
こんにちは、須田です。
今年の初めに「基幹業務もHadoopで!! -ローソンにおける店舗発注業務へのHadoop + Hive導入と その取り組みについて-」と題しまして、Hadoop / Spark Conference Japan 2016にて発表させて頂きました。
カンファレンスでの発表時は絶賛開発中だったこともあり、いかに業務要件を設計/実装に落としていったかという話を中心に行いました。
本エントリでは、「カンファレンスのその後」と題しまして、開発後の性能テストを通じて、いかにプロダクト環境に耐えられる品質にまで高めていったのかについて記載します。
ピーク時では数百HiveQL/秒を処理するこのシステムにおいて、どういった課題があり、そのために実施した対策やチューニングポイントについてまとめます。
主にHiveおよびYARNを中心にその取り組みについて記載していきます。
ぜひ本エントリを読み進めて頂く前に、カンファレンス時の資料を一読して頂ければと思います。
対応内容(ざっと整理)
チューニングの一環として検討・確認を行った項目は以下の通りです。
| 対象 | 対応内容 | 対応詳細 |
|---|---|---|
| Hive | クエリチューニング | ・パーティショニング ・作成ワーク数の削減 |
| Hive | ファイルフォーマットの変更 | - |
| Hive | データ圧縮 | ・圧縮アルゴリズムの選択 ・中間データの圧縮 ・転送データの圧縮 |
| Hive | アクセスプランの効率化 | ・Vectrizationの有効化 ・CBO有効化 |
| Hive | 処理プロセス(スレッド数)の効率化 | ・Reducer数の調整 ・Shuffleコネクション数の調整 |
| Hive | 結合処理の最適化 | ・バケットの利用 ・MapJoinの利用 |
| Hive | リソース利用の最適化 | ・JVMヒープサイズの変更 ・Tezコンテナの再利用 |
| YARN | コンテナ配布の最適化 | ・割当コンテナサイズの範囲調整 ・コンテナサイズの変更 |
| YARN | スケジューラ調整 | ・スケジューラの変更 ・処理用キューの設定 |
| HDFS | NameNode関連 | ・NameNode処理スレッド数調整 |
| その他 | システム構成変更 | タスクインスタンスグループの追加 |
上記に記した項目は一通り性能数値を取得し比較検討を行ったものです。
中にはそもそも採用に至らなかったものもあります。
今回は上記の中でも特に効果のあったものや、本システムで特徴的だったもののみをピックアップして取り扱います。
以下のパートに分けてこの後対応内容の詳細について記載します。
- 1. Hive編
- 2. YARN編
1. Hive編
まずはHiveに関連するチューニング対応の内容について記載します。
対応内容としては大きく以下の2つです。
- 1-1. HiveQLチューニング
- 1-2. Hiveパラメータチューニング
対応した内容の中でも効果が大きかったもの、本システムに特徴的なものを中心に取り上げていきます。
1-1. HiveQLチューニング
HiveQLのチューニングは正攻法で行っています。
開発に入る前にHiveQLのコーディング規約を整備しておいたおかげで、処理負荷が特定ノードに寄ってしまうような処理(ソート処理など)は最低限に留めることができていました。
そのため、チューニングの観点としては以下にHiveにとって効率的に処理ができるようにワーク作成処理を組み替えていくか、作りかえていくかというものでした。
主に実施したHiveQLチューニングは以下の通りです。
- a) 作成ワーク数の削減
- b) パーティション作成の廃止
a) 作成ワーク数の削減
ソースコードおよびHive実行プランの可読性を上げる(効率の悪い書き方をしているクエリがないかといったレビュー観点でも見通しが良くなる)ために小さい単位でワーク作成処理を行うことを大方針としていました。
そのため、HiveQLの開発規約の中ではワークテーブルの作成基準を明確にしていました。
例えば以下のような感じです。
- 1ワーク処理の中での結合数に上限を設け、その上限を超えるようであればワークを分割する
- インラインビューが2段階以上になる場合はワークを分割する etc
基本的には規約に基づくワーク分割の方針で問題なかったのですが、規約に厳密に則ったために、かえって不効率なワーク処理も見受けられました。
例えば、1つのクエリで結合できるテーブル数に上限(最大5としていました)を設けていたために、同一のワークテーブルに追記していくような処理も、クエリが分割されていました。
そのためさばくデータ量的にも1つのクエリとしてまとめあげて処理した方がI/O効率が良さそうな処理も細かく割れてしまってました。
//これまでは規約に則っていたので、以下のようにクエリが分割されてしまっているものもあった |
こういった同一のワークテーブルへのSELECT INSERT処理のようなものはUNION(もしくはUNION ALL)などでまとめあげて1処理に集約していきました。
UNION(もしくはUNION ALL)で繋ぐぶんには、コメントで区切るなどで極端なソースの可読性劣化もなかったので許容することにしました。
また、プランの可読性についても、UNION ALLでまとめていく分には、どこが処理の境目になっているかがわかりやすいので、依然として把握しやすい状態を保てていたため特段問題とはなりませんでした。
//同一ワークテーブルへの追記処理はまとめあげる |
b) パーティション作成の廃止
パーティション作成はいわゆるHiveにおける王道チューニングかもしれませんが、本システムでは利用していません。
当初は全マスタデータ作成処理の結合時に利用される共通キー(店舗コード)をもとにdynamic partitionによる動的パーティショニングを実施していました。
実際に本番相当の各種データを準備してみると、全部が全部巨大なデータサイズではなかったこともあり、逆に無理にパーティショニングすることで以下の弊害がありました。
- パーティション後のファイルサイズが小さくなりがちで、結果I/O効率が悪くなっていった
- パーティション作成処理のオーバーヘッドの積み重ねが処理時間のウェイトを占めるようになっていた
本システムで主に扱うのがマスタデータということもあり、その性質上トランザクション系のデータに比べてボリュームがそれほど大きくないということから、パーティションは作成せずパワーでやりきる方が全体としてパフォーマンスが良い結果となりました。
1-2. Hiveパラメータチューニング
特に効果があった対応としては以下のものでした。
- a) Hive on Tezへの変更
- b) MapJoinの積極的活用
- c) Reducer数の変更
- d) 圧縮とファイルフォーマット
a) Hive on Tezへの変更
発表当時は以下の理由によりHiveエンジンの実行エンジンMapReduceを利用していました。
- 当時のEMRの公開バージョンではTezが正式サポートされていなかった
- 巨大なデータの結合を繰り返す処理が多く、オンメモリでの扱いに慎重だった
前者については、EMRの起動時にインストールアプリケーションとして標準で提供されていなかったことをさしています。
EMRへのTezインストールスクリプトは提供されていたため、ステップ処理でインストール処理を記述すればインストール自体は可能だったため、事前検証は上記提供スクリプトを利用していました。
また、後者ですが確実にクエリが流れ切るということを重視し、必ずディスクを介するMapReduceでの処理する方が安心感がありました。
しかし、開発後の性能テストにて本番相当のデータ量を用いてテストを実施すると、どうしてもMapReduce特有のオーバーヘッドやディスクI/OによるI/Oネックが顕著になってしまい、思っていた以上に処理性能が出ませんでした。
特に本システムの開発においては、ソースコードおよびHiveQL実行プランの可読性を重視するため、なるべくワークテーブルは小さく保ち、小さいワークテーブルを経ながら処理を実施する方針としていたために、上記のオーバーヘッドがチリツモで大きくなっていました。
そんな矢先、EMRバージョン4.7にて正式にTezサポートされたこともあり、Hiveの実行エンジンをMapReduceからTezへ切り替えることにしました。
その結果、Tezへの切り替えのみで処理時間をおよそ1/3にまで減らすことができました。
以下はデータノードのHDFSへのデータ読み取り・書き込み時のブロック操作数ですが、かなり顕著に差が出ていました。
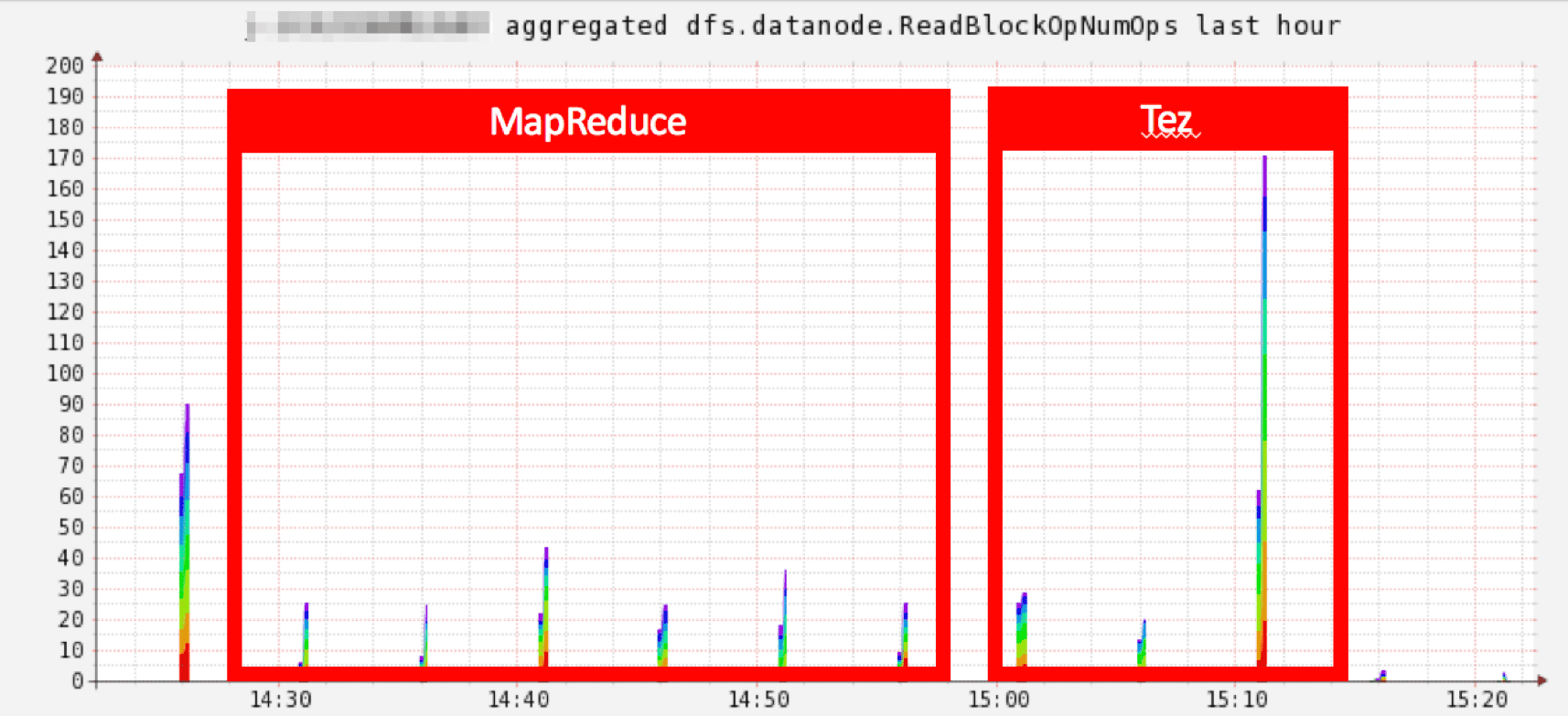
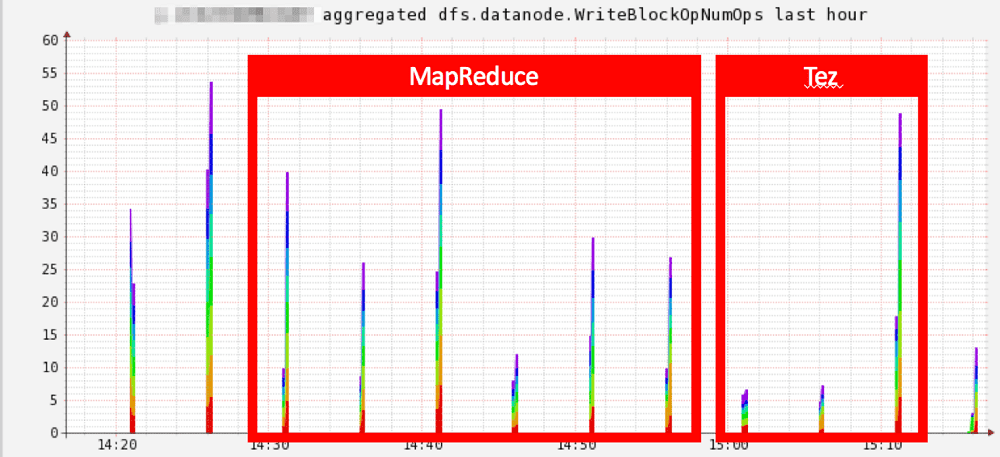
しかし、メモリ関連のパラメータチューニングは必須で、そのためメモリ関連のパラメータ、特にYARNでのTezコンテナサイズの調整をメインに対応していきました。
この詳細については後半のYARN編にて記載します。
b) MapJoinの積極的活用
本システムでは実行されるクエリ数も多く、各クエリを見極めてヒント句でMapJoinに縛るのが難しかったこともあり、以下パラメータにより自動的にMapJoinへ誘導する運用としました。
- hive.auto.convert.join
- hive.auto.convert.join.noconditionaltask.size
hive.auto.convert.join.noconditionaltask.sizeの値ですが、これは性能テストの中で本番相当のデータ量をもとに実行サイズを調整していきました。
c) Reducer数の変更
Tezの変更により、中間データのディスクI/Oは減らせたものの、最終的にできあがるマスタデータのうち、データサイズが大きなものは依然として最後のHDFSへのファイル書き込みがボトルネックとなってしまっていました。
そこで以下パラメータにより起動するReducer数を調整していきました。
- hive.exec.reducers.bytes.per.reducer
最後の書き込み処理だけを考慮してReducer数を起動しすぎてしまうと、ワーク処理の過程にも影響がでてしまう(プロセスが起動しすぎてしまう)のもあり、これは性能テストの中で調整をしていきました。
現状は一律64MBとしています。
Reducer数を上げすぎてしまうと、ファイルが小さくなりすぎてI/O効率が悪くなってしまうのではないかと思われるかもしれません。
本システムにおいては、最終的にできあがったマスタデータはRDSへエクスポートして利用されます。
そのため、できあがったマスタデータが細かくファイルが割れてしまったとしても、直接EMRに対して検索クエリを実行するわけではなかったので、このような対応としました。
d) 圧縮とファイルフォーマット
これもまたまた王道チューニングですね。
圧縮オプションとファイルフォーマットの組み合わせは、ファイル分割が可能な組み合わせとなるよう考慮し、性能テストの中で最も性能がよかった以下の組み合わせを採用しています。
- ファイルフォーマット:SequeanceFile
- 圧縮オプション: Snappy
実現可能な組み合わせのパターンは一通り試したのですが、本システムでは結合をメインとしたワーク処理を積み重ねていく処理のためか、ORCなどのカラムなファイルフォーマットだと処理性能が出ず、Sequence Fileを採用することになりました。
2. YARN編
本システムで一番肝となったのがYARN関連の対応でした。
具体的には以下の対応を中心に実施しました。
- 2-1. コンテナサイズの調整
- 2-2. 処理特性に応じたキュー設定
なおYARNの基本的な仕組みについての説明は省略いたしますのでご了承ください。
2-1. コンテナサイズの調整
今回YARNのリソースコントロール配下におかれるアプリケーションは以下でした。
- a) MRアプリケーション(Apache Sqoopで利用)
- b) Tezアプリケーション
アプリケーションごとに基準となるコンテナサイズ(主にメモリサイズ)を変えています。
a) MRアプリケーション
MRアプリケーションについて、SqoopによるRDSからのインポート/エクスポート処理はsqoopコマンド実行時にmap数の指定が可能です。
そのため、消費コンテナ数を調整可能なので、パフォーマンスは落とさず1コンテナあたりのメモリサイズをどこまで減らすことができるかという観点でメモリサイズの調整行っていきました。
b) Tezアプリケーション
Tezアプリケーションの場合、Sqoopのような利用コンテナ数の調整は難しいため、性能テストの中でコンテナサイズを調整していきました。
主に以下の観点でコンテナサイズの調整を実施しました。
- MapJoinを行えるだけのメモリ確保が可能か(同時にhive.auto.convert.join.noconditionaltask.sizeの調整も実施)
- 同時実行されるジョブ数に割り当てられるだけのコンテナサイズの確保が可能か
なおコンテナサイズで指定したメモリの利用内訳については、下記を参考にしました。
これはもう地道に様々なコンテナサイズで処理を回してみて、適切な値を出しました。
最終的にTezアプリケーションでのコンテナサイズはメモリ4GB・vCPU1コア/コンテナが標準として落ち着きました。
-- コンテナサイズ |
ただし、Hive編で記載した通り、MapJoinに処理をよせるにあたり、作成するマスタデータによってはコンテナあたりのメモリサイズを大きくする必要がありました。
そういったマスタデータ作成処理のみ例外的にコンテナのメモリサイズを大きくするといった対応を実施しています。
なお、処理ピーク時に同時稼働ジョブがかなり多くこともあり、なるべくクラスタトータルでメモリの使用を抑えたかったこともあり、TezアプリケーションもMRアプリケーションも起動するApplication Master用のコンテナサイズをデフォルトから小さくしています。
2-2. 処理特性に応じたキュー設定
本システムではピーク時では常に数百のクエリを処理し続けるといったかなりハードワークです。
また作成するマスタデータごとに処理の複雑度合や利用するテーブルのデータサイズなどかなりまちまちです。
そのため、作成するマスタデータの業務優先度やそのワークロードに応じたリソース配分が必要となりました。
そのために以下の対応を実施しました。
- a) YARNのスケジューラの変更
- b) 業務優先度や処理特性に応じたキュー設定とリソース制御
a) YARNのスケジューラ変更
YARNのデフォルトのスケジューラはFIFO(First in First Out)であるため、最初に実行されたジョブに利用可能なコンテナをほとんど持って行かれてしまい、同時に複数ジョブを投入してもペンディングが多発していました。
そのためジョブの実行多重度をあげるために他のスケジューリングアルゴリズムを採用することにしました。
YARNでは他にFair Scheduler、Capacity Schedulerといったスケジューリングアルゴリズムを選択可能なのですが、今回はFair Schedulerを採用することにしました。
Capacity Schedulerでは、利用リソース量に基づいたスケジューリングが可能なのです。
ただFair Shcedulerでもキュー単位でリソース使用量や重み付けが可能であったのと、Capacity Schedulerの場合、キュー間ではリソース利用に応じて細かな制御は可能なのですが、同一キューに投入されたジョブはFIFOで処理されていたため、今回の要件には少し不足気味だったため採用を見送りました。(もしかしたら挙動を変える方法があった…? )
b) 業務優先度や処理特性に応じたキュー設定とリソース制御
クラスタ上で複数のジョブが同時に走るようになったものの、FairSchedulerでは特に設定をしない限りはクラスタに投入されたジョブはみな等しくリソースが按分されて処理が行われます。
そのため、それほどリソースを利用しなくても処理が十分回るもの、そうでないものも全て同じくリソースが按分されることになります。
今回のバッチ処理の特性としては、実行多重度がかなり高く、ひとつひとつの作成処理量の重さもばらつきがあります。
そのため、同時に処理する量が増えてくるほど一向に処理が完了しないマスタ作成処理もでてきてしまうといった事態が発生していました。
そこで必要となるリソース量や業務的な優先度を鑑みて、ジョブを投入するキューを分けることにしました。
キュー見直し後の構成は以下のようになりました。
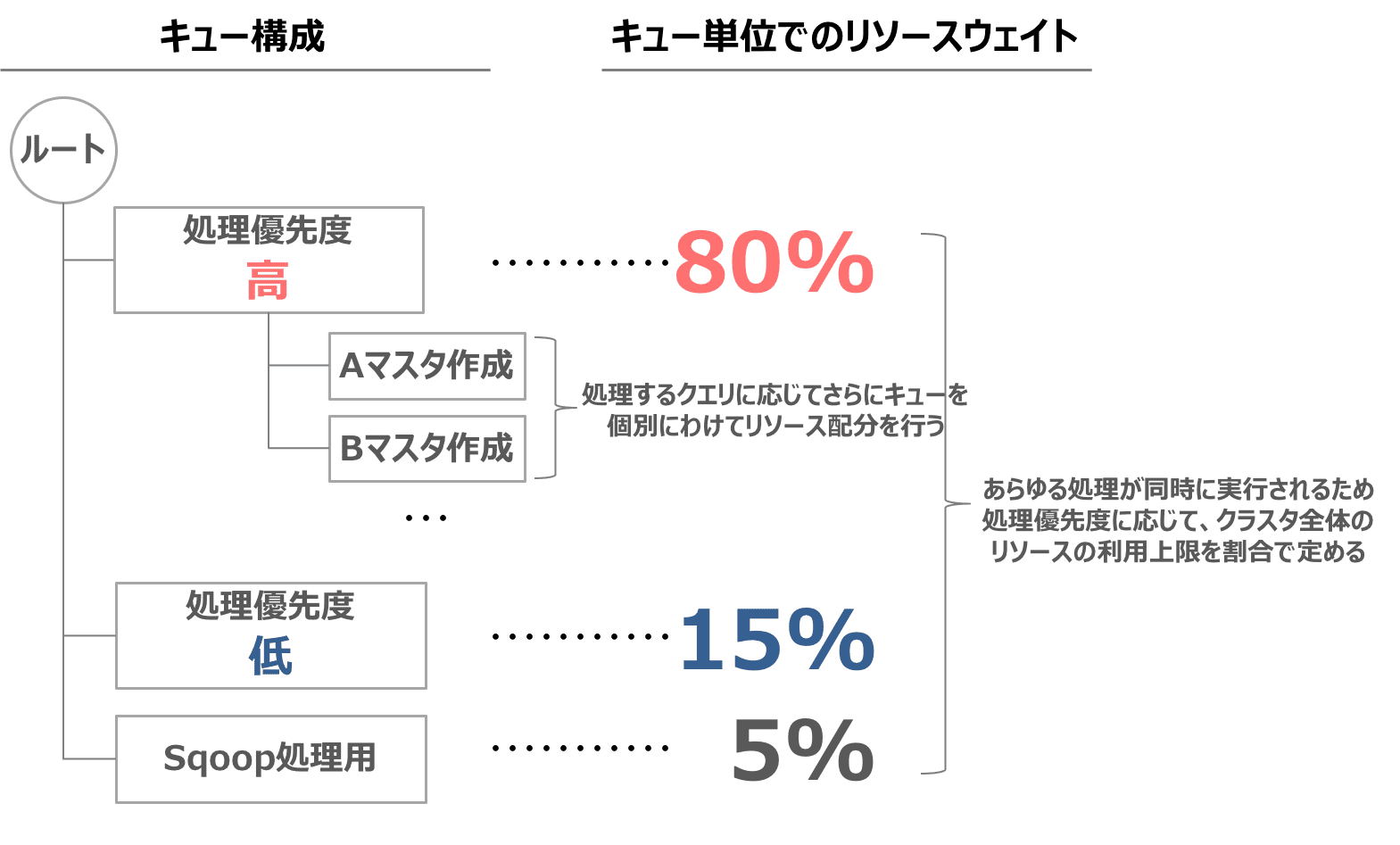
キュー単位に指定している利用可能なリソースウェイトですが、これは最大ピーク時の多重度を考慮した割合としています。
実際に性能数値を確認しながら最も全体として短い時間で終わるような重み付けを探っていった具体です。
そのため、ピーク時間帯以外で他キューに空きがあればその分のリソースを他キューからも利用できるようにしています。
キュー単位でのリソース制御ですが、リソースを絶対量で指定もできますが、割合による重み付けを利用しています。
理由としては、今後クラスタサイズが変更になりトータルのリソース量が変わってしまった際に都度細かな数値を見直さなくても大丈夫なようにするためです。
最後に
ざっとですが、これまでの取り組みについて記載しました。
実はもう1つ大きな戦いがあって、EMRで作成したマスタデータをAPI参照のためにRDS(MySQL)へSqoopでエクスポートする処理がなかなか性能がでず、ごりごりMySQLチューニングを実施した話とか、その頑張りをあっさりAmazon Auroraに追いつかれてしまった話などまだまだ話は尽きないのですが、それはまた別の機会に。
お付き合い頂きありがとうございました。