AWS Datalake Hands-on(2019 May)メモ
2019/05/29にAWS Japanで行われたDataLakeについてのHands-onメモです。
目次
0. はじめに
自己紹介
はじめまして、Technology Innovation Groupの柳澤です。こちらのブログへ投稿するのは初めてなので、簡単に自己紹介させていただきます。
2018年の5月にFutureへ中途採用で入社した社会人6年目になります。前職のメーカー系SIerではフロント業務からオンプレのアプライアンスもいじるなんでも屋さんみたいな立ち回りをしていました。
Future入社後は業務でクラウドを触ったことがなかった状態で、GCPの運用やオンプレ→AWSのリフト案件の推進など、なかなか刺激的な経験を積んでいたらあっという間に1年経ってしまったという今日この頃です。
DataLake Hands-onセミナーについて
基本的にユーザを主な対象としているセミナーで、30分程度の簡単な講義のあとに、ひたすら手を動かすハンズオンという二部形式で構成されています
あとから知ったのですが、昨年から始まった恒例のワークショップのようです。※開催報告の公式ページはこちら
また、参加者層としては、後述のハンズオンの進捗を見るにユーザの方が多かったのかなという印象でした。
(ハンズオンの分量が多かったものの、ハンズオン終了時時点で分量の半分まで到達できていた人が6割くらいだった印象です)
1.参加の背景
あるプロジェクトでデータ分析基盤を開発することになり、その一環として
- データってどうやって集める?
- 集めたデータをどう使う?
- 集めたデータをどう使える状態にする?
を知るために参加しました。
当日の講義の内容としては、以下のような簡単な座学の後に、ハンズオンに移ります。
- 実際にハンズオンで手を動かして作るものの構成とその概要についての
- なぜDatalake(DataLakeってなに? という話題も含めて)なのか
2.手を動かす、その前に
もともとユーザ向けのセミナーだったこともあり、技術的に複雑な説明などはありませんでした。
しかし、データレイクについては、その利点などについてしっかりできていなかった部分があったのでそれらを整理する意味でも有意義なものだったと思います。
説明のあった内容をざっくり要約すると以下の通りです。
企業の保有するデータについて
- いま現在も企業の保持するデータは増え続けている
- しかもデータの形式や抽出要件も増える一方
要件が複雑化するデータに対して(RDSの場合)
- 複雑化する要件に合わせてスキーマなどが増加するため、どんどんサイロ化が進む
- また、リアルタイム分析や
最近流行の機械学習などの領域への対応が難しい
複雑化するデータへの対策としてのデータレイク
- 上記の問題への対応策として、データレイクは非常に有効
- データレイクとは、構造にかかわらずデータをそのままの姿で保存可能な一元化されたリポジトリのこと
- データレイクを使用することの利点(例)としては
- 前述の通り、データを保存する段階でスキーマの分割などが発生しないため、サイロ化が発生せず、データの一元管理が可能になる
- 一元管理が可能になることでSSOT(詳しくはこのあたりをご参照ください)として使用することが可能に
- データの保存場所に対してinput/outputが独立するため、それぞれ柔軟に手段を選定できる
- 前述の通り、データを保存する段階でスキーマの分割などが発生しないため、サイロ化が発生せず、データの一元管理が可能になる
3. ハンズオンでやったこと
座学の後は、黙々と手を動かす時間が続きます。
- はじめの準備
- アプリケーションログをリアルタイムで可視化する
- 2に加えてアラームの設定
- アプリケーションログの永続化と長期間データの分析と可視化
- クラウドDWHを使用したデータ分析
- サーバレスでデータのETL処理
使ったサービスは全部は以下の通りです。
| No | 内容 | 使用サービス |
|---|---|---|
| 1 | はじめの準備 | VPC, EC2, CloudFormation, IAM |
| 2 | リアルタイムのアプリケーションログ可視化 | Elasticsearch Service |
| 3 | アラームの設定 | CloudWatch Lambda, Elasticsearch Service |
| 4 | アプリケーションログの永続化・長期間データの分析と可視化 | Kinesis Data Firehose, S3, Athena, QuickSight |
| 5 | クラウドDWHを使用したデータ分析 | Kinesis Data Firehose, S3, Athena, Redshift Spectrum, Quicksight |
| 6 | サーバレスでデータのETL処理 | Glue, Athena |
上記のサービスを使って最終的には
- バッチレイヤ(バッチ処理、あとからまとめて分析)
- スピードレイヤ(リアルタイム処理、監視のアラートなど)
の両面から監視・分析を実行できる環境を構築していきます。
イメージ図はこちら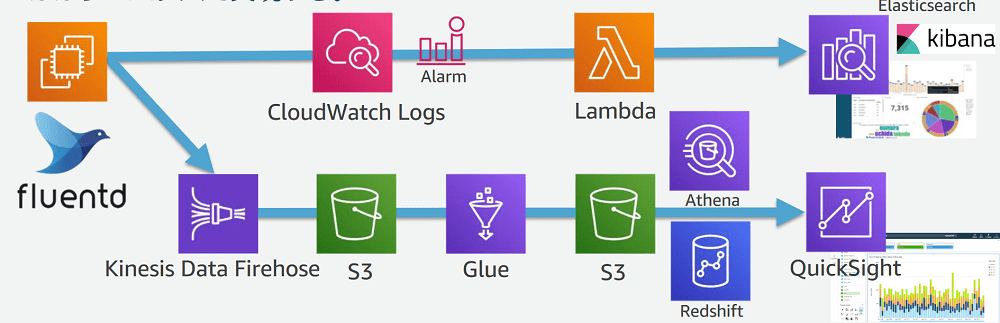
3-1. はじめの準備
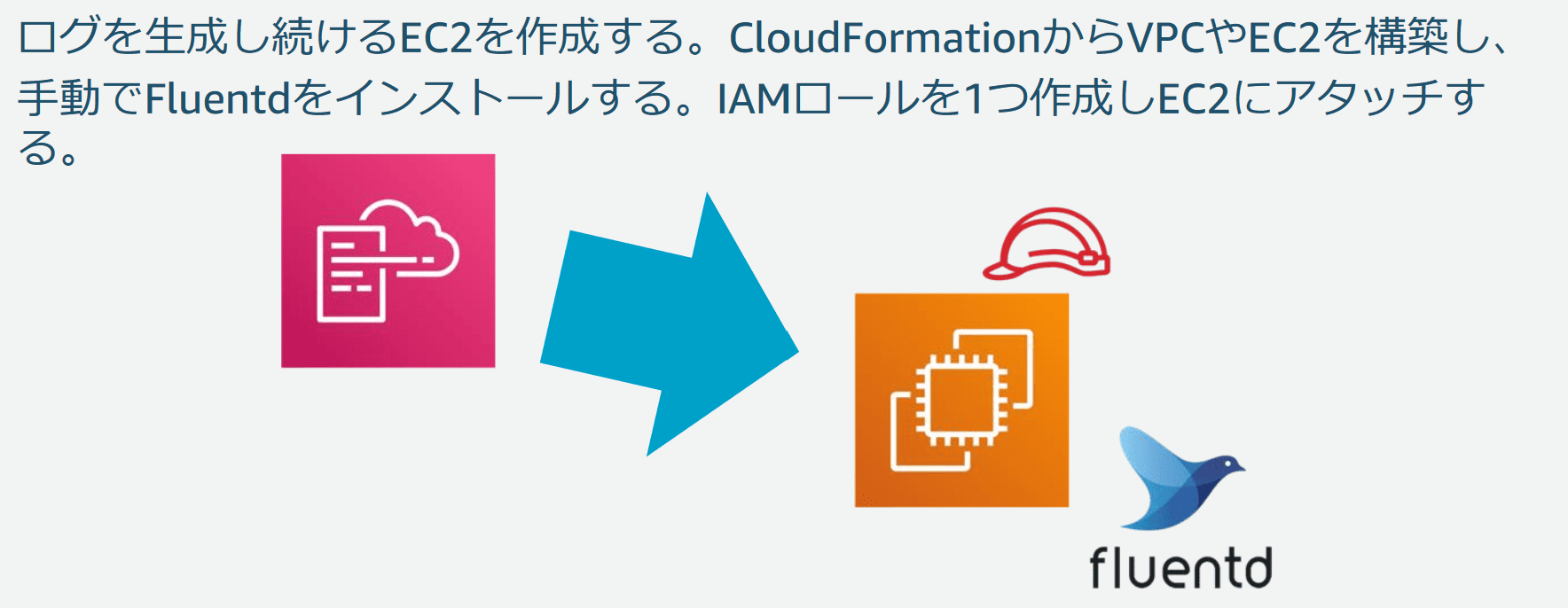
後続のログ分析に使うためのログを生成し続けるEC2インスタンスを作成します。
このEC2インスタンスおよび周辺の設定(VPCやSecurityGroupなど)はすでにCloudFormationのテンプレートが用意されており、実作業としてはテンプレートをS3に置いて、スタックの作成を実行するだけ、という感じでした。
ここまでは特筆すべきこともないのでさっくりいきます。
3-2. リアルタイムのアプリケーションログ可視化
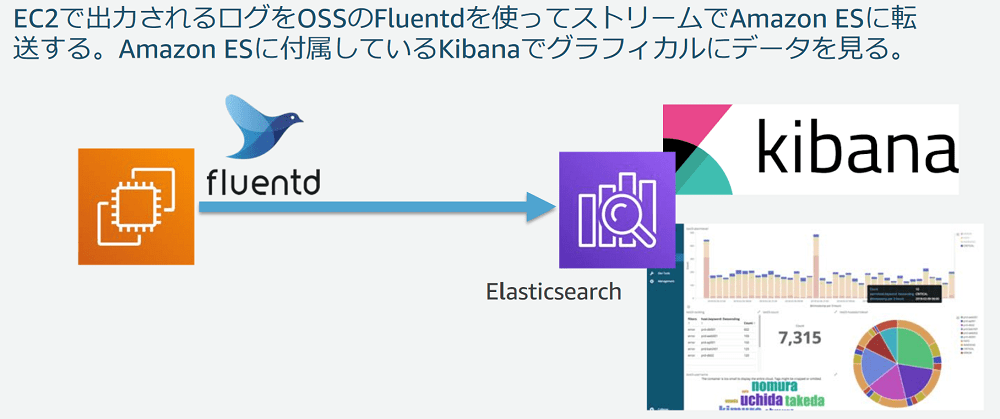
続いて、スピードレイヤの構築を開始します。
前手順で作成したインスタンスで出力したログを
- fluentdでElasticsearch Service(以下、ESとします)へストリーミング
- ESに付属しているKibana(←Kibanaのセットアップしなくていいのは楽!!)でグラフィカルにデータを確認
することをしました。
できた画面は↑の画像内のスクリーンショットのような感じです。
3-3. アラームの設定
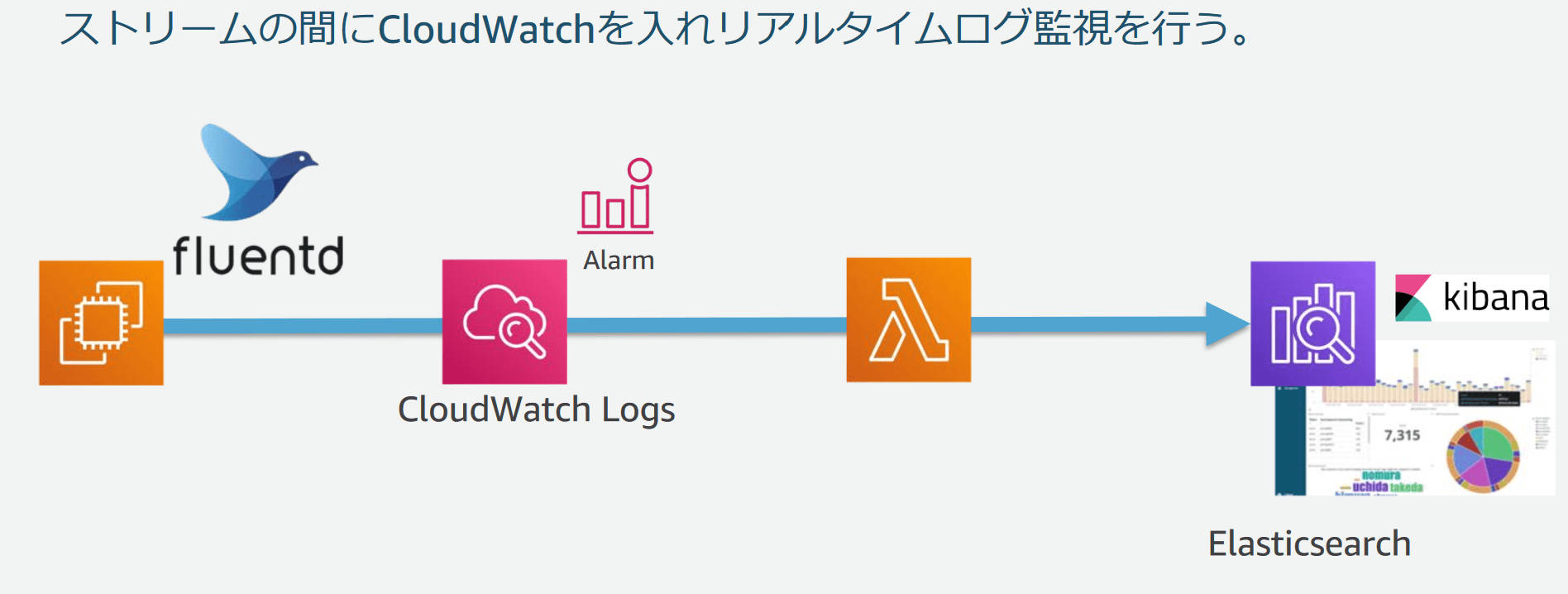
fluentd→ESの間に、CloudWatchLogs(Alarm)とLambdaを差し込むことで、リアルタイムのログ監視とアラームを設定します。
ここまでがスピードレイヤの構築です。
3-4. アプリケーションログの永続化・長期間データの分析と可視化
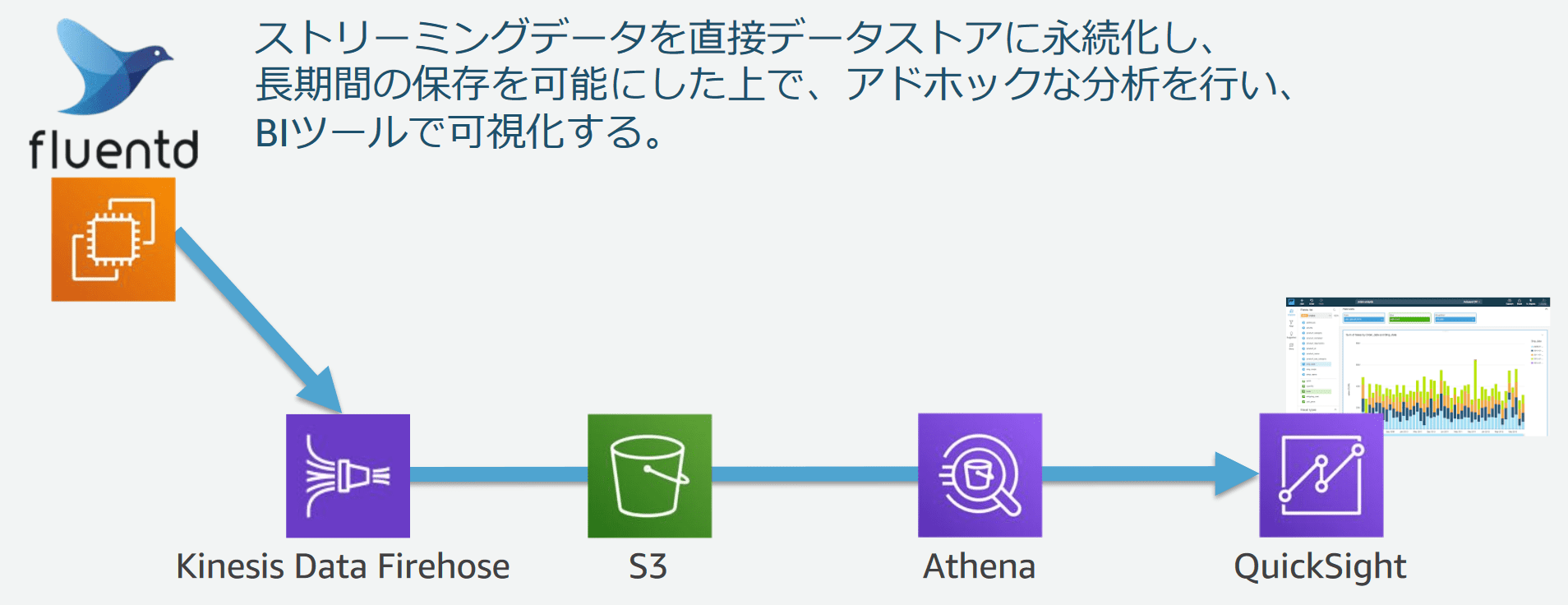
ここからバッチレイヤの構築に入ります。
fluentdからKinesis Data Firehoseにもストリーミングを行い、保存先としてS3を指定します。
S3への保存によって長期間のデータ保管を可能にしたうえで、アドホックな分析を行うと同時にBIツールで可視化しました。
3-5. アプリケーションログの永続化・長期間データの分析と可視化
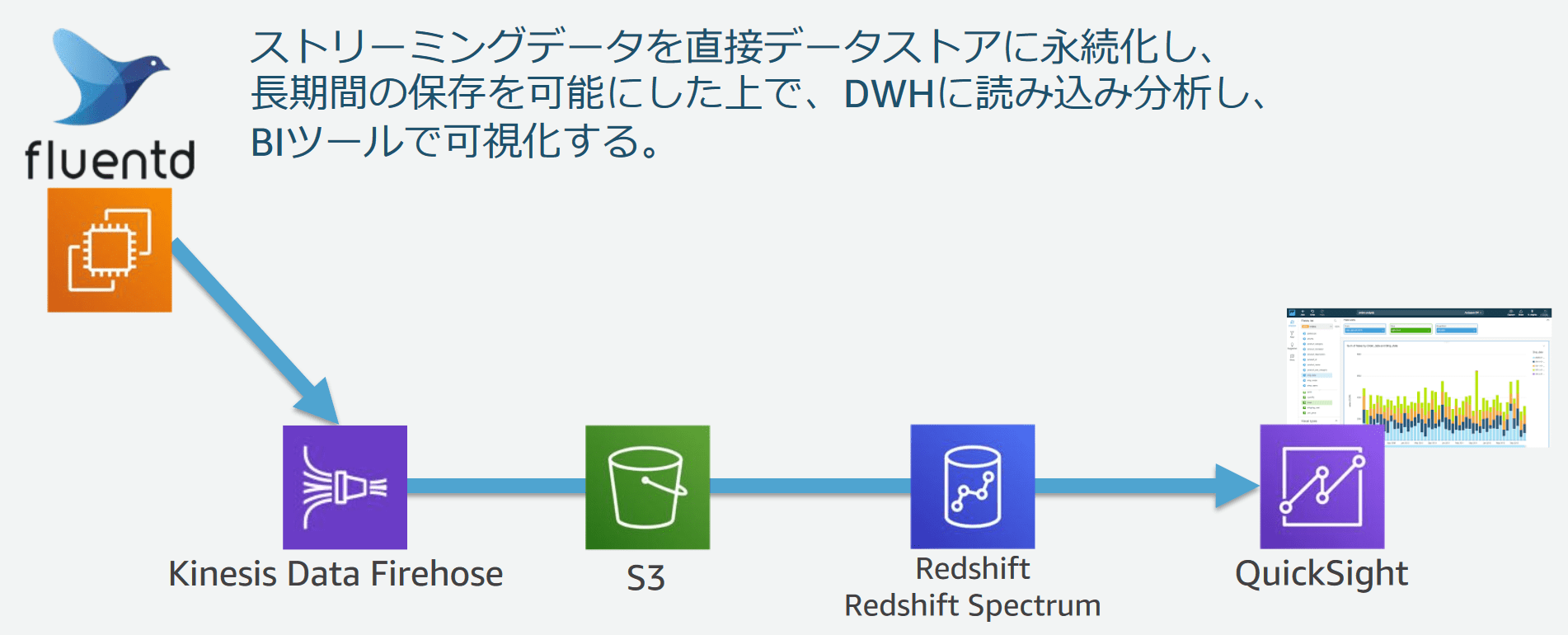
3-4とは異なり、ストリーミングされたログをS3で永続化したうえで、DWHに読み込み分析し、BIツールで可視化しました。
3-6. サーバレスでデータのETL処理
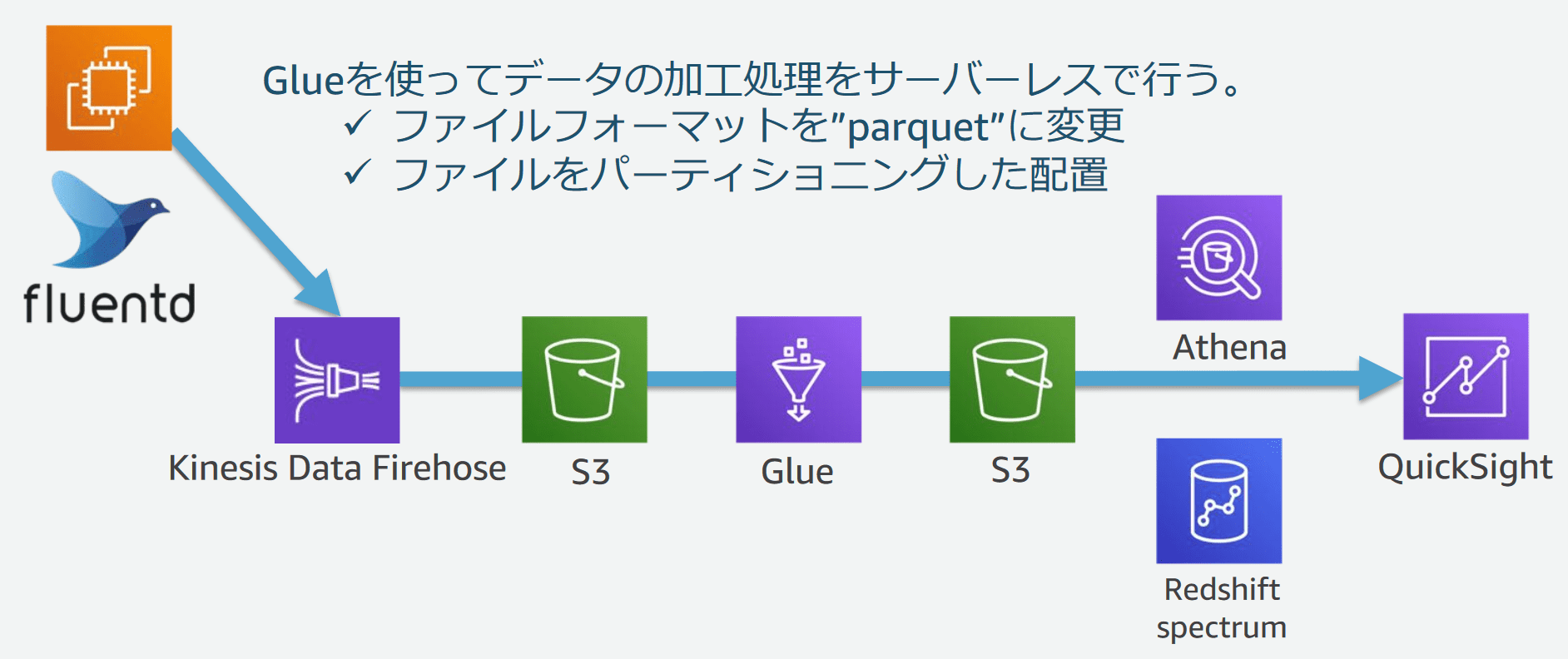
Glueを使い、サーバーレスでデータの加工処理をしました。
4.まとめ
4-1.勉強になったこと/もう少し知りたかったこと
勉強になったこと
以前かかわったPJでElasticsearchの運用していたこともあり(構築にはさほどかかわっていませんでしたが)、諸々の設定をスキップしてGUIポチポチである程度の構成が出来上がってしまうマネージドサービスの生産性の高さを改めて認識できました。
もう少し知りたかったこと
もう少し知りたかった、というよりはもう少し時間が欲しかったという表現が正しいかもしれませんが、セミナーのテキストが400ページ近い超大作だったのに対し、実際に手を動かせる時間が3時間もなかったので、すべてを腹落ちさせて帰るのはちょっと厳しかったかなという印象でした。(そもそもシナリオを選択してかいつまんで構築していく想定だとは思いますが)
4-2.所感
私自身、現在AWSを触っていることもあり、セミナーで使用するCloudFormationの扱いやGUI操作については特に詰まるところはありませんでした。
この点についてはある程度マネジメントコンソールを触ったことのある人であれば特に困ることはないのではないかと思います。
逆にいえば、従来までログ分析基盤などをがんばって作っていた時間を「集めたログをどうやって使っていくか」などビジネス的視点に立ったタスクにシフトさせていく必要性を強く感じる結果になりました。
そういった意味では、少し技術的な部分に触れてみたいユーザ企業の方や、さくっとログ分析基盤作ってみたい! というクラウド初心者の方には短時間で方法論を学べるいい機会になるのではないかと思いました。