GCP集中連載の7回目です。
TIGのDXチームに所属している加部です。入社してからは主にインフラやデータベースを中心に仕事をしており、現在はGOでバックエンドのAPIの開発なんかもしています。
突然ですがAWSを利用しているけどビッグデータの蓄積や解析はBigQueryで実施したい、なんて意見も最近多くなってきているようですね。実際にS3からBigQueryのデータ転送について検索すると、自前でデータ転送を作成してみましたや、データ転送をサービスとして販売しているような会社もあります。そんな中GCPが提供しているBigQeryへのデータ転送サービスDataTransferServiceのソース元としてS3が追加され、簡単にS3からBigQueryのデータ転送のジョブを作成できるようになりました。まだ、ベータ版でのリリースのみですが今回は実際にS3からのデータ転送を試してみましょう。
DataTransferServiceとは

BigQuery Data Transfer Service は、あらかじめ設定されたスケジュールに基づき、BigQuery BigQuery Data Transfer Service は、あらかじめ設定されたスケジュールに基づき、BigQuery へのデータの移動を自動化するマネージド サービスです。そのため、アナリティクス チームが BigQuery データ ウェアハウス基盤を構築する際にコードの作成はまったく必要ありません。
https://cloud.google.com/bigquery/transfer
要はBigQueryに対してデータを転送するジョブをマネージドサービスで簡単に作成できるよということですね。
マニュアルによると現在下記のようなサービスとの連携が可能となっています。
- AWS S3
- キャンペーンマネージャー
- Cloud Strage
- Google アドマネージャー
- Google 広告
- Google Merchant Center
- Google Play
- 検索広告360
- YouTubeチャンネル
- YouTubeコンテンツ所有者
今までは主にGoogle系のサービスとの親和性が高く、AWSのS3は初めてのGoogle以外のソース元のサービスになるのではないでしょうか。
今回の構成と手順
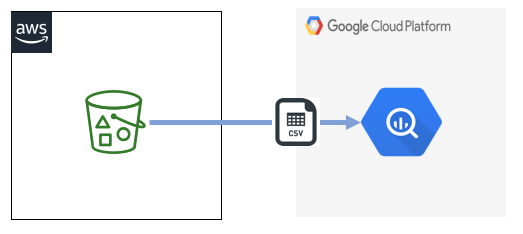
今回はS3のバケットに格納したCSVファイルのデータを、DataTransferServiceの機能を使ってBiqQueryに転送します。
複雑なコマンドや手順があるわけでは無いため、とてもかんたんに設定できます。本記事では主にコマンドラインによる作成となりますが、もちろんコンソールからポチポチして作成することもできます。
- S3バケットの作成
- シークレットキー、アクセスキーの発行
- DataTransfer APIの有効化
- BigQueryのデータセット、テーブル作成
- 転送ジョブの作成
手順1 AWSでのS3バケットの作成
S3の作成に関しては下記参照
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/user-guide/create-bucket.html
手順2 シークレットキー、アクセスキーの発行
S3のデータ転送をするためには「AmazonS3ReadOnlyAccess」の権限が必要になるため、シークレットキーとアクセスキーを発行するユーザの権限に追加してください。
シークレットキー、アクセスキーの発行は下記参照
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/cli-services-iam-create-creds.html
手順3 DataTransfer APIの有効化
AWS環境の準備が完了したら次はGCP環境の準備です。まずはDataTransfer APIの有効化にしましょう。
コンソールタブの「APIとサービス」からライブラリを選択し、「BigQuery Data Transfer API」と入力して検索してください。
検索したAPIを選択して、有効にするをクリックするとAPIが有効化されます。
手順4 BigQueryのデータセット、テーブル作成
今回のサンプルデータとして気象庁のデータから2019年の東京の気温のデータを使います。
下記URLから取得
http://www.data.jma.go.jp/gmd/risk/obsdl/index.php
bqコマンドでデータセットを作成して、取得したデータを格納できるようなテーブルを作成します。
データセットの作成
bq --location=asia-northeast1 mk \ |
テーブル作成
bq mk --table test-project-268106:from_s3.temp_tokyo \ |
手順5 転送ジョブの作成
いよいよS3からの転送ジョブの作成です。こちらもコマンドラインでの作成していきます。
bq mk \ |
簡単にコマンドラインのオプションについて抜粋して説明を記載します。
- data_source : BigQueryにデータを転送するデータソース。今回はS3なので「amazon_s3」を選択
- data_path : S3のURIを入力します。基本的には「S3://バケット名/フォルダ名/オブエジェクト名」
- access_key_id/secret_access_key : 手順2で作成したユーザのアクセスキーとシークレットキー
- file_format : 今回はCSVデータがサンプルデータなので「CSV」を入力。CSV以外にも、JSONやPARQUETなどのファイルフォーマットも選択することが可能
- field_delimiter : 今回はカンマ区切りのCSVのため「,」を入力
- skip_leading_rows : スキップするヘッダの行数。今回はヘッダ行を含まないデータにしているため「0」
コマンドを実行するとGoogleアカウントのログイン許可のURLが表示され、URLのリンクに飛び認証コードを入力すると正常に作成されましたと表示されます。コンソールからも転送ジョブが作成されていることが確認できました。
ジョブが作成されるとその後すぐに実行され、コンソールから実行ログを確認できます。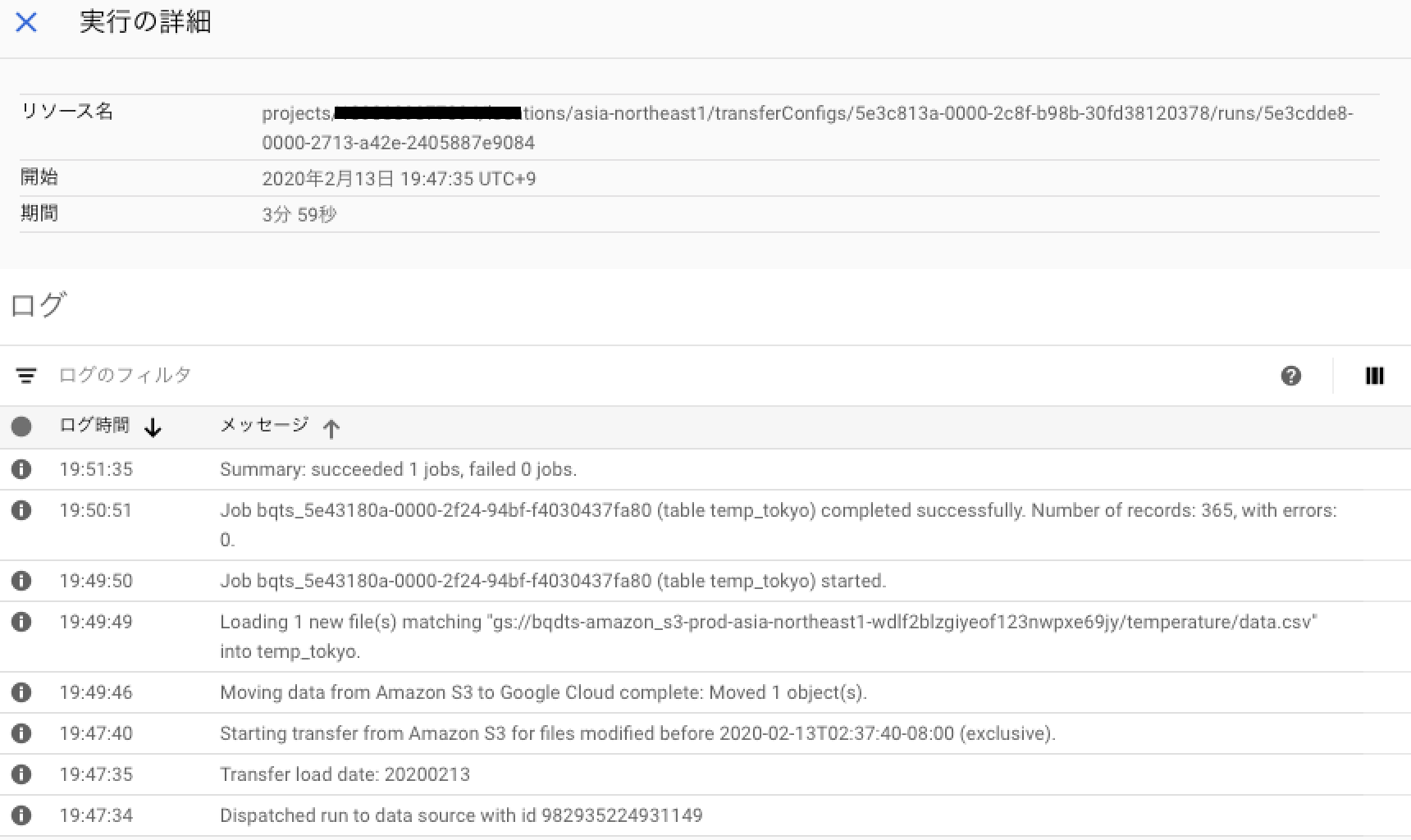
今回は小さなデータでしたが3分ほどかかってジョブは終了しました。
実際にSQLでデータを見てみると下記の様に取得できます。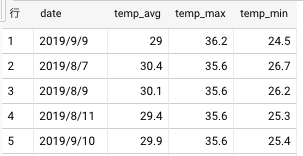
注意点
注意点としてはコマンドラインからの作成の場合、スケジュールの選択オプションがありませんでした。どうやらデフォルト値である24時間ごと(日時)が自動で選択されているようです。作成後にコンソールからジョブのスケジュールを編集することは可能です。下記のように毎日、毎週、毎月、カスタム、オンデマンドと選ぶことができます。
まとめ
今回はGCPのコマンドラインで作成しましたがInfrastructure as Codeで有名なTerraformなどでも作成できます。
今回の機能を実運用で利用するとなるとS3のパス設計など検討することは他にもあるとは思いますが、AWSを使いつつGCPのBigQueryを利用するなどのマルチクラウドの夢が広がるような機能ですね。今後もさらなる機能拡張を期待します。
GCP集中連載の7回目でした。次は木村さんのgcloud compute sshじゃなくてsshコマンドを使いたいあなたへです。