はじめに
フューチャー夏の自由研究2021の9回目です。こんにちは、TIG DXユニットの西田と申します。
業務で GCP のインフラの設計/構築/運用を担当しております。私が感じている『GCP の特徴』というと、Gartner の Magic Quadrant などでも毎回紹介されているデータ分析領域だと思っています。
そのため今回は、
- Google社が買収したLookerという技術の簡単な紹介
- そして、それを使うとなった場合、何が必要になるか?
- Looker を採用するメリットに関しては本記事では特に触れません。
- 経営層から、使う事が決定された前提での話になっています。
という事を考察してみます。
本記事はあくまでも自由研究であり、私自身は Looker の運用経験はない中での私の主観がメインです。そこは最初に申し上げておきますが、ご容赦ください🙇
Looker とは?
概略
Gartner の アナリティクス&BIプラットフォーム領域の Magic Quadrant 2021 としては CHALLENGERS。まだLEADERS ではないです
内容としては最新 かつ 網羅的な概略に関しては公式サイトなどを見るのが一番良いですが、一旦アーキ面にフォーカスします。
以下の記事が参考になります。
- https://ja.looker.com/platform/overview
- https://marketing.itmedia.co.jp/mm/articles/1907/16/news054.html
要約すると、ポイントは以下です。
- 前提
- データを分析するためのツール。書き込みやデータの管理などは主目的ではない。
- データウェアハウスにて、正確なデータが一元管理されている前提。
- データがサイロ化・分散していない事が導入の前提条件
- 特徴
- データを保管する層と、データを閲覧する層の間にそれらを管理する層を設ける。
- データに対する参照権限やデータの解釈を統一的に管理
- データガバナンス が他の製品にはない特徴
- 通常のBIとは異なり、かなり大きな規模(=会社全体)で統制を効かせる事が出来ます。
- データを保管する層と、データを閲覧する層の間にそれらを管理する層を設ける。
要するに、データガバナンス がLookerの大きな特徴です。
そのため、それをきちんと運営する事/できる事がLookerを上手に使うことになりますね。(できないなら、Lookerを使わずに、他を使った方が良いかもしれません)
データガバナンスとは?
データガバナンスという言葉だけではあまりピンと来ませんよね。
実装を交えつつ、説明してきます。
実装のSample
こちら を例に解説します。
Model を定義する
order_database というデータウェアハウスとすでに接続している前提です。
中身は Bigquery でも snowflake でもOKです。
その中に orders と customers というテーブルがあり、それを join したテーブルを定義しています。
connection: order_database |
値などを定義
上記で作成したテーブルの中で参照する事が出来る値を定義していきます。
- dimension : DB に入っている値を基本はそのままの形で定義
- measure : 何かしらの集計結果を定義
view: orders { |
上記を閲覧
上記で定義した値を閲覧します(いい画像がなかったので手元の環境です)
左側のペインで項目を選択して実行を押すと表形式で表示されます。これが基本です。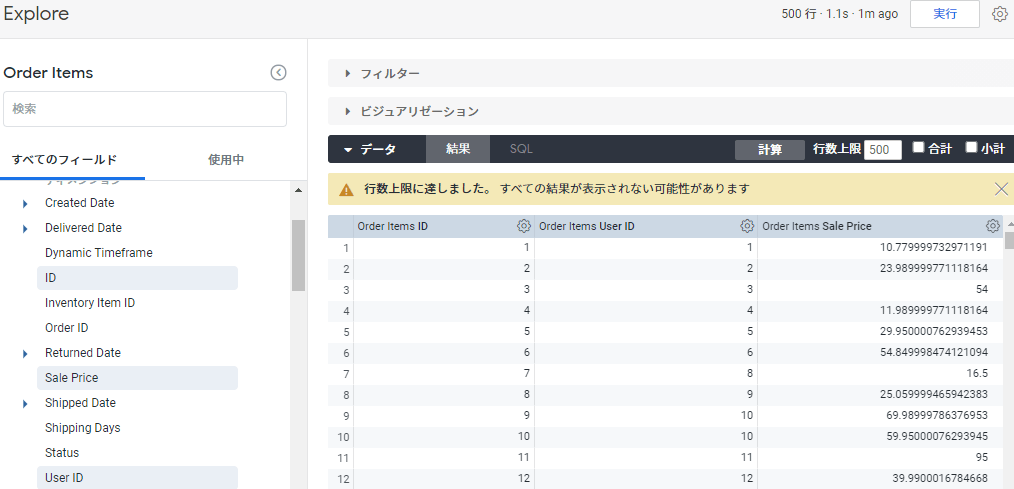
今度は measure の方です。
例えば、status 毎の件数をカウントしたい場合は、その2つを選択して実行させると、自動的に集計結果が得られます。
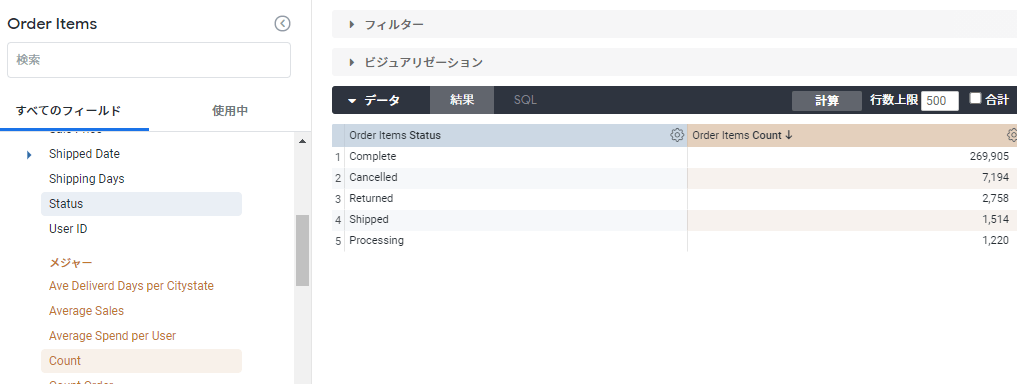
ここで注目してほしいのは dimenstion ではなく measure です。
dimension の方は引っ張ってくる値と、その単位などの定義なので、人に依ってそこまでブレ要素はありません。
しかし、measure の方は人によってブレ要素があります。例えば、○○に対する○○率、などの複雑な指標を得たいときの計算式は、分母に持ってくる値など、定義が人によって異なる ケースがあります。
データガバナンスとは?(再)
上記のケースの様に、データや値の定義が分析する毎に、分析する人毎に、変わってしまうと整合性が取れなくなり、正しい経営判断が出来なくなるリスクが出てきます。
それを防ぐために、データの値や定義を行う層と、その値を見て判断材料を得る層を分離させる事が Looker が言うデータガバナンスの1つの側面です。
しかし、ご存知の通り、これは技術だけでは成立しません。組織の運営とセットでようやくその目的が達成できます。
要約すると以下の3つのロール/層に分かれますね。
| No | ロール/層 | タスク | 必要となる知識 |
|---|---|---|---|
| 1 | view を閲覧し判断材料を収集 | 経営判断の材料を集める | 技術要素とよりは、高い情報処理/整理能力 |
| 2 | KPI の計算方法を定義 | 何の値をどう計算すると目的の指標が計算できるのかを検討 | 数学的知識 |
| 3 | model, view の実装 | 上記の計算を Looker で実装 | Lookerの専門知識 |
上記を組織運営としてチームを分けつつ、適切に運営していく事がデータガバナンスの肝になります。
Looker 導入/運用のために何が必要か?
さて、いよいよ本丸です。少し例を交えて説明していきたいと思います。
想定となる As-Is例 は?
少し極端なところもありますが、データは各部門でバラバラに管理されている(データがサイロ化されている)ケースが多く、何らかのKPIを策定しようにも、それを測定する仕組みから準備する必要があるケースがほとんどです。
例えば、NW/SV機器の保守事業を例にすると…
- NW機器やSV機器の予備機を保管し、顧客の機器が故障した際に機器交換を行う事業を展開
- 予備機・保守部材は日本全国に展開している倉庫に保管
- 上記とは別に、交換作業員が在籍する営業所も日本全国に存在している
- 営業部門 / 保守部門は分かれている
- よくある話ですが、保守部材・予備機の在庫を最小化するという経営目標を立てるとする
- この場合、保守部門が持つデータだけではなく、営業部門が持つ今後の見込みのデータも組み合わせて適切に在庫の配置を決める必要が出ます
ですが、保守部門は倉庫管理システムなどでDB化されているのに対し、営業部門はExcelでデータを管理しているケースが非常に多いため、このKPIを実現させるためには測定する仕組みをまずは作らないといけません。
(もっと言うと、それを使う営業担当者の動きの設計= 業務設計 も必要ですね。技術だけでは解決しません)。
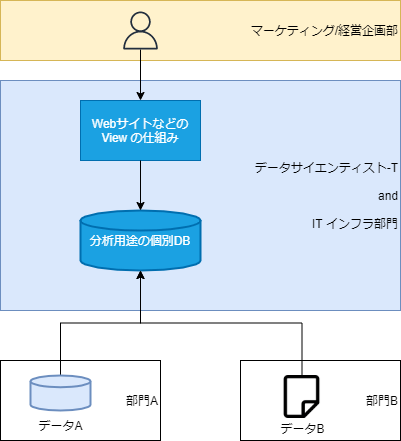
これをまずは基本として、Looker を導入するためには何が必要か? を考察しましょう。
まずはデータウェアハウス!
前述した通り、まずはLookerの大前提のデータウェアハウスの準備が必要です。
データのサイロ化に関しては、Google検索すれば山ほど記事はありますし、色んなベンダーさんが解決策を提案してくれはします。GCP で言えば Bigquery に格納することになります。当然、Looker からも接続できます。
通常、データウェアハウスはITインフラ部門が担当することになります。こんな感じです。

(おそらく)新たに必要になるモノ
- データウェアハウス
- 上記の運用スキル・ナレッジ
Looker を導入!
さて、前提条件が満たされたので、いよいよ Looker を導入しましょう。
先に触れた通り、Looker を実装する層と、計算方法などの数学的な方法を検討する組織を分ける事を前提とします。
(分けなくても運営できる可能性もありますが、一旦わかりやすさのため)
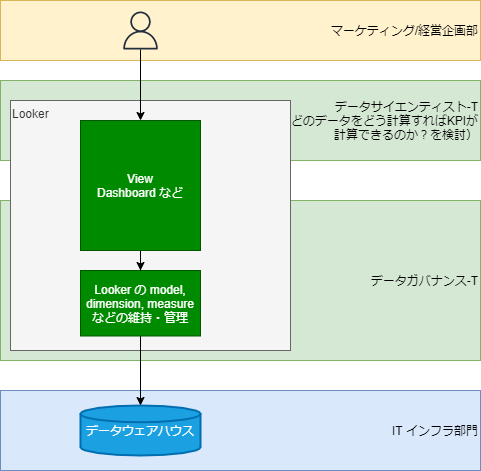
View/Dashboad などの見栄え部分はモノに寄りけりですね。
一時的に分析したい指標であれば、Looker の View 上で GUI で操作して値を取れば良いのでLookerの知識は浅くてOKですし、それを永続化したいのでばれば、view.lkml に落とし込むなどの実装が必要になると思いますので、Lookerの知識は深く必要になります。
(おそらく)新たに必要になるモノ。
- LookML の管理・統制-T
- 外注するか、自前で組織するか
※ データサイエンティスト-T は、Lookerが導入されなくともデータウェアハウスが存在しているのであれば、人としては存在しているはずなので、新しく必要となる事はないと想定されます。
これでおそらく完成じゃないかと思います。
まとめ
Looker をきちんと運用するために必要な事を、組織運営の観点から考察してみました。
会社全体の業務データを横ぐしで管轄し、経営判断に生かすためには、これくらいの編成が必要になる事が想定されます。
スモールスタート自体は問題ないと思いますが、スモールの状態での運用は人件費的にコストメリットが出ませんので、コンサルとして提案するなら、組織運営までやり抜く覚悟を持って提案します!