はじめに
TIG DXユニット1の真野です。Serverless連載2021の2日目です。
AWSで一度Lambdaを利用すると、その利便性から徐々に利用範囲が広がっていくことがよく観測されます。一度だけならと一度手を出すと、いつの間にかLambda以外で動かすことによるイベント連携の手間や、キャパシティプランニング、CI/CDパイプライン構築と運用監視の手間など、フルマネージド及び周辺システムのエコシステムの恩恵を得られなくてイライラする事も、身体に耐性がついてつい利用量が増えていくこともしばしばです(例のサイクルの画像は割愛)。
本記事ではAWS Lambdaでのバッチ処理について検討します。
AWS Lambdaとバッチ処理との相性
そんなAWS Lambdaですが2021.06.01時点では実行時間に制約があり15分です。過去、5分から15分にアップデートされた経緯がありますが、今後も何かしらの制約は残るでしょう。
そのため、AWS Lambdaのサービス単体でバッチ処理を行うのは難しく、他のサービスあるいは、他のサービスと組み合わせてバッチ処理を実現することが多いです。
よく見るのは以下3つでしょうか。
- ECSで処理
- AWS Batchで処理
- Step FunctionsとLambdaを組み合わせ
3つ目のStep Functionsは過去にまとめたことがあります。
今回はLambda中毒者らしく、1のECSや2のAWS Batchに頼らず、3のStep Functionsでもなく、LambdaとKinesisでバッチ処理を実現しようと思います。
Scatter(Fanout)パターン
Enterprise Integration Patternで分散・集約するパターンをScatter-Gatherパターンと呼びますが、今回はこちらの分散する部分のみを利用します。GatherなしのScatterパターンとはあまり聞かないので、Fanoutパターンが正しいのかもです。タイトルでは15分の壁を超えてとありますが、個別のLambdaでその壁は超えられないので、複数のLambdaを並列で実行させることで、それら処理時間の合計で仮想的に超えることにします。
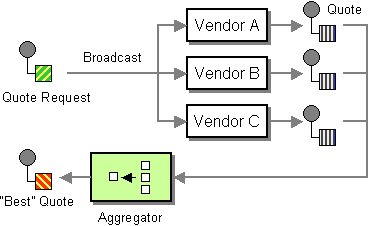
https://www.enterpriseintegrationpatterns.com/patterns/messaging/BroadcastAggregate.html
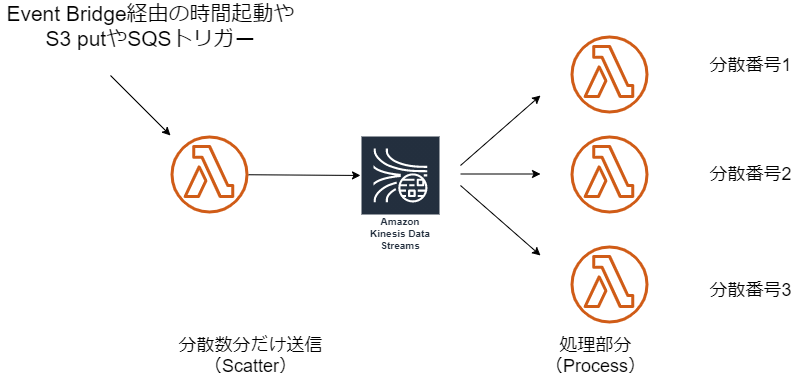
何かしらの入力ソースを元に、Lambdaで分散数だけKinesisにジョブを示すメッセージを送信。後続のLambdaで処理を行う構成にします。最初のLambdaがScatterと呼ばれる分散の開始部分です。
Gatherについては、DynamoDBのIncrement an Atomic Counterなどを利用しつつ実装するのかなと思います。同じ設計で実装するのであれば下記のような構成になるかなと思います。
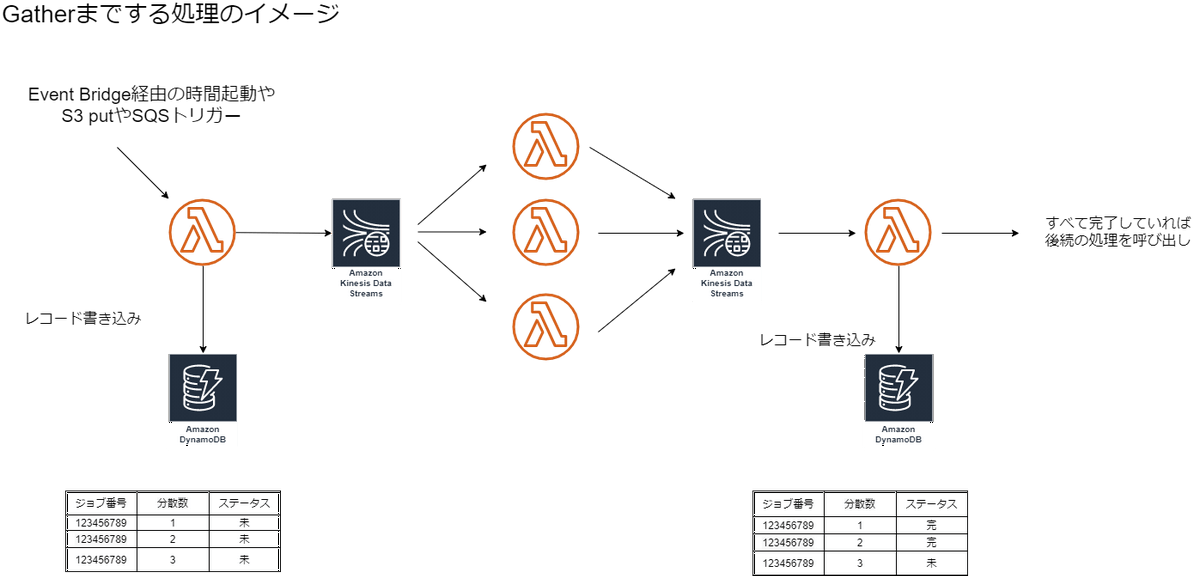
ただ、現実的にはスクラッチでGatherの作り込みを行うのではなく、Step FunctionsやManaged Workflows for Apache Airflowを利用することが大半だと思いますので、本記事では細かい設計・実装について触れていきません。
実装
バッチ処理対象のデータはDynamoDBにあることにします。あるテーブルをフルスキャンしてそのデータを駆動にして何かしら処理を加えると仮定します。
コードはこちらにあげていますので、適時参照ください。
Kinesis Data Streamに連携するペイロード
Jobという名前のStructの形式で連携します。Totalに分散トータル数、Segに今の分散番号を指定する仕様にします。
type Job struct { |
また、処理対象のDynamoDBには7000件弱のデータと登録しました。
Scatter
最初に処理対象のDynamoDBテーブルの件数を取得し、一定のしきい値単位になるように分散数を計算します。
var db = dynamodb.New(session.Must(session.NewSession())) |
db.ScanWithContext でテーブル件数を取得し、今回はしきい値を1000で分散トータル数を導出しています。
あとは、その数だけKinesis Data StreamにJobを送信します。
動かしてみると、以下のような結果がでると、無事KinesisにメッセージをPutできています。
START RequestId: 9469393a-eba9-4a21-9e98-8a3fc7f2a3f5 Version: $LATEST |
並列処理部分
次は、Kinesisのメッセージトリガーで起動するLambdaです。分散処理で行うメインの処理を実装する部分です。
今回は、 executeBizLogic の中身では単純に指定された件数のカウントを取る内容にしています。
func main() { |
動かしてみると以下のようなログが出る想定です。
2021-06-01T12:45:46.143+09:00 START RequestId: d44ecc4c-433c-481b-9051-435280c81900 Version: $LATEST |
最初のLambdaでKinesisに呼び出した分だけ、後続のLambdaが起動していることがわかると思います。
この実装の使い所
ジョブの依存関係が多くない場合で、かつECSやAWS Batchを導入せずカジュアルに分散実行したい時に試せるかと思います。
また、今回の例としては分散トータル数+分散番号の処理モデルですが、処理対象のデータモデル次第では、ユーザIDの範囲をしていしたり、良い感じのカーディナリティになる業務コードを指定しても良いかなと思います。支社CDとか営業エリアCDとかです。
リランについて
後続のLambdaのある分散番号だけ障害が発生し、リカバリが必要になった場合の対応について説明します。
今回の実装では作り込んでいないんですが、例えばエラージョブキューを格納するDead Letter Queueを用意するのが一手です。ちょっとツールで利用する用途であれば、連携された連携情報を awscli で直接Kinesisにputするのも一手だと思います
処理データの一貫性
実行するLambdaが分割される関係上、利用するのがPostgreSQLのようなRDBであっても、バッチ処理全体の処理結果の一貫性を保つことはできません。そのため分散処理単位で登録してよいかが利用する上での大前提だと思います。
実用上の話
この手の分散処理を1日に複数回実行し、かつある分散処理番号のみ失敗する場合を考慮すると、システム運用上の負荷が高まります。
そのため、実用に耐えうるためにはScatterのLambdaの起動のたびに一意な実行IDを取得し、それをキーに管理テーブルを用意することが多いと思います。それぞれが成功・失敗・処理中などのステータスを持つと役立つことが多いです。それぞれの処理件数や処理時間を格納すると嬉しいこともおおいでしょう。
一方でそこまでやるのであれば、Managed Workflows for Apache Airflowといったワークフローエンジンの導入も検討したほうが良いかもしれません。
また、分散しなくてもAWS BatchやECSで15分の制約を持たないサービスを選定したほうが良い場面は多分にあるので、程々に利用しましょう。
インフラ上の注意
並列処理Lambdaですが、Kinesisトリガーのバッチサイズは 1 が推奨です。これが10などにすると今回だとタイミングによっては1つのLambdaですべてメッセージを処理してしまう可能性があるからです。
また、 シャードあたりの同時バッチ で1シャードあたりの同時起動数を制御できます。デフォルトはおそらく1です。現状は1シャードあたり最大10までです。Kinesis Data Streamをジョブキューとして利用すると、だいたいシャードは1なので通常は同時起動数の制約がここで決まります。
通常は10並列で十分かと思いますが、もし上げたい場合はシャードを増やす対応です。多少費用が増えますが通常は誤差の範囲かと思います。
最後に
AWS Lambda実行時間15分の壁は、当然ハードリミットなのでそれ単体では超えられないですが、Kinesis Data Streamsと組み合わせて、仮想的にコンピューティング時間の合計で15分を越えようという記事でした。
実用上はいくつか壁があるので、用法用量を守り正しく参考にしていただければ幸いです。
次は伊藤真彦さんのAWS LambdaにおけるGo Contextの取り扱いです。
- 1.Technology Innovation Group(TIG)は、「最先端、且つ先進的なテクノロジーのプロフェッショナル集団」「プロジェクト品質と生産性の向上」「自社サービス事業の立ち上げ」を主なミッションとする、技術部隊です。DXユニットとはデジタルトランスフォーメーションを推進するチームで、IoTやらMaaSなどのテクノロジーカットでビジネス転換を行います。 ↩