はじめに
こんにちは。TIGメディアユニットの町田です。2020年4月にフューチャーに転職してきました。
当社を選んだきっかけの1つとしてこのTechブログの存在があったので、このように投稿できることをうれしく思います!
春の入門祭り🌸 #17は、全文検索エンジンとして高い人気を誇る「Elasticsearch」についての入門記事です。

Elasticsearchとは何か、どのようなメリットがあるのかということから、ローカル環境へのインストールと簡単な活用事例を見ていきたいと思います。
※本記事の環境はWindows 10 Pro 64ビットとなります。
Elasticsearchとは何か
Elasticsearchは「全文検索システム」を提供するソフトウェアです。
全文検索とは検索手法の1つで、文字列をキーにして複数の文書データをまたがって検索し、目的のデータを探し出す機能のことを指します。ECサイトやコンテンツマネジメントシステムなどで利用されているいわゆる検索エンジンと呼ばれるものは、裏の仕組みとして全文検索システムが動いているものが多いようです。元々はShay Banon氏(現Elastic社CEO)が妻の料理レシピの情報を検索するためのアプリケーションとして開発されたのがElasticsearchの起源だそうです。
それが今では世界中で利用される検索エンジンとなっている訳ですから、ソフトウェア開発の可能性は無限大ですね!
どうやって入手するか
ElasticsearchはElastic社からオープンソースで公開されており、誰でもインストールして無料で利用することが可能です。
また、Amazon Web Service(AWS)上においても「Amazon Elasticsearch Service」としてマネージドサービス(※)として提供されています。
※インフラ設定やバージョン管理などは不要になりますが、利用データ量などによって料金がかかります。
本記事ではオープンソースのソフトウェアをローカルPCにインストールしていきます。
Elasticsearchのどのようなところが便利か
Elasticsearchのメリットとして、以下が挙げられます。
- 索引型検索を採用しているため、大量データに対して高速検索が可能
- 標準で分散配置型の構成をとり、高速化と高可用性を実現
- JSONフォーマットで非定型データを投入可能
- REST APIによるシンプルなアクセスが可能
- 関連ツールを利用して分析・可視化
当社の実績においても、大量の顧客データ検索し数秒で結果を返す要件のプロダクトにて実際に採用されています。
前置きが長くなりましたが、実際にインストールをして試していきましょう!
Elasticsearchのインストール
公式ページからzipファイルをダウンロードします(執筆時のバージョンは7.7.1です)。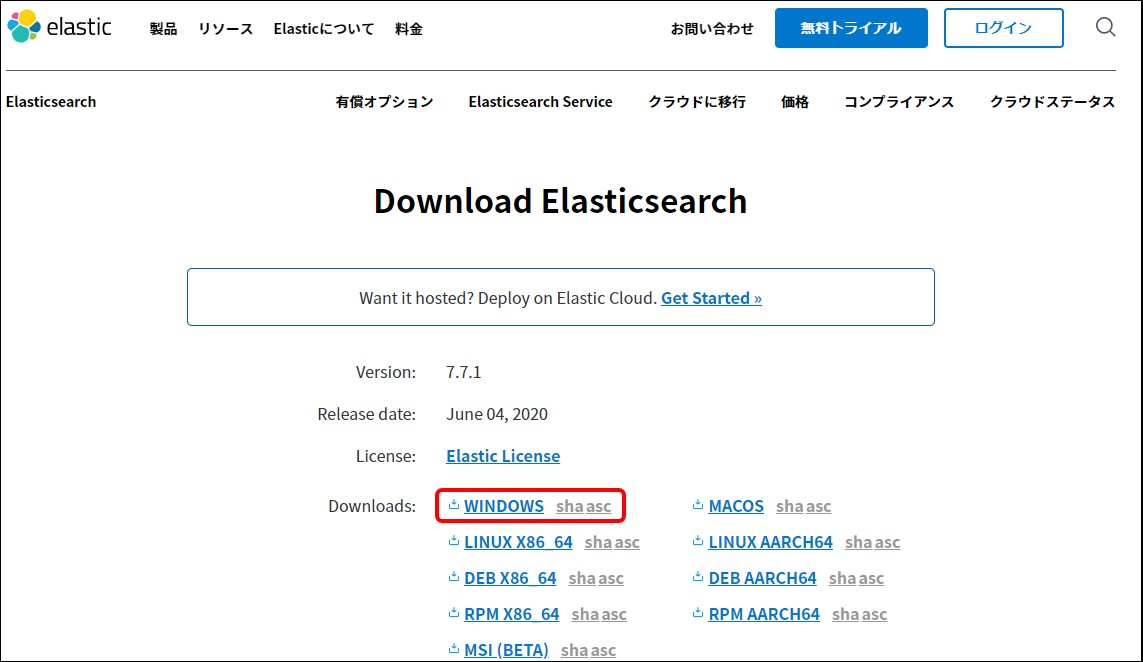
ダウンロードしたzipを解凍すると以下のような構成になっています。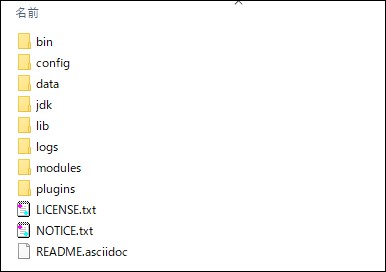
ここで bin/elasticsearch.bat を実行するとコマンドプロンプトが立ち上がり、Elasticsearchが起動状態になります。
動作確認として、別のコマンドプロンプトを立ち上げ curl http://localhost:9200/ と叩いてみましょう。
> curl http://localhost:9200/ |
上記のようにレスポンスがあれば準備OKです。簡単ですね!!
停止する場合は、起動時に現れたコマンドプロンプトで Ctrl+c で停止してください。
ちなみに、ポートはデフォルトで 9200 となっています。
もし変更したい場合は config/elasticsearch.yml の #http.port: 9200 のコメントアウトを外して別のポートを指定することも可能です(再度起動すると反映されます)。
日本語解析への対応
標準ではElasticsearchは日本語の形態素解析(後述します)に対応しておりませんが、オープンソースのkuromojiというソフトウェアを対応させることで、日本語の解析が可能となります。bin/elasticsearch-pulgin.bat から追加インストールできます。コマンドプロンプトで以下のコマンドを実行しましょう。
# [zip解凍したフォルダ\bin] にて実行 |
インストール後はElasticsearchを再起動します。
また、ご利用の環境によってはコマンドプロンプトの文字コードによって日本語表示が文字化けることがあります。chcp 65001と実行すると文字コードがUTF-8になります。
Elasticsearchの用語について
ここでElasticsearchで知っておくべき用語と概念を示しておきます。
Elasticsearchは様々なデータを格納するにあたり、MySQLなどのRDBMSで言うところのデータベースやテーブルに相当する概念が存在します。
RDBに慣れている方も多いかと思いますので、比較する形で示したいと思います。
※厳密に言うと異なる概念ですが、イメージしやすいかと思います。
| Elasticsearch用語 | 説明 | RDBMSで言うところの… |
|---|---|---|
| インデックス | ドキュメントを格納する場所 | データベース |
| ドキュメントタイプ・マッピング | ドキュメントの構成やフィールド型などの定義 | テーブル |
| ドキュメント | 格納される1つの文章の単位 | レコード |
| フィールド | ドキュメント内のKeyとValueの組み合わせ | カラム |
これらを踏まえ、実際にElasticsearchを動かしていってみましょう!
インデックスとドキュメントの登録
ここからは実際にElasticsearchにドキュメントを登録したり検索したりしてみます。
Elasticsearchは、REST APIによるHTTPリクエストでシンプルに操作できるというメリットがありますので、
curlコマンドを使ってバシバシ叩いてみましょう。
まずはインデックスとドキュメントを作成してみます。
ドキュメントは、JSON形式で登録することとなります。
事前準備として、登録するドキュメントの内容をmy_document_1.jsonというファイルに作成しておきます。
{ |
登録のHTTPリクエストは以下の形式で行います。
- メソッド: POST
- URL: http://localhost:9200/my_index/my_type/?pretty
- localhost:9200/{インデックス名を指定}/{ドキュメントタイプ名を指定}/
⇒インデックスとドキュメントタイプが存在しない場合は、自動的に作成される- ?prettyを付与するとJSONが整形された形で返却される
- ヘッダ: “Content-Type”:”application/json”
- ボディ: my_document_1.json
それでは、実際にコマンドを叩いてみます。
> curl -X POST "http://localhost:9200/my_index/my_type/?pretty" -H "Content-Type":"application/json" -d @my_document_1.json |
インデックス、ドキュメントタイプの作成、ドキュメントの登録がこれだけで完了しました!
登録された内容を確認してみましょう。
ドキュメントを指定して参照するには、~/{インデックス名}/{ドキュメントタイプ名}/{ドキュメントid}と指定してリクエストします。
ドキュメントidとは、先ほどのレスポンスの “_id” です
> curl -X GET "http://localhost:9200/my_index/my_type/D4DCxnIB33lDYAWdACgJ?pretty" -H "Content-Type":"application/json" |
しっかり登録されていますね!
ドキュメントの検索
続いて、Elasticsearchのコア機能となる検索機能を試してみましょう。
検索する条件もJSONに記載します。messageが「春祭り」という条件で検索をかけてみましょう。
まずは以下のファイルを作成してください。
{ |
検索は~/{インデックス名}/{ドキュメントタイプ名}/_searchという形式でリクエストします。
検索条件として、先ほどのmy_query_1.json を指定します。
> curl -X GET "http://localhost:9200/my_index/my_type/_search?pretty" -H "Content-Type":"application/json" -d @my_query_1.json |
{ |
いろいろな要素が返却されていますが、着目したいのは「春祭り」という条件で検索したにも関わらず、「春の入門祭り」を含むドキュメントが結果として取得できた点です。
これはElasticsearchが備えるAnalyzerという機能によって、格納している文章を単語単位で分割して保持しているため、このような検索が実現されます。
特に日本語を単語単位で分割することを形態素解析と呼びます。
※日本語を形態素解析するためには、先ほど追加インストールしたkuromojiが必要です。
ここで、先ほど登録していたmessageの内容である「春の入門祭り Elasticsearch入門」という日本語がどのように形態素解析されるのか確かめてみましょう。
リクエストのため以下のファイルを作成します。
{ |
そして以下の通りリクエストしてみます。
> curl -X POST "http://localhost:9200/my_index/_analyze?pretty" -H "Content-Type":"application/json" -d @my_analyze_1.json |
{ |
このように「春の入門祭り Elasticsearch入門」という文章は、「春」 「入門」 「祭り」 「Elasticsearch」 「入門」という形で解析され分割されることがわかります。
形態素解析された単語たちは、自身のドキュメントidと紐づく形の構成で保持されており、ドキュメントへのインデックスとなります。このような構成を特に「転置インデックス」と呼びます。
検索時には、クエリ文字列に対しても形態素解析を行いその結果(今回は「春」 「祭り」)を条件に検索をかけ、Hitしたドキュメントが返却されるという仕組みです(索引型検索)
Elasticsearchではこの索引型検索方式を採用することで、大量データの中からでも高速に対象のドキュメントを探し出すことが可能となっています。
もう少し検索についてみていきます。
先ほどと同じ手順で新たにドキュメントを追加してください。
{ |
そして以下の条件で検索をかけてみます。
{ |
> curl -X GET "http://localhost:9200/my_index/my_type/_search?pretty" -H "Content-Type":"application/json" -d @my_query_2.json |
{ |
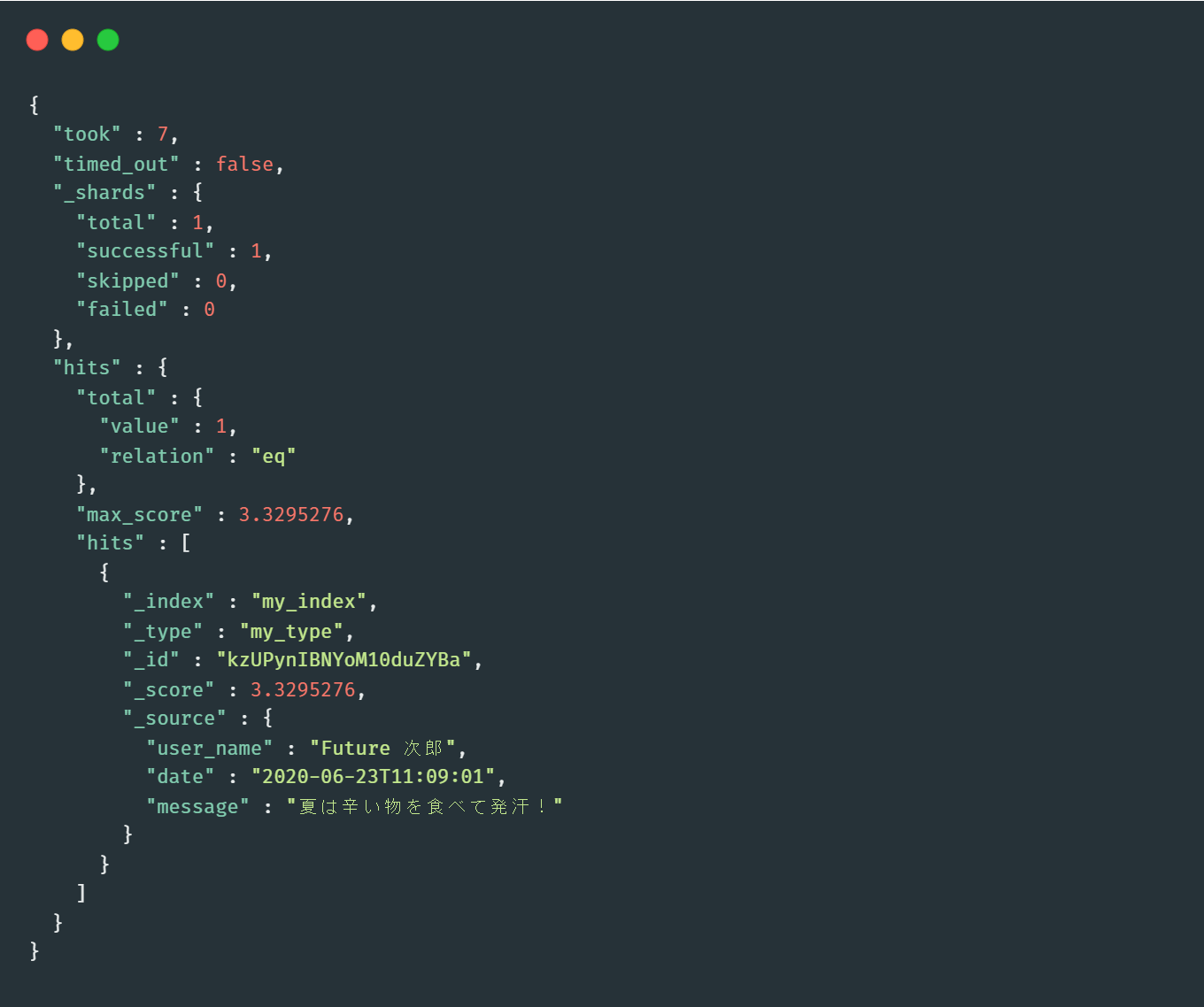
検索条件は「食べ物」ですが、「食べる」を含むドキュメントが結果として取得されました。
こちらも同様にAnalyzerが「表記のゆれ」を検知して、「食べる」や「食べた」を「食べ」に変換して検索しています。
RDBMSでは「~と一致する」や「~を含む」などといったカッチリした条件指定となりますが、Elasticsearchでは文章を解析したりゆれを考慮して結果を返してくれるのです。
全文検索エンジン便利!!
さいごに
本記事ではドキュメントの登録や検索などのほんの(本当に!)一部しか紹介していませんが、より高度な条件の検索をかけたり、登録ドキュメントの分析を行う様々な種類があります。
また、周辺ツールとしてデータをグラフィカルに表示する「Kibana」や、ログを自動的にElasticsearchに送り込む「Logstash」などがあります。
本記事にてElasticsearchの基本に触れたのちは、当ブログの過去記事に高度な利用法も紹介されていますので、是非挑戦してみてください!
- マネージャーがうれしいRedmineデータのグラフ表示方法を公開します!!
- マネージャーがうれしいRedmineデータのダッシュボード表示方法を公開します!!
- マネージャーがうれしいRedmineデータのEVM表示方法を公開します!!