TL;DR
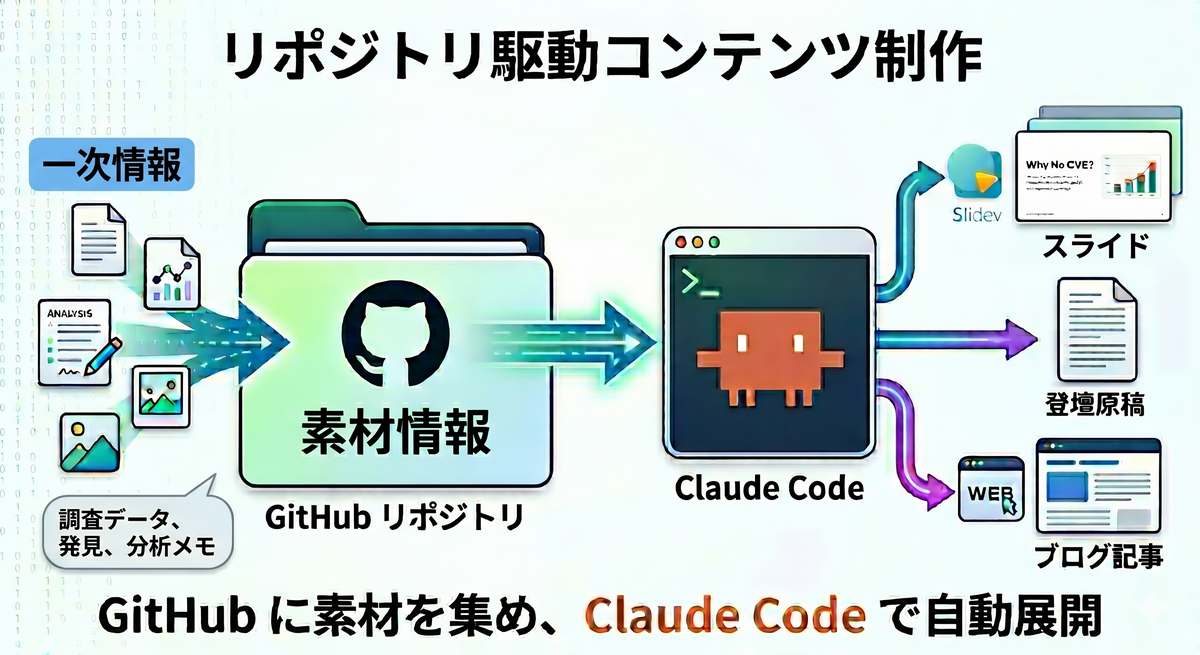
- 調査データや発見を GitHub リポジトリにひたすら追加していく。スライド・原稿・ブログへの反映は Claude に任せる
- 新しいデータが出たらリポジトリに入れるだけで、Claude が成果物を更新してくれる。準備中にデータが増え続けても、成果物は追いつく
- VulnCon 2026 の登壇準備を通じてたどり着いた、リポジトリ駆動のやり方
はじめに
こんにちは、フューチャー株式会社の棚井龍之介です。2026年4月、アリゾナ州スコッツデールで開催された VulnCon 2026 で初めてアメリカのセキュリティカンファレンスに登壇してきました(登壇レポートはこちら)。60分の英語セッションで、発表スライドと登壇原稿の両方を準備する必要がありました。
面白かったのは、準備期間中にも新しい発見が次々と出てきたことです。登壇内容に関わるデータが日々増えていく。それを逐次スライドと原稿に反映していくことになります。
この状況で採ったやり方が、調査データや発見をまず GitHub リポジトリに追加して、スライドや原稿への反映は Claude に任せる、というものでした。データの置き場をリポジトリに決めてしまえば、自分は新しいデータを入れることに集中できる。そこから先の成果物への落とし込みは Claude がやってくれる。
なお、この記事で「Claude」と書いているのは、ターミナルから claude コマンドで起動する Claude Code のことです。

ターミナルで起動すると、カレントディレクトリのファイルを直接読み書きできます。Git 操作も gh コマンドも叩けます。リポジトリを作業場所にして Claude Code を立ち上げれば、リポジトリの中身を全部見た上で作業してくれます。
準備中にデータが増え続けるなかで
VulnCon の登壇準備で必要だったのは、発表スライドと登壇原稿です。加えて、FutureVuls ブログの技術記事も書く予定でした。
CFP が通った段階で、素材と方向性はおおよそ見えていました。ポイントは、そこから先です。
準備期間中に trivy へのサプライチェーン攻撃が発生し、これをきっかけに FutureVuls ブログとして複数の記事を執筆することになりました。
- FutureVuls 配布バイナリの安全性を SHA256・ビルドタイムスタンプ・Sigstore 署名の3軸で検証
- 攻撃者が狙った7リポジトリの攻撃直前の OpenSSF Scorecard を分析
- Sigstore・cosign による改ざん検証の仕組みを体系的に整理
- 第2波の攻撃が GitHub Actions・Docker Hub・npm・PyPI に波及し、影響確認ガイドを公開
どれも登壇内容に直結するテーマです。情報を収集しながらスライドと原稿に反映し、同時にブログとしても公開していました。スライド、原稿、ブログ——複数の成果物を並行して、継続的に更新し続ける状況です。
ここで力を発揮したのが、Claude を活用したワークフローでした。
やり方: データをリポジトリに入れて、Claude に反映させる
採ったやり方は単純です。新しいデータや発見が出たら、まず GitHub リポジトリに追加する。形式は何でもいい。Markdown でも、テキストファイルでも、画像でも、PDF でも。とにかくリポジトリに入れておく。スライドや原稿への反映は Claude に頼む。
リポジトリの中は、大きく「素材」と「成果物」に分けています。
リポジトリ/ |
素材の中身は自分が管理しやすい粒度で分ければいい。ファイル1つにまとめてもいいし、テーマごとにディレクトリを切ってもいい。実際、自分のリポジトリでは最初は大雑把にファイルを放り込んでいましたが、データが増えてきたタイミングで Claude と壁打ちしながら構成を見直しました。「このデータとこのデータは分けたほうが扱いやすいか?」「ブログ用のプランはどこに置く?」といった相談を Claude にして、ディレクトリ構成自体を育てていく。最初から完璧な設計を決める必要はありません。
たとえば、攻撃者が狙った7リポジトリの Scorecard 分析が終わったら、まず素材として追記する。
case-studies/ に 7リポジトリの攻撃直前 Scorecard 分析結果を追加しました。 |
今回の VulnCon 2026 の準備では、自分と共同登壇者の神戸さんが、それぞれの調査結果や発見を次々と同じリポジトリに追加していきました。日によって誰がどのデータを入れるかはバラバラです。でも、データの置き場がリポジトリに決まっているので、スライドのどこに入れるか、原稿のどの段落を書き換えるかは、Claude がリポジトリ全体を見て判断してくれます。
Claude にリポジトリごと見せておけば、原稿に新しいデータを追加したときにスライド側の整合性も一緒に確認してくれます。スライドと原稿の整合性チェックを丸ごと任せられたのは助かりました。
さらに言えば、Claude はデータが増えたときに単に差分を反映するだけではなく、新しい情報を踏まえてより良い構成を提案してくれることもありました。「この発見を入れるなら、Part 5 と Part 6 の順番を入れ替えたほうが流れがいい」といった提案です。データが増えるたびに構成が良くなっていく、という体験は、手作業ではなかなかできません。
また、準備中に過去の自社ブログや公開情報を思い出して「そういえば、これも関連するな」と気づくことがあります。そういうときは、とりあえずリポジトリに入れておく。あとは Claude に任せます。使うかどうか、どこに入れるかは Claude が判断してくれます。素材の投入に迷わなくていいので、思いついたらすぐリポジトリに放り込む癖がつきました。
なぜ Slidev か
VulnCon のスライドは Slidev で作りました。Markdown でスライドが書けるツールです。
Slidev を選んだ一番の理由は、Claude との相性です。Claude はテキストファイルの読み書きが得意なので、Markdown で書かれたスライドなら中身を理解して直接編集できます。PowerPoint でも扱えますが、テキストベースのほうが編集がスムーズです。リポジトリのデータからスライドへの流れを Claude に任せたいなら、スライドも Markdown で書いておくのが自然でした。
たとえば、VulnCon で実際に使ったスライドを2枚紹介します。
1枚目は、サプライチェーン攻撃で CVE が採番されなかった理由を整理したスライドです。
# Why No CVE? |
この Markdown が、こういうスライドになります。

2枚目は、この攻撃をどうやって知ったかを聴衆に問いかけるスライドです。
--- |
実際のスライドはこうなります。

<v-click> は Slidev の機能で、クリックするたびに次の要素が表示されます。まず CVE や NVD が取り消し線で並んでいて、クリックすると「X(旧 Twitter)で知った」が出てくる。もう一度クリックすると「これが CVE の盲点だ」と結論が出る。こういうプレゼンの「間」を、Markdown で書ける。Claude はこの Markdown を直接読み書きできるので、「この v-click の順番を入れ替えて」といった修正もそのまま頼めます。レイアウトの調整も Markdown と CSS の範囲で完結するので、ストレスなく進められました。
VulnCon の準備では、登壇原稿からスライドを起こすこともあれば、スライドを先に直して原稿に反映させることもありました。どちらが先でもいい。原稿とスライドの両方がリポジトリにあるので、Claude が双方向に反映してくれます。
今回は英語での登壇だったので、スライドと原稿の役割分担にも気を配りました。スライドには情報を多めに載せて、聴衆が視覚的に追えるようにする。一方で原稿の英語表現はシンプルに抑えて、ノンネイティブでも話しやすくする。こういう「整合性は保ちつつ、それぞれの役割に合わせてアレンジする」ことも、両方のファイルを同時に見られる Claude だからできることでした。
ブログ記事も同じリポジトリから
VulnCon の登壇内容をブログ記事にする場合も、同じリポジトリから直接書けます。データはすでにリポジトリにある。登壇原稿もある。ブログ用に新たにデータを集め直す必要がありません。
やることは、リポジトリの中の素材を踏まえて、どういうブログを書いてほしいかを Claude に伝えるだけです。
リポジトリの素材を使って、サプライチェーン攻撃の影響確認ガイドをブログ記事として書いて。 |
Claude はリポジトリ内のファイルを直接読めるので、数値をコピペし直す手間がありません。素材に書いてある数値を、Claude がそのまま引用してくれます。
もちろん、生成された記事をそのまま公開するわけではありません。生成した原稿に対して Claude 自身にセルフチェックさせたり、PR を作成して GitHub Copilot をレビュアーにアサインしたりしながら推敲を重ねています。複数の AI の視点を入れることで、一人では気づきにくい表現の不自然さや論理の飛躍を拾えます。
ブログの執筆途中で新しい発見があったときも同じです。素材をリポジトリに追加して、「この情報を既存の記事に入れて」と頼めば、Claude が記事の流れを読んで適切な場所に追加してくれる。つまり、最初の執筆だけでなく「編集」も任せられる。スライドと原稿のときと同じ話で、新しいデータが出てきたら、自分はリポジトリに入れるだけでいい。
CLAUDE.md で表記を揃える
成果物が増えてくると、スライドとブログで数値の書き方を揃えたくなります。そこで CLAUDE.md をリポジトリのルートに置いています。
Claude Code はセッション開始時にこのファイルを自動で読み込みます。
## ブログ文体ルール |
ここに正規の数値を載せておくと、スライドでもブログでも「-68%」で統一されます。「約7割減」ではなく正確な数値で統一できます。出典が PR なのか Issue なのかも、ここで決めておけばブレません。
最初は「まあ書いておくか」くらいの気持ちで作りましたが、成果物の本数が増えるほど効果を実感しました。
リポジトリ操作も Claude に任せる
ファイルの作成・編集、git commit、git push、Issue の起票——こういったリポジトリ操作は基本的に Claude に任せています。
Claude Code は gh コマンドも叩けるので、Issue の起票は gh issue create で済みます。自分は「データを集める」「指示を出す」「出来上がりを確認する」に絞れます。
壁打ちの結果を Issue に残す
Claude との壁打ちで出た気づきや方針変更は、そのまま GitHub Issue にしておく。これが地味に効きました。
たとえば、VulnCon の Q&A 準備をしているとき。
Issue #xx: Q&A セッション用のバックアップスライドを追加する |
Issue の起票自体も Claude に頼みます。翌日の別セッションで「Issue #xx の内容を踏まえてスライドを追加して」と言えば、前回の議論を引き継げる。
Claude とのセッションは消えますが、リポジトリに書いたものは消えません。Issue やコミットログが、セッション間の記憶の代わりになります。
Perplexity で素材を足す
一次データの補強に Perplexity を使いました。
ブログに書く数値の裏取り——「endoflife.date のカバレッジは2026年4月時点で何件か」「gorilla/mux はいつアーカイブされたか」——こういった確認を Perplexity に投げて、返ってきた結果を出典ごとリポジトリに追記しておく。
Claude はリポジトリの中身しか見ないので、Perplexity で集めた情報もリポジトリに入れておかないと使えません。リポジトリに素材が増えるほど、Claude が書ける内容の幅が広がります。
実践を通じた所感
1ヶ月やってみて思ったのは、結局自分の仕事は「自分で試行錯誤して、それを記録すること」だった、ということです。こういうデータは自分で手を動かさないと生まれない。でも逆に、試行錯誤の記録さえリポジトリにあれば、そこから先は Claude に任せられる。
リポジトリに入れる素材は、Markdown で書くこともあれば、画像や PDF をそのまま放り込むこともありました。きれいに整形してから入れる必要はない。ただ、スライドや原稿のように Claude に直接編集させたい成果物は Markdown にしておくと、この流れが途切れません。
ディレクトリ構成は最初の数日で試行錯誤しましたが、構成が固まってからは、データを入れて反映を頼むだけのループになりました。VulnCon の直前まで新しい発見を出し続けられたのは、このループが軽かったからだと思います。
運用上の留意点
Claude が書いた文章は、必ず自分でレビューしています。CLAUDE.md で数値を揃えていても、文脈に合わない場所で引用されることはあるので、数値と前後の文脈の両方を確認する。
また、Claude の修正を完全には信用せず、適用漏れや横展開漏れがないかをチェックし続けることも大事です。たとえば「この表現を全箇所修正して」と頼んでも、一部が抜けていることがある。このチェック自体に、Claude 自身のセルフチェックや GitHub Copilot の PR レビューなど、複数の AI を組み合わせると抜け漏れを拾いやすくなります。
なお、Claude に git push や gh issue create を任せる以上、リポジトリはプライベートで運用し、機密情報は直接書かないようにしています。
おわりに
VulnCon 2026 の準備を通じてたどり着いたやり方は、データを GitHub リポジトリに集めて、成果物への落とし込みは Claude に任せる、というものでした。
新しい発見が出たらリポジトリに追加する。スライドや原稿への反映は Claude がやる。準備期間中にデータが増え続けても、リポジトリにさえ入れておけば、成果物は追いつく。
共通の情報源から、スライド・原稿・ブログといった複数の成果物を作る必要があり、しかもデータが継続的に増えていく——今回の VulnCon 準備は、まさにこのやり方が合うケースでした。同じような状況に直面している方の参考になれば幸いです。
なお、この記事自体も同じリポジトリから Claude で書いています。コミットログを見ると Co-Authored-By: Claude の記録が残っています。VulnCon の登壇準備でスライドや原稿を作るつもりで始めたリポジトリが、試行錯誤の記録が溜まった結果、こうしてワークフロー自体を紹介するブログ記事にまで繋がりました。リポジトリに記録を残しておくと、思わぬ形で次の成果物が生まれることがあります。