない限り、(当時の) 最新版であるv1.1がインストールされますが、その後何らかの理由によりv1.1がPyPIから削除されると、カットオフを2025年7月としてもv1.0がインストールされるといったことが発生します。
データセットの構築
先述のアイデアのもと、本研究では The Stack v2 から、ユニットテストが実装されているPythonリポジトリを選定のうえ「2つの異なる断面 (日付) でテストを実行し、テスト結果が Pass → Failとなるものを抽出する」 全自動のパイプライン を構築しました。
全自動であるというのは、すなわちデータセットの「継続的な更新が可能である」ということです。
評価データが学習データに混入することで評価の妥当性が失われる「データ汚染」が深刻な課題となる昨今、このような “ライブ” なパイプラインには大きな意味があります。
さらに、本研究では人手の検証により「所与の環境下で解けることを保証した」100件のサブセット (Verified) を構築しました。
「所与の環境下で解ける」ものに限定した背景として、もしLLM (エージェント) に環境へのテコ入れを許容すると、任意のマイグレーションタスクはダウングレードにより (テストを通すだけであれば) 解決することができる、ということが挙げられます。
しかしながら、そのようなショートカットが、マイグレーション本来の目的に即していないことは火を見るより明らかです。
一方で、自動パイプラインにより抽出されたリポジトリの中には、ダウングレード以外での解決が本質的に困難なものも一定数含まれます。
例えば、当該リポジトリが依存するサードパーティライブラリの実装において、バグの修正、あるいは何らかの仕様変更により計算誤差が生じるようなケースです。今回は、モデルに安易なショートカットの選択肢を与えず、コードの修正によってマイグレーションに対応する能力を評価するため、Verifiedサブセットで評価を行うこととしました。
なお、Verifiedサブセットの構築にあたっては、問題の解決に必要な最小限の修正 (Gold Edit)、および人が解決までに要した時間に応じた問題の難易度 (Easy: 〜15分, Medium: 〜1時間, Hard: 〜2時間) のアノテーションを行いました。
以下は実際の問題の例となります。
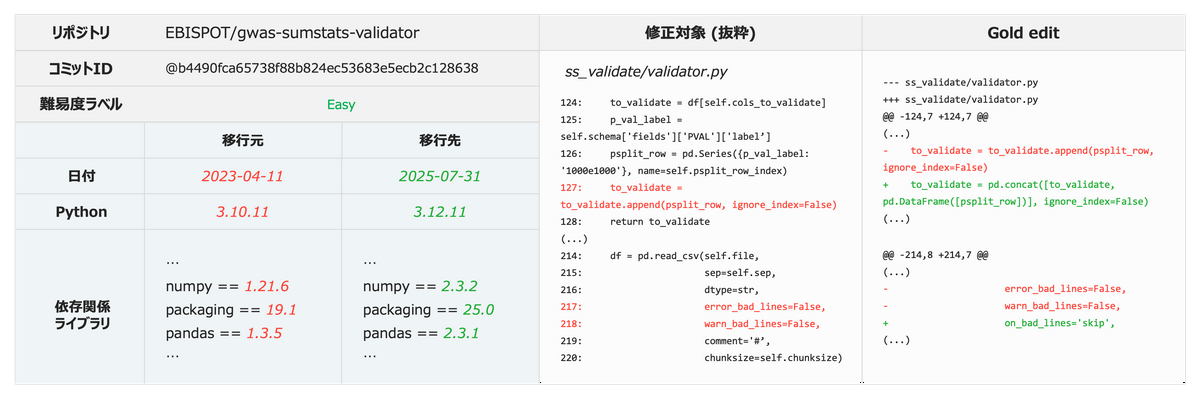
この問題では pandas のアップデートに関連して複数のランタイムエラーが発生しますが、一つのエラーを解決することで初めてその背後に隠蔽されていた別の不具合が顕在化するという多段の構造になっており、マイグレーションを対象とした既存のベンチマークとの違いが見て取れます。
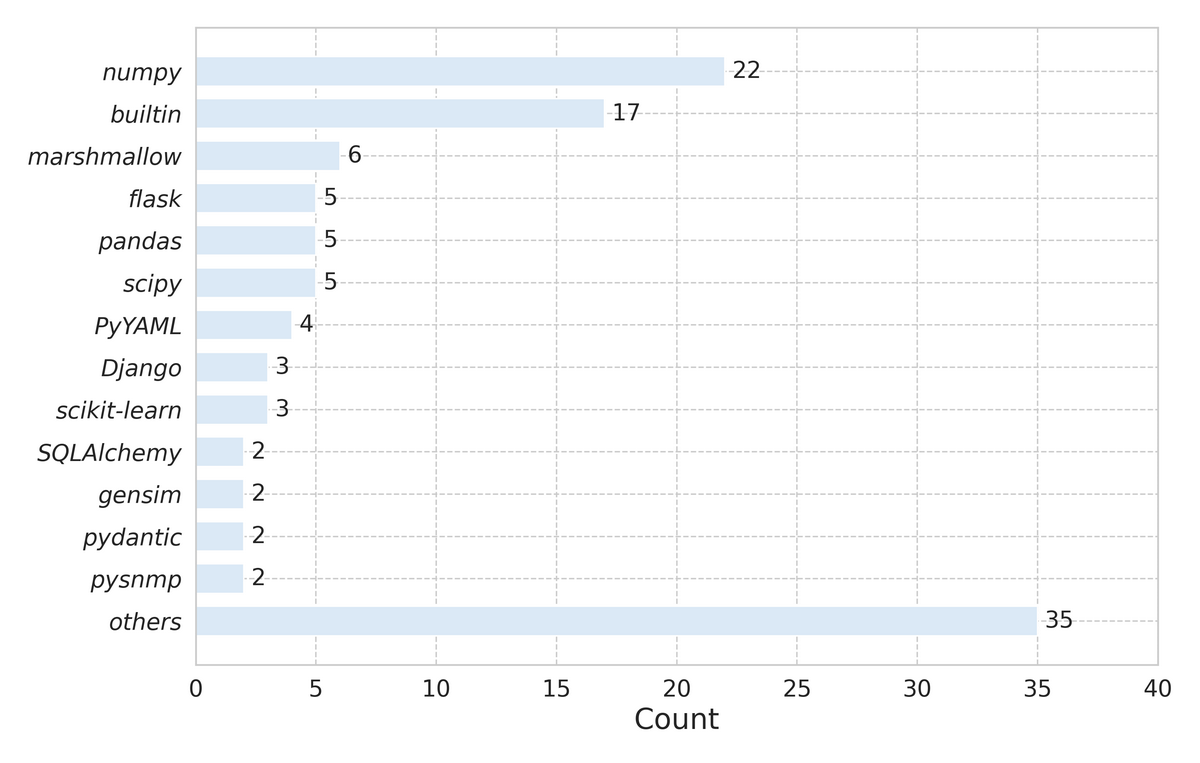
また、データセット中に含まれるエラー関連ライブラリは numpy や flask といったメジャーなものはもちろん、 pysnmp のように特定のドメインでのみ用いられるものなど多岐に渡っており、日付ベースの環境構築 (タイムマシン) の優れたスケーラビリティが確認できます。
現在の到達点
本研究では、最終的にタスクを解決できたか (pass@1) に加えて、人手のアノテーション (Gold Edit) と比較して無駄のない修正ができたか (prec@1) 、という2つの観点からモデルの性能を評価しました。
マイグレーションの本質は新環境への適応であり、コード品質の改善を目的とする「リファクタリング」とは本質的に役割が異なります。
両者を同時に行うことは変更の意図を不明瞭にし、レビューコストの増大や予期せぬバグの混入のリスクを増大させることから、「環境に適応するための最小限の変更」を特定する能力についても評価を行うこととしました。
実験では、4つのプロプライエタリモデル、および7つのオープンモデルを評価しました。ファイルの探索や多段の問題解決を要する「リポジトリレベル」のマイグレーションタスクについては標準的なアプローチが確立されていないことから、今回はSWE-benchに対する解法の一つであるSWE-Agentを参考に、10種のツールからなるReActエージェントをベースラインとしました。
モデルは最初の入力として、環境における各ライブラリのバージョンと初期のエラーログを受け取り、10種のツールを駆使しながらエラーの解決を目指します。最大で100回のLLM呼び出し (≒100回のツール利用)、10回のテスト実行の制限を設定し、この制限内でどれだけタスクを解決できたかを評価しました。
以下がTimeMachine-bench-Verifiedにおける11モデルの評価結果です。
※ Easy, Medium, Hardは各難易度の正解数、および正解率 (括弧内)
| モデル | pass@1 (%) | prec@1 (%) | Easy | Medium | Hard |
|---|---|---|---|---|---|
| Claude Sonnet 4 | 99.0 | 78.0 | 64 (100.0) | 30 (100.0) | 5 (83.3) |
| Claude 3.5 Sonnet v2 | 91.0 | 66.8 | 61 (95.3) | 25 (83.3) | 5 (83.3) |
| GPT-5 | 91.0 | 54.2 | 62 (96.9) | 27 (90.0) | 2 (33.3) |
| GPT-4o | 76.0 | 61.4 | 57 (89.1) | 19 (63.3) | 0 (0.0) |
| Qwen3-Coder-480B | 90.0 | 70.1 | 62 (96.9) | 26 (86.7) | 2 (33.3) |
| Qwen3-235B | 87.0 | 69.1 | 62 (96.9) | 24 (80.0) | 1 (16.7) |
| Qwen3-32B | 53.0 | 44.1 | 40 (62.5) | 13 (43.3) | 0 (0.0) |
| Llama-4-Maverick | 76.0 | 63.2 | 56 (87.5) | 20 (66.7) | 0 (0.0) |
| Llama-3.3 | 52.0 | 44.0 | 40 (62.5) | 12 (40.0) | 0 (0.0) |
| DeepSeek-V3.1 | 75.0 | 61.4 | 52 (81.3) | 21 (70.0) | 2 (33.3) |
| gpt-oss-120b (low) | 55.0 | 33.8 | 36 (56.3) | 19 (63.3) | 0 (0.0) |
この表を見てまず目につくのは、Claude Sonnet 4の99.0%という高いタスク解決率でしょう。また、オープンモデルの躍進も注目に値します。特に、Qwen3-Coder-480Bは前世代のフラグシップモデルであるClaude 3.5 Sonnet v2やGPT-4oに匹敵、もしくはそれらを上回るスコアを記録しました。
従来ベンチマーク化されてこなかった「リポジトリレベル」のマイグレーションという (モデルにとって) 未知のタスクにおいて、これだけのスコアを達成したということは、モデルが単に既存のベンチマークを暗記しているのではなく、実用的なエンジニアリングタスクに対して一定の汎化性能を有することを示す結果であると考えられます。
しかし、手放しでは喜べない懸念点もいくつか残されています。
まず、無駄のない修正という観点では、最もスコアの高いClaude Sonnet 4でさえ、20%以上 (prec@1 = 78.0%) の、課題解決に寄与しない修正を行なっているという点が挙げられます。これは一部のモデルではより顕著であり、例えばGPT-5は91.0%と高いタスク解決率を達成する一方で、その修正の約45%は過剰な修正であったことが確認できます。
また、タスクの難易度に着目すると、唯一の例外であるgpt-oss-120bを除いては、難易度の上昇に伴いタスク解決率が低下する一貫した傾向が見られました。特にHardの問題ではClaude系列を除くモデルの解決率が50%未満に留まるなど、人間にとって難しい問題は多くのLLMにとっても依然難しいということが示されました。
マイグレーションは解決済みなのか?
先に述べたような課題こそあれ、99%という高いスコアを見れば当然このような疑問が浮かぶでしょう。
しかしながら、我々は、この課題はまだ「解決済みとはほど遠い」と考えています。
その理由として、まずひとつにVerifiedサブセットの構築方法に起因する選択バイアスが挙げられます。人手での検証は安易なショートカットの除外というポジティブな側面 (信頼性) と引き換えに、人間が (妥当な時間で) 解ける程度の難易度に限定してしまうという欠点も持ち合わせています。すなわち、実世界の問題はHardや、2時間よりもずっと長くかかるが不可能ではないようなUltra-Hardの問題をより多く含むということです。
また、今回はダウングレードを禁じ手としましたが、真に有用なエージェントは、然るべき状況では (ダウングレードが唯一の正解であるような状況では)、選択的にダウングレードするといった判断も行いながら問題を解決することが期待されます。
そのため、この結果はマイグレーションタスクが99%解決されたことを保証するものではなく、「人間が短時間で対処可能な」課題に対する一定の自動化の可能性を示すものと解釈するのが妥当だと考えています。
これは余談となりますが、本データセットの人手検証は約1ヶ月間、私が普段より少し早起きをしてコツコツ行いました。検証は合計で70時間以上かかっており、その大半を短時間で解いてしまうLLMのコストパフォーマンスの良さも実感したところです…
また、個々の事例を分析すると99%という数字の裏に隠れたトリックも見えてきます。
以下の問題では pysnmp.hlapi パッケージに定義されていた定数が、他の場所に移動したことに伴って発生するimportエラーを解決することが期待されます。ここで、Claude Sonnet 4はいくつか候補として考えられるパスを試したのち、それらがいずれも不正解であることがわかると、最終的には図のようにtry-exceptブロックのネストとダミー変数の定義によりエラーをバイパスするという手段を選択しました。
この例は、モデルとデータ、双方に残る信頼性の課題を浮き彫りにするものです。
まず、モデルの側面として、このように「意味的な正しさよりもテストの通過を優先する」選択を行うことはpass rateへの過度な最適化の弊害と考えられます。無理にハックしてでも進むのではなく、自身の限界を正しく認識し「ここでは立ち止まる (あるいは人間に助けを求める) べきだ」という判断を下すことのできる高度なメタ認知能力の獲得は、今後のLLM開発における大きな課題であると考えられます。データの側面としては、このようなハックを見抜けないテストケースの危うさが挙げられます。
今回のケースではインポートされた定数がどのように使われるか、といった挙動をチェックするテストケースが定義されておらず、それゆえ、このような回答が「見かけ上は」正しいと判断されてしまいました。
これは、本研究で構築したデータセットが、GitHubリポジトリに紐づく既存のテストケースに依存していること、および (人間が書いた) それらのテストケースが往々にして不足していることに起因します。ユニットテスト自動生成 (UTG) のような技術を統合することで、より頑健、かつチャレンジングなベンチマークの構築を目指すことは、今後の有力な方向性のひとつだと考えています。

後日談
今回の話は、SWE-benchの下に名前を載せるという意気込みで取り組みました。
その意味では、手法のピースがはまり、初めてモデルに解かせた際「あまりにも解けてしまった」ことには、モデルの進化に対する驚きとともに、なんとも言えない悔しさが入り交じる複雑な心境を抱かずにはいられませんでした。
先に述べたようなテストの穴を塞ぐ、大規模な人手検証を通して難易度の高い (人間にとって時間のかかる) 問題のみを集める、といった方法でこのタスク成功率は70%, いや50%にもできたかもしれません。
しかし、たとえこのデータセットの寿命は出た瞬間に尽きていたとしても、この方法論を早く世に出すことにこそ意味があると考え、このように公開するに至りました。
果たして近い世の中、コンテナ開発のように、コードも「壊れたら使い捨て」「メンテナンスよりもスクラッチで作り直し」という時代になるのかもしれません。
しかし、実際のプロジェクトでは (望ましくないことではありますが) 検討段階で漏れていた仕様がコードのみに反映されているといった不一致や、そもそも「コードこそが仕様書」であることも少なくありません。
仕様とコードの自由な往来が達成されるまでの間においては、人間はこの厄介な業務と付き合っていくことになるでしょう。
本研究が、マイグレーション、バージョンや時系列を扱うCode LLMs研究の道標となり、より実用的で信頼できるLLMの実現に向けた議論を加速させる一助となれば、著者としてこれほど嬉しいことはありません。
おわりに
今回は、NLP2026にて若手奨励賞を受賞した自著論文 “TimeMachine-bench” について、裏話も含めてじっくりと解説させていただきました。
改めまして、論文の審査を担当いただきました皆様に、この場をお借りして感謝申し上げます。
この記事を読んで興味を持っていただけましたら、ぜひオリジナルの方もご一読いただけますと幸甚です。引き続き、本分野における研究の発展とその社会還元に貢献していきたいと思います。
ここまでお読みいただきありがとうございました!
フューチャーではともに働くメンバーを募集しています。
ご興味を持っていただいた方は、ぜひ キャリア採用サイト からのご応募をお待ちしております。