はじめに
こんにちは、Strategic AI Group(通称 : SAIG)の岩田です。
前回のICLR2018記事に引き続いての投稿になります。
今回は少し話題を変えまして、先日出展したIoT/M2M展のご報告と、そこで披露した音声認識デモについてのご紹介となります。
IoT/M2M 展のご紹介
- Japan IT Weekという非常に大きな展示会が年に3回あり、その1つとしてIoT/M2M展があります
- IoT/M2M以外にもクラウドやAI・自動化、情報セキュリティ等、企業として関心が高いものブースが沢山あります
- 国内最大級の展示会イベントなので、とにかく人が多いです!(通路を歩くのもやっと・・)
展示のきっかけ
- IoT/M2M展には弊社のグループ会社である TrexEdge が出展を決めました
- 共同出展という形で、ブース内の一部を借りてFutureのAIサービスも紹介を行なう運びとなりました

出展物
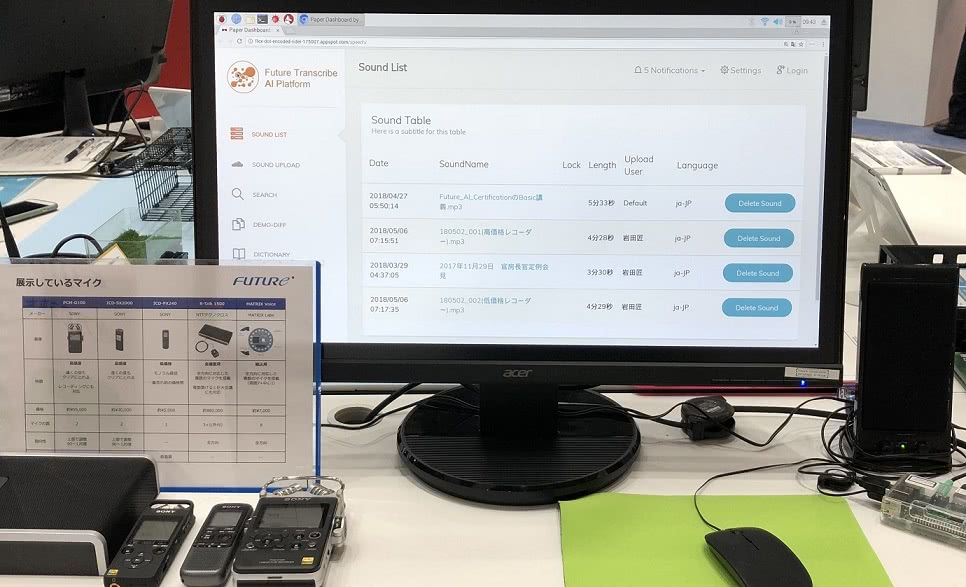
2017年より開発していた音声認識サービスを展示してきました。
今回は展示(音声認識サービス)としてのポイントをいくつかご紹介します。
※そもそも音声認識とは? という方は是非こちらを参照ください。
自称・世界一わかりやすい音声認識入門
サービス化への道のり
音声認識サービスとしては、Google Cloud Platform の Speech APIを用いています。
自分たちでスクラッチでゼロから開発するのではなく、クラウド機械学習API を利用するという選択をしました。
理由は以下の2点があります。
- Google/Amazon/Microsoft/Apple等々のITガリバーと認識エンジンレベルで競い合うことはハードルが高く、差別化も難しい
- クイックにデモサービスを作成し、実用段階を確かめたい(音声データの収集、認識エンジン作成の手間を削減する)
Google APIの採用理由は、自社内で比較した中で最も精度が高かったためです。
早速、これを用いて「プロタイプ」を作り、触ってもらって実用レベルなのかを判断してみました(わくわく)。
…しかし、社内での判断としては「クラウドAPIを単純に呼び出すレベルでは実用としてはまだ遠い」というものでした。
そのため、クラウドAPIを活用し、その上に肉付けすることによって、「プロトタイプ」ラインから「現場で使える」ラインに昇華するという戦略を考えました。
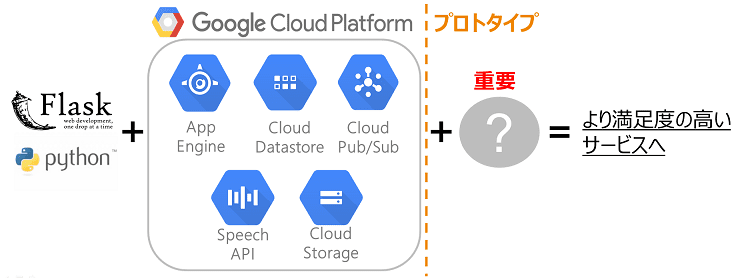
「現場で使える」ラインにするために出した答えとしては、音声認識結果に対する後処理校正機能でした。
業界に関連するコーパスと作成した言語モデルを用いて、誤りと思われる部分を可視化してあげます。
また、Google側では現状として結果に句読点が入らないなど、実用で考えたときに足りない部分がいくつかあります。その部分を補い、そして顧客に合った形でサービス(UI/UX・AI/システムの機能運用)をカスタマイズする。
もちろん理想としては、人の手を煩わせない(どんな音声でも正解率100%)ですが録音ユースケースによっては、満点を求められることはないケースもあります。
したがって、ミニマムとしてそのケースの品質は担保し徐々に適用できるケースを広げていくというのがサービスの始まりになっています。
サービス名
本サービスとしての名称は Future Transcribe AI Platform として展開を実施していきます。

こうしてサービスの名前も決まり、そして縁がありIoT/M2M展示会に出展できることとなりました。
当日は多くの質問や引き合いがあり、嬉しい限りでした。
※注意
上記の書き方だと、特に考えもなしにプロトタイプを作った感があるので、少し補足しておきます。
音声認識には下記2点で優遇すべきポイントがあると認識しています。
- 音声認識(文字おこし)をバリバリ使ってますという実例報告は多くない
- 顧客によってはインプットとなる音声の録音ユースケースが多い
この2点を踏まえて、作ってみる価値があるという結論になってからの Go としています。
業務観点として必要なマイクの選定
サービスとして、認識エンジンの精度を向上させるのはもちろんですが、インプットとなる音声自体の質も重要です。
単一指向性や全指向性、付属するマイクの数、そして価格帯等を観点として複数マイクをならべた検証も現場で利用する上では必要です。
この録音ユースケースに対してマイクの自体の比較と、認識結果の比較の展示も行いました。
例えば、こちらはインタビューに対しての低価格帯レコーダー vs 高価格帯レコーダーの認識結果です。

一部変換ミスもありますが、言葉尻などの細かい部分で高価格帯は正しく認識できています。
では、この結果から例えば
- 低価格帯のマイクでもどのように録音できれば精度が向上するのか
- マイクの組み合わせによって、より精度を向上させることができるのか
といった疑問やアイデアがでてくるかと思います。
この点は社内で研究している最中ですので、何か有益な結果がでましたらまた公開できればと思います。
おわりに
今回は展示(音声認識サービス)にスポットを当てた話となりました。
サービスとしてのご紹介となってしまいましたが、弊社のSAIGグループでは、「AI導入の検討」から「カスタマイズされたAIシステム構築・運用」まで一貫してお手伝いさせていただきます。
お問い合わせはこちらからお願いします。
また、10月にございます人工知能/ビジネスAI 2018にもブースを出展する予定ですので是非お立ち寄りいただければと思います。