はじめに
こんにちは、Strategic AI Group(SAIG)の山野です。
今回は、機械学習の実験管理をテーマにMLflowについて紹介します。
1. 実験管理の必要性
モデル開発では、様々な条件で大量の実験を時には複数人で回していくことがありますが、徐々に管理し切れなくなり、後から(必要に迫られて)もう一度その実験を再現しようと思ってもできなくて困る、ということがあります。
つまり、実験が終わって数ヶ月後に「あの実験てどのような条件で実施してどのような結果出たんだっけ? +再現できる?」と聞かれても困らない状態を作れれば良いです。PoCが終わってプロダクション化のフェーズで、PoCの実験について確認されるケースが意外とあったりします。
管理すべき情報は、前処理・学習・評価それぞれで以下があります。
- 前処理
- 元データ <-> 前処理コード <-> 加工済データ
- 学習
- 加工済みデータ(学習用) <-> 学習コード、ハイパーパラメータ <-> モデル
- 評価
- 加工済みデータ(評価用) <-> 評価コード <-> モデル <-> 評価結果(サマリ表、画像出力結果など)
2. MLflowとは
MLflow は、実験、再現性、デプロイメント、セントラルモデルレジストリなど、メーリングリストライフサイクルを管理するためのオープンソースのプラットフォームです。MLflowは現在、4つのコンポーネントを提供しています。
- MLflow Tracking
- MLflow Projects
- MLflow Models
- Model Registry
今回は、実験管理を効率化してくれる1のMLflow Trackingについてと、それをどう使っているかを記載します。
3. MLflowを使った理由
- 実験管理をライトに始めることができる
- MLflow本体には様々な機能があるが、目的に応じてライトに始めることができます(「5. MLflowのシンプルな使い方」参照)
- リッチなUIで実験結果を確認できる
- OSSであり、自分でサーバをたてることができる
- 他のツールでは、サービスとして提供されており、サーバ管理不要だがアカウント登録やデータ送信の必要がある場合があります
- 実験管理ツールとして広く使われている
- GitHubスター数6.8k(2020.6.25時点)
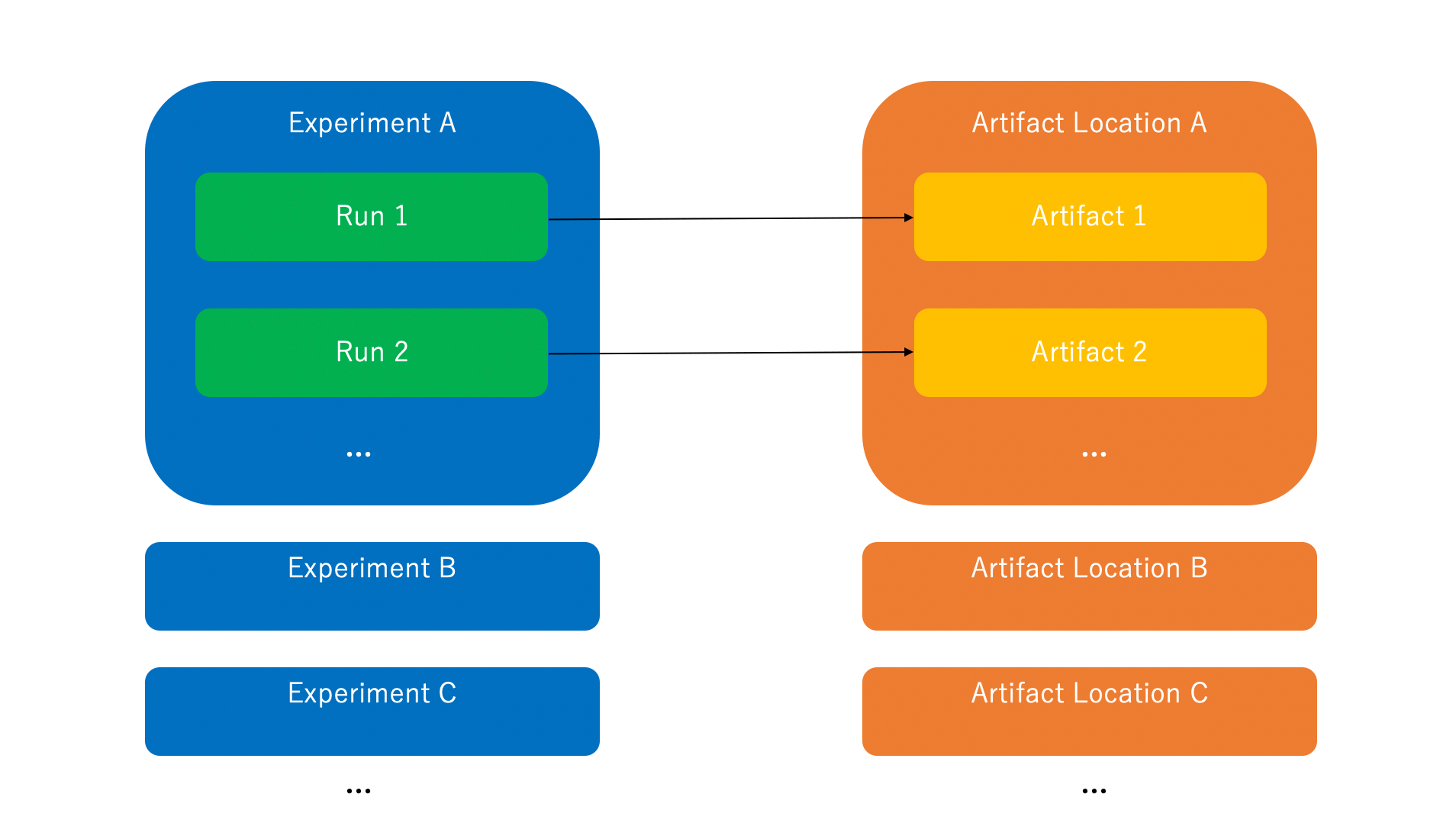
4. MLflowのアーキテクチャ
MLflowのデータストアを覗いてみるに分かりやすく詳しく記載されています。
- Run
- 1回の試行(実験、学習、前処理、etc)
- Experiment
- Runを束ねるグループ
- 格納先は、ローカルファイル or HTTPリモートサーバ or DB
- Artifact
- Runで得られた出力や中間生成物の保管先
- 格納先は、ローカルファイル or S3
5. MLflowのシンプルな使い方
pipでインストールしたら、あとはlogger感覚で記録したい値を設定するだけです。
※MLflow Tracking Serverを別途立てず、ローカルに保存・確認する場合。
インストール
pipを用いてmlflowをインストールします。
pip install mlflow |
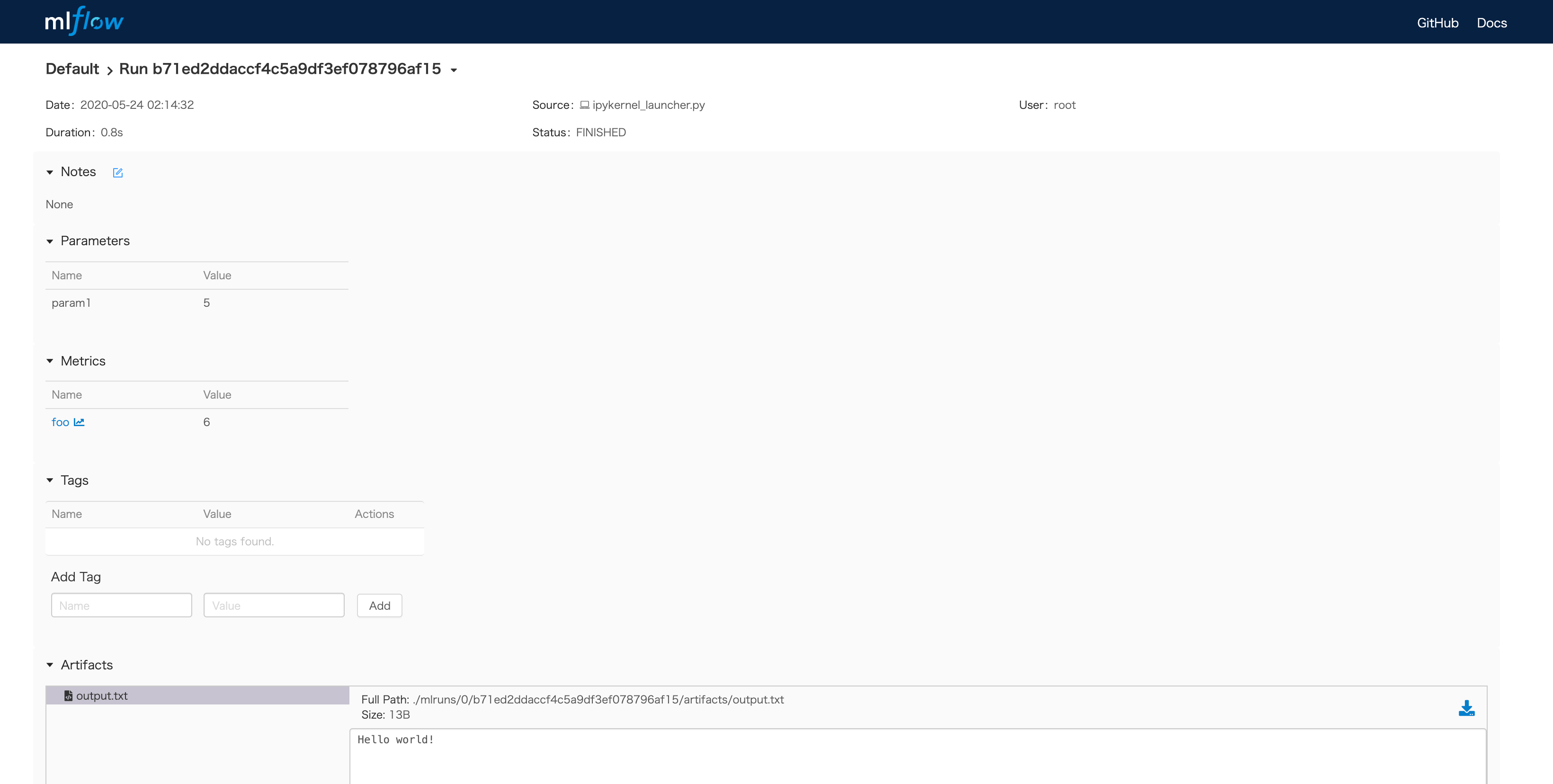
実装例
- start_run
- runIDを発行する
- log_param
- パラメータを記録する
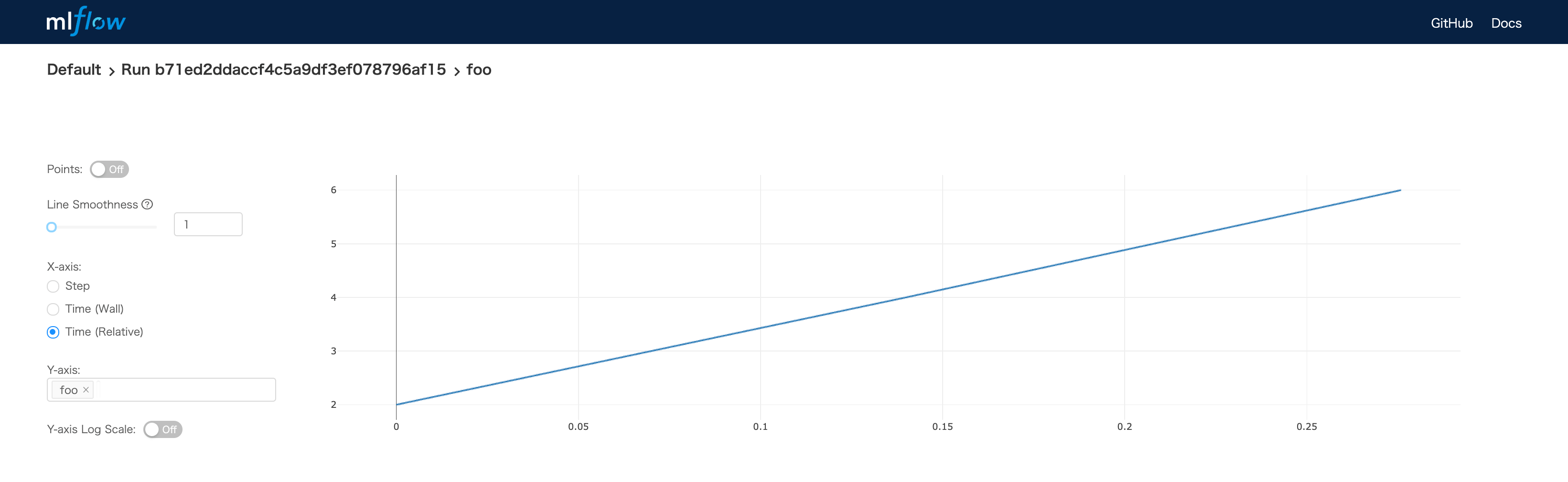
- log_metric
- メトリックを記録する(ステップごとに)
- log_artifact
- 生成物を記録する
- UIからディレクトリ・ファイルの中身を確認できる
import mlflow |
- -> UIで実験結果を確認できる。
$ mlflow ui |
6. MLflowの実践的な使い方
MLflowを実際に使うときによくやること。
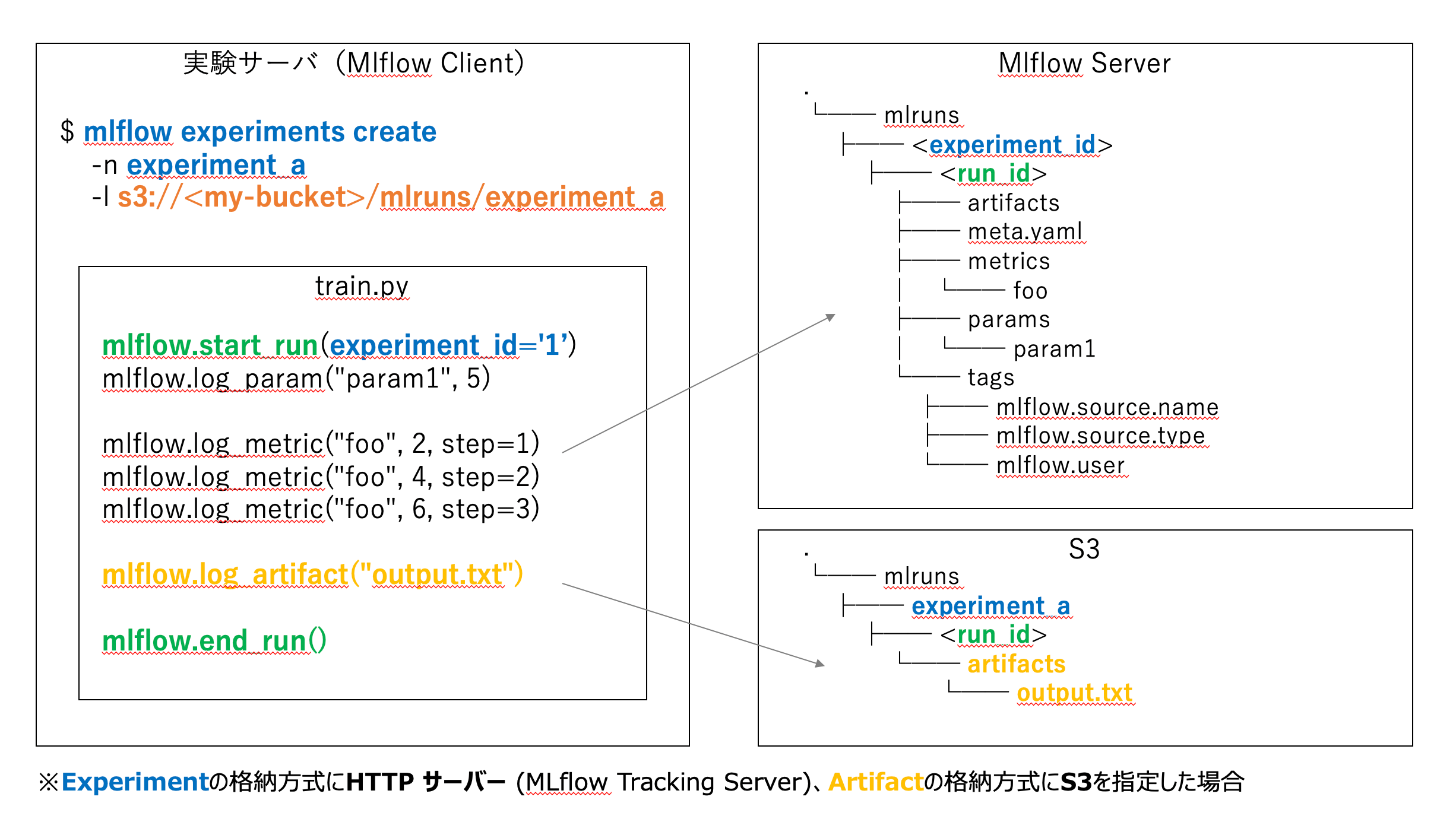
6-1. MLflow Tracking Serverを実験サーバと別で立てる
Experimentの格納方式にHTTPサーバー(MLflow Tracking Server)を指定します。
設定内容(Server側)
pipを利用してインストールします。
pip install mlflow |
MLflow Tracking Server起動します。
- UIのデフォルトポートは5000
- backend-store-uri: 連携されてきたデータの格納先
cd /opt |
設定内容(Client側)
環境変数exportします。
export MLFLOW_TRACKING_URI=http://<MLflow Server IP>:5000 |
6-2. アウトプットの保存先として、S3と連携する
概要
- Artifactの格納方式にS3を指定する
- Artifactのファイルサイズが大きい場合、S3に格納するとよい
- S3に格納しても、Artifacts Viewerで中身を確認することは可能
- 別途、Server側・Clinet側の双方でS3アクセス用のIAMを設定しておく必要あり
設定内容
- boto3をServer側・Clinet側の双方でインストールしておきます
pip install boto3 |
- experimentsを作成時に格納先を指定します
mlflow experiments create -n experiment_a -l s3://<my-bucket>/mlruns/experiment_a |
- -> run時にexperimentsを指定する。
mlflow.start_run(experiment_id='1') |
6-3. log_artifactを非同期に実行する
Artifactのファイルサイズが大きい場合、非同期で実行させます。
設定内容
import mlflow |
6-4. 実験の再現に必要な項目を連携する
実験の再現に必要な項目を、実験ごとに予め定義しておきます。
設定内容
| 連携する項目 | 連携に使うメソッド |
|---|---|
| 実行時刻 | run発行時に自動で連携される |
| 実行ファイル名 | mlflow.set_tag('mlflow.source.name', filename) |
| 実行ファイルcommitID | mlflow.set_tag('mlflow.source.git.commit', commit_id) |
| 実験の説明 | mlflow.set_tag('mlflow.note.content', DISCRIPTION) |
| Inputデータ | mlflow.log_param("INPUT_DATA_PATH_S3", INPUT_DATA_PATH_S3) |
| Outputデータ | mlflow.log_param("OUTPUT_DATA_PATH_S3", OUTPUT_DATA_PATH_S3) |
| パラメータ | mlflow.log_param("IMAGE_SIZE", IMAGE_SIZE) |
| メトリック | mlflow.log_metric("foo", 2, step=1) |
| 実行結果HTML | mlflow.log_artifact(output_reports_file_path_local) |
※スクリプトファイルの場合は、「実行ファイル名」「実行ファイルcommitID」は自動で連携される。
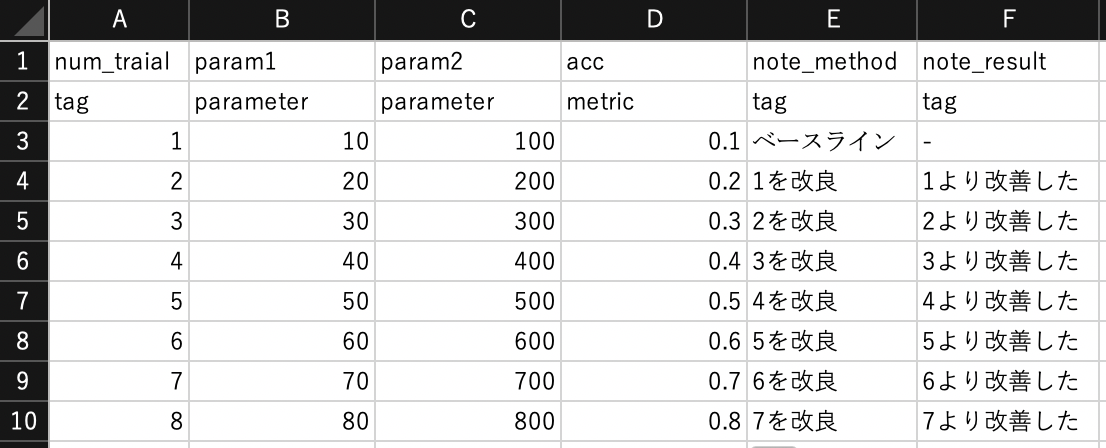
6-5. すでにExcelにて実験結果を管理している場合は、移行(インポート)する
Excelですでにまとめている内容を、MLflowに移行(インポート)します。
設定内容
- 元ファイル例
- 二行目にタイプ(parameter/metric/tag)を追記しておく。
移行スクリプト例を載せます。
import mlflow |
実行結果
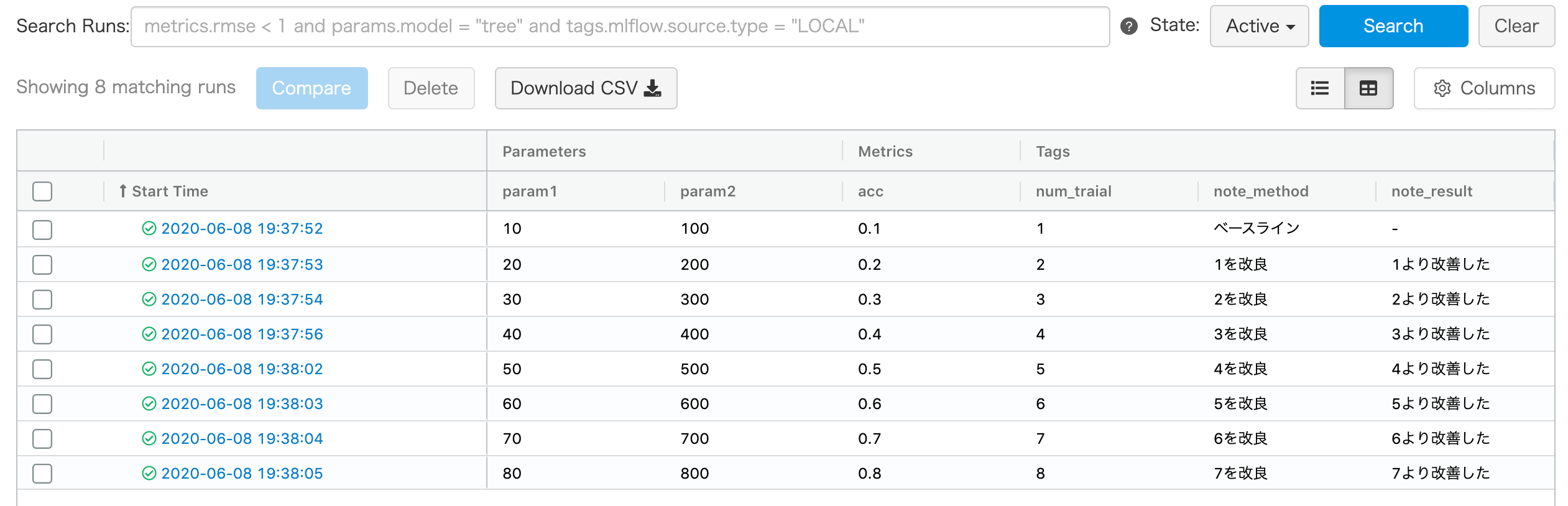
6-6. 過去の特定の試行結果(run)と比較する
過去の特定の試行結果(ベースラインとしたい結果など)と比較します。ベースラインとしたい試行にtagを打っておきます。
設定内容です。
# 今回の試行でのacc |
6-7. 実験結果をチャットに通知する
runが完了したタイミングで、実験結果をチャットに通知させます。
設定内容です。
# start mlflow run |
7. 他の実験管理ツール
- Trains
- “Auto-Magical Experiment Manager & Version Control for AI”
- Weights and Biases
- “Developer tools for machine learning”
- comet
- “Comet provides a self-hosted and cloud-based meta machine learning platform allowing data scientists and teams to track, compare, explain and optimize experiments and models.”
- neptune
- “The most lightweight experiment management tool that fits any workflow”
- mag
- “mag is a very simple but useful library with primary goal to remove the need of custom experiment tracking approaches most people typically use. The focus is on reproducibility and removing boilerplate code.”
8. 参考
おわりに
今回は、実験管理ツールとして、MLflowをご紹介させていただきました。
実験管理以外にも、学習基盤・パイプラインツール・CI/CDなどなども知見が貯まりつつあるので、また別の機会にご紹介できればと思います。
本記事は同じチームの真鍋さんにレビューしていただきました。真鍋さん、ありがとうございました!