こんにちは。TIG DXユニットの村上です。
私は大学時代から深層強化学習の研究をしていますが、分野的にほとんど実世界のデータを扱うことがありませんでした。そんな私ですが、実務で実世界データの分析を行う機会があり、その違いに多くの学びがありました。
実世界データのデータ分析を行った結果見えてきた、実世界データの特徴と欠損値や不正データの処理について解説しようと思います。
簡易的ですがソースコードも示していますので、参考になれば幸いです。
実世界データとは

内容に入る前に、本記事での実世界データの定義を行っておきます。ここでは以下2点を満たすものを実世界データと呼ぶことにします。
- もともとはアナログデータである
- データ品質を高める処理が行われていない生のデータ
例えば身近なものだと、温度計や湿度計から取得されたデータは実世界データとなります。これらに欠損値補完 1などのデータ品質を高める処理を施した後は実世界データと呼ばないことにします。
また、機械学習用のデータセットや、システムのモニタリングデータなどは実世界データではありません。
実世界データの品質
実世界データのデータ品質は基本的に悪いです。欠損値が含まれていたり、不正なデータが存在するのが当たり前です。主な理由は物理的、人間の意志的な影響を受けるからです。これらの作用により、主に以下2ケースのデータ品質悪化が起こります。
これらの発生原因と対処法について解説します。
(1)欠損値が発生する
例えば、データの発生源であるIoTデバイスが屋外に設置されている場合、気象の影響を受けます。台風の時に固いものが飛んできてIoTデバイスに直撃、データを送信できなくなるなんてことも有り得ます。また、単純に電波不良などでデータがサーバに到達しなかったという状況も十分あり得ます。
このように挙げたらきりがありませんが、実世界ではデータがが発生したにも関わらずそれが取得できないことがよくあります。
欠損値処理
欠損値の処理に関しては、そのデータを使ってどのような分析を行うかで適切な処理の仕方が変わってきます。ここでは様々な処理方法とそのユースケースを解説します。
欠損値を削除する
欠損値が無視できるものであれば、削除してしまうのが手っ取り早いです。ではどのような時に無視しても良いのかですが、以下のケースがそれにあたります。
- 後続のデータ分析で利用しない
- データ数が減っても問題ない
1番は分りやすいと思いますが、2番は要注意です。極端な例ではありますが、以下のような天気と気温のデータがあるとします。
見ての通り、データの発生源である温度計は雨が降ると高確率でデータを取得できない残念な仕様になっていたとします。
このような温度計から得られたデータに対して欠損値削除を行い、気温から天気を予測するモデルを構築するとしたらどうなるでしょうか? おそらくそのモデルの予測結果は晴れか曇りのみになります。雨のデータがほとんど存在しないので、とりあえず晴れか曇りと予測しておけば正答率は高くなるということです。このように、データ数が減ること自体が問題になるケースが存在します。
以上を踏まえて、欠損値を削除しても問題ない場合はpandasを用いて簡単に削除できます。
例として、以下のデータに対して欠損値削除を行います。
a |
- 全ての項目が欠損値の場合にその行を削除
a.dropna(how='all') |
- 1つでも欠損値があればその行を削除
a.dropna(how='any') |
特定の値で補完する
欠損値が削除できない場合、何らかの値で補完します。どのような値で補完するかはそのデータに対してどのような分析を行うかに依存するため、目的をよく考えて補完する値を選ぶ必要があります。補完する値の候補と主なユースケースは以下です。
- 固定値:その項目に表れる値があらかじめ決まっている場合
- 平均値:その項目の値の分散が小さい場合
- 中央値:その項目の値の分散が大きい場合
例えば平均値による補完を行う場合は次のようになります。
b |
一定のアルゴリズムに従って補完する
欠損値が一定のアルゴリズムに従って推定できる場合、以下の補完方法が有効です。
- 線形補完:前後のデータ間の中間の値で補完
- スプライン補完:スプライン曲線を用いて値を推定
例えば線形補完をする場合は以下のようになります。今回は分りやすいようにmethodを明示的に指定していますが、デフォルトでlinearなので、線形補完する場合はmethodの指定は省略可能です。
b |
これら以外にも様々な補完アルゴリズムが存在します。いずれもpandasで簡単に行うことができるので、公式ドキュメントを参考にしてみてください。
(2)不正なデータが混入する
このケースはデータの生成過程で人間による入力が存在する場合、容易に発生し得るものです。また、データの生成過程に人間が介入しないとしても、何らかの事情でデータを手動で作成して差し込む場合もあります。
このケースの厄介な点は、それが正しいデータなのか、不正なデータなのかの判断が難しいことです。理論上有り得ないデータであればバリデーションチェックを行うことで正確に判断できるのですが、そうでない場合は不正なデータであることに気づくことが困難です。仮に怪しいデータを発見したとしても、それが不正なデータである裏付けを取るためには、そのデータの生成過程を精査する必要があり、多くの手間がかかります。
不正データの検出方法
次に不正なデータの検出方法を説明します。以下のフローチャートに従ってデータをチェックするのが効率的です。
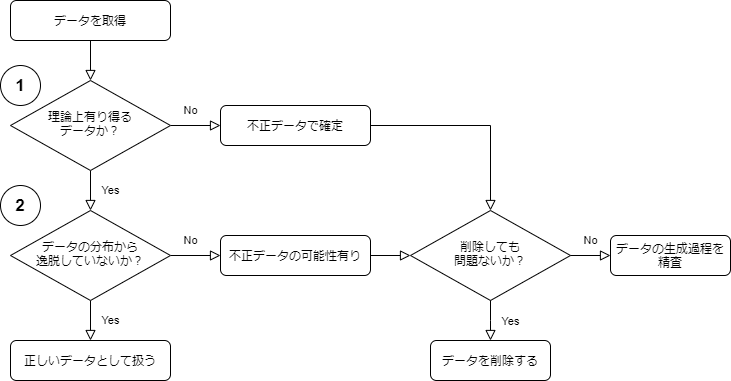
(1)番、(2)番について詳しく見ていきます。
(1)理論上有り得るデータかチェック(バリデーションチェック)
この段階では確実に不正であるデータを検出します。そのために、まずは正しいデータとはどのようなデータかをしっかりと定義する必要があります。この定義に間違いがあると、本当は正しいデータでも不正なデータとして検出されてしまう可能性があります。さらに、そのデータの発生源に対して何らかのシステム的、人間の意思決定的な側面から変更が加わる場合、同時に正しいデータの定義にも変更が必要な可能性があります。
従って、正しいデータの定義は一度決めたらそれで終了ではなく、適時変更が入ることを前提とするのがベターです。
次にバリデーションチェックのやり方ですが、これはpandera 2というpandasの拡張ライブラリを使うのがおすすめです。以下のように正しいデータの値域などを定義し、定義を満たさないものを検出できます。
以下はpandera公式ドキュメントからの引用です。
import pandas as pd |
バリデーションチェックの実行結果は次のようになります。
Traceback (most recent call last): |
(2)データの分布から逸脱していないかチェック
(1)番で弾かれなかったデータは必ず正しいデータという訳ではありません。理論上有り得るデータだが、入力ミスなどで真のデータと少し異なってしまうケースもあります。
このような、バリデーションチェックで検出できなかったデータから不正データを見つけるのはものによりますが、一般的には難しいと思います。ここではデータの分布という観点から、不正データの検出手法を解説します。
データをソートして検出
一番簡単な方法として、データを昇順や降順に並べ替えて、明らかに他のデータの値から逸脱しているものを検出するというものがあります。Excelでも簡単に行うことができるため、まずはこの方法から入ると良いかもしれません。
この手法はお手軽に行うことができる一方で、統計学的妥当性はありません。本質的には人間の感覚による判断になっているため、注意が必要です。
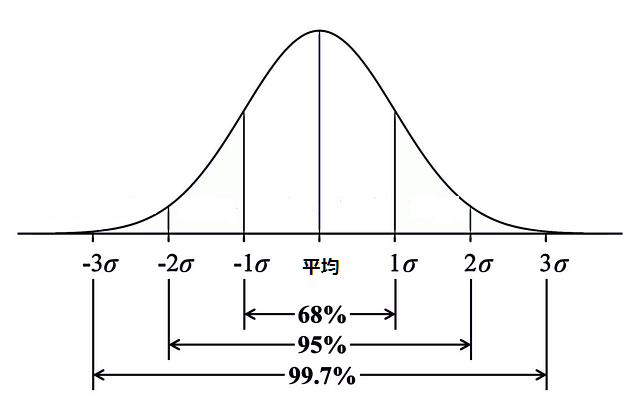
正規分布による外れ値検出
データが正規分布 3に従う場合、この手法が有効です。正規分布では
引用:https://ai-trend.jp/basic-study/normal-distribution/normal-distribution/
従って、これらを逸脱したデータを不正データの可能性有りとみなすのは、一定の統計学的妥当性があります。
実装例として、10000のデータが外れ値(不正データ)の想定です。
df |
10番目のデータがTrueになり、外れ値(不正データ)が検出できています。
不正データの再発防止
不正データを検出し、それらに対して削除などの対応を行った場合、それで終わりではまた再発する可能性があります。
例えば、不正データの発生原因が人間の介入によるものであった場合、人間が介入する割合を最小限に抑えるようシステム化を進める、人間が介入した際はそのデータのチェックを2人以上で行うなど、人間の作業フローを交えて不正データが発生しない仕組み作りを行う必要があります。
また、不正データの発生原因がシステムの故障によるものである場合、そのシステムを監視し、異常が検知された場合はその期間のデータを別の場所に隔離するなどの対応が必要になると思います。
このように、不正データを検知した際は、恒久、暫定的な再発防止策を早急に考える必要があります。
まとめ
今回は実世界データの品質が悪いことと、その対処法について解説しました。
これからの時代は増々データの品質が重視されると思いますので、引き続きデータに対する知識を深めていきたいと思います!
最後まで読んでくださり、ありがとうございました!