
春の入門祭り2026の3本目です。
1. はじめに
CSIGの星名です。今回は、お問い合わせ対応業務にLLM Agentを導入してみたお話です。
最近、開発の現場では、PdMやプログラミング、QAといった役割ごとにAgentを使い分ける手法が、当たり前のように語られるようになってきました。
一方で、非開発業務に目を向けてみると、議事録作成のような単発の活用は進んでいるものの、業務フロー全体をAgentが駆動するような事例は、まだまだ少ないと感じています。というのも、定型業務であればあるほど、そのチーム固有の知識や運用ルールに強く依存するため、外へ向けた知見として一般化しづらい、という側面があるからでしょう。
だからこそ、こうした現場でAgentを活かすには、「何を渡し、どう保つか」を設計する Context Engineering が重要になる。少なくとも私たちのケースではそういう結論になりました。
この記事では、私たちが実際に悩みながら取り組んだプロセスを共有します。
1.1 プロンプトを磨いても、エージェントは賢くならなかった
GitHub Copilot Agent を導入して、 問い合わせ対応の「調査~回答文作成~レビュー」を仕組み化 しようと試みたときの話です。いざ動かしてみると「さっき調べたことを忘れる」「指示を無視する」といった事象が頻発しました。当初はプロンプトの書き方の問題かなと考えていたのですが、プロンプトの書き方以前に、そもそも LLM に何をどう渡すかという「コンテキストの設計」に課題がありました。
本当の失敗モードはプロンプトが悪いことではなく、コンテキストの組み立て(context assembly)が悪いこと
— Andrej Karpathy
設計を見直す中で参考になったのが、LangChain 等で提唱されている Select, Write, Isolate, Compress の 4 戦略です。
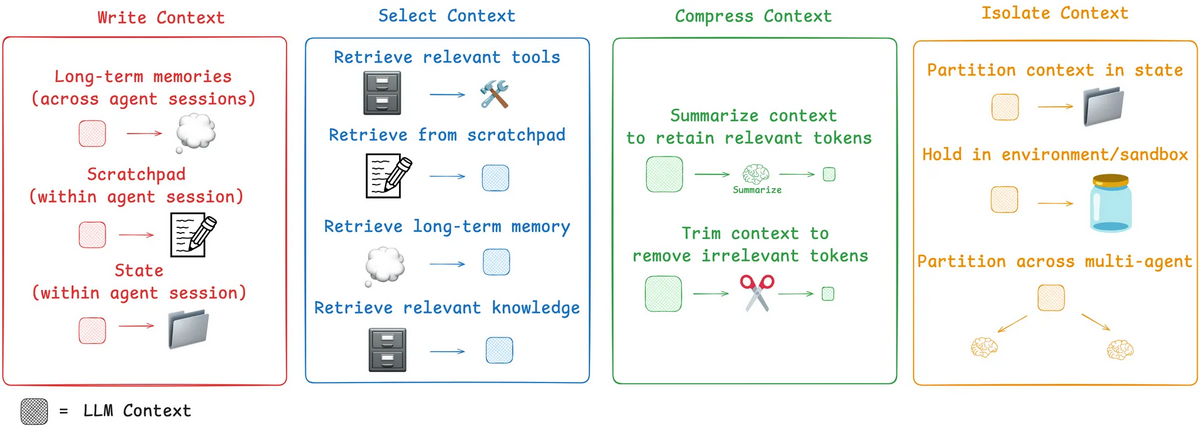
1.2 試行錯誤のポイントとなった 3 つの論点
この 4 戦略を軸に、取り組んだ内容を 3 つの観点で紹介します。
- 何を渡せば仕事ができるか(情報の形式知化)
散在する資料や暗黙知を、LLMが確実に読み取れる「知識」としてどう整えるか - どう思考の状態を保つか(文脈の引継ぎ)
会話の長期化による劣化を防ぐために、一連のプロセスをどう区切り、成果物を引き継いでいくか - どう期待通りに動いてもらうか(振る舞いの実装)
実現したい業務フローに対し、ツールの機能をどう組み合わせてAgentの動きを定義するか
1 や 2 でお話しすることは、開発者目線だと、目新しいテクニックというよりはこれまで大切にされてきた基本に近いものかもしれません。ただ、非開発業務で実践してみてもやっぱりこれが大事なんだな、という感覚がありました。そんな私たちの実践知もあわせて紹介します。
3 に関しては、GitHub Copilot Agent を前提としています。特に handoff は Copilot 固有の機能なので、他のツールでは別の工夫が必要になるかもしれません。私たちの業務(技術調査が中心など)に合わせた内容ですが、Agent を業務に組み込むときの考え方の一例として、何かのヒントになれば幸いです。
2. 何を渡せば仕事ができるか
エージェントも前提知識がないことには仕事のしようがないので、まずは何を読ませるかという視界をどう整えてあげるか。そこから話を始めることにします。
2.1 エージェントに「材料」をすべて渡す
最初に取り組んだのは、問い合わせ対応に必要な情報を git submodule で一つに集約した「巨大リポジトリ」を作ることでした。コードもマニュアルも、git clone 一発ですべてが手元に揃う。いわば、エージェントにまず物理的な視界(Select)を与える作業です。まずは必要な情報をすべてエージェントの目の前に置く。物理的な土台を作るだけでも、一定の成果はありました。
2.2 暗黙知となっていた「対応の作法」を言語化する
ただ、材料を揃えただけでは、的外れな回答が目立ちました。文脈を知らないエージェントが、足りない情報を勝手な推測で補って回答を作ってしまう。そういう状況でした。
原因は、ソースコードや Wiki といった「情報の断片」はあっても、それをどう扱うかという 「仕事の作法」 が欠けていたことでした。
問い合わせ対応は、調査結果をそのまま伝えればよいわけではありません。相手が求めている情報をどう選ぶか。どの順番で伝えるか。出してよい情報の境界線はどこか。どこまでを今回の合意の着地点とするか。
こうした対応の要諦は、熟練メンバーなら無意識にやっていることです。Wiki を作る際にも、わざわざ書くのは冗長だと感じて、あえて省いてきた部分でした。これを丁寧に言語化(Write)することが、非開発系の業務においては特に重要でした。
具体的には、いまはどのフェーズなのか。目的は何か。何を成果物として、どんな観点で取り組むのか。そういった業務フローを一つずつ書き出していきました。
2.3 業務フローを書いたら、そのままエージェントへのインプットになった
ポイントは、AI のための特別なファイルを作ったわけではない、ということです。複雑なスクリプトを書いたわけではなく、あくまで「こういうときはこうする」というレベルの業務知識を整えただけ。それがそのまま、Agent へのインプットになりました。
Agent 定義の設計では、Anthropic の Progressive Disclosure(段階的開示) の考え方も参考にしました。「新人向けオンボーディングガイド」のメタファで設計すると良いという話で、納得感がありました。
Skills は「新人向けオンボーディングガイド」のメタファーで考えると設計しやすい。
— Equipping agents for the real world with Agent Skills — Anthropic Engineering
3. どう思考の状態を保つか
「何を渡すか」を整えたら、次は「どうやり取りするか」の話です。
3.1 一つの長い会話は劣化する
はじめは何も考えず、手軽に1つのチャットセッションですべてを完結させようとしていました。調査から回答方針の作成、回答文作成、レビューまで。
ところが、会話が長くなるにつれ、エージェントの挙動が明らかに怪しくなりました。さっき調査したはずのことを忘れたり、同じことを何度も聞き返してきたり。あるいは、前後のつじつまが合わない回答を平気で出力し始める。
こうした劣化は Lost in Conversation という現象として知られています。Philippe Laban らによると、マルチターンの会話では、わずか 2 ターン目から性能低下が始まり、精度が大幅に落ちてしまうのだそうです。
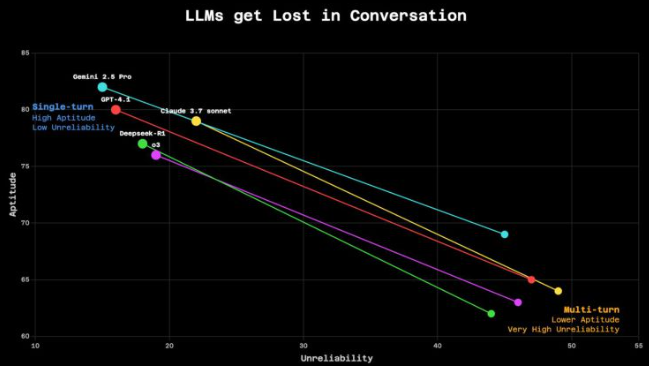
これは2025年の調査ですが、一方で、いまの多くのモデルの挙動をみていると、コンテキストウィンドウが圧迫され始めると、会話を要約して空きを作っている様子がみてとれます。ただ、その要約の過程で必要な情報が抜け落ちてしまうことが頻繁に起こっていて困るなぁと思うときもあります。特に不具合調査では意外なところにヒントが落ちていたりするので。
また、Lost in the Middle と呼ばれるように、情報量が増えるほど「中ほどに書かれた情報」を軽視してしまう性質もあります。
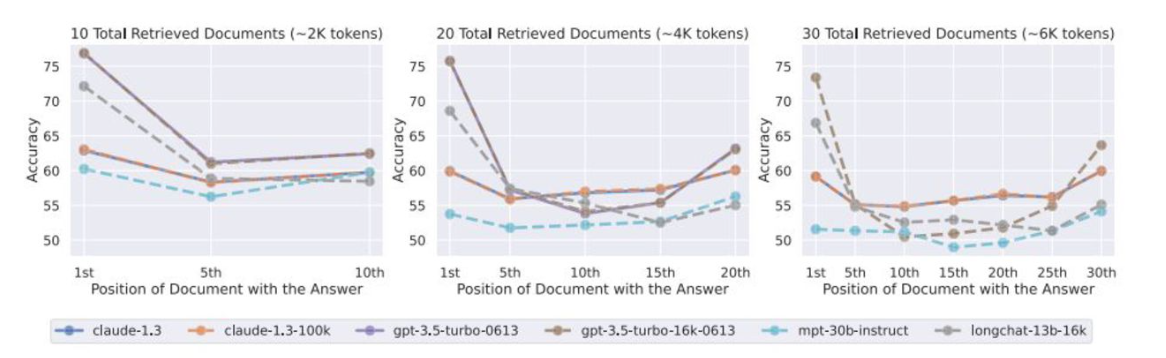
Lost in the Middle: How Language Models Use Long Contexts (2024)
結局、一つの会話で全部をこなすのは、そもそも筋が悪かったということでした。現場で感じていた「なんだか話が通じなくなる」という感触の正体が見えました。
3.2 いつでもセッションを捨てられるよう、成果物をファイルに「逃がす」
長い会話が劣化するなら、いつでもセッションを切り直せる状態にすればいい。ということで、履歴という曖昧な記憶に頼るのをやめて、成果物を「記録」としてファイルに逃がす方針にしてみました(Compress & Isolate)。
具体的には、まず 会話履歴.md を用意し、調査工程ではそれを読み込んで 調査結果.md を吐き出す。後続の工程は、その2つのファイルだけを読めば仕事ができる状態にする。という構成にしました。
このファイルを介したリレー方針には、いくつか利点がありました。
- セッションの断絶を恐れなくていい
調査フェーズなどは時間がかかり、セッションが切れがちです。こまめにファイルへ書き出しておけば、事故が起きても「最新のファイル」からいつでも再開できます。 - 情報の純度を保てる
前の会話にあった「試行錯誤のノイズ」を捨て、整理された結果だけを次に渡せます。エージェントにとっても、その方が圧倒的に読みやすいはずです。 - 人間が「横入り」しやすい
書き出されたファイルは人間も編集できます。エージェントの調査が甘ければ、人間がファイルを直接直して次へ進める。この「手戻りのしやすさ」が、実運用では大きな安心感になりました。
結局、履歴という過去の蓄積を無理に引きずるより、成果物という今の結論だけを引き継いでいく方が、設計としては筋が良かったと感じています。
4. どう期待通りに動いてもらうか
ファイルを「逃がす」方針が決まったら、次はそれを扱うAgentをどう作るかについてです。ここからはかなり今回の実装に寄った具体的な話に移っていきます。
4.1 要件整理:入出力の管理と人間との協調
Agent への業務指示に関しては、2.2で手順書を整備しているので、「このリンクを読んで指示に従ってください」で終わります。楽ちんです。
その上で、Agent に求める要件を改めて整理してみました。
- 要件①:セッションの入出力管理
- 整備した業務指示を確実に読み込めること
- 前の工程が吐き出した「成果物ファイル」を、新しいセッションのインプットとして引き継げること
- 自分の仕事を終えたら、また結果をファイルに書き出すこと
- 要件②:人間との協調
- フェーズの区切りで必ず立ち止まり、人間がレビューを挟めること(調査が間違えば回答も間違うため、あえて一気通貫にはしない)
- 次にどの工程へ進むかは、勝手に判断せずに人間の指示を仰ぐこと
「フェーズごとに停止して人間が確認する」という運用を前提に、今回は業務フローを 「起票・調査・回答方針作成・回答文作成・レビュー」のフェーズに切り分け ました。
この管理上の「区切り」を、具体的に Copilot のどの機能で具現化するか、ここからはツールの仕様に基づいた具体の話になります。
4.2 技術選定:Custom Agent指定で指示を確実にロードさせる
要件①の入出力管理において、まず解決すべきは「プロンプト以前に、そもそも指示がAgentに届くか」という問題です。GitHub Copilot には指示を置く場所がいくつかありますが、仕様上の振る舞いがそれぞれ異なります。
どれが今回の実務に適しているのか、整理したのが以下の図です。
Agentの振る舞いをどう定義するか |
結論から言えば、今回のケースでは .github/agents/*.agent.md(Custom Agent) を選ぶのが最も手堅いという判断になりました。
補足すると、当初は .github/instructions/*.instructions.md を試していましたが、無視される挙動が頻発しました。これは、applyTo で指定したファイルパターンを操作していないと指示がロードされないという仕様上の制約があるためです。コードファイルの操作を伴わない運用業務には向きませんでした。
UIから明示的に指定した瞬間に、コンテキストとして確実にロードされる。この確実性を買って、Custom Agent をベースにした構成を選んでいます。
4.3 全体像:handoff 機能による人間主導のフロー
これで要件①はクリアです。次は要件②、人間との協調です。
ここで使ったのが、GitHub Copilot の handoff 機能です。handoff とは、Agent が会話の中で次に推奨する Agent をボタンとして Copilot Chat のウィンドウに提示し、人間がワンクリックでそのエージェントを選択・起動できる仕組みです。
どの Agent を候補として提示するかは Agent 側が判断してくれるので、人間のフェーズ制御をサポートする立ち位置になります。各フェーズ(起票 → 調査 → 回答方針 → 回答文作成 → レビュー)に対応した agent.md をそれぞれ作成し、窓口となるオーケストレーター Agent がこれらを handoff 候補として提示します。人間がどのフェーズに進むかを選択する。これで、フェーズごとの停止と人間レビューが自然に実現できました。
加えて、handoff 先の Agent はメイン Agent としてフルのコンテキストウィンドウを使えます。成果物はファイルに書き出し、次の Agent がそれを読み込むので、会話履歴の蓄積による劣化もありません。
参考:利用イメージ
- 会話開始時に GitHub Copilot チャットウィンドウから 「inquiry」Custom Agent を指定
- 問い合わせ内容を貼り付け(機密情報はマスクしておく)
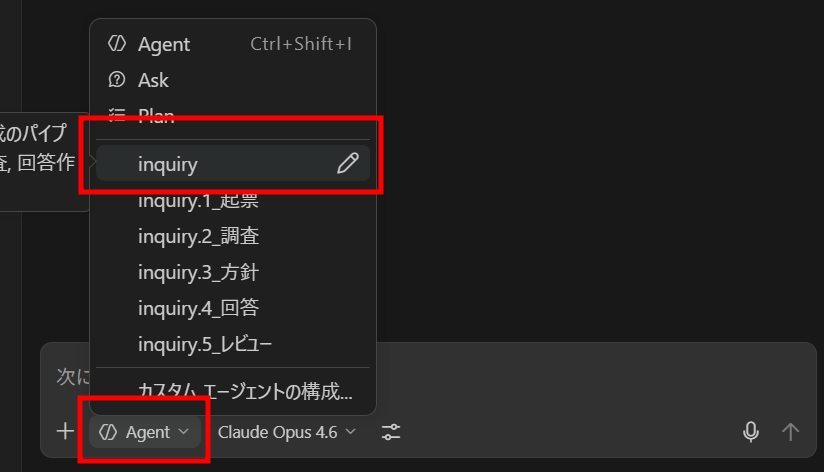
- チャット下部に次フェーズ開始ボタンが現れるので、任意を押下
- ボタン押下でagent、プロンプトが自動入力されるので送信するだけ
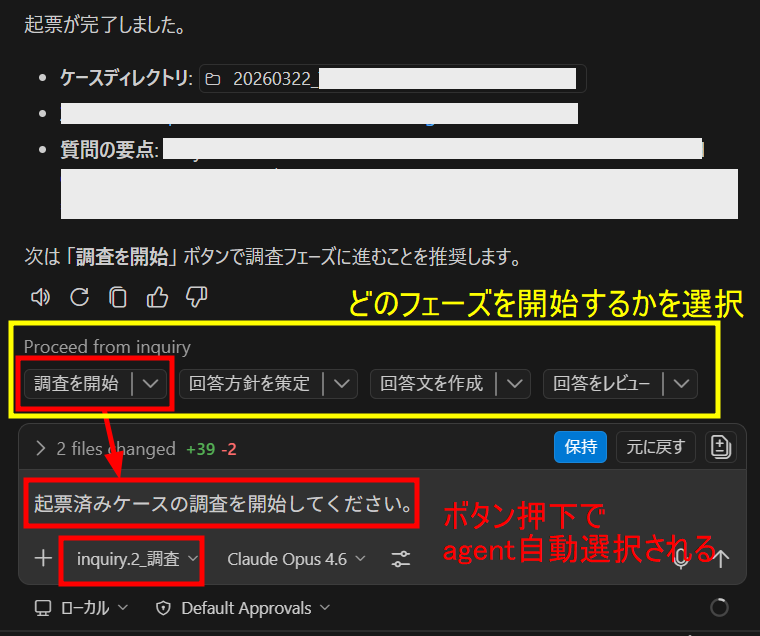
- 各フェーズが終われば次ののhandoffボタンを押下で、次のフェーズへ移行
参考:SubAgent パターンとの比較
補足になりますが、他のパターンとして、Orchestrator が SubAgent を自動で呼び出す方式(runSubagent)も検討しましたが、不採用としています。
| 比較項目 | SubAgent パターン(不採用) | handoff パターン(採用) |
|---|---|---|
| コンテキストウィンドウ | 小さい可能性(調査で途中停止する事象あり) | フル(メイン Agent として起動) |
| 人間レビュー | 挟めない(Orchestrator が自動制御) | 自然に挟める(handoff 選択時にレビュー) |
| コンテキスト分離 | ○(まっさらで起動) | ○(handoff 先もまっさらで起動) |
| 進行管理 | Orchestrator が自動で制御 | 親 Agent が候補を提示、ユーザーが選択 |
上記の比較はあくまで「人間がフェーズ間でレビューを挟む」という私たちの要件に照らしたものです。全自動化パイプラインや人間レビューが不要な定型タスク、高スループットが優先される場面では、SubAgent パターンの方が適しているケースも十分あります。
4.4 業務知識が整理されていれば、agent.md は薄くて済む
Custom Agent + handoff chain という構成が決まったところで、では agent.md に実際に何を書いたか。frontmatter と、整備した手順書ファイルへの参照リンク、成果物ファイルの入出力指示のみです。業務知識の本体はあくまで手順書ファイル側にあるので、agent.md 自体は非常に端的。高度なスクリプトも複雑なパイプラインも書いていません。業務知識を形式知化しておいたおかげで、Agent のために特別な仕組みを作り込む必要がなくなりました。業務フローの言語化がそのまま Agent へのインプットになっているので、ツールへの依存は薄く済んでいます。
scaffolding(モデル補助コード)は次のモデルで不要になる。
投資 vs 待機のトレードオフを常に意識
個人的に納得感のある考え方で、今回 agent.md を薄く保ったのも同じ理由からです。モデルが進化すれば文言を調整するだけで済むはずで、過度にツール依存した自動化は次のモデルで丸ごと不要になるリスクがあると感じています。
まとめ
今回は、お問い合わせ対応の調査~回答作成の業務を 人間とLLMでうまく協調するための運用フローについて考えてみました。
- 何を渡せば仕事ができるか(Select & Write)
暗黙知をなくし業務フローを言語化したことが、そのまま Agent へのインプットになった - どう思考の状態を保つか(Isolate & Compress)
長い会話ではコンテキスト管理が難しくなる傾向がある。会話履歴ではなくファイルをリレーすることで、新鮮なコンテキストを保てた。 - どう期待通りに動いてもらうか(Select)
handoff 機能で入出力管理と人間との協調を両立できた。
業務知識が整理されていればagent.mdは薄くて済む
モデルの進化で最適解も変わっていくと思うので、引き続き試行錯誤しながらアップデートしていくつもりです。
問い合わせ業務に限らず、LLM を業務に組み込む際の参考になる部分があれば幸いです。