GlyphFeeds連載企画第5弾の記事となります。
はじめに
はじめまして、2018年新卒入社の渡邉です。
第5弾はGlyphFeedsCMSにおけるSpringを駆使したルールエンジンについてです!
新聞業界の多種多様に変化する業務体系に対してどのようにシステムを構築したかご紹介致します。
新聞社の業務について
ニュース(=コンテンツ)を世の中に配信していく過程において、新聞社には大きく次のアクターが関わります。
- 記者:取材活動を元に記事を書く、写真・動画を撮影する
- デスク:記者から連携された記事や写真・動画を確認し出稿する
- 校閲:記者やデスクから連携された素材に誤りがないか(誤字脱字・事実関係)を確認する
- 紙面制作担当:新聞制作においてレイアウトを調整する
- デジタル配信担当:デジタルサイト(各社ニュースサイト、スマホアプリなど)向けにコンテンツを編集・配信する
記者がニュース記事となる素材(テキストや写真)を生み出し、デスクや校閲と渡って紙面制作担当まで届き、
新聞やニュースサイトに組み上げられるという大枠でのワークフローはあります。
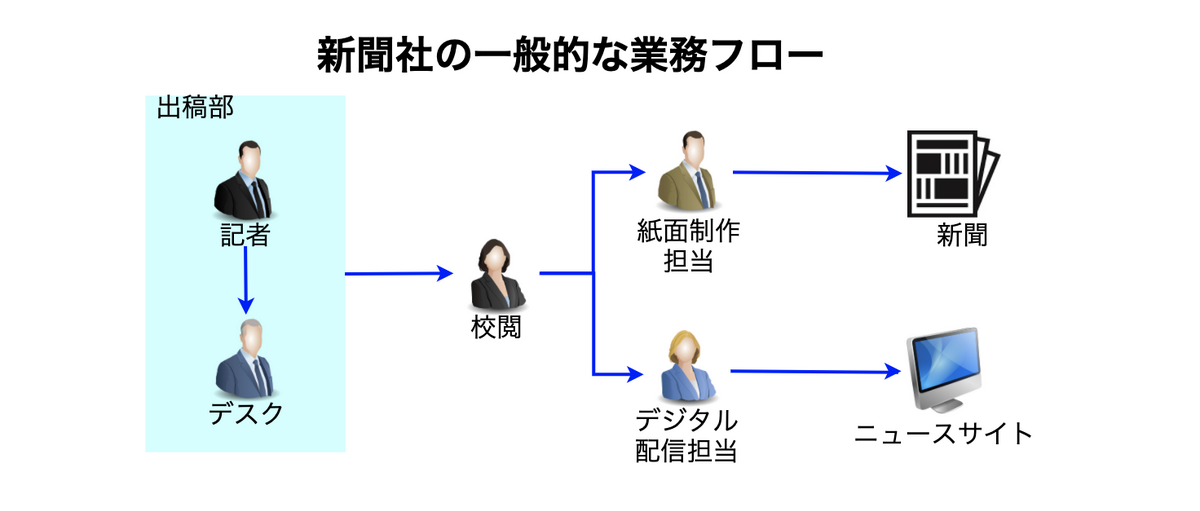
ベースのワークフローをシステムで担保することは当然ですが、
新聞社では選挙やオリンピックといったイベント事に対して、専用のチーム(≒組織)が組成され、通常のフローとはことなるワークフローをまわすことがよくあります。
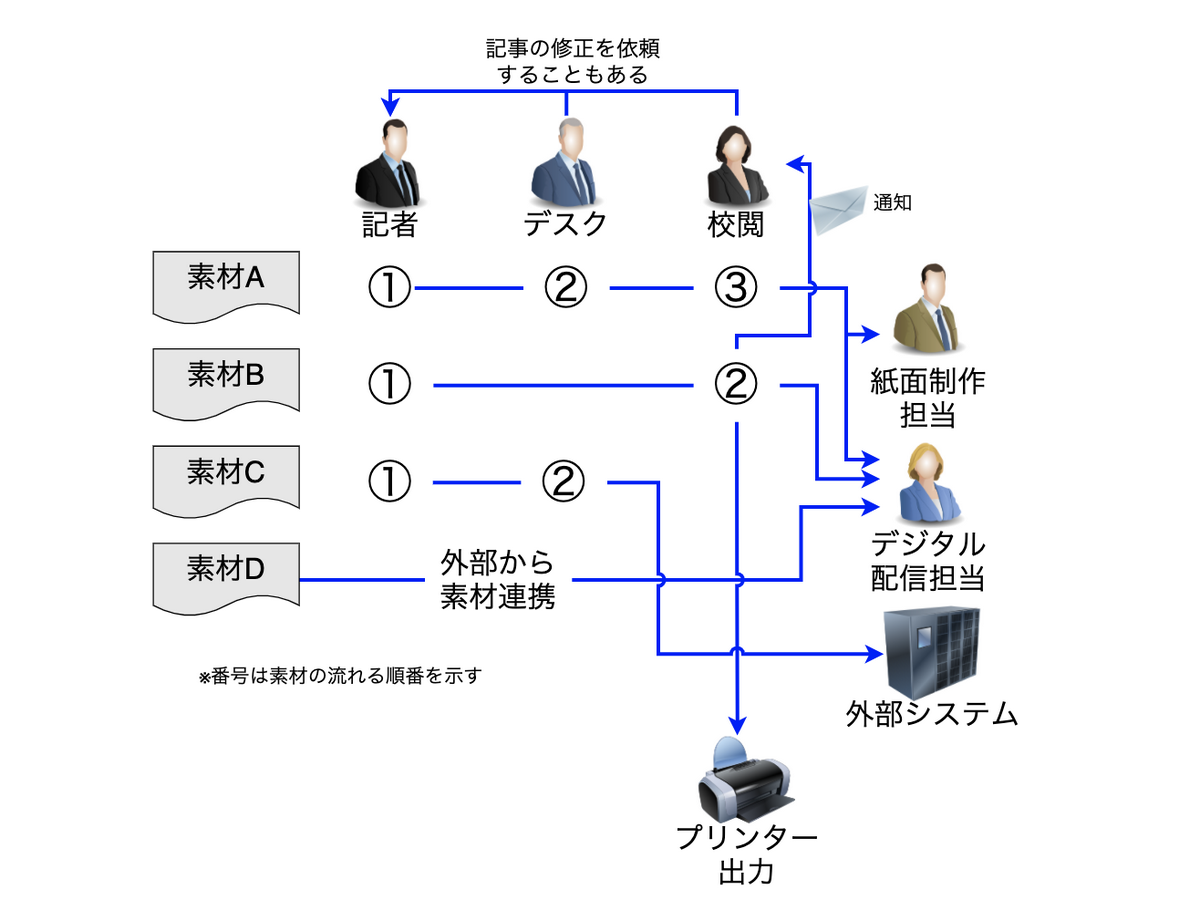
各素材に対してアクターがどんなアクションをしたか、素材の属性情報(新聞社では1素材に対して約500程の属性がある)によって全く異なるフロー・処理を行う必要があります。ここで示したフローはごく一部であり、実際の業務では時と場合により様々な素材に対して様々なワークフローでニュース記事が作られます。
つまり、まともにシステムを構築しようとすると、莫大なパターンの業務ロジックを実装しないといけない、しかもそのパターンがシステム稼動後も組織変更や業務変更によって増減してしまいます。
上記のような複雑な業務に対応するため、ビジネスロジックを部品化して自由に組み合わせることができるルールエンジンという仕組みで実現しました。
ルールエンジンの概要
GlyphFeedsのルールエンジンの全体概要は以下の図のようになっています。
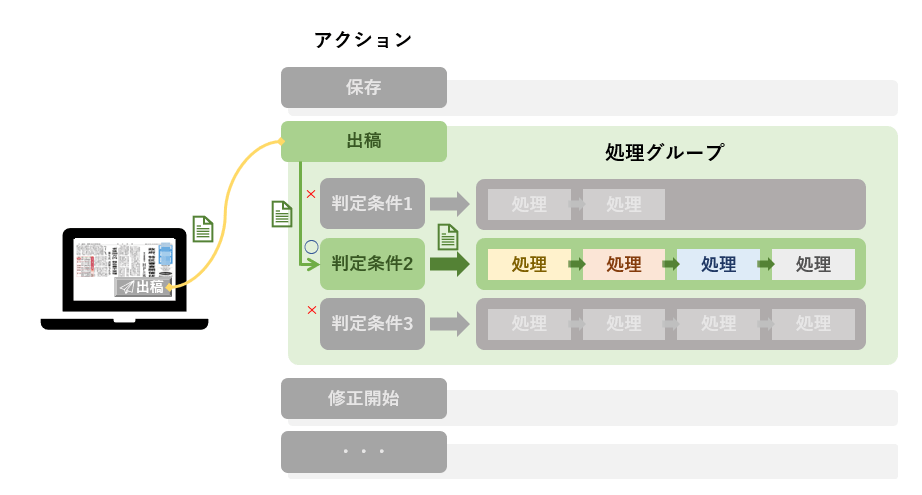
GlyphFeedsで管理する素材データに対し、画面などから特定のアクション(例えば保存や出稿など)が実行されると、そのアクションに対応する各条件に素材データがマッチするか判定し、マッチした条件に対応する処理グループが実行されます。
処理グループ内では、複数の定義済ルールエンジン処理を自由に組み合わせることができ、これによって自動化したい操作を実現しています。
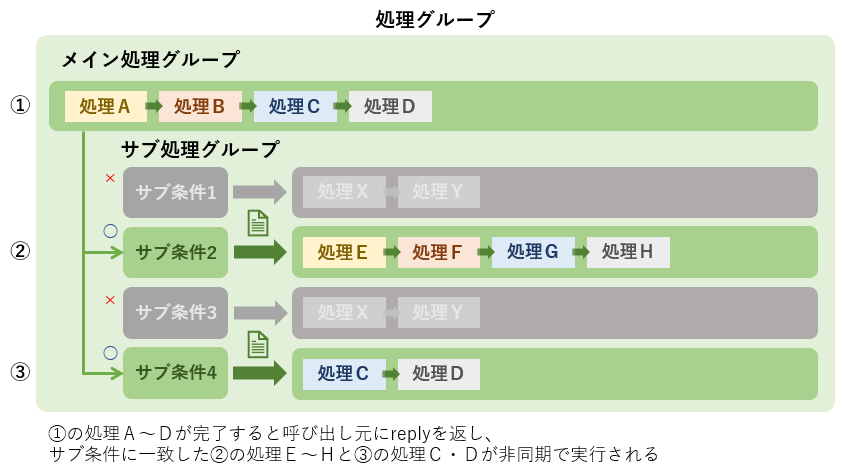
処理グループ
処理グループの部分について、実際にはさらにメイン処理グループとサブ処理グループに分かれています。
メイン処理グループは1つの条件に対して1つ、サブ処理グループは複数定義でき、サブ処理グループには追加で判定条件を指定できます。メイン処理グループは基本的に同期で、サブ処理グループは非同期で実行されます。メイン処理グループから非同期に設定することも可能です。
処理の定義方法
上述した内容はすべてRDS登録されたルールエンジン定義に従います。
各アクション別の処理条件、条件一致した際に実行される処理、各処理に渡すパラメータなどが定義されています。定義アップロード時にファイル内容を解析し、RDS上のテーブルにデータを格納しています。
どう実現したか?
さて、ここからはこのルールエンジンが具体的にどのように実装されているのかについて掻い摘んで説明させていただきます。
以下の図で示す通り、実装上はルールエンジン実行とメイン処理実行、サブ処理実行、処理グループ実行、個別処理に分かれています。画面などで素材に対してアクションが実行されると、ルールエンジン実行のREST APIが呼び出されそこから個別処理が開始します。
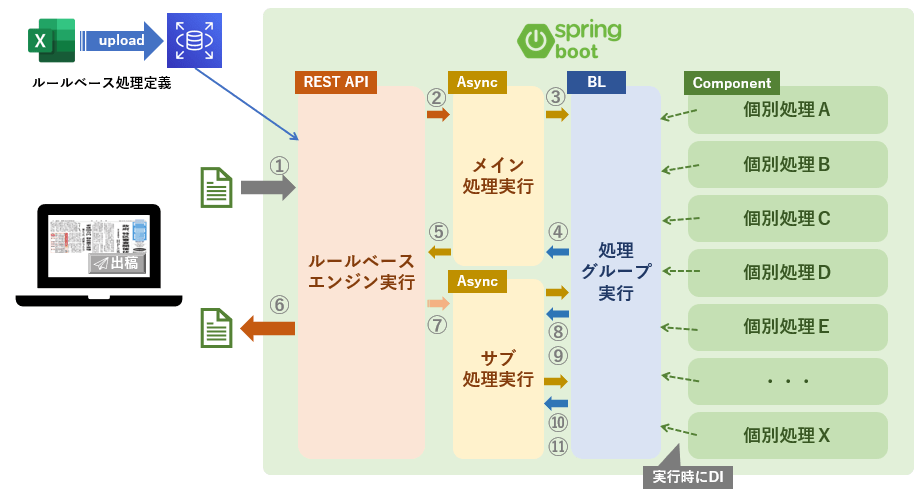
ルールエンジン実行
個別処理の実行を担うREST APIです。
素材の情報と実行に必要なパラメータを受け取り、ルールエンジン定義を読み込んで条件判定を行い実行すべき処理を特定します。そこから、メイン処理実行とサブ処理実行が呼び出されます。
メイン処理実行・サブ処理実行
メイン処理実行とサブ処理実行はSpring BootのAsyncスレッドを利用して実装されています。
長くなってしまうのでここでは詳細は割愛しますが、AsyncスレッドとJava標準のCompletableFutureを組み合わせており、非同期実行でありながらメイン処理実行部分は同期的にレスポンスを返すことができるようになっています。
処理グループ実行・ルールエンジン個別処理
ここではSpringのDI(Dependency Injection)の仕組みを利用して、定義に従い実行時に動的に処理を切り替えます。
各処理グループ内には最大で10個までの処理を定義でき、定義された順にSpringのDIコンテナから対応するルールエンジン個別処理のBeanを取得して処理を実行していきます。
各ルールエンジン個別処理の実装クラスは共通のインタフェースをimplementしており、コンテナ登録時のBean IDをルールエンジン定義のIDと紐づけることにより取得するBeanを特定し、定義ベースでのDIを実現しています。これにより、ソースコードに一切手を加えることなく定義のみで柔軟に実行する処理を切り替えることが可能となります。
ルールエンジン個別処理と処理グループ実行部分の依存関係が疎(動的)になっているため、新たにルールエンジン個別処理を追加するケースでも、1つルールエンジン個別処理を実装し、それをルールエンジン定義に指定するだけですぐに使えるようになりメンテナンス性が高い仕組みとなっています。 1
各処理には共通のデータコンテキストが渡され、処理間のデータのやり取りはすべてコンテキストを通して行われます。
細かい部分はお見せできなくて申し訳ないのですが、少しでもイメージが沸くようにルールエンジン個別処理のインタフェース定義と個別処理、処理グループ実行処理の実装サンプル(大枠だけですが💦)を掲載します。
public interface WfInstructedProcess<T extends BaseProcessParam> { |
import org.springframework.stereotype.Component; |
|
GlyphFeedsはサービスとして展開しており、ユーザ企業単位の個別カスタマイズが入ることがあります。
そういったケースでも個別処理の追加はWfInstructedProcessの実装クラス(とその処理のパラメータクラス)を作成してルールエンジン定義を変更するだけ。既存のエンジン部分などには手を加える必要がないので処理追加の要望はもう怖くありません😀
余談ですが、標準でAWS Lambda実行のルールエンジン個別処理も用意されており、簡易な処理であればそちらを利用することも可能です。
最後に
今回はGlyphFeedsの根幹部分を担っているといっても過言ではない、ルールエンジンについて、仕組みと実装方法の概要をご説明させていただきました。
Springの機能を活用することで、メンテナンス性の高いルールベースエンジン処理を比較的簡単に実現できますので、少しでも参考になれば幸いです。
さて、GlyphFeedsではこれまでの4回でご紹介してきた内容以外にもさまざまな技術要素が含まれています。また機会がありましたらそれらについてもご紹介させていただきますので、次回のGlyphFeeds連載企画までお待ちください!
- 1.実際にはルールエンジン定義の取り込み部分などでもう少し追加で実装が必要となる箇所があります。 ↩