はじめに
こんにちは、TIG コアテクノロジーユニットの平岡です。
コアテクノロジーユニットはフューチャーグループ全体のビジネスを支えるコアとなる技術をグループ横断で提供することをミッションにしています。またOSS活動も活発に行っています。コアテクノロジーユニットのメンバーが以前に投稿した記事をいくつか紹介しておきますので、是非そちらもご覧ください。
ANTLRとは
皆さんはANTLRをご存知でしょうか? ANTLRとはparser(構文解析器)を生成するためのツール(パーサジェネレータ)で、以下のような特徴があります。
- grammar(解析したいテキストの構造に関するルールを定義したもの)を元に、parserを自動生成できる
- 解析対象をparserに渡した後に構成されるAST(抽象構文木)をトラバースすることで、目的に合った解析を行うことができる
- 様々なプログラミング言語のgrammarが公式で整備されている
- もちろん、自分でgrammarを作ることもできる
- ターゲット言語(生成されるparserの実装に使用可能な言語)はJava, JavaScript, Pythonなど主要なものをサポートしている(詳細)
- Javaで開発をしない人向けに:ただし、ANTLRはJavaで実装されているため、Java以外の言語で実装されたparser生成にもJavaが必要となる(Javaコマンドでparser生成したい場合の手順)
このように非常に汎用性の高いツールであり、応用先は多岐にわたるようです。公式サイトによると、Twitterの検索機能にも使われているという記述がありました。
パーサジェネレータや構文解析に関連した他のトピックもいくつか紹介しておきましょう。
- ANTLR以外のパーサジェネレータの例としては、JavaCC(Java), PEG.js(JavaScript), Bison(C)などが有名ですが、いずれもターゲット言語=実装言語です。一方で、ANTLRはターゲット言語の種類が多いという特徴を持ちます。
- 同じコアテクノロジーユニットのメンバーである太田さん(Vue.jsのコミッターです! )がメンテしているeslint-plugin-vueでは、ANTLRは使っていませんがASTに基づいた構文解析を行っています。
この記事では、まずシンプルな例を通してANTLRの概要を説明します。その後、ANTLRを使って業務で生じた課題を解決した時の話について述べたいと思います。
ANTLRの概要
lexerとparser
ANTLRはgrammarを元にparserを自動生成できることを上で述べましたが、より正確には、解析対象のテキストをparserに渡すために必要なlexer(字句解析器)も生成します。ここでは、123 + 456のような2個の整数を足す式を構文解析する例を通してlexer, parserの役割について説明します。
まず、解析対象がlexerを経由してparserに渡るイメージを見てみましょう。
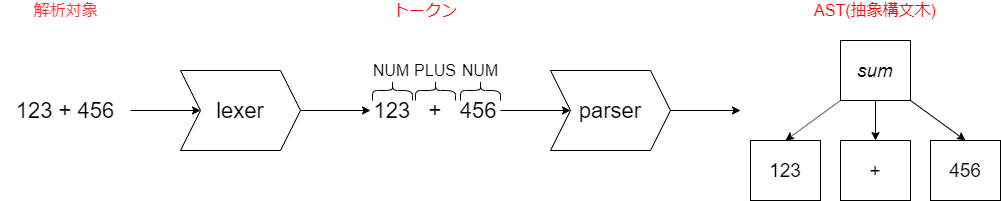
lexerの役割は、解析対象を読んでトークン(1つの意味を持つ最小単位)の列に分解することです。この例では、2個の整数を足す式123 + 456を3つのトークン123,+,456に分解しています。なお、123 + 456には空白が含まれていますが、grammarを上手く設定すると読み飛ばすことができます(後述)。
parserの役割は、トークンの列を読んでAST(抽象構文木)を構成することです。listenerやvisitor(後述)を実装してASTをトラバースすることで、目的に合った解析処理を行うことができます。
lexer, parserを生成するためにgrammarには何を記述すれば良いのでしょうか?
基本的には、ルール名:ルール定義;の形式でルールを列挙します。実際に例を見てみましょう。
SampleLexer.g4
lexer grammar SampleLexer;
NUM
: [0-9]+
;
PLUS
: '+'
;
SPACE
: ' ' -> skip
;
|
SampleParser.g4
parser grammar SampleParser;
options { tokenVocab=SampleLexer; }
sum
: NUM PLUS NUM
;
|
VSCodeをお使いの場合は、ANTLR4 grammar syntax supportという拡張を導入するとシンタックスハイライトが使えて見やすくなります。また、この拡張はgrammarの構造を可視化する機能も備えており(詳しくはこちら)、非常に便利です。
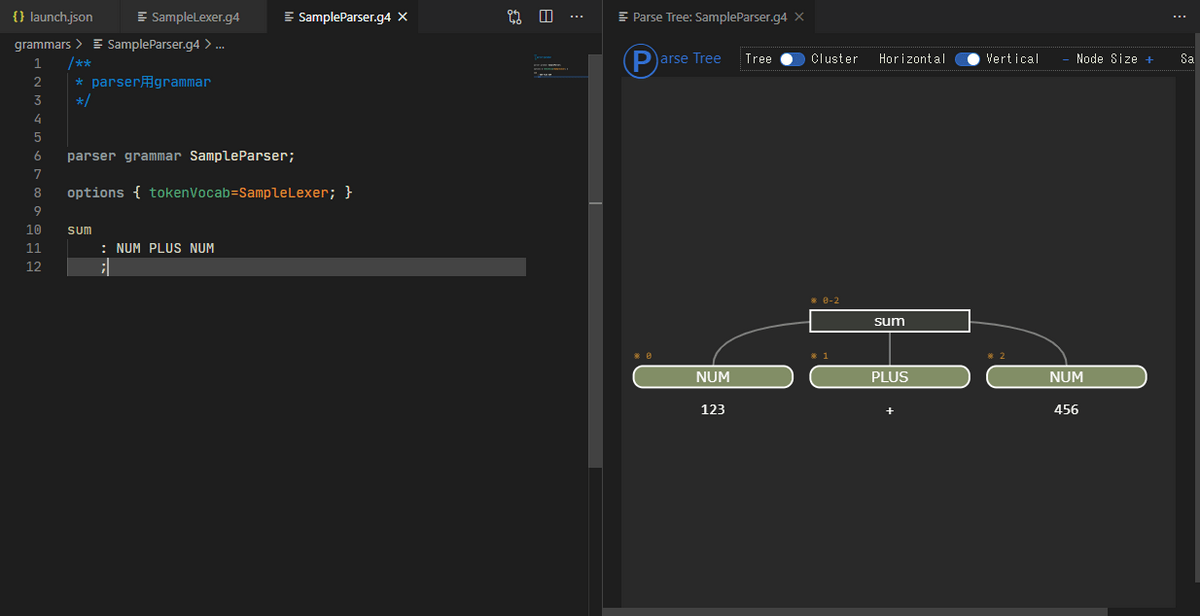
grammarの説明に戻りましょう。
lexer用とparser用のgrammarを分割して記載していますが、同一ファイルで記述することもできます。保守性を考慮する場合は、分割するのが良いでしょう。
lexerとparserのルールを区別するために、lexerの場合はルール名は大文字始まり、parserの場合はルール名は小文字始まりで記述する必要があります。
lexerのルール定義について見てみましょう。例えば、整数を表すトークンNUMの定義は、[0-9]+ですが、これは数字1個以上からなる文字列を最長一致でマッチさせてNUMというトークンに割り当てることを意味します。
parserのルール定義について見てみましょう。sumというルールは、NUM,PLUS,NUMという3つのトークンから構成される列(つまり、足し算の式)であるという定義です。sumのようなルール名はASTの節点に対応し、NUM, PLUS, NUMのようなルール定義を構成する要素はルール名に対応する節点の子に対応しています。
lexer用grammarのSPACEでは、skipコマンドを使うことで空白を読み飛ばしています。skipコマンドを使わないで空白をケアする場合は、parser用grammarのsumの定義が下記のように複雑になってしまいます。このように、lexerの定義次第でparserの定義が複雑になり得るので注意が必要です。
sum
: SPACE* NUM SPACE* PLUS SPACE* NUM
;
|
grammarの詳細については、公式ドキュメントを参照して下さい。
では、上に載せたgrammarを元に、Mavenでparserを生成してみましょう。
ANTLR v4 Maven pluginのデフォルトの動作の特徴は次の通りです。
src/main/antlr4以下に配置されたgrammarファイル(.g4ファイル)を参照してparser等を生成する- 生成されるparser等のパッケージ構造は、
src/main/antlr4から見た相対パスを元に自動で設定される
jp.co.future.antlr.parserパッケージにparser等を格納したい場合は下記のようにgrammarを配置すれば良いです(参照するgrammarや設定したいパッケージ名をpom.xml内で明示的に指定することもできます)。
src
├─main
│ ├─antlr4
│ │ └─jp
│ │ └─co
│ │ └─future
│ │ └─antlr
│ │ └─parser
│ │ SampleLexer.g4
│ │ SampleParser.g4
│ │
(省略)
|
また、pom.xmlに以下のように追記します。
pom.xml<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<build>
<plugins>
<plugin>
<groupId>org.antlr</groupId>
<artifactId>antlr4-maven-plugin</artifactId>
<version>${antlr.version}</version>
<configuration>
<outputDirectory>src/main/java</outputDirectory>
<listener>true</listener>
<visitor>true</visitor>
</configuration>
<executions>
<execution>
<id>antlr-generate</id>
<phase>generate-sources</phase>
<goals>
<goal>antlr4</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr4-runtime</artifactId>
<version>${antlr.version}</version>
</dependency>
</dependencies>
<properties>
<antlr.version>4.8-1</antlr.version>
</properties>
</project>
|
mvn antlr4:antlr4を実行すると、下記のようにparser等が生成されました。
src
├─main
│ ├─antlr4
│ │ └─jp
│ │ └─co
│ │ └─future
│ │ └─antlr
│ │ └─parser
│ │ SampleLexer.g4
│ │ SampleParser.g4
│ │
│ └─java
│ │ SampleLexer.tokens
│ │ SampleParser.tokens
│ │
│ └─jp
│ └─co
│ └─future
│ └─antlr
│ │ App.java
│ │
│ └─parser
│ SampleLexer.interp
│ SampleLexer.java
│ SampleParser.interp
│ SampleParser.java
│ SampleParserBaseListener.java
│ SampleParserBaseVisitor.java
│ SampleParserListener.java
│ SampleParserVisitor.java
(省略)
|
listenerとvisitor
grammarを元にparserを生成できました。
ここからは、parserから得られるASTをトラバース(ASTのノードを深さ優先探索で順番に訪問)し、目的に合った解析を行う方法について見ていきましょう。
今回は、+の右側の整数を取得したいという目的があるとしましょう(例えば、123 + 456が入力の場合は456を出力)。
ASTをトラバースするためには、listenerもしくはvisitorを実装する必要があります。
まずは、listenerの実装例を見てみましょう。
ExtractRhsNumListener.javapackage jp.co.future.antlr.parser;
public class ExtractRhsNumListener extends SampleParserBaseListener {
Integer rhsNum;
@Override
public void exitSum(SampleParser.SumContext ctx) {
setRhsNum(new Integer(ctx.NUM(1).getText()));
}
public Integer getRhsNum() {
return rhsNum;
}
public void setRhsNum(Integer rhsNum) {
this.rhsNum = rhsNum;
}
}
|
App.javapackage jp.co.future.antlr;
import jp.co.future.antlr.parser.ExtractRhsNumListener;
import jp.co.future.antlr.parser.SampleLexer;
import jp.co.future.antlr.parser.SampleParser;
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTreeWalker;
public class App {
public static void main(String[] args) {
extractRhsNumByListener();
}
public static void extractRhsNumByListener() {
CharStream cs = CharStreams.fromString("123 + 456");
SampleLexer lexer = new SampleLexer(cs);
CommonTokenStream tokens = new CommonTokenStream(lexer);
SampleParser parser = new SampleParser(tokens);
ParseTreeWalker walker = ParseTreeWalker.DEFAULT;
ExtractRhsNumListener listener = new ExtractRhsNumListener();
walker.walk(listener, parser.sum());
System.out.println(listener.getRhsNum());
}
}
|
実行結果
listenerの特徴は以下の通りです。
- ASTの全ノードを訪問する
- ノードに入るタイミング(
enterXXXメソッド)・ノードを抜けるタイミング(exitXXXメソッド)に行う処理を目的に合わせてOverrideする
- Overrideするメソッドは返り値を持たないため、欲しい値はフィールドで保持する必要がある
上の実装例のExtractRhsNumListener#enterSumは、ASTでsumノードを最初に訪問した時に2番目のNUM(つまり、+の右側の整数)をセットする処理を行っています。
enterSumではなくexitSumでOverrideしても同様の実行結果が得られます。
続いて、visitorの実装例を見てみましょう。
ExtractRhsNumVisitor.javapackage jp.co.future.antlr.parser;
public class ExtractRhsNumVisitor extends SampleParserBaseVisitor<Integer> {
public Integer visitSum(SampleParser.SumContext ctx) {
return new Integer(ctx.NUM(1).getText());
}
}
|
App.javapackage jp.co.future.antlr;
import jp.co.future.antlr.parser.ExtractRhsNumVisitor;
import jp.co.future.antlr.parser.SampleLexer;
import jp.co.future.antlr.parser.SampleParser;
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTree;
public class App {
public static void main(String[] args) {
extractRhsNumByVisitor();
}
public static void extractRhsNumByVisitor() {
CharStream cs = CharStreams.fromString("123 + 456");
SampleLexer lexer = new SampleLexer(cs);
CommonTokenStream tokens = new CommonTokenStream(lexer);
SampleParser parser = new SampleParser(tokens);
ParseTree tree = parser.sum();
System.out.println(new ExtractRhsNumVisitor().visit(tree));
}
}
|
実行結果
visitorの特徴は以下の通りです。
- ASTの全ノードを訪問するとは限らない
- ノードに入った時(
visitXXXメソッド)に行う処理を目的に合わせてOverrideする
- Overrideするメソッドは返り値を持つため、欲しい値をフィールドで保持しなくてよい
上の実装例のExtractRhsNumVisitor#visitSumは、ASTでsumノードを最初に訪問した時に2番目のNUM(つまり、+の右側の整数)を返す処理を行っています。
listenerでは自動的にASTの全ノードを訪問するのに対し、visitorの場合は今いるノードの部分木を訪問したい場合は明示的に実装する必要があるという大きな違いがあります。
業務で生じた課題
以降では、業務で生じた課題をANTLRで解決した話について述べたいと思います。課題の概要は以下の通りです。
以下のような<template>, <script>, <style>ブロックから構成されるvueファイルが与えられます。
input.vue<template>
<p>{{ greeting }} World!</p>
</template>
<script>
export default {
data () {
return {
greeting: 'Hello'
}
}
}
</script>
<style>
p {
font-size: 2em;
text-align: center;
}
</style>
|
このとき、以下のように<script>ブロックの中身を抽出する処理をJavaで実装して下さい。
output.jsexport default {
data () {
return {
greeting: 'Hello'
}
}
}
|
解決策
- 正規表現では難しい
<script>(.*)</script>で良さそうに見えるが、以下のようなコメントがある場合に対応できない
<script>
export default {
}
</script>
|
- DOMやNekoHTMLなどのJavaで動作するXML用parserでは正しくparseできない場合があった
- 当時はANTLRについて調査するタスクも担当していたため、ANTLRで対応を試みた
- Vue.js用のgrammarは公式で用意されていなかったが、
<script>ブロックの中身を取り出せれば十分なので、grammarを自作することにした
コード
lexer用grammarを表示
SimpleVueLexer.g4
lexer grammar SimpleVueLexer;
HtmlComment
: '<!--' .*? '-->' -> skip
;
WhiteSpaces
: [\t\u000B\u000C\u0020\u00A0]+ -> skip
;
LineTerminator
: [\r\n\u2028\u2029] -> skip
;
TemplateOpen
: '<template' .*? '>' -> pushMode(TEMPLATE)
;
ScriptOpen
: '<script' .*? '>' -> pushMode(SCRIPT)
;
StyleOpen
: '<style' .*? '>' -> pushMode(STYLE)
;
mode TEMPLATE;
CommentInTemplate
: '<!--' .*? '-->' -> skip
;
TemplateClose
: .* '</template>' -> popMode
;
mode SCRIPT;
MultiLineComment
: '/*' .*? '*/'
;
SingleLineComment
: '//' ~[\r\n\u2028\u2029]*
;
ScriptClose
: '</script>' -> popMode
;
ScriptText
: (~[</] | '<' ~'/' | '/' ~[*/])+
;
mode STYLE;
CommentInStyle
: '<!--' .*? '-->' -> skip
;
StyleClose
: .* '</style>' -> popMode
;
|
parser用grammarを表示
SimpleVueParser.g4
parser grammar SimpleVueParser;
options { tokenVocab=SimpleVueLexer; }
parse
: templateElement? scriptElement styleElement?
;
templateElement
: TemplateOpen TemplateClose
;
scriptElement
: ScriptOpen scriptBody ScriptClose
;
scriptBody
: (SingleLineComment
| MultiLineComment
| ScriptText)+
;
styleElement
: StyleOpen StyleClose
;
|
抽出用listenerを表示
JavaScriptExtractorListener.javapackage jp.co.future.antlr.parser;
import java.io.IOException;
import java.nio.file.Paths;
import jp.co.future.antlr.parser.SimpleVueParser.ScriptElementContext;
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTreeWalker;
public class JavaScriptExtractorListener extends SimpleVueParserBaseListener {
private String scriptBody;
public void exec(String filePath) throws IOException {
CharStream cs = CharStreams.fromPath(Paths.get(filePath));
SimpleVueLexer lexer = new SimpleVueLexer(cs);
CommonTokenStream tokens = new CommonTokenStream(lexer);
SimpleVueParser parser = new SimpleVueParser(tokens);
ParseTreeWalker walker = ParseTreeWalker.DEFAULT;
walker.walk(this, parser.parse());
}
@Override
public void enterScriptElement(ScriptElementContext ctx) {
scriptBody = ctx.scriptBody().getText();
}
public String getScriptBody() {
return scriptBody;
}
}
|
この記事に掲載したコードをGitHub上でもご確認頂けます。
https://github.com/f-t-hiraoka/antlr-sample
まとめ
正規表現や既存のparserでは対応が難しい課題をANTLRを利用して解決しました。文字列の処理で困ったときは、選択肢の1つとして検討してみてはいかがでしょうか。
コアテクノロジーユニットでは、現在チームメンバーを募集しています。
私たちと一緒にテクノロジーで設計、開発、テストの高品質・高生産性を実現する仕組みづくりをしませんか?
参考