はじめに
こんにちは、Technology Innovation Group所属 DBチームの岩崎です。
テックブログにて記事を書くのは1年半ぶりです。(反省)あれからずっと設計~開発まで推進し、無事アプリリリースが完了しました。
このタイミングで改めてKVS関連のナレッジを還元できたらと思い筆を執りました。
1. データモデル設計の勘所
前回の記事でも書かせていただきましたが、KVSを採用するにあたって一番ポイントになるのがデータモデル設計です。
ここを外すと、開発で大いに苦しみます。場合によっては要件を満たせず再設計ORノックアウトなんてことにも繋がりかねません。
1-1. 更新要件を中心に設計するのがベター
KVSはキーアクセスしかできないのでデータ参照にフォーカスしたモデルを設計しがちです。
もちろんこのアプローチは全然悪くないのですが、どのようにデータを取得するかに意識が偏り実は更新要件が満たせていない・・・なんてことにならないように気を付ける必要があります。
KVSは分散処理でハイパフォーマンスを実現する代わりにトランザクション管理を犠牲にしています。そのため、データの整合性を担保した更新は苦手なためデータモデルを工夫する必要があります。
1-2. その更新は”部分更新”なのか? “全体更新”なのか?
アプリケーションからKVSに対してReadだけでなくWriteも発生する際は対象データの更新範囲を意識する必要があります。例えば、ログデータのように一度書き込んで以後更新が発生しないようなデータ特性であればKVSは適しており、データ整合性の保証も容易で扱いやすいです。
ただし、トランザクションデータで更新が発生する際は、**データ整合性をどこまで保証するか? **というのがデータモデルを考える上で非常に重要なポイントとなります。
Cassandraではデータをスキーマ定義してテーブル管理しているため、データ更新時はレコード全体ではなく特定のカラムに対して、UPDATE(部分更新)をかけることができます。
そのため、複数ユーザーがそれぞれ別のカラムに対して部分更新をかけるのであれば、更新対象が分離しているため、同時更新時もデータ整合性は担保できます。またRDBのように行単位でロックを取得しないため、同一キーに対する更新であってもロック待ちが発生せず高速に書き込み処理を行うことができます。
# 更新対象が分離していれば同時更新もOK。行ロックも取得されない。 |
このように複数ユーザーから同時更新がかかる要件がある場合は、更新対象が分離できるか?
また、**更新対象が重複時はあと勝ちが許容できるか? **というのを明確にする必要があります。
ただし、データモデルのネストが深くなるとUPDATE可能な範囲に制約が発生する点に注意です。
この制約を見落とした設計を行うと、部分更新できずに更新要件を満たせない! なんてことになります。
例えば、結合ができないという観点から親子関係を持ったデータモデルで考えてみます。
更新要件は同一カラムに対しての更新はあと勝ちで良いが、別カラムの更新は整合性を担保するとします。
-- ユーザー定義型(UDT) |
Cassandraではネストが深くなると(第三階層移行)frozenを使用しないと定義できません。
親のカラム「parent_XXX」はfrozenされていないので、部分更新をかけることが可能です。
-- frozenされていないカラムの部分更新は可能 |
親のカラム「children」の更新はMapのValueにあたるchild型がfrozenされているため、子のカラム「child_XXX」は部分更新ができず、子のモデル全体で更新を行う必要があります。
frozenされたカラムの部分更新をしようとすると、他の項目がnullになってしまいます。
-- frozenされたカラムの更新は全体更新になる |
このように本来child_col_1だけ更新したいはずなのにchild_col_2のデータも含めた全体更新にせざるを得ないため、ネストの深い項目に対する同時更新時のデータ整合性を保証できずに更新要件が満たせなくて詰んでしまう・・・なんてことになりかねません。
そのため、更新要件次第ではあえてテーブルを分離させてfrozenを避けるというのも案の1つです。
もちろん子テーブル参照時は親からキーを手繰る必要があるので参照性にはデメリットもあります。
CREATE TABLE child( |
1-3. パーティション検索も念頭に入れておく
一般的にKVSは単一キーによるプライマリーキーアクセスしかできないと思われがちです。
Cassandraではテーブル定義時にパーティションキーと呼ばれるデータの物理配置を管理するキーを定義します。このパーティションキー単位でデータをクラスタ化して管理しておりCQLではWHERE句にパーティションキーを指定してクラスタ単位でデータ操作を行うことができます。
例えば下記のように、パーティションキーを日付にしたテーブルを作成します。
-- PTキーがdateのテーブル |
このテーブルにデータを格納した時のイメージは下記になります。
| date | id | body |
|---|---|---|
| 2021-03-20 | 01 | 01-hoge |
| 02 | 02-hoge | |
| 03 | 03-hoge | |
| 2021-03-21 | 04 | 04-hoge |
| 05 | 05-hoge |
このように日付をパーティションキーにすることで1クエリで日付単位のデータアクセスが可能になるため、キーアクセスの連射が不要になります。
また、日単位でデータ削除なども可能になるのでパーテイション設計は重要になります。
SELECT * FROM test WHERE date = '2021-03-20' ; |
先述の親子関係のテーブルを分離する際も子テーブルに親IDをパーティションキーに設定することで、親ID指定するだけでキーアクセスの連射することなく取得できるようになります。
-- parent_idをパーティションキーに設定 |
この時childは下記のようなイメージでデータが格納されます。
| parent_id | child_id | child_col_1 | child_col_2 |
|---|---|---|---|
| p-01 | c-01 | aaa | aaa |
| c-02 | bbb | bbb | |
| c-03 | ccc | ccc | |
| p-02 | c-01 | ddd | ddd |
| c-02 | eee | eee |
親IDを指定するだけで子要素が一括で取得できるのでパーティションキーを適切に設計することで効率的なアクセスが可能になります。
SELECT * FROM child WHERE parent_id = 'p_02' ; |
ただし、パーティションキーを設計する際に気を付けるべき点があります。
理由は運用設計の勘所にて詳細説明しますが、1パーティションサイズが100MB以上にならないようにするというのが重要になります。
トランテーブルに対して年や月など粒度の大きな単位でパーティションキーを設計すると1パーテイションに大量のデータがクラスタ化されて100MBを超えてしまうということに陥りやすいので注意が必要です。
1-4. クラスタリングキーを利用してデータ格納時のソート順を制御する
先ほどパーテイションキー単位でクラスタ化するという話をしましたが、**データ格納時にクラスタ化されたデータのソート順(ASC/DESC)を指定できます。
通常、カラムはアルファベットの昇順でソートされますが例えばチャットのデータなどを一覧表示する際に最新日付順に表示したいなどソート条件が決まっている場合は、クラスタリングキーでソート順を指定することでデータ格納時に制御できます。
こうすることで、アプリケーション上でCassandraから取得したデータをソートしなおすなどの無駄なフェーズを省くことができるため非常に重要な設計になります。
クラスタリングキーのソート順はあとから変更できないので注意です。
CREATE TABLE chat( |
1-5. staticを利用したテーブル集約
staticカラムを利用してテーブル集約ができるケースがあります。
これに関しては前回の記事で詳細を説明しているので下記ご参考ください。
https://future-architect.github.io/articles/20190718/
2. トランザクション管理の勘所
一般的にKVSはトランザクション管理ができないと理解されていますが、Cassandraでは単一行に対してはCompare and Set(CAS)と呼ばれる軽量トランザクションを利用することでトランザクション管理を実現できます。
2-1. 単一行に対してはトランザクション管理可能
単一行に対してINSERT及びUPDATEクエリにIF句を利用することで、軽量トランザクションによる一意のデータ挿入や楽観ロック的な更新が可能になりデータ整合性を守るのに役立ちます。
INSERT INTO test(id, name) VALUES ('01') IF NOT EXISTS; |
データ整合性を保証できるのでつい軽量トランザクションを多用したくなりますが、軽量トランザクションはPAXOS合意と呼ばれるアルゴリズムで下記の4フェーズで実装されておりCASコーディネーター間で往復が発生し、非軽量トランザクションに比べて操作のレイテンシーが4倍に増加するとドキュメントで明文されてます。
https://docs.datastax.com/ja/dse/5.1/cql/cql/cql_using/useInsertLWT.html
1.準備/約束
2.読み取り/結果
3.提案/受諾
4.コミット/確認
また、行ロックを取得するということは同時更新時のパフォーマンスが著しく低下する可能性が高くなるので全ての処理を軽量トランザクションに寄せるのではなく、データ整合性を厳格に管理する必要がある処理に絞って利用するのがベターです。
ただし、私のプロジェクトでもID採番処理などでCASを採用するケースはあり、性能テストでは1CASあたり約50~100ms前後の処理時間をマークしていました。
アプリケーション特性にもよりますが、100ms台であれば許容される場面は多いと思うので多少の性能劣化はあれど、CASの利用を踏まえたモデル設計もありだと個人的には考えています。
2-2. 同一PTキーの更新であればバッチ処理時に原子性が保証される
Cassandraでは複数のDML文(SELECTを除く)を組み合わせてバッチ処理でリクエストを集約できます。
バッチ処理を利用することでクライアント-サーバー間のトラフィックを削減できるというメリットがありますが、**1つのパーティションをターゲットとするバッチ処理であればアトミック性(原子性)を担保できるというメリットもあり非常に便利です。
また、同一パーティションであれば先述した軽量トランザクションも利用可能です。
ただし、実行の順序性は保証されないという点には注意が必要です。
-- 同一パーティションキーに対する更新であれば原子性が保証される |
このバッチ処理で便利な点は同一パーティションキーという点にあります。
実は同一テーブルという制約はなく、同一パーティションキー(キーの中身が同じ)であれば、別テーブルであってもバッチ処理で原子性を担保した更新処理を実行できます。
例えば最新断面のみを管理する記事テーブルと記事の全リビジョンを管理する記事リビジョンテーブルを用意し、両者のテーブル構造は同じでパーティションキーも揃えておきます。
CREATE TABLE art( |
通常KVSでテーブル分離すると更新時のトランザクションが分かれるためエラー時に片方だけ更新されなかった、などのデータ不整合が発生する可能性が高くなります。
が、先述した同一パーティションキーに対するバッチ処理で更新を行えばテーブル分離しても両者のテーブルの原子性を担保した更新が可能になります。
BEGIN BATCH |
このようにリビジョンテーブルと分離ができると、アプリケーションからのデータアクセスが容易になる上にデータ整合性も担保しやすくなるので非常におすすめです。
また、バッチ処理の中に軽量トランザクション(CAS)を含めることもできます。
ただし、下記のように注意点もあります。
- バッチ処理内に複数パーティションに対する更新が含まれる際は原子性は保証されない(リクエストの集約にはなり、実行エラーにはならない)
- バッチ処理内のDMLの実行順序は保証されない(更新順序に依存させない。順不同で冪等にする必要がある)
- バッチ処理内で軽量トランザクションを利用する際は単一パーテイションのみ可能(複数パーテイション更新になる場合は実行エラー発生)
基本的にはメリットが多く、バッチ処理をうまく利用することでデータ整合性を保証しつつ性能面の向上も見込めるためおすすめです。
3. アプリケーション開発の勘所
私のPJではデータストアとして業務データを管理するdatastax(KVS)、全文検索機能としてElasticsearch、オンプレ構成だったのでアーカイブ用にDynamoDBを採用しており、複数のデータストアが混在していました。
アプリ開発者にデータストア層を意識させるのは非常に困難かつ、データ整合性を担保できないと考え、業務ロジックを実装するHandlerとデータの整合性を保証したCRUD機能を提供するPersister層に分離しました。
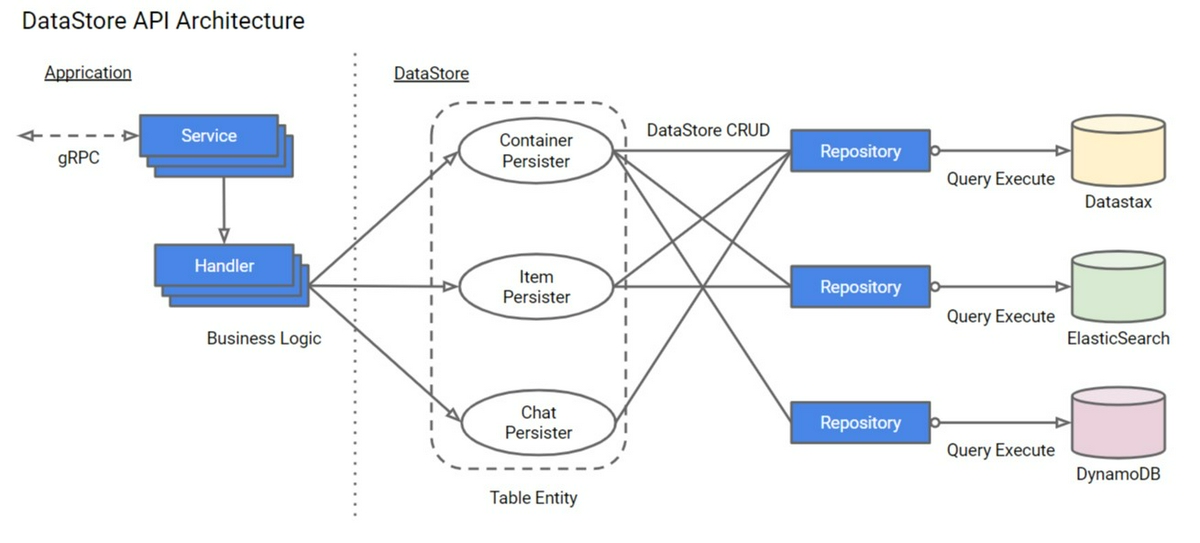
APIコールすると紐づくHandler(業務ロジック)が呼び出され、Handler内で発生するデータストアへのCRUDは全てPersisterクラスの共通メソッドを呼び出すことでデータストア層を隠蔽化しています。
3-1. gRPCモデルを利用したCRUD機能を提供
]
クライアント/サーバー間のAPI連携にはgRPCを採用しました。datastaxはCassandraベースの製品でデータアクセスはCassandraと同じCQLを利用します。
CQLはSQLライクで、従来のRDBアプリ開発者にも直感的に記述できるインタフェースです。とはいえ、コレクション型(Map,Set)の更新や軽量トランザクション(CAS)やバッチクエリなどCassandra特有のクエリもあり、少なからず学習コストがあります。
アプリ開発者がCQLを意識せずに実装できるようにするためPersisterレイヤーにCRUD及びCASなどの機能を持ったメソッドを共通実装して提供し、引数に対象エンティティに合わせたgRPCのモデルを渡せばモデルクラスから動的にCQLを組み立ててクエリ実行できるよう処理を隠蔽化しました。
Elasticserch、DynamoDBへのCRUDも同様にPersisterレイヤーで隠蔽化しています。私のqiitaでgRPCを用いた設計開発のノウハウを公開していますので是非参考頂けたらと思います。
https://qiita.com/yatarou/items/5f49b91ebb5229e2f0c1
3-2. 処理ごとにCONSISTENCY LEVELを意識する
CONSISTENCY LEVELとはCQLクエリ発行時の非軽量トランザクションを適切に処理するために
応答する必要があるレプリカ内のノードの数を決定します。
下記によく利用するCONSISTENCY LEVELとユースケースを整理してみました。
| Level | 範囲 | ユースケース |
|---|---|---|
| ALL | すべてのレプリカに問い合わせ、書き込みの完了をもって成功とする | CONCISTENCYレベルONEで読み取りを行ってもデータの整合性を担保したいとき。ALLは処理性能・可用性を犠牲にするため基本は推奨しない。 |
| QUORUM | 全てのデータセンターの全ノードの過半数の完了をもって成功とする。 | 過半数の成功で良いためALLに対して可用性は高い。が、「全てのデータセンター」の過半数なのでマルチセンターで両アクティブ構成でなければやりすぎ。 |
| LOCAL_QUORUM | コーディネーター(処理要求を出すノード)と同じデータセンター内の過半数の完了を待って成功とする。 | QUORUMに対してデータセンター間のレイテンシーを避けることができる。また、過半数の書き込みが整合性を保証するため、読み取り時も同一レベルを設定することで読み取り整合性も保証できる。基本的にはこのレベルで処理を行うことを推奨する。 |
| ONE | コーディネータ-から最も近いノードに処理が成功した時点で完了とする。 | 1ノードにしか処理を行わないのでONEで書き込まれたデータを参照するときはデータ整合性が保証されない可能性があるため、データ登録後にUPDATEをかけないようなデータに向いている。また、レイテンシーが最も低いのでハイトランザクションのread/writeには強いため性能を最重視する際は検討しても良い。書き込まれたデータはノード間で非同期でレプリカコピーが行われる。(ALL以外はコピー実施される) |
3-3. KVS-Elasticsearch間のデータ同期の考え方
KVSだけでは満たせない全文検索などの機能を利用するためにElasticsearchを採用しました。Persisterの重要な役割の1つにdatastax(KVS)とElasticsearchのデータ同期がありました。
まず、Elasticsearchの検索インデックスはKVSのテーブルと1対1の関係にしました。これはKVSが結合できないため複合インデックスにするとデータ保証しきれないためです。
次にポイントとなるのがデータ連携のタイミングです。
Elasticsearch上のデータは主管データではなく、あくまで検索補完の位置づけなので更新フローは「KVS->Elasticsearch」として必ずKVS側から更新するようにしました。KVSを更新せずにインデックスのみ更新するフローも原則禁止としています。更新順序に依存関係を持たせることでKVSの更新エラー時に検索インデックスだけ更新されてKVSにはデータがないのに検索はヒットするといった不整合を防ぐことができます。
また、KVSは1レコードサイズが肥大化しがちなのでKVS更新時に検索項目が含まれている時のみElasticsearchへのインデックス同期することを推奨します。こうすることでインデックスサイズの削減、同期不要時の処理性能向上が見込めます。更新順序制御や更新時のインデックス同期判定を業務ロジック上で判断させるのは困難なためPersisterのKVS更新メソッドの引数に渡すgRPCモデルのフィールドオプションにインデックス化する項目に対してカスタムオプション定義をしておき更新制御を行いました。
KVSからElasticsearchのデータ連携は基本的に同期処理で行っているのですが、Elasticsearchはインデクシングまでは同期処理で、連携されたデータを即時に検索できるようにするか、非同期で準リアルタイム(といっても数百msの世界)で検索できるようにするかをrefreshと呼ばれるオプションで制御できます。
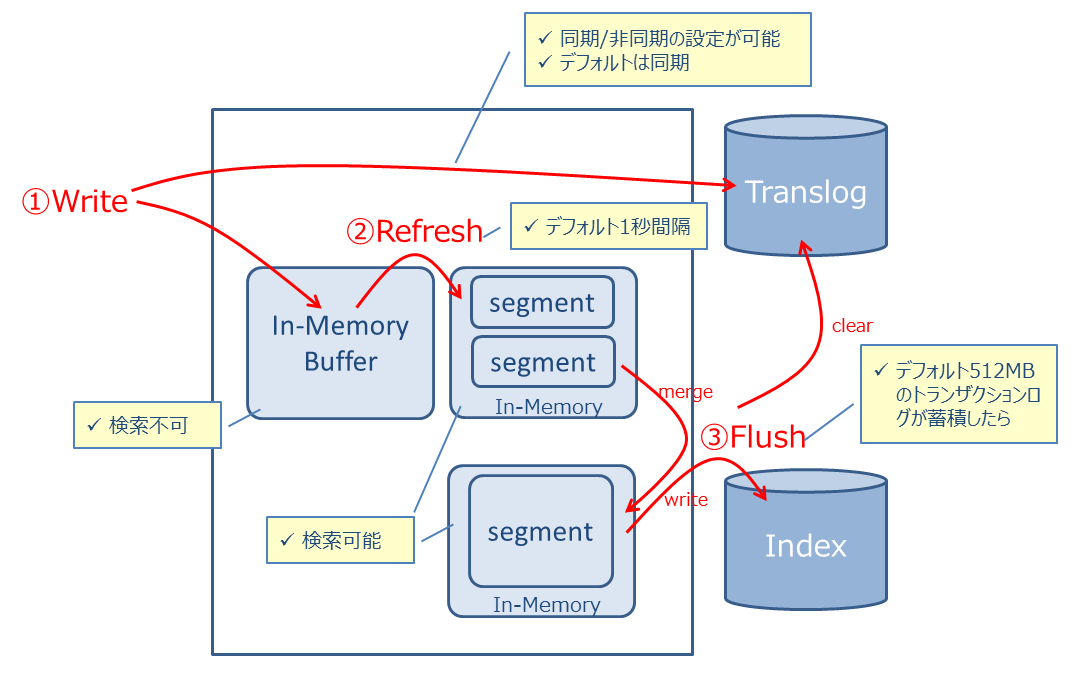
検索可能なSegment領域へのrefreshは基本的に非同期(false)を推奨します。
refreshを同期的(true)に行うと、KVSへの連射更新時やSegmentのmerge処理が走るとパフォーマンスに大きな影響を与えかねません。
Elasticsearchの公式ドキュメントでもrefresh同期は性能影響を与えると言及しています。refresh_intervalと呼ばれるパラメータでrefreshが定期実行されるのでそれに任せます。ただし、業務ロジック上でインデックス更新直後に即座に検索クエリを投げて対象の更新データを取得して後続処理を行うようなケースがある場合はrefresh_intervalで検索可能なインデックスへの書き出しが間に合わず検索にヒットしない、というケースが稀にあります。
そのため、refresh同期反映が必要な場合はPersisterから更新時にrefreshオプションを渡せるようにも工夫しました。
ちなみに更新時ではなくインデックスを指定して強制的にリフレッシュを実行するrefreshAPIがElasticsearchは提供していますが、このAPIはインデックス全体を対象としたrefresh処理を行うので性能影響があります。更新時のrefreshオプションなら対象レコードのみrefresh対象としてくれるのでこちらを利用することを強く勧めます。
3-4. 更新管理テーブルを用いたBCP同期
KVSはマルチデータセンターでクラスタ構成を容易にとることができるためKVSを採用する背景にBCP(事業継続計画:Business Continuity Plan)要件が含まれることが多々あると思われます。
しかし、Elasticsearchはマルチデータセンターでクラスタを組むことができず、KVSとのデータ整合性を担保したBCPデータ同期の仕組みを考える必要がありました。
現在では有償サブスクリプション(プラチナ)でクロスクラスタレプリケーション機能を提供しているそうですが、当時はベータ版の機能だったので採用を見送りました。
https://www.elastic.co/guide/en/elasticsearch/reference/6.7/ccr-getting-started.html
BCP要件上アクティブスタンバイ構成でリアルタイム同期の必要はなかったため、KVS側に更新管理テーブルを作成してスタンバイ側からPULL型の定期実行で同期対象の特定および対象レコードを抽出してElasticsearchに連携する仕組みを作りました。
更新管理テーブルはKVSにデータ登録・更新時に業務テーブルに書き込む前に対象レコードのPK、更新日付、BCP同期ステータスなどをまず更新管理テーブルに記録します。更新管理テーブルへの更新が完了したら、業務テーブル更新とインデックス同期を行います。
KVS上のデータはDRサイト側にもデータベースの機能で同期が図られているのでDRサイト側で定期的に更新管理テーブルをチェックしてBCP同期対象のPKを取得します。
更新管理テーブルはあくまでPKだけ管理しているので、仮にKVS側で更新管理テーブルの書き込みは成功して、業務テーブルへの書き込みが失敗していたとしても常に業務テーブルの最新データを取得してインデックスに連携するためデータ不整合は発生しません。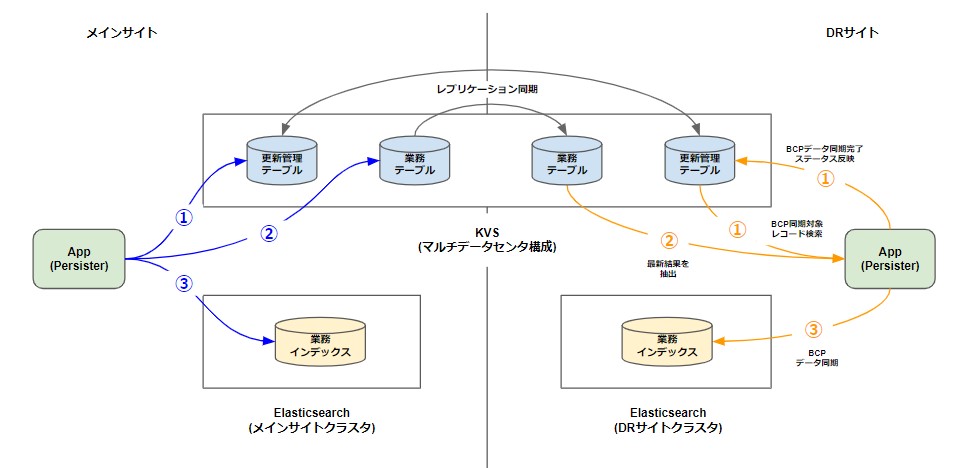
3-5. エラーハンドリング
基本的にエラー時はアプリケーション上でリトライさせず、ユーザー画面にエラー通知を返して画面操作のリトライを促しました。
一部、軽量トランザクションを利用したロック制御を実装しており、ロックフラグをみてステータス更新をかけるような排他制御がありました。
この処理はロック取得の軽量トランザクションで更新がかけられない時はwaitを挟み、アプリケーション上でリトライをかけるように制御しました。また、DatastaxのDriver上でリトライポリシーを設定することが可能なためReadTimeoutException、WriteTimeoutExceptionに関してはリトライポリシーに従ってリトライをかけていました。リトライポリシー設定例は下記参照ください。
https://docs.datastax.com/en/developer/java-driver/3.7/manual/retries/
4. 性能テスト/運用監視の勘所
4-1. Gatlingを利用した性能テスト
性能テストは負荷テストツールのGatlingを利用しました。
https://gatling.io/
テストシナリオはscala言語で記述し、Gatlingテストレポートはhtml形式で出力されます
例えば下記のようなシナリオを想定したサンプルコードは下記になります。(環境構築は割愛)
- 100TPS相当の負荷をかける
- 負荷は一定時間同等量をかけ続ける
- 実行するAPIのURLは動的に変化させる
package perf_test |
constantUsersPerSecは指定時間・ユーザ数でリクエストを投げ続けてくれます。
他にも便利な機能があるので公式ドキュメントを参考にしながら実装してみてください。
4-2. nodetoolコマンドでクラスタの性能を監視する
Cassandraではnodetoolユーティリティと呼ばれる、クラスタ操作/監視や性能レポート出力など運用機能を提供するコマンドラインがあります。
https://docs.datastax.com/ja/dse/5.1/dse-admin/datastax_enterprise/tools/nodetool/toolsAboutNodetool.html
色んな機能がありますが、運用でよく使うコマンドを中心に紹介していきます。
GC監視
gcstatsコマンドは、ガベージ・コレクション統計を出力します。
nodetool -u monitorRole gcstats |
Cassandraの性能劣化の原因でまず疑われるのがGCなので、上記コマンドの統計結果だけでなくjstatコマンドを利用して毎秒ファイル出力しログ監視を行うなどの仕組みも作って重点的に監視を行っていました。
性能監視
tablehistogramsコマンドで対象テーブルの過去15分間に発生したRead/Writeのレイテンシーに関する現在のパフォーマンス統計を表示します。
時間はマイクロ秒表記なので注意です。
nodetool -u monitorRole tablehistograms [キースペース] [テーブル名] |
また、proxyhistogramsコマンドでノード単位のレイテンシーを出力できます。
ノード間通信の読み取りと書き込みのレイテンシー値のパーセンタイル・ランクが含まれており、
このコマンドを使用して、処理の遅いノードに要求が届いているかどうかを確認します。
CAS Read/Write Latencyで軽量トランザクションのパフォーマンスもみることができます。
軽量トランザクションを利用する際に性能懸念がある際は確認することを推奨します。
nodetool -u monitorRole proxyhistograms |
4-3. kibanaを利用して処理全体の性能監視の仕組みを作る
nodetoolコマンドなどでKVSレイヤーの統計情報を取得できますが、KVSではRDBのように複雑なSQLが実行されるようなことがないため単一クエリの性能は基本的に問題ないというケースが多いです。
そのためKVSレイヤーのみに絞って性能監視してもボトルネックが掴めない場合が多いです。アプリ全体でどこがボトルネックになっているかを追えるようなロギングが重要になります。
私のPJではフロントでグローバルトランザクションIDを払い出してそれを取りまわしていたのでグローバルトランザクションID起点で性能監視が追えるように各レイヤーでロギングしました。各レイヤーのアプリログをElasticsearchに取り込み、kibanaでグローバルトランザクションIDで横断検索しボトルネック箇所を特定できるダッシュボードを作成してチューニングを実施しました。
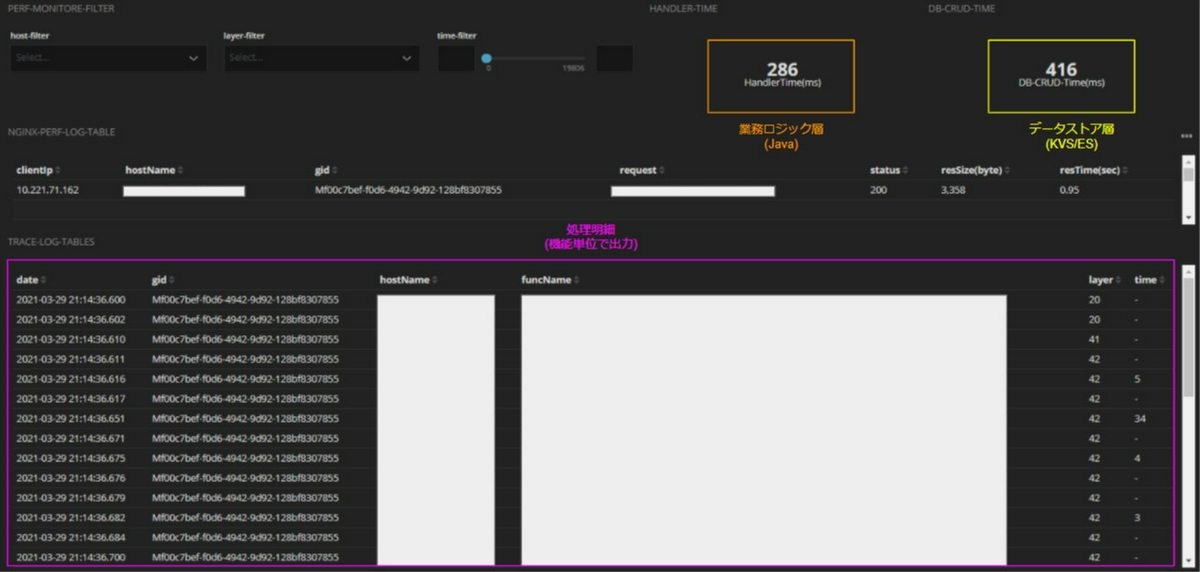
業務ロジック上で時間がかかっているのか、データストアへのCRUDで時間がかかっているのかを切り分けることで、チューニング対象の特定がグッとしやすくなります。
4-4. 1パーティションサイズが100MB以上にならないようにする
Cassandraはデータ書き込み時にCONCISTENCY LEVELに応じてノードの書き込み完了を保証します。
CONCISTENCY LEVELがALLでなければクラスタ内のノードがすべて書き込みが成功しているという保証ができないため、定期的にクラスタ内のノード間でデータの整合性を合わせるためにバリデーションとデータ同期が行われています。この仕組みを”nodetool repair”と呼びます。nodetool repairによる同期が完了しないと全ノードが同じデータを持つことが保証されませんがLOCAL_QUORUMで読み書きを行っていれば、仮に3ノード中1ノードが古いデータを持っていたとしてもデータ不整合は発生しないのでアプリケーション側に影響はありません。
しかし、削除データに関してはこの同期が完了していないと問題になるケースが存在します。
Cassandraでは削除データに対し、”tombstone”とよばれる論理削除フラグで管理を行っておりnodetool repair実行時にこのtombstoneも併せて同期を取ります。実際に物理削除されるタイミングはコンパクションと呼ばれるタイミングで行われるのですが仮にコンパクション実行時にtombstoneが連携されていないノードがあった場合、そのノードでは本来削除するべきデータがゾンビとして残ってしまう可能性があります。
ゾンビ状態でnodetool repairでデータ同期が行われると、削除したはずのデータが再度他のノードにデータ同期されて復活するという事象が発生してしまいます。この事象を避けるためにtombstone削除の猶予期間として各テーブルごとに”gc_grace_seconds”と呼ばれるパラメータでデフォルト864000秒(10日間)経過したデータを対象に削除を行います。つまり10日以内にnodetool repairでデータ同期を終わらせる必要があるということになります。
Datastaxではgc_grace_secondsで設定した値の期間内に同期が完了するようにrepaireタスクをスケジューリングして自動実行してくれる”nodesync”とよばれるサービスが動いています。
運用ではnodesyncによって10日以内にデータ同期が完了しているかを監視することが大切です。nodesyncによる同期状況はDatastaxが提供する専用のダッシュボードがあるのでそれを利用します。このnodesyncは自動でスケジュールしてくれるので非常に便利な機能ですが、データを積んでテストしていく中である日突然CPUが一定間隔で高騰し続ける事象が発生しました。その原因がパーティションサイズに大きく関係していたのです。
nodesyncの実行単位は200MBのセグメントと呼ばれる領域にパーティションデータを乗せてバリデーションを行うのですが1パーティションが1GBなど200MBを超えている場合はパーティション内のデータを分割できず、1GBそのままセグメント領域に展開してしまうため1コアあたりの占有時間が顕著に長くなり、1GBを超えるような巨大パーティションが複数存在するとCPUリソースを全体を食いつぶすというのが原因でした。
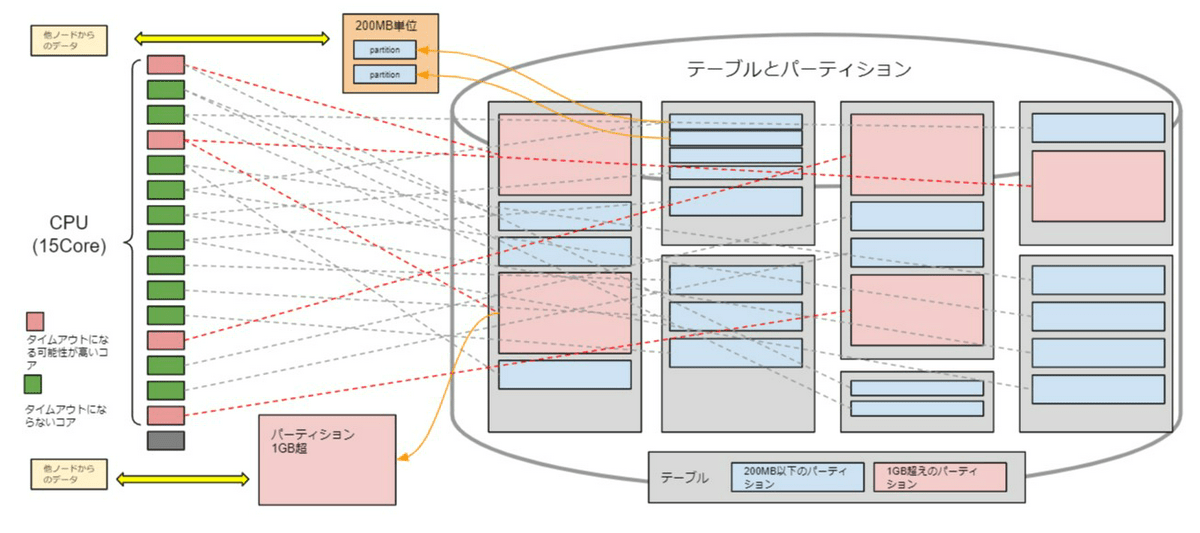
そのためパーティションサイズが1GBを超えるテーブルは100MBに収まるよう設計を見直しました。サイズが肥大化しがちなパーテイションの主は日付をキーにしている場合が多いです。定常業務の更新量では1GBを超えなくても、移行などでイレギュラー要素で想定以上の更新量が発生する可能性もあるため、月や日などの単位ではなく日時分などでパーティションの粒度を細かくするもしくは、日付+分散キーにしてコンポジット化するなど検討しました。
テーブル作成後のパーティションキー変更は出来ないのでデータモデル設計時には1パーティションサイズが100MBを越さないようなキー設計になっているかを意識してください。また、運用開始後もパーティションが想定外に肥大化していないかなどを監視すると事前に事故を防げる可能性が高くなるので重要です。
さいごに
KVSと二年間設計から開発まで携わる中で一番苦労したのは「情報収集」でした。
Cassandraをエンタープライズ領域で採用した事例は、日本ではまだ少なく参考文献やネット上の情報も少ないため設計の勘所や運用ノウハウがなくトライ&エラーの連続でした。
私は「同じ山を同じ苦労で登る必要は絶対にない」という考えでナレッジは隠さずオープンにしていくべきと考え本稿の執筆に至りました。
伝えたいことを長々と書いてしまい、まとまりのない記事になってしまったかもですが、本稿がKVSを採用したいと思っている方に少しでも役立てば幸いです。