はじめに
はじめまして、Strategic AI Group(以降SAIG)に在籍しています、2019年度入社の真鍋です。学生の頃よりクラウドやHadoop等、大規模分散システムの研究をしていました。その経験と私自身の希望もあり、SAIGでは主にインフラ担当として業務に取り組んでいます。
今回は私がAI分野のインフラに触れ、MLOpsを知り、SAIG全体で利用する学習基盤を構築するまでに得た知見を、一部ではありますが共有させていただければと思い筆を取りました。MLOpsについて興味を持たれていて、具体的な取り組みについて知りたいといった方に読んでいただければ幸いです。
概要
本稿は下記の内容で構成しています。
- MLOpsとは
- SAIGの課題
- 施策1:実験管理についての取り組み
- 施策2:SAIG学習基盤の構築
- まとめと今後の展望
1. MLOpsとは
私がアサインされたSAIGは、フューチャーの一般的なプロジェクトとは異なり、AI技術を用いて横串で色々な企業様とお仕事をさせていただくことが多く、その中ではPoC(Proof of Concept)と呼ばれる、将来的なシステム構築に向けて、新しいアイデアについて実現できるかどうか検証するという概念実証を行っているプロジェクトが多く走っていました。
PoCでは実際にシステム構築を始める前段階として、モデル学習や評価を行うことになるのですが、システム構築を始めるにあたって問題が発生することがあります。PoC時点でどのバージョンのデータを利用して学習したのかが分からなくなったり、実行環境やパッケージに関する整合性の問題でソースコードが動かなくなったり、PoC時点でのメンバーが居なくなった際に引継ぎが十分でなかったたことで当時の再現が難しくなったり等です。
上記の理由もあり、SAIGではMLOpsの概念の導入が求められていました。SAIGにおいてMLOpsとは、「機械学習モデルの実装から運用までのライフサイクルを円滑に進めるための管理体制(機械学習基盤)を築くこと、またはその概念全体」と定義しています。
詳細は、SAIGにて先んじてMLOpsの導入を進めていた山野さんが網羅的にまとめた記事を見ていただければと思います。
本稿では、一般的なMLOpsについて簡単にまとめるに留めます。
MLOpsとはMachine Learning、Develop、Operateをまとめた概念です(参考)。機械学習のプロジェクトにおいて、モデルの作成・学習は全体から見てほんの一部であるという話は良く聞かれます。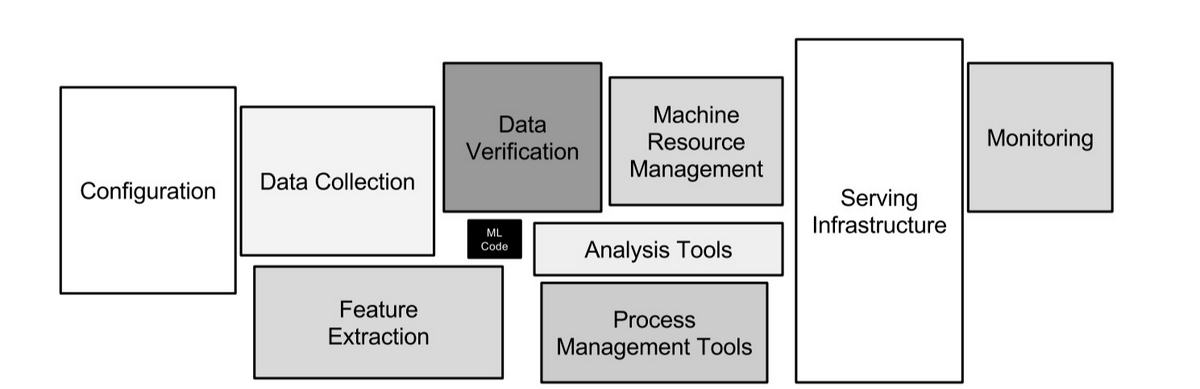
▲ Hidden Technical Debt in Machine Learning Systemsより引用
MLOpsとは、機械学習プロジェクト全体のフローに発生する多様なコストを包括的に削減するための概念だと認識しています。
- 元データ・加工後データを格納し、後から参照することを可能にする
- 作成したコード・モデル・利用したデータ等についてのバージョン管理
- モデルを使ったサービスを提供するための、モデルのパッケージ化・API化
- サービス展開後のモデル精度監視と、再学習・再デプロイの自動化
MLOpsを導入することで、上記のような機械学習プロジェクト全般における課題の解決が期待されます。
2. SAIGの課題
1章ではMLOpsの概要と、MLOpsによって解決を期待される課題について列挙しましたが、SAIGにおいてもほぼ同様な課題が存在していました。私達がMLOpsの導入を行うにあたり最初に実施したことは、実際に機械学習プロジェクトを推進している各リーダーや、最前線でモデル学習を行っているメンバーの方々へのヒアリングです。本章では、SAIGにおいて機械学習プロジェクトを進める中で頻出した困りごとについて一部を紹介します。
後になってから実験の再現ができない
「PoC終了時の結果をもう一度見せて欲しい」「新しいデータがあるので、これでもう一度学習してみて欲しい」といったご要望を企業様よりいただくことがあります。当時のメンバーが在籍しており、直近の記憶で再現することが可能なPoC直後なら良いですが、PoC終了の数ヶ月後にこのようなご要望があった場合、必要な情報が揃っていないと困ったことになります。
実験の再現に必要なのは、masterブランチのソースコードを動かせる(バグが無く、実行コマンドが分かる)ことはもちろん、再現したいソースコードのバージョン、学習時に利用したデータ、そのデータの前処理方法、各種パラメータ値等、多岐にわたります。セキュリティ・ネットワーク・ファイルのパーミッション等、実行する環境の違いや、利用しているパッケージのアップデートによりソースコードが動かなくなることもあります。また、利用しているモデルが変わることで精度に影響することもあるでしょう。
ヒアリングを行った結果、この問題はどの機械学習プロジェクトでも直面する可能性があることが分かりました。あるプロジェクトはExcelやスプレッドシートに結果を記録していたり、あるプロジェクトはGitLabのissueやWikiに結果を各自で投稿していたりと、各々の裁量に任されていました。
開発におけるリソースが不足している
モデル学習には膨大な計算機リソースを必要としますが、SAIGの案件拡大に伴うメンバー増員により計算機に関するコストは増大していました。機械学習プロジェクトにおいて、GPUを多く利用するという面や、学習に長い時間を要するという面がコストの増大に大きく影響しています。
また、企業様より受領するデータをクラウド環境へアップロードする際には、その調整が難しいケースがあることもヒアリングで明らかになりました。その場合はAWSやGCPといったクラウドサービスを利用できません。
SAIGにおいて、プロジェクトを進める上での人的・金銭的コストを抑えた上で、GPUを複数人で利用でき、容量の大きいデータを運用できる計算環境の構築は喫緊の課題でした。
その他の課題
上記以外の、現在対応中な課題についても簡単にご紹介します。それらの課題については、また別の場でご紹介させていただければと思います。
まず多かったのは「Jupyter Notebookを使いたいが、バージョン管理が難しい」といった課題です。Jupyter Notebookはブラウザ上でセルごとにPythonのコーディング・実行をでき、画像等の結果をインタラクティブに表示できる大変優れたツールです。SAIGでも、多くのプロジェクト、特にOCR等の画像を扱うプロジェクトで利用されています。ただ、Notebookファイル(.ipynb)はpythonスクリプト(.py)とは異なり、ファイルに出力結果や実行順番が含まれるため、差分を取ることが難しいという特徴があります。
これは少しMLOpsの対象と外れるかもしれないのですが、繰り返し利用するソースコードのライブラリ化についても話に挙がっていました。SAIGでは先ほど述べたOCR等の画像処理だけでなく、言語処理や最適化問題等のプロジェクトも存在しています。それぞれの分野に在籍されているメンバーは、よく使うソースコードを「秘伝のタレ」として持っていますが、それらを全体に共有し別プロジェクトで利用するには一手間かかります。汎用的なライブラリを分野ごとに用意することも将来的なアイデアとして挙がっています。
3. 施策1:実験管理についての取り組み
MLOpsの導入を進めるにあたり、まずは2章で紹介した「後になってから実験の再現ができない」問題に対して、私達はツールを用いた解決を目指しました。ツールを利用する方針にした理由は、実験の再現に必要な情報は2章で述べた通り多岐に渡るため、ハイパーパラメータチューニングの中で何度も手作業で記録することはコストが高いと判断したためです。私達がツールを選定した基準は下記の通りです。
| フェーズ | 処理内容 | 概要 |
|---|---|---|
| モデル実装 | Notebook対応 | Jupyter notebookによる利用が可能かどうか |
| 複数人の運用 | ソースコードや実行結果等を中央管理できるかどうか | |
| GUI | ブラウザ上で結果を確認するインタフェースを有するかどうか | |
| 記録 | チューニングにおける実際の値とスコアを保存しておけるかどうか | |
| 自動チューニング | パラメータのオートチューニング機能を有するかどうか | |
| 学習 | パラメータ記録 | 学習の際に設定したパラメータや、その他設定値を記録できるかどうか |
| 出力結果記録 | 標準出力の内容や、生成した画像ファイルなどを保管・参照できるかどうか | |
| 学習の再現 | 過去に実行した学習をパラメータを変え再実行できるかどうか | |
| 並列学習 | 学習においてクラスタを利用した並列実行が可能かどうか |
複数のツールについて、上記の観点で実現可能かどうかを実際に動かして調べました。SAIGのプロジェクトは多様であり、1つのツールで全ての要件を満たすことは難しいです。複数のツールを組み合わせ、一部は運用ルールを策定し、一部は基盤に機能を組込むことで上記の要件を満たすことを想定しています。
今回は別ツールとの連携やカスタマイズの容易性から、機械学習ライフサイクルを管理するオープンソースプラットフォームであるMLflowの導入を決定しました。MLflowについての詳細は、別記事にて山野さんが書いています。
詳細はそちらで紹介していますので省略しますが、実験管理として私達が実施した主な施策は下記の通りです。
- 記録するパラメータおよび結果の選定
- インプット・アウトプットデータの保管
- 各実験の比較用プログラムの実装
上記の施策を見ていただくと分かる通り、私達はただツールを導入しただけではありません。データサイエンティストのメンバーと打ち合わせを重ね、必要なパラメータやインプット・アウトプットデータといった情報の選定を選定しました。加えて、実験結果を比較するための独自の手法を、実験管理ツール内で実行できるような追加機能として実装したりもしています。
実際に実験管理ツールを使っていただいたメンバーの方からは、手作業の記録の手間が大幅に省け、作業の効率化が目に見えてできたとコメントをいただいています。MLOpsを実現するためにはツールを入れればOKというわけではなく、環境やサービスを構築するエンジニアと、AIロジックを実装するデータサイエンティストの両立場からの情報の擦り合わせが重要だと感じました。
4. SAIG学習基盤の構築
私達は次の取り組みとして、計算リソースが不足している課題の解決に取り組みました。そのためにローカルで構築する学習基盤は、SAIGのメンバーだけでなく、アルバイトとして業務に協力していただいている方々も含めた大人数が同時に、かつ計算量の大きい学習を長時間回すことが予想されました。
SAIG全体で利用する学習基盤を設計するにあたって、まずは実験管理と同様にヒアリングから始めました。その結果、SAIG全体で運用していくにあたってどうしても考慮しなくてはならない課題や、SAIGのデータサイエンティストの方々が求めている条件が明らかになってきました。一部にはなりますがそれぞれの要件について、その概要と対処法について紹介したいと思います。
物理マシンの追加・削除に対応する
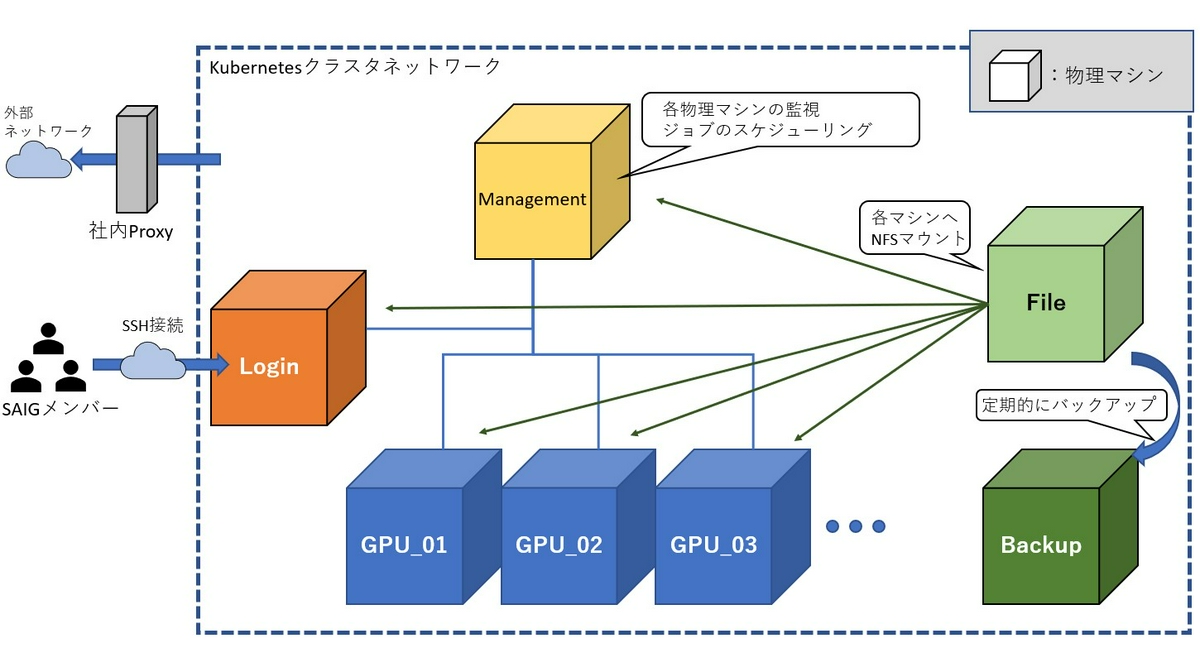
今回、物理マシンは新たに購入したものと、リソースが余っていたマシンを活用してクラスタを構築することとなりました。必要に応じてマザーボードから用意することもあれば、GPUやメモリ、追加NICを買い足しマシンを構築しました。全体の構成は下記の図の通りです。
ソフトウェアスタックは下記の通りです。

利用者はログインノードにsshで接続し利用を開始し、実際の学習はGPUノードで実行されます。ログインノードや管理用のマネジメントノードは良いのですが、GPUノードは将来的にスケールアウトが必要になることが想定されます。また、古いマシンも利用しているため、各ノードの入れ替えが必要になるかもしれません。
そのたびに環境構築をやり直すのは大変な手間がかかり、復旧に失敗する恐れがあります。実験の再現と同様に、環境構築においても風化しない、私達現行のメンバーが不在になっても問題ない仕組みが必要と考えました。そこで今回は全面的にansibleを使った環境構築を採用しています。
ansibleとは構成管理ツールと呼ばれる、サーバ上の環境構築を自動化するアプリケーションです。ansibleの優れている点は、処理ごとの依存関係の設定が可能な点や、実行するノードごとに変数として値を個別に設定できる点にあります。ansibleを利用することでログインノード・マネジメントノード・ファイルサーバ・バックアップサーバ・GPUノードの全ての環境構築を可能としました。
複数人での利用を想定した環境の構築
複数人で同一環境を利用するにあたって、各自・各プロジェクトごとに開発環境を整備できるようにしなければならず、誰かが利用している間、他の人は使えないといったことは避けなければなりません。私達は、複数のマシン上で処理を動かす際の可用性と、複数人が実施する処理のスケジューリングが必要だということ、そして全計算リソースの利用状況を可視化する事を目的にKubernetesの導入を決めました。
コンテナを利用する利点は、OSの多様化に対応できることや、パッケージを気軽に追加できること、複数のマシンで動かすときの差異に影響されにくい等、枚挙に暇がありません。大規模計算クラスタで多く使われているSlurmも候補に挙がりましたが、ジョブ単位での実行ではなくJupyter Notebookを用いたインタラクティブな利用が多くなることが見込まれたことと、多くのプロジェクトでDockerを用いた開発が進められていたため導入コストが低くなることが期待できたため、導入は見送られました。
メンバーごとにプロジェクトへ所属させ、ファイルのパーミッションを適切に限定する
複数人での利用は、kubernetesのPodと呼ばれるリソース単位でそれぞれ利用することで、他のメンバーへの影響を最小限にした上で開発を進めることができるようになります。ただ、全員が全てのプロジェクトのファイルにアクセスできるようでは、機密性の問題が発生してしまいます。そこで今回はLDAP(Lightweight Directory Access Protocol)を導入しメンバーの権限を一括管理することとしました。Kubernetesには元から権限管理の機能が備わっていますが、Kubernetesに組込まれたマシン以外でもLDAPを利用する想定があったためLDAPを採用しています。現在、学習基盤の利用における権限管理はLDAPの情報を用いて実施していますが、将来的にはKubernetesと各種認証プロトコルの統合も視野に入れています。
LDAPの構築にあたって、Kubernetesのリソース管理機能を有効活用するため、Deploymentという形式でLDAPのコンテナをデプロイしました。Deploymentで構築することで、Kubernetesクラスタ上において設定した数のPodが起動していることを保証できます。
GPUの利用
通常Kubernetesを導入する際には、kubeadmを利用する方法が一般的かと思いますが、そのまま利用しただけでは起動したPod内でGPUを認識できません。今回私たちは、こちらの記事を参考にさせていただき、Nvidia Docker2の導入を決めました。
Nvidia Driverをインストールした上で、nvidia-docker2を導入し、Dockerの起動設定を下記の通り変更し適用することで、Kubernetes上でGPUを認識できます。
{ |
高速なファイルの転送
LDAPと同様に、Kubernetesのリソース管理機能を活用するべく、DockerのプライベートレジストリについてもDeploymentで構築しました。プライベートレジストリとは、各自が作成したイメージを保存・バージョン管理することのできるストレージのようなものです。プライベートレジストリを用意することで、Kubernetesの各ノード上で各自がビルドしたコンテナイメージを利用できるようになります。
ただ、Dockerのイメージは物によってはサイズが大きくなってしまいます。今回のプライベートレジストリは、ファイルサーバ上に構築したNFSに保存するようにしていますが、ネットワークの転送速度には長い時間がかかる恐れがあります。
構築前のヒアリングでも要望として上がっていましたが、機械学習プロジェクトでは大規模なモデルや学習データを取り扱う機会が多い事もあり、大容量のファイル送信は必須でした。今回は通常のネットワーク用とは別にNICを各マシンに追加し、外部通信とは別に利用するネットワークを構築することで高速なデータ転送を実現しています。
CI/CDの実現
CI/CDとは継続的インテグレーション・継続的デプロイメントとして広く知られた手法になってきていますが、機械学習プロジェクトにおいても今まで以上に重要な技術です。機械学習プロジェクトでは、ただソースコードが動けば良いだけでなく、モデルの精度についても継続して評価する必要があります。
今回はGitLabとKubernetesを連携させ、各プロジェクトごとに利用できるCI環境を構築しています。Kubernetes上でHelmというパッケージ管理ツールを使いGitLab runnerを動かせるようにした上で、設定パラメータにGitLabの情報を入力することで連携できます。また、Kubernetes環境にMLflowのPodを立てCIの結果を逐一記録することで、継続的なモデル評価を実現できます。
5. まとめと今後の展望
長々と、かつまとまりの無い記事になってしまいましたが、MLOpsを進める中で感じたことは下記の2点です。
- データサイエンティストのメンバーと対話し実情を知るべき
- 画一的に技術・ルールを整備するのではなく、状況や案件に合わせて都度カスタマイズするべき
データサイエンティストとエンジニアは持つ知識や経験が異なり、片方が常識だと考えていることが一方ではそうではないことは多々あります。それは多様な職種の企業様と行うコンサルティングと同様に、それぞれの理解の擦り合わせを積極的に行うことと、自分の知らない分野に関する知識を学び、より良いモノを作るよう努力を続けるという歩み寄りの姿勢が重要であると感じました。
未だSAIG内で表面化している課題の全てには対応できていません。ディレクトリ構成に関する運用ルールを策定するにとどまっているJupyter Notebookのバージョン管理や、データの前処理と学習を一連の処理として扱うパイプラインツールの導入も今後挑戦したいと考えています。
引き続き、円滑な機械学習プロジェクト推進の一助となれるよう、MLOpsの導入に力を入れていきたいです。
また、MLOpsの導入に力を貸してくれるメンバーも募集していますので、興味のある方は是非、SAIGの門を叩いてみてください!