概要 AWS Glueの環境構築は過去の記事にあるのですが、公式のDockerイメージが案内されているので改めて、構築してみます。
なお、Glueの公式イメージでもJupyter Notebookは利用できるのですが、使い勝手を考慮し、Jupyterlabに差し替えています。
手順
Dockerfile作成 docker-compose.yml作成 動作確認
Dockerfile PySparkのオプションを設定しつつ、gluepysparkを実行していますが、gluepysparkがPySparkのwrapperになっているため、こちらの設定で問題なく動作しています。
Dockerfile FROM amazon/aws-glue-libs:glue_libs_1.0.0 _image_01RUN pip install jupyterlab COPY jupyter_start.sh /home/jupyter RUN chmod 775 /home/jupyter/jupyter_start.sh ENV PATH $PATH:/home/aws-glue-libs/bin/:/usr/share/maven/bin:${SPARK_HOME}/bin/ENV PYTHONPATH $PYTHONPATH:/home/jupyter/jupyter_default_dirENV PYSPARK_DRIVER_PYTHON jupyterENV PYSPARK_DRIVER_PYTHON_OPTS ' lab --allow-root --NotebookApp.token="" --NotebookApp.password="" --no-browser --ip=0.0.0.0' RUN mkdir ~/.aws COPY aws/config /root/.aws RUN chmod 600 ~/.aws/config COPY aws/credentials /root/.aws RUN chmod 600 ~/.aws/credentials
Dockerfileでコピーしているファイルです。
jupyter_start.sh # !/bin/bash /home/aws-glue-libs/bin/gluepyspark
.aws/config [default] region = ap-northeast-1 output = json
.aws/credentials [default] aws_access_key_id = xxx aws_secret_access_key = xxx
docker-compose.yml line10 で、jupyterlabのdefaultのWorkspaceにlocalをマウントしています。
docker-compsoe.yml version: '3.5' services: glue.dev.summary: container_name: glue.dev build: context: ./ dockerfile: ./Dockerfile volumes: - ./:/home/jupyter/jupyter_default_dir environment: - AWS_DEFAULT_REGION=ap-northeast-1 - AWS_DEFAULT_OUTPUT=json - AWS_ACCESS_KEY_ID=xxx - AWS_SECRET_ACCESS_KEY=xxx ports: - 8888 :8888 - 4040 :4040 networks: - glue.dev.network command: /home/jupyter/jupyter_start.sh glue.dev.s3.local: image: localstack/localstack:0.12.8 environment: - SERVICES=s3 - AWS_DEFAULT_REGION=ap-northeast-1 - AWS_DEFAULT_OUTPUT=json - AWS_ACCESS_KEY_ID=xxx - AWS_SECRET_ACCESS_KEY=xxx networks: - glue.dev.network networks: glue.dev.network: name: glue.dev.network
Docker 起動 docker-compose up --build
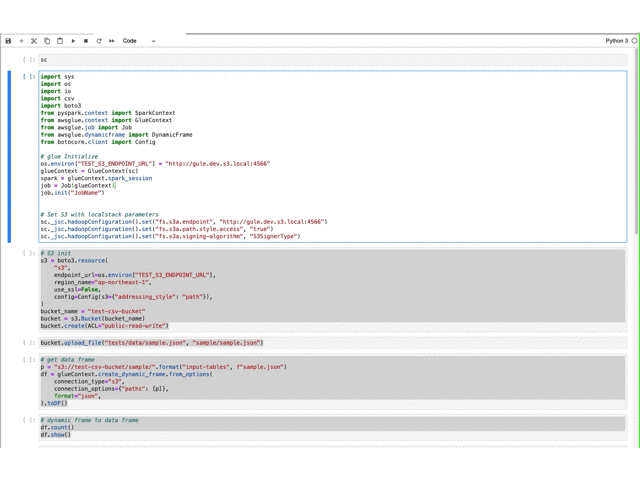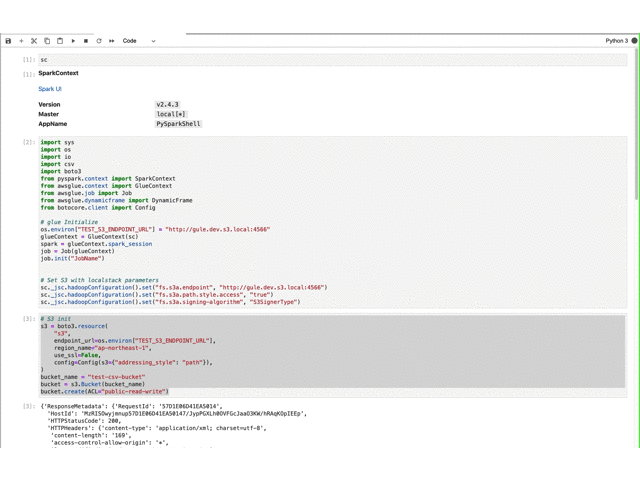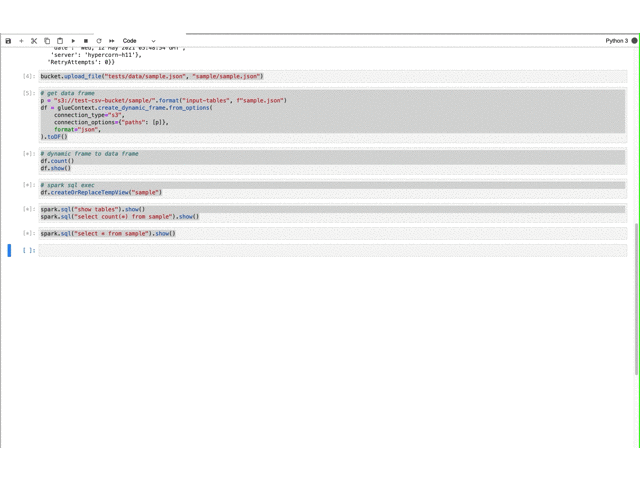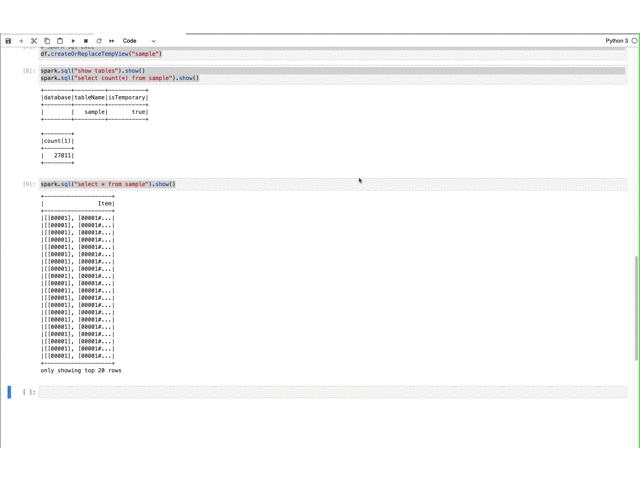
動作確認(準備) Glue/localstack(s3)を初期化し、dynamic frameで取り込んだファイルをdata frameに変換して、spark sqlを実行します。
import sysimport osimport ioimport csvimport boto3from pyspark.context import SparkContextfrom awsglue.context import GlueContextfrom awsglue.job import Jobfrom awsglue.dynamicframe import DynamicFramefrom botocore.client import Configos.environ["TEST_S3_ENDPOINT_URL" ] = "http://gule.dev.s3.local:4566" glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init("JobName" ) sc._jsc.hadoopConfiguration().set ("fs.s3a.endpoint" , "http://gule.dev.s3.local:4566" ) sc._jsc.hadoopConfiguration().set ("fs.s3a.path.style.access" , "true" ) sc._jsc.hadoopConfiguration().set ("fs.s3a.signing-algorithm" , "S3SignerType" ) s3 = boto3.resource( "s3" , endpoint_url=os.environ["TEST_S3_ENDPOINT_URL" ], region_name="ap-northeast-1" , use_ssl=False , config=Config(s3={"addressing_style" : "path" }), ) bucket_name = "test-csv-bucket" bucket = s3.Bucket(bucket_name) bucket.create(ACL="public-read-write" ) bucket.upload_file("tests/data/sample.json" , "sample/sample.json" ) p = "s3://test-csv-bucket/sample/" .format ("input-tables" , f"sample.json" ) df = glueContext.create_dynamic_frame.from_options( connection_type="s3" , connection_options={"paths" : [p]}, format ="json" , ).toDF() df.count() df.show() df.createOrReplaceTempView("sample" ) spark.sql("show tables" ).show() spark.sql("select count(*) from sample" ).show() spark.sql("select * from sample" ).show()
動作確認 ブラウザより、http://localhost:8888 を実装し、jupyterlabで動かします。
docker-compose.yml でマウントしたlocalストレージにtests/data/sample.jsonを用意して、実行してみます。
所感 ローカルでAWSに依存せず、GlueのAPIをインタラクティブに確認できるので、開発効率としては良いのではないでしょうか。