
みなさん、初めまして、お久しぶりです、こんにちは。
フューチャーアーキテクト2018年新卒入社、1年目エンジニアのTIG(Technology Innovation Group)所属の澤田周吾です。大学では機械航空工学を専攻しており、学生時代のインターンなどがキッカケで入社を決意しました。
実は、本記事でフューチャーテックブログの2記事目となります。インターン時代も ジャガイモARの記事 を書かせて頂きました。入社してからもこうして業務で学んだIT技術を記事に書くという機会を貰え、なんだか懐かしいやら感慨深いやらの思いで一杯です。
さて、3ヶ月の新人研修後にすぐに配属されたプロジェクトで、AWSを使ったビックデータ分析のための基盤構築をお手伝いしています。わたしは分析のための前処理であるETL(Extract、Transform、Load)処理部分をちょっと変わった性格の先輩方と一緒に開発しており、今回はそれに用いているサービスであるAWS Glueについて紹介いたします。
※記事は2回にわけて発信していきたいと考えています。
第一弾として、題名の大規模データを処理するために行った様々な工夫を説明する前に、Glueの概要や開発Tips、制約について書かせていただきます
第二弾はこちらをどうぞ。
AWS Glueとは
ご存知の方も多いかと思いますが、簡単にGlueについての説明です。
AWS Glue は抽出、変換、ロード (ETL) を行う完全マネージド型のサービスで、お客様の分析用データの準備とロードを簡単にします。AWS マネジメントコンソールで数回クリックするだけで、ETL ジョブを作成および実行できます。
引用:AWS公式サイト
簡単に言うと、「データ処理を行うサービス」です。
公式サイトにも書かれていますが、Glueの特徴として、5点挙げられます。
- AWSの1つであること
- ETL処理を行うサービスであること
- 完全マネージド型であること
- Scala、Python、Apache Spark を使用できること
- 並立分散処理ができること
今回実現したいこと
S3やDynamoDBに配備された入力データを、少々複雑な加工ロジックが入ったETL処理を何度か繰り返し、蓄積用のDynamoDBと、分析用のS3に出力することです。
入力のマスタデータは日次程度の洗い替えでOK、入力データは10分毎にzip圧縮後で35GB程度がDataLakeに供給され、それらを逐次バッチ的に処理します。ETLの処理ウィンドウ時間は10分以内となり、1日では合計5TBに及びます。
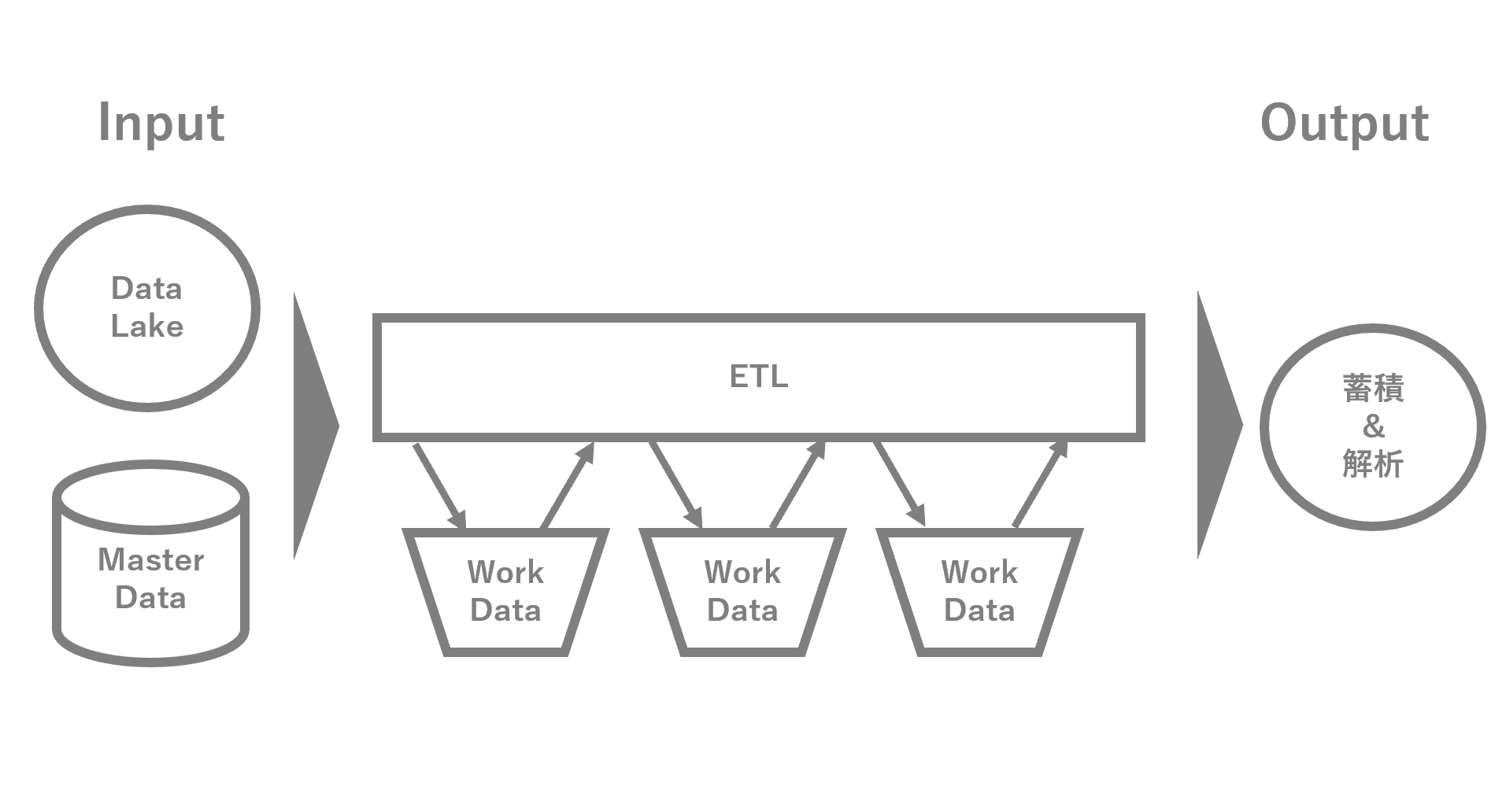
データ量が多いため、Glueが利用できる前だとSpark on EMRで処理することを検討していたと思います。EMRも良いサービスだと認識していますが、10分毎に処理する要件だと、EMRクラスタを常時立ち上げざる得ないため、EMRの保守運用を考えるとマネージドでSparkを扱えるGlueを採用したほうが良いのでは? という判断がなされました。他にもAWS Athenaなども候補に上がりましたが、読み込み時のパーティションは可能なものの、2018.08時点ではクエリ結果をS3に書き込む際に、DynamicPartitionができないという点がネックで採用には至りませんでした。
ETL処理の中身を簡単に言うと..。
- 処理対象のフィルター(例: 異常値の排除など)
- コンテンツへのエンリッチメント(例: マスタデータと結合し非正規化処理など)
- 多様な分析軸でのグルーピング(例: ユーザID軸、ユーザの属性軸など)
- 逆ジオコーディングのために外部サービスにアクセスが必要
- k-meansライクなクラスタリング処理が必要
などがあります。
特に4,5は少し毛色が変わっており、処理特性の違いからETLのパイプラインを当初より少し多めに分割する必要性がでてきました。今回は4つのステップに分割しました。そのため、各ステップは10分よりずっと短い時間で処理を完了させる必要があります。
また、今回の要件だとワークフローは複雑な分岐や待ち合わせが存在せず、前のジョブAが終わったら素直に後ろのジョブBを起動すれば良いだけだったため、StepFunctionなどを導入せずGlueで完結して構築しています。
EMR と Glue 比較
EMRとGlueですが、アプリケーションの実装としてはどちらもSparkを利用する以上は差が出ないため、インフラレベルで比較した表となります。どうやら、Glueは内部的にEMRを起動させているようなので、GlueはSparkクラスタを構築せずジョブが実行できるといった仕組みと捉えたほうが理解しやすいかと思います。
EMRの方が細かくチューニングが可能ですが、先に述べたように保守運用性の観点からGlueを採用しました。
| # | EMR | Glue |
|---|---|---|
| Pros | ブートストラップアクション/ステップ処理を通じてOSレベルからの設定変更が可能 | ランタイム環境がフルマネージドで提供されるため、クラスタの管理が不要 |
| コアノード/タスクノード数を調整することでシステムリソース量の調整が可能 | サービスとしての単一障害点がない | |
| Spark以外のツールを利用可能 | データカタログを他AWSサービスと共有可能 | |
| Cons | マスタノードが単一障害点(特に常駐起動させておく場合にネック) | ランタイム環境がフルマネージドで提供されるため、OSレベル・クラスタレベルでの設定変更が不可能(システムリソースは調整可能) |
| EMRクラスタの設定や起動処理の設計・実装が必要 | ー |
Glueで行えること
具体的なイメージが湧きにくいと思いますので、早速ですが、コードベースでどういうことができるかいくつか例示していきたいと思います。
今回、コードはPythonで説明していきます。
S3上のファイルの読み書き
以下のコードでS3に対して読み込み・書き込みが行えます。
ファイル形式を変更することで、CSV、JSON、Parquetなどの形式に対応できます。
Glueで定義されたデータ構造のDynamicFrameを使っていきます。
使い方はSparkのDataFrameのように扱うことができます。
df = glueContext.create_dynamic_frame.from_options( |
datasink = glueContext.write_dynamic_frame.from_options( |
他のファイル形式についてはAWS Glue の ETL 出力用の形式オプション を参考ください。CSVであれば区切り文字やヘッダ行出力の有無もオプションで指定できます。
DaynamoDBからの読み込み、書き込み
DynamoDBへのアクセスはAWS SDK for Pythonなboto3を利用します。
2018.08時点では標準のコネクタは存在しないようです。
dynamo_region="AWSリージョン名" |
あとは素直にget, put すれば読み書きできます。
table = dynamodb.Table("テーブル名") |
table = dynamodb.Table("テーブル名") |
もし、DynamoDBへのR/Wを行う場合は、Read/Writeのキャパシティーユニットを確認するとともに、レスポンスでスループット超過時のエラーハンドリングもお忘れないように注意ください。
加工処理
入力で取得したデータは例えば以下のようにSQLクエリを用いて加工できます。
# DynamicFrameをDataFrameに変換 |
今回の開発では情報量が多いことと開発チームメンバーのスキルセットからDataFrameに変換後にSQLで加工する手法を使いました。
ジョブのワークフロー
GlueのTriggerを利用することで、Glue内でジョブのワークフローを作ることができます。
また、起動を制御するためのTriggerは3種類用意されています。
- Triggerの開始をタイマーで行う = スケジュール
- ジョブイベントが監視対象リストに一致した場合に行う = ジョブイベント
- 手動で開始させる = オンデマンド
1のスケジュールトリガー、3のオンデマンドトリガーについてはイメージがつくと思います。
2のジョブイベントトリガーについて補足していきます。
ジョブイベントトリガーは、ジョブXが終わったら次のジョブYを起動する、といった依存関係を設定できます。
具体的にはジョブイベントトリガー作成時には以下の項目を選択できます。
- 監視対象ジョブ(複数可)
- トリガーするジョブ(複数可)
- 「成功、失敗、停止、タイムアウト」の4つのジョブズテータス
- 監視対象ジョブとステータスが全一致でトリガーするか、部分一致でトリガーするか
- 起動時に渡すパラメータ(セキュリティ設定、ブックマーク、タイムアウト、キー/値)
例:ジョブイベントトリガーを利用して以下の様なフローを3つのジョブイベントトリガーを設定することで実現できます
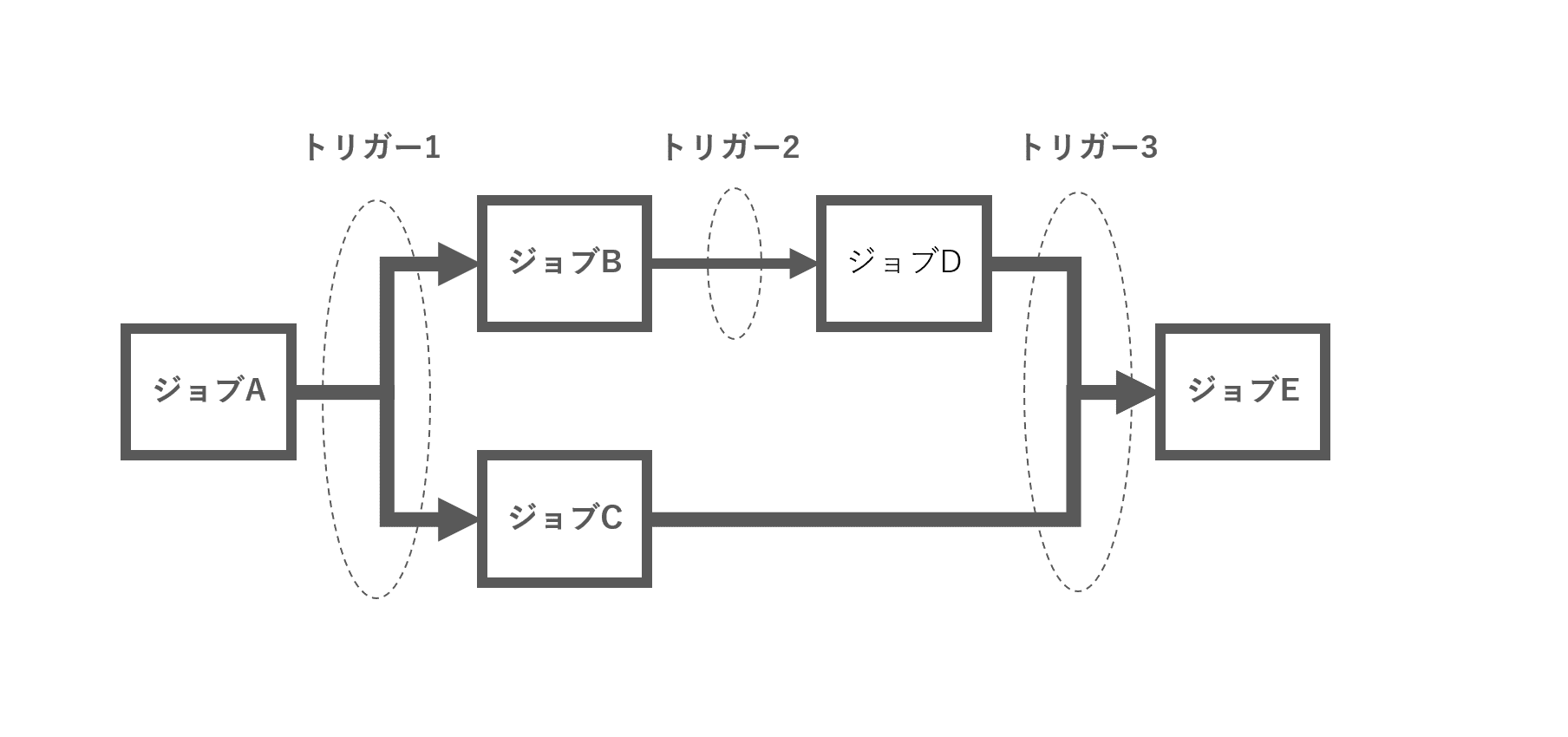
- トリガー1はジョブAが成功したらジョブB, Cを起動
- トリガー2はジョブBが成功したらジョブDを起動
- トリガー3はジョブC, Dが成功したらジョブEを起動
Glue開発Tips
この1ヶ月で学んだGlueで開発を行う上でのコツをお伝えします
Tips1. Glueデバッグについて
Glueの開発・デバッグには、開発エンドポイントを利用すると便利です。
ローカルのコンソール上から開発エンドポイントへSSH接続することで、Glueに対しPythonやscalaのREPLを使用できます。
エンドポイント作成はGlueのDPU数を指定し、SSH用の鍵を設定するのみです。わずか数クリック、1~2分で完了できます。ただし、エンドポイント作成後は裏でGlue(Spark)のクラスタ構築が行われるため、実際に使用可能となるのはその完了後(約15分ほどかかりました)です。
作成したエンドポイントへApache Zeppelin ノートブックを接続し、ノートブックでの開発も可能なようですが、今回は必要でなかったため使用しませんでした。ノートブックはローカルでもEC2上でも利用可能なようです。詳細は以下をご覧ください。
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/dev-endpoint.html
また開発エンドポイントも裏ではGlueのクラスタが上がっているため、通常通りのGlue料金が請求されます。開発エンドポイントのDPU数はデフォルトで5、料金は1DPUあたり$0.44/時かかります。(公式ドキュメントには$0.44/秒と誤記されてますが、そんな高くないです)。
仮に終業時に開発エンドポイントを落とし忘れた場合、翌出社までに以下の金額がかかります。
5 * $0.44 * 14時間(20時退社、10時出社) = $30.8
1回の飲み代程度です。一晩にしてはなかなかです。自動で落とす方法もちょっと調べてみましたが見つけられず…。
忘れずに落とすようにしましょう!
※開発エンドポイントを使わない場合※
開発開始直後は開発エンドポイントの存在を知らず、Glueコンソール上でソースを編集し実行することで開発をしていました。
その当時の開発スタイルの状況も悪い例として記載します。興味が無い場合はスキップください。
(※開発エンドポインを利用すれば解決できる内容です。開発エンドポイントをぜひ利用しましょう!)
ジョブ実行に時間かかる
- Glueジョブは実行の都度リソースを確保しクラスタの構成を行います。そのため純粋なコンピューティング以外で毎回10分ほど待たされます
- ソースを編集 → 実行(10分以上かかる) → 結果を確認、ソースを修正 → 実行(10分以上かかる) → …
不要なログが多く目的のログに辿り着けない
- Glueの実行ログはCloudWatch上から確認可能ですが、実行スクリプトのログとSparkのログが同一のログストリーム上に出力されます
- そのため大量のSparkのログに目的のスクリプトログが埋もれます
- CloudWatchから目的のログに辿り着けるよう、ログにプレフィックスなどをつけるなど工夫が必要でした
- ソースを編集 → 実行(10分以上かかる) → CloudWatchのログストリーム表示 → プレフィックスで目的のログ検索 → 結果を確認 → ソースを修正 → 実行(10分以上かかる) → …
- Glueの実行ログはCloudWatch上から確認可能ですが、実行スクリプトのログとSparkのログが同一のログストリーム上に出力されます
ソース修正、実行のための画面遷移が多い
- ジョブの一覧画面からスクリプトを参照することはできますが、編集するには専用の編集画面で行う必要があります。そのため編集の都度画面遷移が必要です
- また、編集画面にはジョブの実行ボタンが存在しますが、このボタンが反応せずほとんど実行開始してくれません(原因は不明)。そのため実行の都度またジョブ一覧画面へと遷移する必要があります
- ソースを編集 → 編集画面から実行画面へ → 実行(10分以上かかる) → CloudWatchのログストリーム表示 → プレフィックスで目的のログ検索 → 結果を確認 → 実行画面から編集画面へ → ソースを修正 → 編集画面から実行画面へ → 実行(10分以上かかる) → …
どうでしょう? 壮絶な開発状況を想像していただけたでしょうか?
エンジニアたるもの、あるものは利用して賢く効率よく働きたいと、改めて思いました..。
これらの苦労は 開発エンドポイントを利用すれば その多くが回避できます。ぜひ利用しましょう!
Tips2. AWS Athenaで簡易的にデータ確認
Glueのテーブルを使用する場合は、Athenaのクエリで中身を確認できるため開発が捗りました。
Athenaからテーブルに対して、 SELECT * FROM TABLE などのクエリを投げても良いですし、Glueコンソールのテーブル一覧画面から「アクション」→「データの確認」を選択しても良いです。後者の場合は自動でAthenaから SELECT * FROM TABLE limit 10 というクエリを投げてくれます。どちらの場合もAthenaの料金が発生するため、読み取りデータ量には注意が必要です。
また、開発にSparkSQLを用いる場合はAthenaも同じSQLであるため、AthenaでSQLを開発してからSparkへ移植という使い方が可能です。ただし、AthenaはPrestoベース、SparkSQLはHiveSQLのスタイルをベースに開発されており、利用できる構文に微妙な差異がるため注意が必要です。
Athenaで開発したSQLをそのまま移植しようとした時に少しハマりもしました。
例えば文字列結合の場合、以下のようなSQLはAthenaでは利用できてSparkSQLでは利用できません。
-- AthenaではOK、SparkSQLではNG |
SparkSQLの詳細については、GlueのVersionが2018.08月時点では2.1.1ですので、下記のガイドを参考ください。
https://spark.apache.org/docs/2.1.1/sql-programming-guide.html
Tips3. Glueのカタログデータについて
Glueといえばカタログデータ、という印象がありましたが実はカタログが未登録でもETLジョブは実行可能です。
GlueのデータカタログはApache Hive メタストアとの互換性がありますが、EMR以外にもAthenaやRedshift Spectrum でも利用できます。
開発Tips2であるように一部のS3バケットに対してはAthenaのクエリを発行したかったためデータカタログを設定しましたが、ETL処理に閉じて見た場合に恩恵が無いように感じられたため最終的にはデータカタログを利用しませんでした。
Tips4. DataFrameとDynamicFrameについて
Glueでは2種類のDataFrameを利用できます。
SparkのDataFrameと、Glueで独自に定義されたDynamicFrameです。
両者ともテーブルの構造でデータを持ち、データ操作を行えるという点は共通していますが、DynamicFrameはchoice型を扱うという点で差異があります。choice型とは、同一列に複数のデータ型を持つことができる型です。
例えば、同一列にstringとdoubleを含むデータをDynamicFrameに読み込んだ場合、以下のようなイメージとなります。
取り込み元データ
| col1 | col2 |
|---|---|
| 1 | str |
| 2 | 20.3 |
取り込み後DynamicFrame
root |
col2は2種類の型のデータが存在するためchoice型となり、stringとdouble両方を保持します。
様々なデータ取り込みに対応可能とするため、このような構造になっているのでしょう。
ただchoice型はこのままでは扱いにくいため、resolveChoice関数によって扱いやすい形へ変換してあげるとよいです。
resolveChoice関数では以下のことができます。
- choice列を任意の型にcastする。(choice列を、例えばstring列へ変換する)
- choice列に含まれる型別に、新しく列を生成する。(stringとdoubleの2列を生成する)
- choice列に含まれる型を保持できる構造体の列を生成する。(stringとdoubleを保持できる構造体列を1列生成する)
- choice列を任意の型にcastした列を生成する。(例えばstring列を1列生成する)
今回は、調査時の情報量が圧倒的にSparkのDataFrameの方が多く使いやすいため、データの取り込み後choice列は早々にstringへ変換し、かつSparkのDataFrameへ変換して使用しています。
データの取り込みはDynamicFrameで行い、本格的なデータの加工はSparkのDataFrameで行う、という使い分けが良いかと思います。
DynamicFrameやresolveChoiceの詳細は以下を参考ください。
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/aws-glue-api-crawler-pyspark-extensions-dynamic-frame.html (edited)
Glueの注意点
Glueを利用して感じた注意点をまとめます。
注意1. 既存データに対するUpdate
Glueではカラムの加工、テーブルの新規作成(SQLでいうCreate As Select)、テーブルのJoinなどETL処理ができます。またその特性上、中間データはS3上に配備されることが多いと思います。
しかしS3上にある既存カラムの Updateはできません ので注意が必要です。
これは裏側で動くSparkがあくまでS3へ追記しか行っていないからでしょう。
どうしてもUpdateしたいときは以下で代用できないかなどが追加の検討が必要です。
- Delete & Insert でテーブルやパーティション自体を再作成する
- 既存データの更新せずデータを追記し、抽出時にDistinctするロジックを追加する
どちらにしても、書き込みや読み込みに余分な処理が発生するため処理コストが多くかかってしまいます。
最終的な利用元である分析に対して、どれくらいのデータ鮮度が求められるか、費用対効果で考える必要があると思います。
※ちなみに、DynamoDBに対しては書き換えたい情報だけに絞り込んでInsertすることで、実質的にUpdate処理が可能となりますが、DynamoDBのRCU/WCUの費用を考えると利用したいユースケースは少なそうです。
注意2. C言語に依存するパッケージ(Pandas等)が利用不可
リファレンスにも記載がありますが、Glueの仕様でC言語依存パッケージを使うことができません。
Scikit_learnを使いたかったのですが、内部パッケージにpandasが使われているため起動できず、Scikit_learnの処理は違うアーキテクチャ(ECS)に切り分けました。すでに使いたいものが決まっている場合は注意してください。
もともとは、PySparkのUDFで処理可能と想定していましたが、Glueのこの制約を見逃していて、半日潰してしまいました。
C言語依存パッケージがGlueで使えない理由としては、コンパイルが絡んでいるのではないかと考えています。今後のGlueの機能拡張で使えるようになってくれると便利さが増しますね。
注意3. ジョブブックマークが対応していない入力
Glueの機能にジョブブックマークというすでに処理されたデータかどうかを判定し、処理済みであれば次のジョブでは入力データに含めないという機能があります。
2018.08時点ではJSON、CSVなどには対応しているものの、zipファイルやParquestには対応していませんでした。
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/monitor-continuations.html
そのため、もしジョブブックマーク非対応の入力に対しては、手動でオフセット管理する必要があります。
今回、わたしたしは入力ディレクトリに処理済みかどうかのフラグファイルを配備し、Glueジョブ上でその有無を確認することで処理対象とするか判定するロジックを追加しました。
注意4. S3上のソースファイルの実行
S3にソースファイルを配置する際に複数ファイルの場合は、zip圧縮する必要があります。
地味ですが忘れると動かないのでご注意を。
注意5. 並立分散処理
Sparkの設定にちょっとした工夫が必要です。
第2回目の記事で詳しく説明したいと思います。
注意6. 料金について
Glueの料金計算はやや特殊でDPU (Data Processing Unit) という数に基づいて時間(1秒)ごとに課金が発生します。2018.08時点では1DPUでは4vCPU・16GBメモリが提供されます。
2018.08時点では 10分の最小期間が設定 されているため、処理時間が10分以下のミニバッチを連続的に起動させたい場合にはコスト的には不利になってしまいます。
https://aws.amazon.com/jp/glue/pricing/
これを避けるために分析部門にとってはデータの鮮度は下がるものの、20-30分単になどに処理頻度を変更する余地が無いか、費用対効果から見た全体最適の視点で検討中です。
注意7. リソースの確保について
(2018.08時点、東京リージョンで発生した事象です)Glueのリソースは先に述べたDPUという単位でコンピューティングされます。これを性能検証のために、数十DPUといった比較的大きめに確保しようとするとリソースが確保できず起動できなかったことが何度かありました。
2018.08時点ではGlueリソースをリザーブド化することもできず、設定レベルでの回避が難しい状態です。
東京リージョンでGlueが利用可能になったのは2017.12 と比較的新しく、今後も継続的にリソースの増強などが期待されるため、改善に向かうと予想しています。現時点では実行タイミングによっては確保が難しい場合があるようです。人気のサービスであるという証拠なのかもしれませんね。
他の時間帯・日本国外リージョンなどを試すことや、処理粒度をある程度細かくし急激に大きなDPUを確保しないようにするなどの工夫が必要になってきます。また、どうしても確実に実行できないと困る! という場合は、リザーブドインスタンスでEMRを利用するしか無いようです。
まとめ
Glue(直訳:のり)とはよく名を付けたものだと感じています。
粗削りで膨大なデータを、使いやすい形に成形してあげる。つまり、データと後続のシステムをうまくつなぎ合わせることができるものがGlueです。
以下にあてはまる方はGlueの導入を考えてみたらどうでしょうか。
- ビッグデータの処理が必要
- 起動時間は常時ではなく短い
- サーバーを立てる余裕がない
- 運用、保守する余裕がない
- パイオニア精神がある
実はGlueの記事はネット上にはまだ多くない状態です。
そのため、Glue開発を導いていきたいというパイオニア精神ある方におすすめの領域だと思います。
次回のGlueの記事について
次回の内容はGlueを用いた性能改善です。
皆さんの参考になれば光栄です。
Glueを検討の方はご気軽にご連絡ください。