はじめに
はじめまして!フューチャー株式会社の田中裕真と申します。
私は2025年10月に新卒として入社し、2026年2月にAIXG(AI戦略推進グループ)のNLPチームに配属されました。配属からちょうど2ヶ月が経ち、これまでのゆったりとした生活から一変して、忙しくも目まぐるしく新しい情報が得られ、知的好奇心を満たしながら働く充実した毎日を送っています。
大学院での研究ではAIの性能調査などを通じてAI自体には触れていたものの、自然言語処理(NLP)分野はあまり経験がありませんでした。現在はNLP関連のキャッチアップを進めながら、チャットシステムの構築業務に携わっています。
本記事では、2026年3月9日(月)〜3月13日(金)にかけて栃木県宇都宮市で開催された言語処理学会第32回年次大会 (NLP2026) の参加報告をお届けします。
当社はプラチナスポンサーとして協賛し、総勢8名がオンサイトで参加しました。スポンサーブースでの企業紹介や、メンバーによる研究発表など、非常に活気あふれる5日間となりました。
言語処理学会とは
言語処理学会は、自然言語処理(NLP)分野における国内最大の学会で、毎年3月に開催されています。第32回となる今年の年次大会は、栃木県宇都宮市でのオンサイト開催とオンライン配信のハイブリッド形式で行われました。
今回の大会は、事前+直前参加登録者が2236人(歴代2位)に上り、当日参加者を合わせると歴代1位の参加者数を記録しました。さらに、発表件数は797件(歴代1位)、スポンサー数は100団体(歴代2位)と過去最大級の規模となりました。生成AIや大規模言語モデル(LLM)の社会実装が急速に進む中、産学問わず非常に多くの研究者が集い、基礎研究から応用事例まで幅広い議論が交わされる熱気のある学会です。NLP初学者の私にとっても、最前線の研究トレンドを直接肌で感じることができる非常に貴重な機会となりました。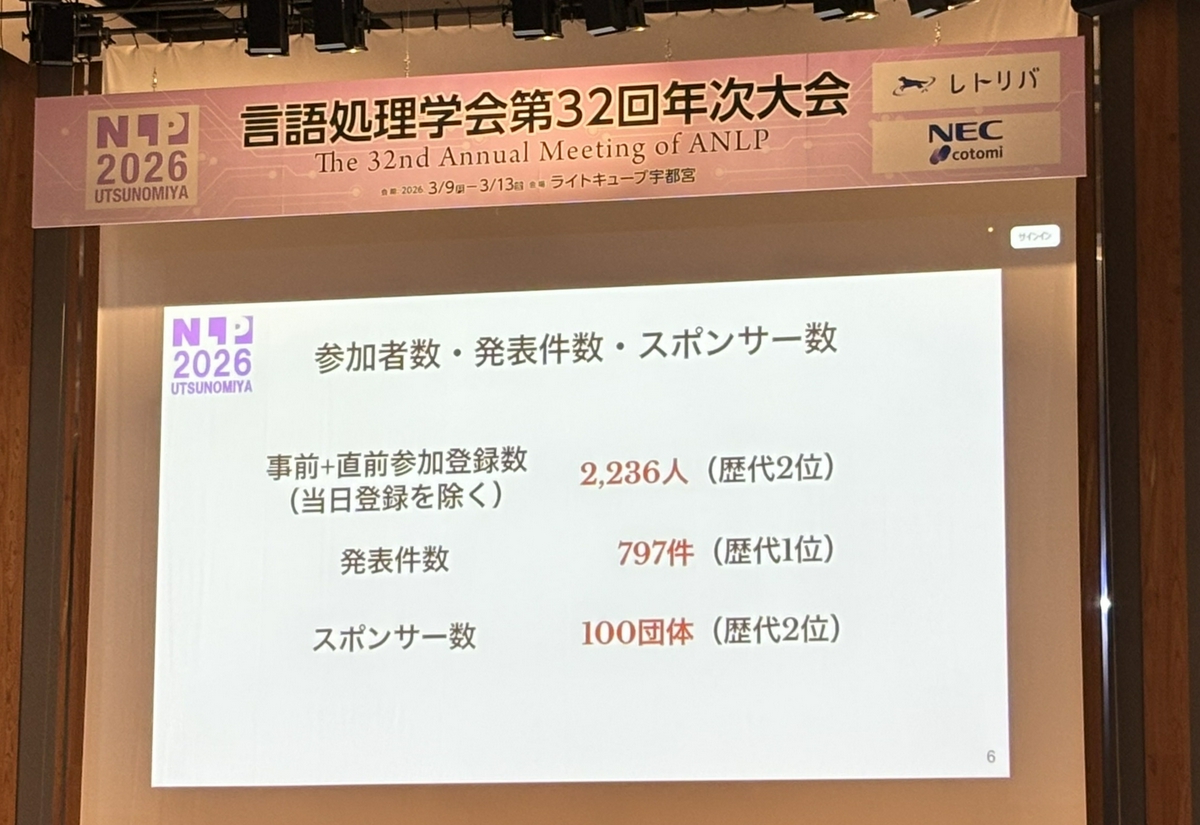
スポンサーブースの様子
企業ブースでは、NLP関連の過去の導入事例や、そのほかのAIXG担当領域についての紹介を行いました。連日多くの方々に足を運んでいただき、NLPの社会実装に関するディスカッションや、学生の皆さんとの交流で大いに盛り上がりました。
今回はノベルティとして眼鏡やディスプレイを拭ける「クロス」と折りたたみ可能な「トートバッグ」を用意しご好評をいただきました。

▲ 企業ブースの様子
祝・若手奨励賞受賞!
本大会では、同じAIXGメンバーである藤井の主著論文『TimeMachine-bench: LLMは「あの日」のコードを最新環境に適応できるか?』が、見事若手奨励賞に選出されました!
当論文の背景や解説については、著者の藤井自身が執筆したブログ記事が公開されておりますので、ぜひ併せてご覧ください。
投稿論文の紹介
当社は、NLP2026において著者・共著者を含めて合計4件の論文を投稿しました。
本章ではこれらの4件の論文について簡単に紹介します。
- [B8-1]UI-Redline-bench: 赤入れ指示によるWebUIコード修正ベンチマーク
この論文では、WebUI開発における、スクリーンショットに直接手書きで修正指示を書き込む「赤入れ」プロセスに着目し、視覚的指示に基づくコード修正タスクのベンチマーク「UI-Redline-bench」を構築しています。人間にとって直感的な形式の指示に対するVLM(視覚言語モデル)の処理能力に焦点を当て、VLMを活用した開発作業の能率向上への寄与を目指すものです。
既存研究が主に言語的指示を扱っているのに対し、本研究は図形や文字を使って描きこまれた視覚的指示を扱う点が特徴です。著者らが視覚的指示を描きこみ作成した、計350件のHTML/CSSコード修正データセットにより、GPT-5等の主要なVLMの視覚的指示に基づくコード修正能力を検証しました。
検証の結果、GPT-5等は全体として高い修正能力を示した一方で、矢印を使って示された離れた位置に、概形で描かれたUIを実装する事例では、修正に失敗する傾向が見られました。この結果から、今後VLMの空間推論能力の強化が不可欠であると言えます。具体的には、矢印の指し示す位置を正しく認識する、個々の図形を意味のあるまとまりとしてグループ化するなど、空間的に分散した視覚的指示を統合するタスクの必要性が示唆されています。(肥合) - [B8-3]TimeMachine-bench: LLMは「あの日」のコードを最新環境に適応できるか?
この論文は本学会において若手奨励賞に選出されました!こちらの技術ブログで詳しく説明されていますので、ぜひご覧ください。 - [B9-19]WikiOriginQA: 知識の起源を組み込んだ文化的バイアス分析用QAデータセットの自動構築
この論文では、LLMの性能における文化的バイアスを検証するためのQAデータセットと、その自動構築手法を提案しています。LLMの学習データは、英語をはじめとした使用者の多い主要な言語に偏っています。そのため、主要言語圏の知識は良く知っている一方で、マイナーな言語圏の知識は適切に扱えないという文化的バイアスが起こることが知られています。しかし、既存の手法では該当する文化に詳しい協力者を必要とするため、多言語・多文化にわたる調査用データセットの構築は困難でした。そこで本論文では、「ある文化に特有の知識は、その文化と関係の深い言語において最も早くドキュメント化される」という仮説に基づき、文化的知識と言語の結びつきをWikipediaの記事作成日を用いて表現することで、文化的知識を問うQAデータセット「WikiOriginQA」を自動構築しました。
WikiOriginQAを用いた実験の結果、先行研究と同様にLLMの性能における英語圏の文化へ偏重傾向が確認され、これにより、多様な文化におけるバイアス検証を人手を介さずに行う上で、本手法が有効であることが示唆されました。(羽根田) - [C9-20]項の復元は必要か?日英機械翻訳における省略された項の扱いの分析
この論文では、主語や目的語等の述語の項が省略されやすい日本語のような言語 (pro-drop言語) から英語への機械翻訳において、従来重視されてきた「省略された項の同定および復元」が本当に必要かという問題に対し、その必要性を実証的に検証しています。
具体的には、LLM (GPT-4o) を用いた日英翻訳を対象に、省略項の同定 (ゼロ照応解析) の成否と翻訳品質の関係、および翻訳時に項がどの程度復元されるかを分析しています。また、省略項が復元されなかった場合の構文選択なども含め、多角的な事例分析が行われています。
その結果、GPT-4oは省略項の同定が困難な事例や項を復元せずに訳した場合においても文意が伝達できる翻訳が行えていました。ただし、項の同定が困難な事例では復元を避ける傾向が見られるなど項の同定可否に伴って翻訳の性質には差が見られました。しかし、省略項を復元しない場合、GPT-4oは述語の名詞化や受動態などを用いることで構文的に自然な翻訳が行えていました。これらの結果から、項の同定・復元は必須ではなく、日英翻訳において最先端のLLMには項の省略はもはや主要な障壁ではないことが示唆されました。 (野末)
社員が選ぶNLP2026の注目論文の紹介
ここからは、NLP2026に参加したメンバーが各自の視点で「これは面白い!」「業務に活かせそう!」と感じたイチオシの論文やセッションを3件ピックアップして紹介します。
- [P8-20] 多言語文埋め込みの意味と言語の分離のための損失関数の分析
日本語や英語など、言語が違っても似た意味の文同士が近くなるようにベクトル化する「多言語文埋め込み」は、情報検索や機械翻訳の品質推定など幅広い領域で使われています。
この技術では「言語によらず」意味の近さが反映されることが理想ですが、実際には言語情報に引っ張られてクラスタが分離してしまい、言語横断的なタスクでの性能低下を招くことが知られています。そのため先行研究では、文埋め込みを「意味表現」と「言語表現」に分離し、意味表現のみを用いる手法が提案されてきました。
この分離のための学習手法(損失関数の設計)には、各要素内で完結する「要素内制約」と、両者に跨る「要素間制約」が存在しますが、これらが分離にどう寄与するかは十分に分かっていませんでした。本研究でこれらを比較した結果、従来のエンコーダ由来モデル(LaBSEなど)では両者の併用が有効な一方、近年のデコーダ由来モデル(Gemini Embeddingなど)では「要素間制約」のみを用いる方が高い性能を示すことが明らかになりました。
LLMベースのモデルが普及する中で、従来のモデルとは適した学習アプローチが異なることを実証した事実は興味深いと考え、こちらの発表を取り上げました。(森下) - [Q3-10] マルチモーダルかつ長い文脈の処理が求められる語用論的推論ベンチマーク
大規模言語モデル(LLM)や大規模視覚言語モデル(VLLM)において、言語の辞書的な意味ではなく文脈依存の意味を理解するための「語用論的推論能力」の向上は社会実装を目指すうえで重要な課題です。この研究では、特にマルチモーダルかつ長期文脈の処理が必要な設定における語用論的推論のベンチマークを提案しています。
特徴として、漫画データを題材として採用し、著者が人手で問題・選択肢を作成することで計101問の多肢選択式QAデータセットを構築しています。実際にVLLMと人間による評価実験を行った結果、最新のVLLMであっても正解率は人間を大きく下回り、語用論的推論能力には課題が残っていることが示されました。
マルチモーダル・長期文脈の処理が必要な設定として漫画を活用している点や、評価実験を通して昨今著しい性能向上が見られるVLLMの弱点を浮き彫りにした点が非常に興味深く、挙げさせていただきました。(岸波) - [B6-7] クロスコーダーを用いた脳と言語モデルにおける内部表現の特徴量比較
本研究は、ポッドキャスト聴取時の脳活動(fMRIデータ)と言語モデル(LM)の内部表現を「クロスコーダー」という手法で比較し、両者の情報処理における類似点や相違点を検証した論文です。従来の研究では、LMの表現から脳応答を予測するエンコーディングモデルが主流でしたが、これはLMから脳への一方向的な写像に留まり、予測の根拠となる要因を人間が理解できる形で抽出できない(解釈性が低い)という課題がありました。
本手法では、脳応答とLM表現の両方を同一のスパース(疎)な潜在空間に写像し、そこからそれぞれの表現を再構成するプロセスを学習します。この仕組みにより、抽出された特徴量が脳とLMのどちらに強く寄与しているかを定量的に評価することが可能になりました。実験の結果、「場所」に関する描写は脳とLMで共通して表現されている一方、「負の情動」は脳側に、フィラー(言いよどみ)などの「口語表現」はLM側に特有の反応として抽出されました。
fMRIの解像度の限界や、因果関係の特定といった課題はあるものの 、AIの内部表現と人間の理解を直接比較し、その差を数値で示せる点は非常に画期的です。知性の在り方を定量的に議論できる可能性に興味を惹かれ、本論文を取り上げました。(田中)
会場の様子・オフタイムのエピソード
オンサイト参加ならではの、現地の雰囲気やエピソードも少しご紹介します。
最も印象的だったのは、学会オープニングでの出来事です。全プログラム終了後に「重要な注意事項」と銘打たれたスライドで宇都宮餃子の正しい食べ方のレクチャーがありました。開催地である宇都宮ならではの粋な計らいに、会場全体が温かい笑いと拍手に包まれました。

▲ オープニングでの「重要なお知らせ(餃子の食べ方)」
また、天候に関しては驚きの連続でした。開催2日目には、3月であるにもかかわらずなんと大雪に見舞われました。会場周辺の道も真っ白に雪が積もり、ある意味で非常に記憶に残る学会となりました。

▲ 3月とは思えない大雪に見舞われた2日目
一方で、天気の良いお昼時には会場の外にキッチンカーが出店しており、日差しを浴びながら外でランチを楽しむこともできました。
おわりに
NLP初学者としての参加でしたが、日々の業務に直結する知見や、LLMの最新動向など、膨大なインプットを得ることができました。何より、最前線で活躍する研究者やエンジニアの熱量に直接触れることができ、「自分もさらに技術を磨いていこう」と強くモチベーションを刺激されました。
現在、AIXGのNLPチームでは、以下のような環境・制度を整え、NLPの基礎・応用技術開発を積極的に推進しています。
- 大学との共同研究
- 社会人博士制度
- 新規参画者への教育プログラム
- GPUクラスタ
こうした環境のもと、ともに働くメンバーを積極的に募集しています!
学生の皆様へ
夏季インターンやアルバイトについては、4月20日 (月) に下記のウェブサイトから募集を開始いたします。
また、博士課程向けのResearch Internは通年募集中です。
https://www.future.co.jp/recruit/summer_intern/2026/
昨年のインターンシップ参加者へのインタビューもぜひご確認ください。
https://future-architect.github.io/articles/20260323a/
新卒・キャリア採用について
NLP分野における社会実装のニーズは拡大し続けており、自然言語処理の力で顧客のビジネス課題を解決していく仲間を求めています。少しでも興味を持っていただけた方は、ぜひ以下の採用リンクからご応募をお待ちしております!