はじめに
失敗談をテーマにした連載の3本目です。
TIG DXユニットの原です。21年度4月に新卒で入社し、2年目となります。
参加しているプロジェクトで、数百万件のデータを処理する機能を担当したことがありました。
本記事はその際の失敗と、その失敗から得た経験を共有するため、執筆しました。
内容のサマリ
- 本来フィールドで宣言すべき定数的に扱いたい変数を、関数内で毎回生成しreturnしてしまったので呼び出す度に毎回アロケートが発生し性能劣化してしまった
- Benchmark Test、Profiling、Escape Analysisでどのような挙動になってしまっていたか調べてみた
内容
本記事では、まずどのような状況であったかを説明し、どのような順番で問題を解決したかの順で説明します。
主にGoのテストとProfilingに関した内容です。
Goのテストについての関連記事として、Goのテストに入門してみよう!とGo 1.17のtesting新機能があります。
ぜひ確認ください!
問題状況
処理する数百件のデータについて、マスタ情報から情報を引き出す必要がありました。
その際に、マスタデータをDBに置いとくとDBへの接続が発生するため、map型でハードコーディングすることにしました。
そして、他の個所でマスタ情報の変更ができないようにGetterを作りました。
(Go言語では、map型はconstができないため、Getterにするしかありませんでした、、)
それで最初に作成したコードが下記のような感じです。
package master |
その結果、数百件のデータを処理するためには、数時間がかかる性能問題が発生しました。
問題箇所の特定
最初は、問題個所の特定ができなかったため、問題の箇所を特定するために、機能ごとのBenchmark Testを書くことにしました。
Benchmark Test
Go言語では、テスト作成の際に性能の観点でのテストができるBenchmark Testを提供しています。Benchmark Testは、*testing.Bの引数を持つBenchmarkで始まるテストメソッドを作ることで作成できます。
package master_test |
Benchmark Test Result
テストの実行は-benchオプションと-benchmemつけてテストを実行するだけでできます。
$ go test -v -bench . -benchmem playground/master |
上記のテスト結果を見ると、BenchmarkGetMasterを5713反復したら、平均的に207556 ns/opの実行速度と210712 B/op・1021 allocs/opのメモリアロケーションが発生していることが分かります。
ほかの機能と比較して、実行速度が顕著に遅かったため、マスタデータのGetterが性能問題の原因であると特定できました。そしてその原因は、想定外の大量のメモリアロケーションが発生しているからだと推測できます。
メモリアロケーションの原因特定
メモリアロケーションの原因を特定するためには、ProfilingとEscape Analysisを利用しました。
Profiling
Go言語では、標準的にProfiling機能提供しています。Profilingは-cpuprofileと-memprofileオプションを用いてできます。
Profiling Test Code
$ go test -v -cpuprofile cpu.prof -memprofile mem.prof -bench . -benchmem playground/master |
Profiling結果の確認
-cpuprofileでは、CPUの処理時間ベースのProfilingが、-memprofileメモリベースのProfilingができます。その結果はgo tool pprofコマンドで確認できます。
$ go tool pprof -http :8080 cpu.prof |
すると、下記のようにProfilingの結果を確認できます。
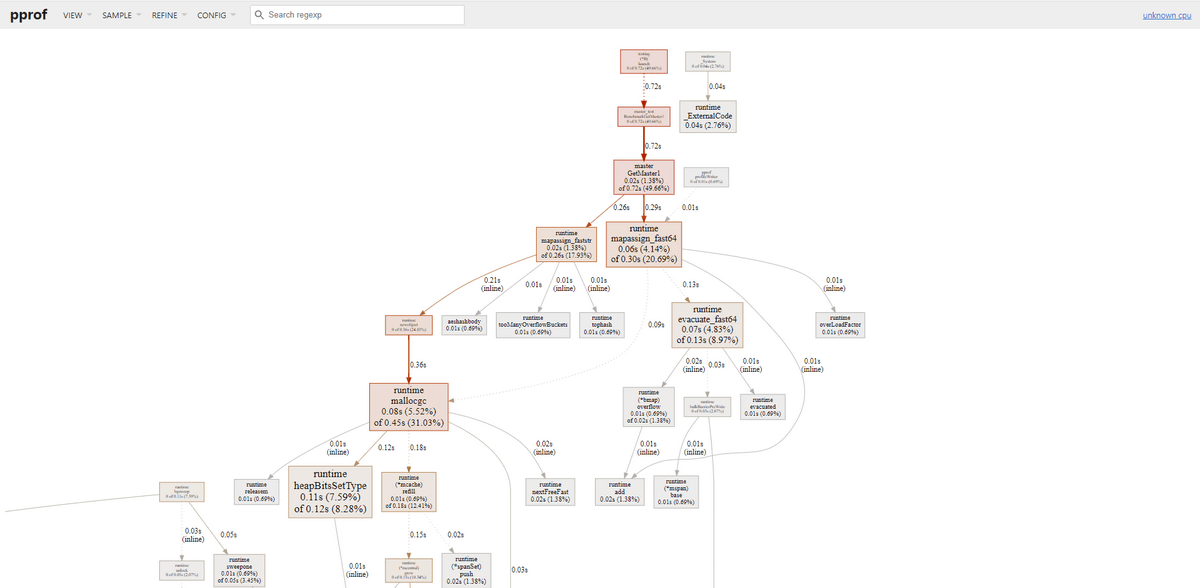
私が想像したのは、固定のmap型のデータを返すような単純な処理図を予測していましたが、ものすごく複雑な結果を得ました。
Escape Analysis
なんでこんなに複雑になったかを把握するため、Escape Analysisを適用してみました。Escape Analysisは、go buildする際に-gcflags '-m'オプションを追加することでできます。
$ go build -gcflags '-m' master/mater1.go |
その結果、GetterをするたびにHeapメモリにエスケープが発生していることが分かりました。すなわち、Getterが呼ばれるたびに、mapデータを作っていたわけです。
問題の解決
Getterが呼ばれるたびに、mapを生成することが問題であるため、mapデータをパッケージ変数として定義し、Getterではその変数を返すようにすることで、mapの再生成は抑えることができました。
その結果最初数時間かかる数百万件データの処理速度も、数十秒レベルで終わらせることができました。
package master |
もとの変数mが直接呼び出し元に渡るため、呼び出し元でmapを直接操作して書き換えると、全体に影響を受けます。これを避けるために、アクセスをキー指定必須にするといったことも検討できると思います。
// GetMaster2() は非公開のみとし、ID指定の関数のみパッケージエクスポートする |
今回の要件ですとマスタ(map)を駆動に処理をしたい処理があったこと。トレードオフはあるものの、書き換えはコードレビューで担保することとし、GetMaster2()方式で対処しました。
比較
Getterでmapデータを生成していたGetMaster1と、パッケージ変数を返しているGetMaster2を比較してみました。
GetMaster1とGetMaster2のBenchmark Test結果
その結果は明らかで、パッケージ変数を返しているGetMaster2ではメモリアロケーションが発生してなく、処理速度も数十万倍速くなりました。
$ go test -v -cpuprofile cpu.prof -memprofile mem.prof -bench . -benchmem playground/master |
グラフで比較すると下記のような感じです!
.png)
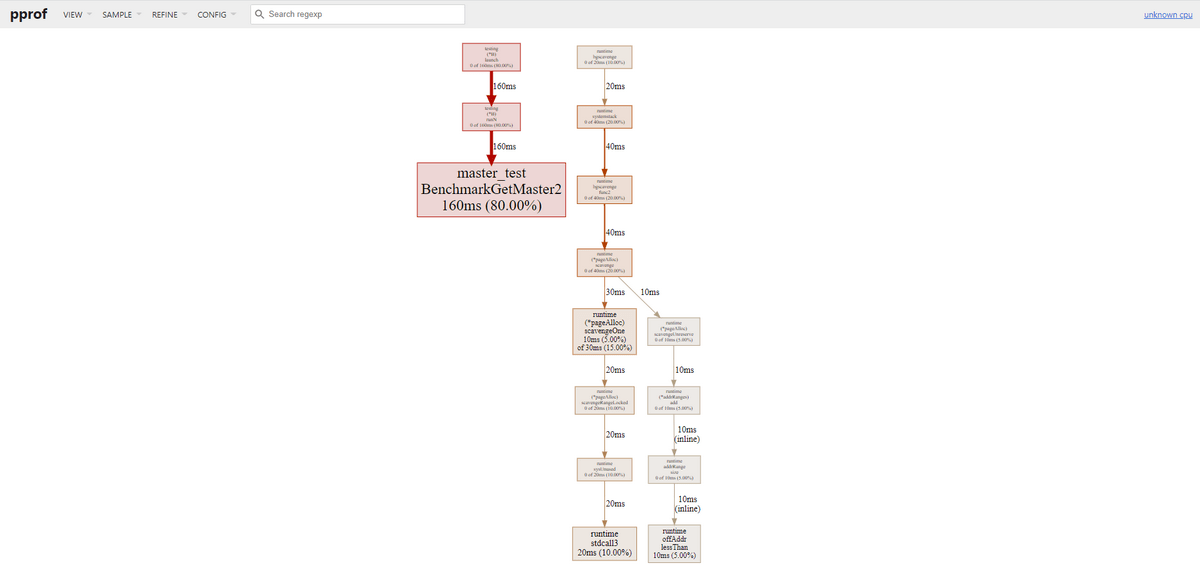
GetMaster2のProfiling結果
GetMaster1と比較してみると、ものすごく単純な処理図になっていることが確認できます。
さいごに
まとめると、Go言語ではmap型は基本Heapメモリにエスケープするため、使う際には注意が必要であるになります。
Go言語では、Benchmark TestやProfiling、Escape Analysisを使うことで性能問題の原因の調査ができるため、みなさまも性能問題に遭遇したらご活用してください!
次は藤井さんのRDSの自動再起動によるインフラコストの悲劇です。
参考リンク
- https://pkg.go.dev/cmd/go/internal/test
- Goのテストオプションに参考になる記事です
- https://go.dev/blog/pprof
- GoのProfilingに参考になる記事です
- https://segment.com/blog/allocation-efficiency-in-high-performance-go-services/
- Goのメモリアロケーションの理解に参考になる記事です
- https://hnakamur.github.io/blog/2018/01/30/go-heap-allocations/
- 上記の英語記事の日本語レビュー記事です
- https://medium.com/eureka-engineering/understanding-allocations-in-go-stack-heap-memory-9a2631b5035d
- HeapメモリとStackメモリの理解に参考になる記事です