こんにちは、TIG所属の玉木です。この記事はPython連載の7本目の記事になります。
2021年9月24日にscikit-learn 1.0がリリースされました。私が大学院生のころ、scikit-learnのサンプルを動かすところから機械学習を勉強したので、ついに1.0かとなんだか感慨深い気持ちがあります(この記事で紹介しているPython 機械学習プログラミングです)。本記事ではリリースから少し時間が経ってしまいましたが、リリースハイライト、チェンジログから、個人的に気になった以下の4つの内容を紹介しようと思います。
- キーワード引数の強制
- pandasのデータフレームからの特徴量名のサポート
- 新しいplot用のクラス追加
- StratifiedGroupKFoldの追加
1. キーワード引数の強制
scikit-learnの機械学習のモデルのクラス、メソッドは、多くの入力パラメータを持ちます。
以前のscikit-learnでは以下のようにクラスをインスタンスできました。以下リリースハイライトからの引用です。
est = HistGradientBoostingRegressor("squared_error", 0.1, 100, 31, None, |
上記は極端な例ですが、この記述の仕方だと、各位置の引数がどんな意味をもつかわからず、APIドキュメントを確認する必要があります。このような位置引数を用いた初期化はTypeErrorが発生するようになります。代わりに以下のようにキーワード引数を用いて初期化します。
est = HistGradientBoostingRegressor( |
位置引数を用いた初期化に比べて、キーワード引数を持ちいた初期化の方が各引数の意味がわかり、非常に読みやすいです。すべての位置引数が禁止されるわけではないのですが、ライブラリの方で可読性が良くなるように書き方を強制してくれるのは嬉しい変更です。
2. pandasのデータフレームからの特徴量名のサポート
scikit-learnでは機械学習のためのデータ変換、前処理の機能が多くあります。例えばscikit-learnのpreprocessモジュールのOneHotEncoderを用いればカテゴリ変数を数値表現に変換でき、StandardScalerを用いれば、数値を標準化できます。
これまでは変換器の入力がpandasのデータフレームであっても、元の列名を保持できず、列名が欲しい場合は自分で列名を作って与える必要がありました。scikit-learn 1.0ではColumnTransformerのような変換器が列名を保持するようになり、get_feature_names_outメソッドを使うだけで簡単にデータ変換後の列名も取得できるようになりました。
from sklearn.compose import ColumnTransformer |
Xは以下のようなデータフレームになります。
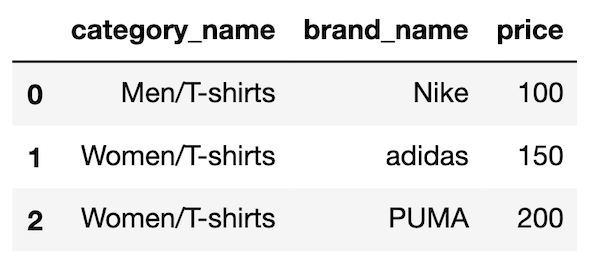
ColumnTransformerを用いて、Xのカテゴリ変数に対してはone-hot encoding、量的変数に対しては標準化を行います。
preprocessor = ColumnTransformer( |
preprocessor.get_feature_names_out()の出力は以下のようになります。列名が保持されているだけでなく、変換後の特徴量に対しても列名がつけられていることがわかります。
Out: |
今回追加されたget_feature_names_out()はscikit-learnでデータ変換を行い、pandasのデータフレームに再度変換したい場合などに便利です。
pd.DataFrame(preprocessor.transform(X), columns=preprocessor.get_feature_names_out()) |
以下の画像のように変換後のデータを簡単にデータフレームに戻すことができます。
pandasのget_dummiesメソッドを使っても同様のone-hot encodingは可能です。
pd.get_dummies(X) |
以下get_dummiesの出力です。
ほぼ同じデータフレームが得られました。今回のように数値変換も同時にscikit-learnで行いたい場合などには、scikit-learnの変換器を通してget_feature_names_out()を使うのがいいのかなと思います。
3. 新しいplot用のクラス追加
これまで混合行列やROC曲線を描画したいときは、sklearn.metricsモジュールのplot_confusion_matrixやplot_roc_curveが使えましたが、scikit-lean 1.0からは非推奨になり、1.2では削除の予定とのことです。代わりにConfusionMatrixDisplay、PrecisionRecallDisplayといったクラスが追加されました。元のplot_*関数はestimatorが引数に必要だったのですが、from_predictionsメソッドを使うことにより、ラベルと予測した値を渡せば描画ができるようになりました。
以下APIドキュメントからサンプルコードの引用です。
import matplotlib.pyplot as plt |
描画される混合行列は以下になります。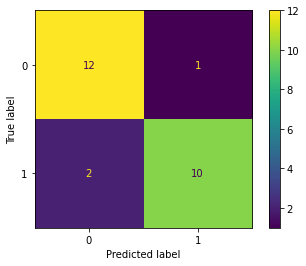
4. StratifiedGroupKFoldの追加
機械学習のモデルの評価において、交差検証における検証データの作り方は非常に重要です。例として、以下のKaggle State Farm Distracted Driver Detectionに参加したスライドが参考になります。
https://speakerdeck.com/iwiwi/kaggle-state-farm-distracted-driver-detection?slide=22
このスライドでは検証データに同じドライバーのデータを使っていたために、学習データの汎化性能を正しく評価できなかった、学習データと検証データ間に同じドライバーのデータを含めないようにしたら正しく評価できるようになった、と報告しています。
このようにデータの分割の手法は重要なのですが、今回追加されたStratifiedGroupKFoldは、そのデータ分割の手法のうちの1つです。StratifiedGroupKFoldはStratifiedKFoldとGroupKFoldの2つの機能をあわせたデータの分割方法です。StratifiedKFoldは各セブセットのクラスの比率が維持されるようにデータを分割します。特にクラスの分布が均等でない場合に有効です。
GroupKFoldは、各セブセット間に同じグループが含まれないように分割します。先程の例のように、同じドライバーを含めてしまうと不当に高くモデルの性能を評価してしまう、といったことを防ぎます。この2つの特徴をどちらも同時に使いたいときがあるのですが、これまでscikit-learnにはこの機能はなく、自分で実装する必要がありました。scikit-learn 1.0からは簡単に使えるようになりました。
まとめ
本記事ではscikit-learn 1.0に追加された以下の機能を簡単に紹介しました。
- キーワード引数の強制
- pandasのデータフレームからの特徴量名のサポート
- 新しいplot用のクラス追加
- StratifiedGroupKFoldの追加
普段scikit-learnを使っている方の参考になれば幸いです。