はじめに こんにちは、TIG/DXユニット所属の宮永です。
今回はAWS Step Functionsの動的並列処理をローカルで実行する方法をハンズオン形式でまとめました。ソースコードはこちらに格納していますのでご参考にして下さい。
https://github.com/orangekame3/stepfunctions-demo
本記事はPipenv+LocalStackで作るLambda開発環境 で作成したLambda関数をベースに実装しています。本記事の実装に取り組まれる方はこちらの記事が参考になると思います。
Step Functionsとは Step FunctionsとはAWSの各種リソースをオーケストレーションするサービスです。
類似のサービスにAirflow 等があります。AirflowとStep Functionsの比較をした多賀さんの記事 はとても読み応えたあるのでぜひご覧ください。
Step Functionsについては技術ブログでもこれまで取り扱っています。
今回はServerless連載6: AWSのStep FunctionsとLambdaでServelessなBatch処理を実現する を参考にPythonとLocalStack(Docker)で動的並列処理を実装します。
モチベーション 今回想定しているユースケースは「大規模データの集計作業をLambdaで実装する」というものです。
Lambdaの実行制限時間である15分を超えるであろう処理をStep Functionsを使ってうまく突破したいというのがモチベーションです。先程紹介したServerless連載6: AWSのStep FunctionsとLambdaでServelessなBatch処理を実現する には動的並列処理以外にもStep Functionsを応用したバッチ処理について幅広く言及しているため、一読されると良いかと思います。
ハンズオンで構築するシステム 全体のシステム概要を記載した後に機能詳細を紹介します。
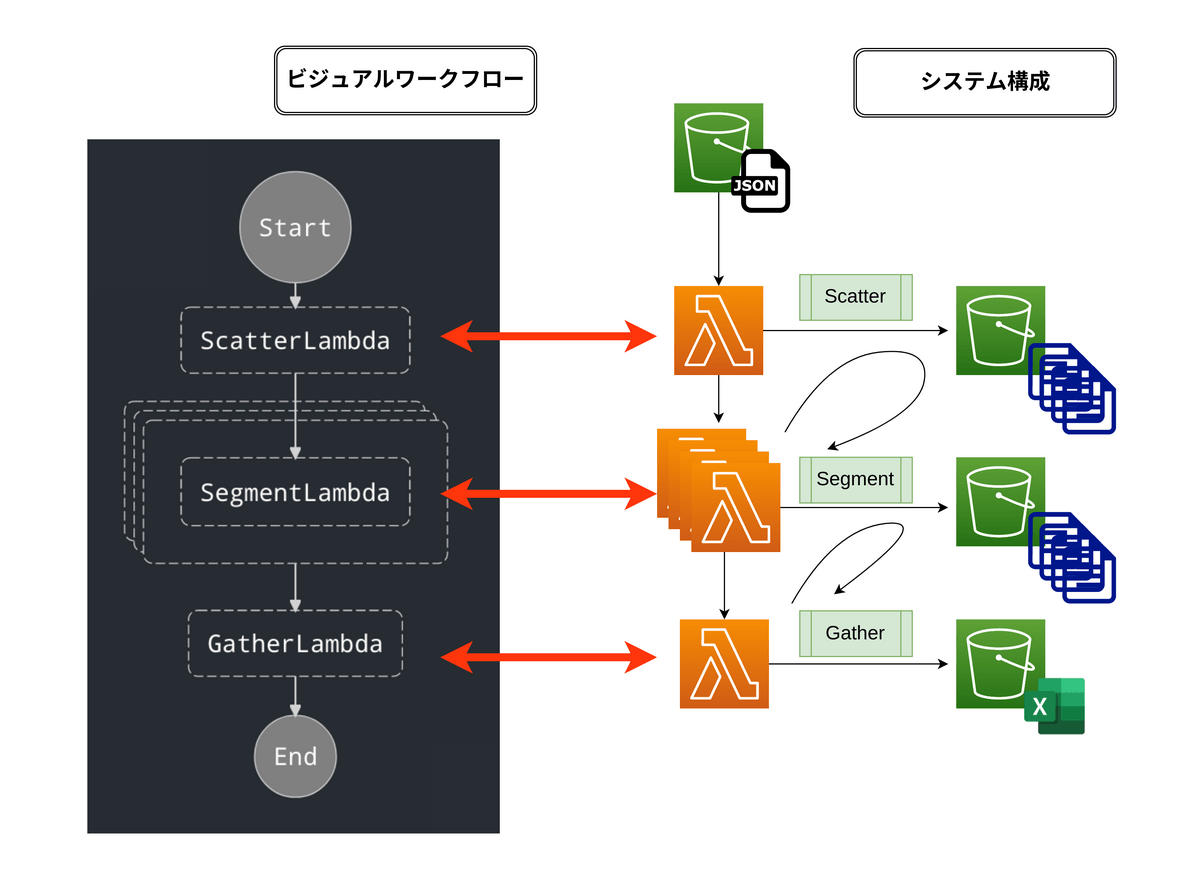
システム構成図 今回構築するシステム構成図を以下に記載します。
画像左側はビジュアルワークフロー図と呼ばれるもので今回扱うStep Functionsの定義書から生成されます。画像右側はビジュアルワークフロー図に対応するシステムアーキテクチャ図です。
S3バケットからJSONを取得し、後続のLambdaでETL処理をします。
余談ですが、Visual Studio CodeにはAWS Tool Kit という拡張機能が存在します。
こちらの拡張機能を利用すればステートメント言語 を下図のビジュアルワークフロー図のように可視化できます。
実装するアプリの機能詳細 こちらの記事 で実装しているLambda関数と同等の機能をもつシステムを実装します。
[ { "会員番号" : "000" , "名前" : "長野原 ひろし" , "会員ランク" : 4 , "ポイント" : 58 , "タイムスタンプ" : "2021-05-16" } , { "会員番号" : "001" , "名前" : "般若 竜門" , "会員ランク" : 2 , "ポイント" : 75 , "タイムスタンプ" : "2021-07-19" } , { "会員番号" : "002" , "名前" : "十河 アンナ" , "会員ランク" : 2 , "ポイント" : 57 , "タイムスタンプ" : "2021-09-06" } ]
ScatterLambda ScatterLambdaでは上記のJSONファイルを取り込み、DataFrameに変換します。その後、DataFrameをSegmentLamdaが15分以内に処理できる単位に分割します。
分割したファイルはpickleファイルでS3バケットに格納します。
SegmentLambda SegmentLambdaではScatterLambdaで分割されたpickleファイルを取り込みETL処理を行います。
「ボーナスポイント」は以下の条件で決定します。
【条件】
会員ランクが「4,5」の会員には「ポイント」×1.25倍のボーナスポイントを、会員ランク「1,2,3」の会員には「ポイント」と同等のボーナスポイントを付与することします。
上記の条件に従ってSegmentLambdaの処理前後のテーブルをまとめると以下のようになります。
SegmentLambda処理前
SegmentLambda処理後
GatherLambda GatherLambdaではSegmentLambdaでETL処理をされた各pickleファイルを取り込み、ひとつのExcelファイルを作成します。
開発環境 開発に取り組む前に筆者の開発環境を記載します。記事中Linuxコマンドを使用している箇所があります。Windowsで開発される方はWSLを使用することをおすすめいたします。
OS Ubuntu 20.04
Python(pyenv) 3.9
Pipenv
Docker
docker compose v2
AWS CLI v2
LocalStackの準備 実装対象が決まったので早速開発環境の準備に取り掛かります。
AWS環境をローカルに用意するためにLocalStackを利用します。使用するのは以下2つのimageです。こちらの記事 を参考にさせていただきました。
それでは上記2つのimageを使用したdocker-compose.ymlを記述します。
docker-compose.yml version: '3.8' services: localstack: container_name: "${LOCALSTACK_DOCKER_NAME-localstack_main}" image: localstack/localstack environment: - DATA_DIR=/tmp/localstack/data - SERVICES=lambda,s3,stepfunctions - LAMBDA_EXECUTOR=docker-reuse - DEFAULT_REGION=us-east-1 - DEBUG=1 ports: - "4566:4566" volumes: - /tmp/localstack:/tmp/localstack - /var/run/docker.sock:/var/run/docker.sock stepfunctions: container_name: stepfunctions image: amazon/aws-stepfunctions-local:latest env_file: stepfunctions-credentials.env environment: - LAMBDA_ENDPOINT=http://localstack:4566 - STEPFUNCTIONS_LAMBDA_ENDPOINT=http://host.docker.internal:4566 ports: - '8083:8083'
stepfunctionsのenv_fileで環境変数を渡しています。env_fileの中身を以下記載します。
AWS_ACCOUNT_ID=test AWS_DEFAULT_REGION=us-east-1 AWS_ACCESS_KEY_ID=test AWS_SECRET_ACCESS_KEY=test
また、DEBUGオプションに1と選択することでLocalStackのログを細かく確認できます。
これでLocalStackの準備が整いました。
docker compose up --build
次にAWS CLIの設定を行います。
AWS CLIの設定 AWS CLIでは認証情報などをプロファイルとして保存できます。.awsの隠しファルダがあります。(エクスプローラーなどで確認する場合は隠しフォルダを表示するように設定してください。).awsフォルダ配下には.configと.credentials2つのファイルがありますのでそれぞれ以下のように設定してください。
参考:名前付きプロファイル
今回は以下のようにlocalというプロファイルを作成しました。
config [localstack] region = us-east-1 output = json
credentials [local] aws_access_key_id = testaws_secret_access_key = test
次にLambdaの実装を行います。
Lambdaの実装 このあと、複数のファイルを作成するため、最終的なディレクトリ構造を先に記載します。
最終的なディレクトリ構造
. ├── Makefile ├── README.md ├── demo-gather │ ├── Makefile │ ├── Pipfile │ ├── Pipfile.lock │ ├── bin │ │ └── lambda.zip │ ├── deploy-packages │ ├── gather.py │ ├── lambda.py │ ├── requirements.txt │ ├── result.log │ ├── setup.cfg │ └── tests ├── demo-scatter │ ├── Makefile │ ├── Pipfile │ ├── Pipfile.lock │ ├── bin │ │ └── lambda.zip │ ├── deploy-packages │ ├── lambda.py │ ├── requirements.txt │ ├── result.log │ ├── scatter.py │ ├── setup.cfg │ └── tmp.py ├── demo-segment │ ├── Makefile │ ├── Pipfile │ ├── Pipfile.lock │ ├── bin │ │ └── lambda.zip │ ├── deploy-packages │ ├── lambda.py │ ├── requirements.txt │ ├── result.log │ ├── segment.py │ ├── setup.cfg │ └── tests │ ├── __init__.py │ └── test_segment.py ├── docker-compose.yml ├── result │ └── test.xlsx ├── state-machine │ └── parallel.json ├── stepfunctions-credentials.env └── utils ├── data │ └── sample_data.json └── utils.py 15 directories, 39 files
前提 ローカルマシンにPython3の環境が構築されていることを前提としています。
冒頭で記載しましたが、以前Pipenv+LocalStackで作るLambda開発環境 という記事を書かせていただきました。
記事ではLambdaの開発時使用するパッケージとデプロイ時のパッケージを分離することでデプロイ時のzipファイルの容量節約する方法を紹介しています。興味がある方はぜひご覧になってください。
今回は3つLambdaを作成しますので、以下のような構成でフォルダを作成してください。
. ├── demo-gather ├── demo-scatter └── demo-segment
まずはdemo-scatterから開発環境を準備します。
次に使用する外部モジュールをインストールします。
続いて開発環境で使用するパッケージをインストールします。以下のコマンドでpytestとmypyをインストールします。
pipenv install pytest mypy --dev
これでプロジェクト環境が整いました。他2つのプロジェクトも同様に環境を構築します。
demo-segment
pandas
pytest mypy (–dev)
demo-gather
pandas
xlwt
xlsxwriter
pytest mypy (–dev)
それではScatterLambdaからロジックの実装をします。
ScatterLambda demo-scatter配下に以下2つのファイルを作成します。
機能のほとんどはscatter.pyに記述し、lambda.pyではハンドラを呼び出すのみにします。
lambda.py import osimport boto3from scatter import ScatterHandlerif os.getenv("LOCALSTACK_HOSTNAME" ) is None : s3 = boto3.client("s3" , "ap-northeast-1" ) else : endpoint = f"http://{os.environ['LOCALSTACK_HOSTNAME' ]} :4566" s3 = boto3.client( service_name="s3" , endpoint_url=endpoint, aws_access_key_id="test" , aws_secret_access_key="test" , ) def lambda_handler (event, context ) -> dict : handler = ScatterHandler( event, context, s3, ) return handler.main()
ScatterLambdaでは、ファイルの分割を行います。
scatter.py import jsonimport tempfileimport loggingimport pandas as pdfrom typing import List , Dict logger = logging.getLogger() logger.setLevel(logging.INFO) class ScatterHandler (object ): def __init__ ( self, event, context, s3, ): self .event = event self .context = context self .s3 = s3 def main (self ) -> dict : try : bucket = "test-bucket" data_path = self .event["input_obj" ] division_number = 10 segments: Dict = {} segments["segment_definitions" ] = [] data = self .get_s3_data(bucket, data_path) df = self .make_df(data) dfs = [ df.loc[i : i + division_number - 1 , :] for i in range (0 , len (df), division_number) ] segments = self .make_segment_df(segments, bucket, dfs) return segments except Exception as e: logger.exception(e) raise e def get_s3_data (self, bucket: str , key: str ) -> List [dict ]: resp = self .s3.get_object(Bucket=bucket, Key=key) body = resp["Body" ].read().decode("utf-8" ) json_dict: List [dict ] = json.loads(body) return json_dict def make_df (self, data: list ) -> pd.DataFrame: df = pd.DataFrame.from_dict(data) return df def make_segment_df (self, segments: dict , bucket: str , dfs: list ) -> dict : for i, df_i in enumerate (dfs): with tempfile.TemporaryFile() as fp: df_i.to_pickle(fp) fp.seek(0 ) fsend = "scatter/job_" + str (i).zfill(3 ) + ".pkl" self .s3.put_object( Body=fp.read(), Bucket=bucket, Key=fsend, ) segments["segment_definitions" ].append(fsend) return segments
test-bucketに格納されたsample.jsonを取得して、pandasでDataFrameに変換します。変換後はpickleファイルで保存することでSegmentLambdaでの読み込み処理を高速化しています。segment_definitionsをキーとした辞書にリストして格納しています。
SegmentLambda SegmentLambdaでETL処理を行います。ETL処理時の条件を再度記載します。
【条件】
会員ランクが「4,5」の会員には「ポイント」×1.25倍のボーナスポイントを、会員ランク「1,2,3」の会員には「ポイント」と同等のボーナスポイントを付与することします。
上記の条件を実装したsegment.pyを以下記載します。
segment.py import tempfileimport loggingimport pickleimport pandas as pdlogger = logging.getLogger() logger.setLevel(logging.INFO) class SegmentHandler (object ): def __init__ (self, event, context, s3 ): self .event = event self .context = context self .s3 = s3 def main ( self, ) -> str : try : bucket = "test-bucket" recieve = self .event send = recieve.replace("scatter" , "gather" ) df = self .get_s3_data(bucket, recieve) df = self .process(df) return self .send_segment_df(df, bucket, send) except Exception as e: logger.exception(e) raise e def get_s3_data (self, bucket, key ) -> pd.DataFrame: resp = self .s3.get_object(Bucket=bucket, Key=key) body = resp["Body" ].read() df = pickle.loads(body) return df def calc (self, row ): if row["会員ランク" ] > 3 : return row["ポイント" ] * 1.25 else : return row["ポイント" ] def process (self, data: pd.DataFrame ) -> pd.DataFrame: data["ボーナスポイント" ] = data.apply(self .calc, axis=1 ) return data def make_df (self, data: list ) -> pd.DataFrame: df = pd.DataFrame.from_dict(data) return df def send_segment_df (self, df: pd.DataFrame, bucket: str , send: str ) -> str : with tempfile.TemporaryFile() as fp: df.to_pickle(fp) fp.seek(0 ) self .s3.put_object( Body=fp.read(), Bucket=bucket, Key=send, ) return send
ScatterLambdaと同様にsegment.pyで定義したハンドラを呼ぶlambda.pyを以下のように作成します。
lambda.py import osimport boto3from segment import SegmentHandlerif os.getenv("LOCALSTACK_HOSTNAME" ) is None : s3 = boto3.client("s3" , "ap-northeast-1" ) else : endpoint = f"http://{os.environ['LOCALSTACK_HOSTNAME' ]} :4566" s3 = boto3.client( service_name="s3" , endpoint_url=endpoint, aws_access_key_id="test" , aws_secret_access_key="test" , ) def lambda_handler (event, context ) -> str : handler = SegmentHandler(event, context, s3) return handler.main()
GatherLambda 最後にSegmentLambdaでETL処理をしたDataFrameを取り込み、1つのExcelファイルにまとめるGatherLambdaを実装します。
gather.pyは以下のようになります。
gather.py import tempfileimport loggingimport pandas as pdimport picklefrom typing import List logger = logging.getLogger() logger.setLevel(logging.INFO) class GatherHandler (object ): def __init__ (self, event, context, s3 ): self .event = event self .context = context self .s3 = s3 def main (self ) -> str : try : bucket = "test-bucket" segments = self .event["segment_results" ] send = "test.xlsx" data_frames: List [pd.DataFrame] = [] for pkl in segments: df = self .get_s3_df(bucket, pkl) data_frames.append(df) df_gather = pd.concat(data_frames) return self .send_excel(df_gather, bucket, send) except Exception as e: logger.exception(e) raise e def get_s3_df (self, bucket, key ) -> pd.DataFrame: resp = self .s3.get_object(Bucket=bucket, Key=key) body = resp["Body" ].read() df = pickle.loads(body) return df def send_excel (self, df: pd.DataFrame, bucket: str , send: str ) -> str : with tempfile.TemporaryFile() as fp: writer = pd.ExcelWriter(fp, engine="xlsxwriter" ) df.to_excel(writer, sheet_name="Sheet1" , index=False ) writer.save() fp.seek(0 ) self .s3.put_object( Body=fp.read(), Bucket=bucket, Key=send, ) return send
gather.pyで定義したハンドラを呼ぶlambda.pyを以下に記載します。
lambda.py import osimport boto3from gather import GatherHandlerif os.getenv("LOCALSTACK_HOSTNAME" ) is None : s3 = boto3.client("s3" , "ap-northeast-1" ) else : endpoint = f"http://{os.environ['LOCALSTACK_HOSTNAME' ]} :4566" s3 = boto3.client( service_name="s3" , endpoint_url=endpoint, aws_access_key_id="test" , aws_secret_access_key="test" , ) def lambda_handler (event, context ) -> str : handler = GatherHandler(event, context, s3) return handler.main()
LocalStackへのデプロイ それでは作成したそれぞれのLambda関数をLocalStackにデプロイします。こちらの記事 にまとめた方法を採用します。各Lambda関数のディレクトリ内に以下のようなMakefileを作成します。
.PHONY : clean zip delete create updatePROJECT_DIR=$(shell pwd) DEPLOY_PACKAGES_DIR=deploy-packages clean: rm -rf ./bin/* zip:clean pipenv run mypy pipenv lock -r >requirements.txt pipenv run pip install -r requirements.txt --target $(DEPLOY_PACKAGES_DIR) @echo "Project Location: $(PROJECT_DIR) " @echo "Library Location: $(DEPLOY_PACKAGES_DIR) " cd $(DEPLOY_PACKAGES_DIR) && rm -rf __pycache__ && zip -r $(PROJECT_DIR) /bin/lambda.zip * cd $(PROJECT_DIR) && zip -g ./bin/lambda.zip lambda.py scatter.py find ./bin/lambda.zip cd $(DEPLOY_PACKAGES_DIR) && rm -r * delete: aws --endpoint-url=http://localhost:4566 \ --region us-east-1 --profile localstack lambda delete-function \ --function-name=scatter-lambda create: aws lambda create-function \ --function-name=scatter-lambda \ --runtime=python3.9 \ --role=DummyRole \ --handler=lambda.lambda_handler \ --zip-file fileb://./bin/lambda.zip \ --region us-east-1 \ --endpoint-url=http://localhost:4566 update: aws lambda update-function-code \ --function-name=scatter-lambda \ --zip-file fileb://./bin/lambda.zip \ --region us-east-1 \ --endpoint-url=http://localhost:4566
上記と同等の内容のMakefileをdemo-segmet及びdemo-gatherにも作成してください。(function-nameとzipコマンド部のscatter.pyは適宜変更してください)
すべての関数内にMakefileを作成したらプロジェクトルートにもMakefileを作成します。
Makefile .PHONY: zip delete create update invoke log download stepfunction test json zip: cd demo-scatter && make -f Makefile zip --no-print-directory cd demo-segment && make -f Makefile zip --no-print-directory cd demo-gather && make -f Makefile zip --no-print-directory delete: cd demo-scatter && make -f Makefile delete --no-print-directory cd demo-segment && make -f Makefile delete --no-print-directory cd demo-gather && make -f Makefile delete --no-print-directory create: cd demo-scatter && make -f Makefile create --no-print-directory cd demo-segment && make -f Makefile create --no-print-directory cd demo-gather && make -f Makefile create --no-print-directory update: cd demo-scatter && make -f Makefile update --no-print-directory cd demo-segment && make -f Makefile update --no-print-directory cd demo-gather && make -f Makefile update --no-print-directory invoke: cd demo-scatter && make -f Makefile invoke-local --no-print-directory cd demo-segment && make -f Makefile invoke-local --no-print-directory cd demo-gather && make -f Makefile invoke-local --no-print-directory log : cd demo-scatter && make -f Makefile log --no-print-directory cd demo-segment && make -f Makefile log --no-print-directory cd demo-gather && make -f Makefile log --no-print-directory download: aws s3 --endpoint-url=http://localhost:4566 \ cp s3://test-bucket/ ./result --exclude "*" \ --include "*.xlsx" --recursive bucket: aws s3 mb s3://test-bucket \ --endpoint-url=http://localhost:4566 \ --profile localstack stepfunctions: aws stepfunctions create-state-machine \ --name Aggregate \ --definition file://state-machine/parallel.json \ --role-arn "arn:aws:iam::000000000000:role/DummyRole" \ --endpoint http://localhost:4566 aws stepfunctions start-execution \ --state-machine arn:aws:states:us-east-1:000000000000:stateMachine:Aggregate \ --endpoint http://localhost:4566 aws stepfunctions delete-state-machine \ --state-machine-arn "arn:aws:states:us-east-1:000000000000:stateMachine:Aggregate" \ --endpoint=http://localhost:4566 test : cd demo-scatter && make -f Makefile test --no-print-directory json: python utils/utils.py 1000
プロジェクトルートに配置するMakefileでは各プロジェクトフォルダで定義されたMakefileを利用しています。
zip化が完了していれば各ファルダのbinフォルダにlambda.zipが生成されているはずです。
Step Functionsの準備 Amazonステートメント言語 Step Functionsでは各種リソースのオーケストレーション(状態管理)JSON形式のファイルで行います。記事 をほぼそのまま転用させていただきました。eventに引数を渡すため一部追加しています。
parallel.json { "StartAt" : "ScatterLambda" , "States" : { "ScatterLambda" : { "Type" : "Task" , "Resource" : "arn:aws:lambda:us-east-1:000000000000:function:scatter-lambda" , "Parameters" : { "input_obj" : "test.json" } , "Next" : "ProcessAllSegments" } , "ProcessAllSegments" : { "Type" : "Map" , "InputPath" : "$.segment_definitions" , "ItemsPath" : "$" , "MaxConcurrency" : 200 , "Iterator" : { "StartAt" : "SegmentLambda" , "States" : { "SegmentLambda" : { "Type" : "Task" , "Resource" : "arn:aws:lambda:us-east-1:000000000000:function:segment-lambda" , "End" : true } } } , "ResultPath" : "$.segment_results" , "Next" : "GatherLambda" } , "GatherLambda" : { "Type" : "Task" , "InputPath" : "$" , "Resource" : "arn:aws:lambda:us-east-1:000000000000:function:gather-lambda" , "End" : true } } }
定義書の詳細については元記事 を参考にしてください。ここで注目していただきたいのはInputPathとResultPathです。ここに宣言したsegment_definitionsとsegment_resultsというパラメータをキーとして、次のLambdaに渡すデータをフィルタリングしています。
そのため、ScatterLambdaでの返り値はSegmentLambdaに渡したい配列のキーをsegment_definitionsとし、Gatherではsegment_resultsをキーに持つ要素を参照します。返り値はJSONにdumpする必要はなく、辞書型で値を渡します。
テストデータの準備 各Lambda関数のデプロイが完了し、ステートマシンの定義も完成しました。あとはStep Functionsの生成と実行をするだけです。
utils.py import datetimeimport jsonfrom random import randintimport boto3from fire import Firefrom mimesis import Personfrom mimesis.locales import Localeperson = Person(Locale.JA) def dummy_data (num: int ) -> dict : id = str (num).zfill(3 ) date = datetime.date(2021 , randint(1 , 12 ), randint(1 , 28 )).strftime("%Y-%m-%d" ) dummy_dict = { "会員番号" : id , "名前" : person.full_name(reverse=True ), "会員ランク" : randint(1 , 5 ), "ポイント" : randint(50 , 100 ), "タイムスタンプ" : date, } return dummy_dict def send_json (s3, sample_data: list , bucket: str , send: str ) -> str : with open ("utils/data/sample_data.json" , mode="wt" , encoding="utf-8" ) as f: json.dump(sample_data, f, ensure_ascii=False , indent=4 ) s3.put_object( Body=json.dumps(sample_data, ensure_ascii=False , indent=4 ), Bucket=bucket, Key=send, ) return send def make_dummy_data (k ) -> list : sample_data = [] for i in range (k): sample_data.append(dummy_data(i)) return sample_data def main (iterate_num: int ) -> str : endpoint = f"http://localhost:4566" s3 = boto3.client( service_name="s3" , endpoint_url=endpoint, aws_access_key_id="test" , aws_secret_access_key="test" , ) bucket = "test-bucket" send = "test.json" sample_data = make_dummy_data(iterate_num) send = send_json(s3, sample_data, bucket, send) return send if __name__ == "__main__" : Fire(main)
テストデータをLocalStack上のS3バケットに格納します。
これでLocalStackのS3バケット上にtest.jsonが作成されました。
Step Functionsの実行 それではStep Functiionsを実行します。
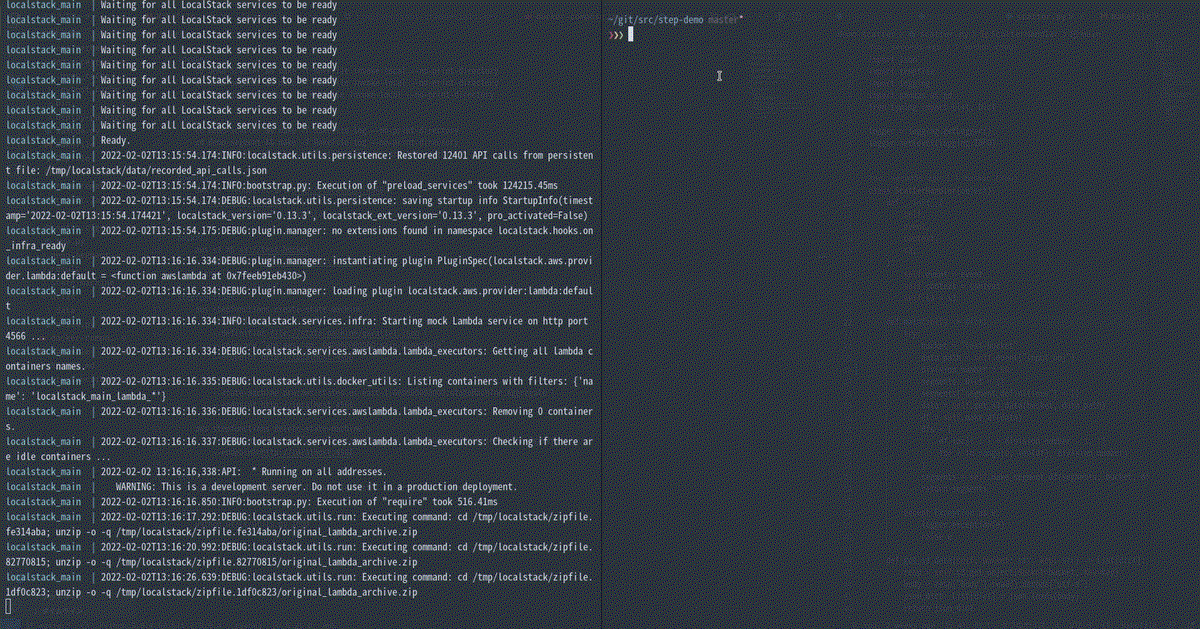
実行するとLocalStackのログで各Lambdaが処理を開始しているのを確認できます。segment_definitionsや、segment_resultsなども出力されていることがわかります。-dオプションを付けずに起動してください。dockcer-compose.ymlのDEBUGオプションを1とすることで画像のようにタスク定義なども確認できます。
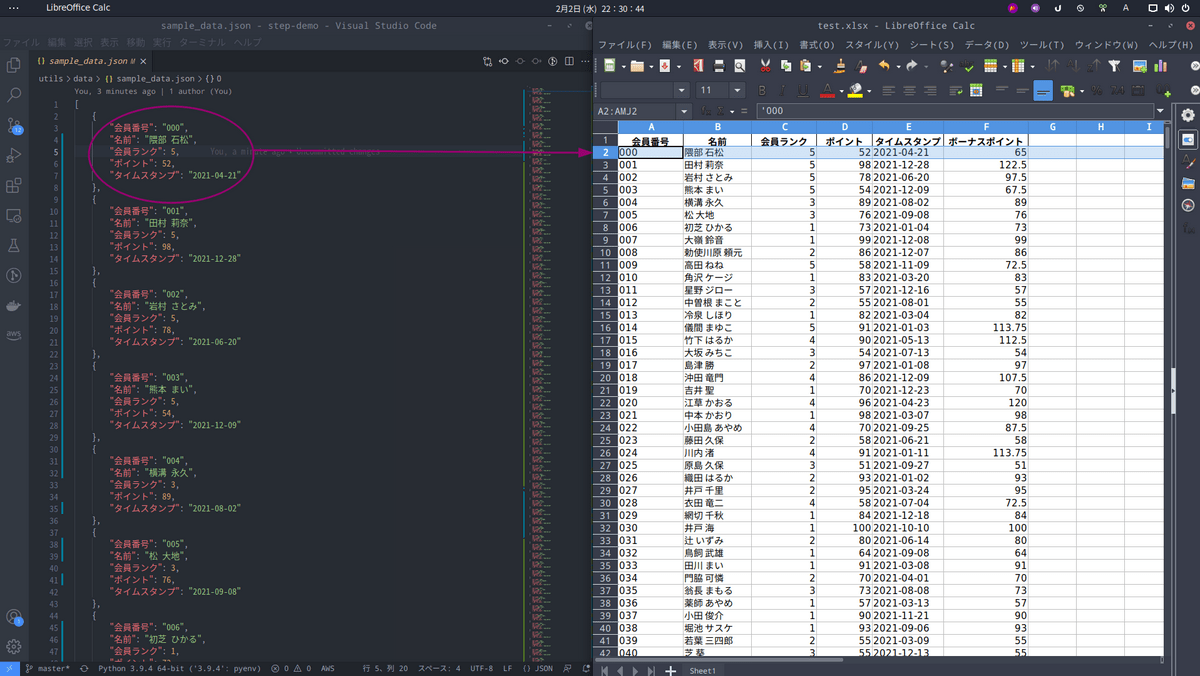
demo-gatherによってアップロードされたExcelファイルをローカルにダウンロードしましょう。
downloadに成功していればプロジェクトプロジェクトルート直下にresultフォルダが生成されtest.xlsxが生成されていると思います。
想定通りの出力が得られましたね🎉
それでは、今回はここまでとしたいと思います。
今回作成したスクリプトはこちらに格納してます。
https://github.com/orangekame3/stepfunctions-demo
さいごに いかがでしたでしょうか、Step Functionsでは性質上、複数のリソースを連動させて処理を行います。デバッグの都度リソースをデプロイをするのはかなりの労力を伴うのでローカル環境で動作確認を行えるのはとても良いですね。
今回はLambdaの並列実行でしたが、様々な用途に応用が期待できそうです。