TIGの伊藤真彦です。
最近会社のPodCastであるFuture Tech Castに出演させていただきました。聞いていただけると嬉しいです。
先日クラウドサービスの障害について社内で体系的に説明する機会があり、0から全体的なイメージがつかめるような情報を整理してみました。
まえがき、良質なクラウドサービス
Webサービス、ITソリューションが自前のサーバーではなくクラウドサービスを利用して構築されるようになって久しいですが…と語っていきたい所ですが、私がITの世界に足を踏み入れた時には、既にAWSを使う事が当たり前の時代になっていました、世の中の変遷を語るだけの含蓄を私は持っていません。
私のようにIT技術に触れた瞬間からクラウドサービスが存在していた世代が産まれる程度に長い時間をかけ、AWS、GCP、Azure各種クラウドサービスは業界に浸透し、使いこなすためのノウハウは一朝一夕では身につかないほど膨大な知識量となりました。
現在のクラウドサービスでは、提供されるサービスを最大限活用することで、世界中からのアクセスに低遅延で応答する、数百万人規模の同時アクセスに耐える、障害発生時も継続して利用可能であるなど、高い性能を有するサービスを作ることも可能です。
一方で性能とコストを天秤にかけベストな落としどころを見極めるための知識、同じ性能を維持したままコストを抑えるための知識も必要です。
今回はAWSの耐障害性、高可用性をテーマに、必要な知識を体系的に学べる情報を集めました。
クラウドサービスにおける障害とは
クラウドサービスの実態は各国、各地域に実際にサーバーなどハードウェアが設置されたデータセンターと呼ばれる施設であり、私たちはそれをレンタルしてサービスを構築しています。
最近の事例だとAWS公式によるEC2 Macインスタンスの紹介動画でAWS EC2担当部署のVice PresidentであるDavid Brown氏がウキウキでトラックに満載されたMacを手にする動画が記憶に新しいです。
ひたすらMacの箱を開けるお仕事を何時間まで楽しくやれるか、時給100円で良いのでやってみたいです。

▲AWS EC2 Mac Instances Launch - macOS in the cloud for the first time, with the benefits of EC2 - YouTubeより
この動画がどこまで本当かはともかく、クラウドサービスとして提供されたものは、行きつくところまで行けば必ず物理的なハードウェア本体が存在し、それらはAWS職員によって管理されてています。当然と言えば当然のことですが、物理機器がそこにある以上何らかの原因で利用できなくなる可能性は0ではありません。
下記のような原因が想定できます。
- ハードウェア本体の故障
- 前段のネットワーク機器の故障による通信不良
- 許容量を超えたアクセス
- その他設備の故障に起因するハードウェア不具合
- 自然災害によるネットワーク断
- データセンターの火災
- 悪意のある攻撃による故障、接続不良
- AWSでのオペレーションミス
例えば2019年の東京リージョンの大規模障害では空調設備の管理システム障害によるサーバーのオーバーヒートという生々しい原因がレポートされています。今年(2021年)はAWS Direct Connectのリージョンレベルでの大規模障害がありました。ここまで大きく、また具体的な調査レポートが報告されることは年に一度あるか無いかといったレベルです。
しかし大規模障害によりAWSに依存する各種サービスが軒並み利用不能になり、ソーシャルゲームのTwitter公式アカウントが障害報告をツイートしはじめる事で、大事件が起きている事が非IT系の方々まで伝わる様子を一度は目にすることになるでしょう。
さて、上記のシナリオで出てきたTwitterはタイムラインの運用基盤にAWSを採用している事がAWS公式のプレスリリースでも確認できます。しかしながら障害発生時においても日本でTwitterを利用することは可能です。
もちろんTwitterが凄いのですが、そこには大規模障害発生時においても正常に動くシステムを構築するためのノウハウがあるはずです。
どのようなノウハウがあるかを、私が思いつく限り整理してみました。
可用性について
可用性とは、システムが継続して稼働できる度合いや能力を意味します。
英語ではアベイラビリティと呼びます、アベイラビリティゾーンのアベイラビリティと同じです。AWSクラウドそのものの可用性という意味でももちろん使われますが、自分たちで構築するシステム単位での可用性という意味でも使われます。
可用性が高いことを高可用性と表現することがあります。
SPOFについて
障害発生時に利用できるサービスと利用できないサービスの差はどこにあるのでしょうか。答えはSPOF(Single Point Of Failure)、日本語で言うと単一障害点の有無が大きく影響します。SPOFとはその名の通り、その単一箇所が働かないと、システム全体が障害となるような箇所を指します。
例えば、Webサービスを自分たちで購入した一台のサーバーを利用して動いている場合、サーバーのLANケーブルが1本抜けただけでサービスが止まります。
そこで、アプリケーションを複数台のサーバーにインストールして、それらをロードバランサー経由で利用し、トラブルが起きたサーバーはロードバランサーから切り離す仕組みを作る事でリスクを回避できます。部分的に壊れることがある前提で、壊れても正常に動く仕組みにする事を冗長化と呼びます。
AWSクラウドにおいてもオンプレミスにおいても、SPOFの存在を見抜き、冗長化することが堅牢なサービスを作る手段になります。一方冗長化をすると当然必要なハードウェアが増えていくため、必要なインフラコストは増えていきます。闇雲にリッチな構成を整えるだけでなく、サービスが求める可用性とコストのバランスを考慮する必要があります。
AWSのマネージドサービスの場合、ある程度の冗長化が済んでいるものが多いです。サービスごとに、リージョンレベル、AZレベルでの耐障害性があるもの、また利用方法によって耐障害性を高めることができるものがあります。AWSクラウドのものであっても、意識して利用しないとSPOFとなるサービスも存在するため、サービスの特性をきちんと理解して運用しましょう。
AZ、リージョンについて
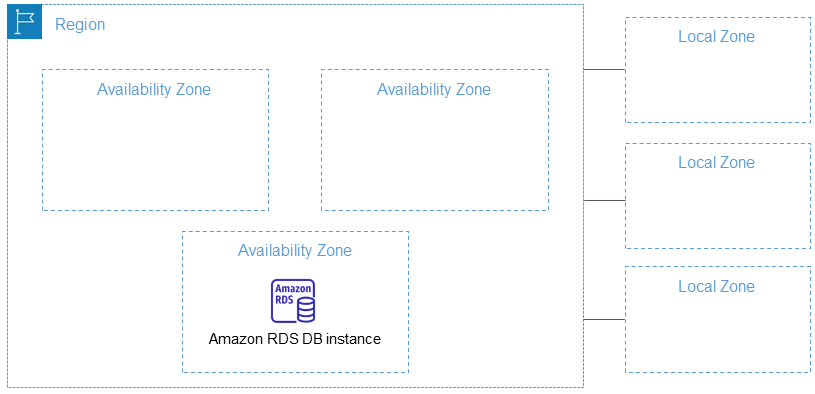
クラウドサービスの耐障害性においては、AZ(アベイラビリティゾーン)、リージョンという概念が存在します。
東京リージョンのap-northeast-1aのように住所のようなものとして使うほか、障害の規模感、および耐障害性のレベル感として、AZ障害、マルチAZ、マルチリージョンやクロスリージョンバックアップといった使われ方をします。
AWSクラウドを利用する上では必須の知識とも言えます、公式ドキュメントはこちらです。
AZ(アベイラビリティーゾーン)とは
前述の通り、AWSクラウドも究極的にはデータセンターのハードウェアをレンタルしている事になります。
AZとは、このデータセンターをネットワークで接続し、冗長化したエリアのことを指します。AWSクラウドを利用するロケーションを選択する際の最小単位がリージョンであり、データセンターを指定することはできません。AWSクラウドのシステムは、データセンターで火災が発生するレベルの事象が起きても問題なく利用できる、もしくは即座に復旧されることになります。
東京リージョンの場合、現在ap-northeast-1aからap-northeast-1dまで4つのAZが存在します。AZごとのネットワークレイテンシが違いすぎる事がないよう、各AZは互いに100km圏内に存在します。障害の内容によっては、どのAZであっても軒並み利用不能になる、リージョンレベルでの障害が発生します
リージョンとは
AZをグループ化したものをリージョンと呼びます。日本では東京リージョン、大阪リージョンが存在します。
リージョンが増える度にAWS公式ブログやプレスリリースで現状が紹介されますが、日本にリージョンが2つある事が中々恵まれている事が伺えます。
リージョンが変わるとネットワークレイテンシがAZの変化より大きく変わるため、耐障害性の面だけでなく、世界中からのアクセスに問題なく対応するという観点でクロスリージョンでの冗長化をする場合があります。
日本で利用されるサービスは当然日本のリージョンで運用した方がネットワークレイテンシが少ないため、基本的にはどの国にサービス利用者が多く存在するかでリージョンを選ぶことになります。
マネージドサービスにはデフォルトでAZレベルの耐障害性を持っているものの、更にリージョンレベルで複製する機能を備えたものも存在します。
障害発生時にダウンしないサービスを作る
どのようなサービスを、どのように冗長化できるのか、マネージドサービスが基本的にはどのレベルでの冗長化が為されているのかを学ぶことで、適切な耐障害性を持ったサービスを構築するための足がかりとなります。
AZレベルでの冗長化
同じリソースを複数台、マルチAZ構成で展開することで、1つのAZが利用不可能になってもサービスを継続利用できます。
例としては、Webサーバーを複数のAZに分散配置して、前段にELBを設置する手法があります。AWS公式のユーザーズガイドのElastic Load Balancing の仕組みの画像が参考になります。
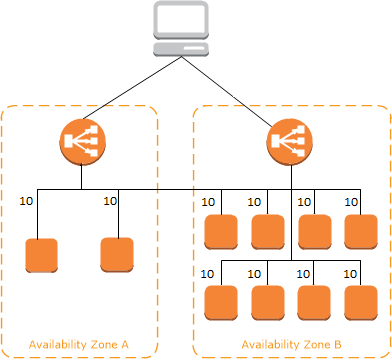
この構成を取ることで、特定のAZが利用不可能になってもサービス全体としては機能します。
障害発生時にもサービスの性能を落としたくない場合は、1つ1つプロビジョニングしているEC2インスタンスをAWS Auto Scalingを利用したインスタンス群にすることも可能です。AWS Auto Scalingはインスタンスの負荷に応じて自動でサービスをスケーリングすることでコストダウンする事も狙いの1つですが、インスタンスの不具合を自動復旧できる事や、AZ障害発生時にも総合的な性能を維持する事も期待できます。
EC2インスタンス以外でも、RDSのマルチAZ配置や、ElastiCacheのマルチAZ配置など、デフォルトではAZレベルの冗長化がなされていないサービスが存在します。
古いサービスの場合、NATゲートウェイを使えば良い所をNATインスタンスのままになっていて、そこがSPOFになる場合があります。AWS S3の場合はデフォルトでマルチAZでの耐久性が保証されていますが、バケットの耐久性の設定を1ゾーン低頻度アクセスにすることで、コストを抑えることも可能です。
利用しているサービスが、現在どのような耐障害性を持っていて、どのような強化が可能かを把握する事が重要です。
リージョンレベルでの冗長化
前述しましたが何らかの原因でリージョン全体が利用できなくなる可能性は0ではありません、数年に一度くらいの頻度では発生しうる障害です。リージョン間での冗長化を行う事で、リージョン全体が利用できなくなるほどの障害発生時においてもサービスの停止を回避することは可能です。
性質上システム全体を冗長化しないと一切の問題なく動くようにはできない事と、大規模障害の発生頻度を考慮すると、このレベルで冗長化されているサービスは比較的少ないです。
S3のクロスリージョンレプリケーション、DynamoDBのグローバルテーブル、RDSのクロスリージョンリードレプリカなど、マネージドサービスにはサービスごとにリージョンを超えた複製を行うシステムが公式から提供されている事があります。
Application Load Balancerは別のリージョンにアクセスを振り分けることができない、AMIやEBSのスナップショットはそのままでは別のリージョンでは利用できず、クロスリージョンのコピーを作成する必要があるなど、AZ間での冗長化とは前提、難易度が異なってくる場合があります。
障害復旧可能なサービスを作る
障害発生時に一切ダウンしないサービスを作るという目標を据える事も可能ですが、コストや工数と求められるレベル感のバランスにより実現できないケースは大いにあり得ます。
しかし障害発生時の復旧を可能な限り迅速に行うための準備、障害によるダメージを最小限に抑えるための工夫を行う余地はあります。
そのような観点で工夫できないか検証する、または要求レベルとしてどのような品質が求められるかをあらかじめ検討、定義する事は必要になってくるでしょう。
RPO, RTOについて
障害復旧においてはRPO、RTOという概念があります(AWSの試験に出ます)。
RPOはRecovery Point Objectiveの略です。障害発生時に主にアプリケーションのデータ損失がどの地点まで回復可能かを意味します。RTOはRecovery Time Objectiveの略です。これは単純に障害発生時から回復までに要する時間です。これらの指標はサービスの性能を意味するものにもなりますが、ビジネス的な要求から指標を定義することで、災害復旧戦略を逆算することが可能になります。
例えばデータベースのバックアップを一時間に一度保存すればRPOは最長一時間になります、データベースのクロスリージョンリードレプリカを作成して、障害発生時にレプリカをマスタに昇格すればおけばRPOはほぼリアルタイムになります。
RTOの例ですが、システムのレプリカを別リージョンに常に展開し、障害発生時はアクセスをレプリカに接続させることで、RTOがほぼ0のような厳しい条件をクリアできます。RTOに時間の猶予が許される場合は、普段は単一リージョンで運用することでコストを抑えることが可能になります。
障害復旧のための様々な戦略
障害復旧のための戦略にはいくつか名称が付けられているものがあります。
障害復旧はディザスタ・リカバリ(DR)と呼ばれ、障害発生時に退避するリージョンをDRリージョンと呼ぶことがあります。
パイロットライト
パイロットライトとは、ガスヒーターなどの設備が、素早く着火できるように常に点灯している小さな火の事です。
そのパイロットライトのように、DRリージョンに停止したサーバーを用意しておく、IaaSを用いて別リージョンにシステムを構築するといった手法を意味します。障害発生時はDRリージョンに切り替えを行います、基本的にはAmazon Route 53の接続先設定の変更によって切り替えを行います。
コストを抑えつつ、リージョンレベルの可用性を持たせることが可能になります。
ウォームスタンバイ
DRリージョンにスペックを下げた同構成でシステム一式を常時起動しておきます。
障害発生時は素早くDRリージョンに切り替え、必要に応じてスケールアップします。
マルチサイト
ホットスタンバイとも呼ばれます、スペックも含め全く同じ構成をDRリージョンに用意しておきます。
コストがかかっても一切ダウンが許されないシステムではこのような構成をとることが可能です。
バックアップと復元
上記3つはリージョンが利用不能な状態でも復元可能な手法ですが、定期的にデータのバックアップを取り、リージョンが回復してから可能な限り素早くシステムを回復できるように備える事も立派なDR戦略です。
RDSやEBS、AMIなど各サービスごとに、どのように定期的なバックアップをとることが出来るのかを把握することは大切です。
障害を検知、自動通知、復旧する仕組みを整備する
障害発生時は公式のアナウンスを待つより早く気が付けるに越したことはありません。
AWS全体ではなく、自分たちのシステムだけが落ちている可能性もあります。
ヘルスチェックの仕組みを整備し、通知する仕組みを整備することで、障害にいち早く気がつくことが可能になります。
これら仕組みは、Amazon CloudWatch、Amazon SNSといったサービスを活用することで構築可能です。
Amazon RDSの場合、Amazon RDS イベント通知という仕組みが用意されています。
EC2インスタンスの場合、CloudWachアラームを受けて自動で復旧、再起動する設定が用意されています。
性能面での可用性を高める
AWSクラウド側に問題が無くても、思わぬアクセス急増やDDoS攻撃など悪意のあるアクセスに対し、構築したシステムの性能が追いついていないことでシステムが利用不可能になることはあり得ます。
一方必要以上にハイスペックなシステムを整えるとインフラコストが問題になってきます。
システムの需要と可用性のバランスを整えていくことが重要になります。
アクセスの急増に備える
新製品のプレスリリースを行った結果会社のホームページが落ちた、ソーシャルゲームをリリースしたが想定以上の人気にサーバーがダウンした、というような事例が実際に起きています。
AWSクラウドの場合AWS Auto Scalingを活用したシステムを構成する事で、高いコスト効率を保ちつつ、急激なアクセス増に耐えるシステムを構築することが可能です。
前述したDDoS攻撃はAWS Shieldを利用してシステムを保護することが可能です。
キャッシュを有効活用する
アクセスを処理する能力をシステム全体の性能だけで解決すると当然コストがかかります。
キャッシュ層を構築することで、コストを抑えつつアクセスに効率よく応答することが可能になります。
Amazon CloudFrontによるコンテンツのキャッシュや、DBの前段にAmazon ElastiCacheを配置するといった戦略が考えられます。
レイテンシを意識する
リージョン間の冗長化は障害発生に備えたものだけではなく、世界中で安定して使えるサービスを作るという意味でも役に立ちます。
Amazon Route 53にはレイテンシーベースルーティングというルーティングアルゴリズムがあり、これを活用することで、複数リージョンに展開したシステムのうち、最もレイテンシの少ないリージョンを利用することが可能になります。
ヘルスチェックを活用することで、普段はレイテンシが最小のリージョンを利用し、障害発生時は別のリージョンにフェイルオーバーする、といった仕組みを整えることが可能になります。
安全なリリース、ダウンタイムゼロでのリリースを行う
アプリケーションの新機能をリリースした際にバグがあった、リリース手順を間違えてしまった、というシナリオで障害が発生することも考えられます。
またデプロイ時に瞬間的にアクセスできなくなることをダウンタイムと呼びます。
デプロイ戦略を整備することで、リリース失敗時に素早く切り戻す、ユーザーへの影響を最小限に留める、デプロイにおけるダウンタイムを最小に抑えることが可能です。
ここにもコストと性能のバランスに応じた様々な戦略が存在します。
Blue/Greenデプロイ
ブルーおよびグリーンと呼ぶ同じ環境を2つ用意し、デプロイ時には利用していない方の環境を更新し、更新した環境を利用開始し、問題があった場合は元の環境に接続し直す手法をBlue/Green デプロイと呼びます。
Amazon Route 53を利用すれば基本的にどのアーキテクチャでも実現可能です。AWS CodeDeployを利用すると、AWS Elastic Beanstalk、Amazon ECSなどのサービスで、整備されたBlue/Greenデプロイを実現するための仕組みを利用することが可能です。
最も安全ですが、2環境分の運用コストが発生します。
Canaryリリース
2環境の接続先を切り替える際の戦略として、Canaryリリースと呼ばれる戦略があります。これはトラフィックの一部を新環境に流し、問題なければ全員にリリースしていく手法です。ここでのCanary(カナリア)は、炭鉱労働者が一酸化炭素中毒やガス漏れに気がつくよう、カゴに入れたカナリアを連れて、カナリアが死んでしまった場合はその場から退避をする手法を検討した、生理学者John Scott Haldane氏による実験に由来します。
気の毒な話ですが、新環境に真っ先に触れる一部のユーザーがこのカナリアに例えられています。
Amazon Route 53では加重ルーティングポリシーと呼ばれるルーティングアルゴリズムが存在します。
これは指定した比率で複数のリソースにトラフィックをルーティングするアルゴリズムです。一部のトラフィックがセーフであれば残りを一気に切り替えることも、10%、20%と線形に切り替える比率を増やしていくことも可能です。CanaryリリースはAPI Gatewayでも機能として用意されています。2019年から、同じことをALBでもできるようになりました。
冗長化されたサーバーの更新戦略
完全に切り分けた環境を切り替えない手法でも、冗長化された複数のサーバーをどのように更新していくか、という観点での戦略があります。
これら戦略はAWS Elastic Beanstalkのオプションとして用意されており、参考になります。
Immutable
同じ環境でWebサーバーを既存の台数と同じ数だけ新しく構築し、問題なければ古いサーバーを削除します。
問題があった際の既存の状態への影響が少ないですが、一時的にコストがかかります。
新旧のシステムが一時的に混在するというデメリットもあります。
Rolling
サーバーの一部をシステムから切り離し、更新を行ってからシステムに再接続します。
コストは抑えられますが、一時的なシステムの性能ダウンと、新旧のシステムが一時的に混在するというデメリットがあります。性能低下を防ぐため、一時的にサーバーを増やして、問題なければ古いサーバーを落とす処理を繰り返すRolling with additional batchと呼ばれる戦略もあります。一度に何台のサーバーを操作するかはシステムの全体的なサイズとリリースにかかる時間のバランスを見て調整します。
トラフィック分割
Blue/Greenデプロイ、Canaryリリースと同様の手法をロードバランサーの単位で行います。
All At Once
瞬間的なシステム断が許容できる場合は、全てのサーバーをまとめて更新します。
手間がかからないという意味では最も楽な仕組みです。
まとめ
障害を起こさないための戦略、障害発生時の対応を体系的に学ぶという観点で、思いつく限り書いてみました。
- クラウドサービスも人が運用したシステムであり、様々な障害が起こりうる
- 耐障害性を向上する
- 復旧戦略を整備する
- 障害を検知する仕組みを整備する
- 高可用性を持ったシステムを作る
- リリース戦略を整備する
各観点においてさらに深掘り、詳細な説明をする余地がまだまだありますので、この記事を読んで気になった点を調べてみてください。