
Real World HTTPでも紹介したネタですが、お仕事で受けている技術コンサル中に質問をいただいた時に、微妙に本で紹介した内容では少し足りなかったので、改めて整理のためにブログ記事にしてみました。次回、本が改訂されることがあればこのブログエントリーの内容も入れて加筆したいと思います。
Real World HTTPだとGoを使っていましたが、フロントとサーバーを同時にいじるので、本エントリーではNext.jsをサンプルに使います。Next.jsでプロジェクトを作って(npx create-next-app@latest –ts)、適当なプロジェクト名を入れてアプリケーションの雛形を作っておいてください。
Next.jsでは、1つのスクリプトファイルを作成すると、それがサーバーAPI(/pages/api以下)と、フロントの画面(/pages/以下のapi以外)になります。Next.jsは説明しないのでまったく未見の方はチュートリアルをやると良いですが、サーバーAPIでやっていることはGoとかJavaのSpringBootとかPythonとかRubyとかの通常のウェブサービス開発と変わらないことなので、何かしらの経験があれば雰囲気で読めると思います。フロントエンドのReactもHTMLのようなJSXなので、HTMLがわかればこちらも雰囲気で伝わるかと思います。
ファイルのダウンロードの基本
HTTPは「ハイパーテキスト転送プロトコル」の略ですが、ハイパーテキストというテキストファイルに限らず、さまざまなファイルの転送を請け負っています。みなさんは例えばオライリーのサイトで購入した実用Go言語の電子ブックのPDFファイルとか、さまざまなファイルを日々ダウンロードしてローカルに保存したりしていると思います。HTTPのプロトコル自体は、画面に表示されるファイルも、ダウンロードフォルダに保存されるファイルも、1つか2つのフィールドを除いては変化ありません。
Content-TypeContent-Disposition
また、それ以外にHTMLの<a>タグのdownload属性で制御する方法と、そのJavaScript版もあります。
サーバー: サーバーが返すContent-Typeフィールドがブラウザで表示対象外 or 未サポート
ブラウザは、ウィンドウ内でコンテンツを表示するかダウンロードにするかは、サーバーから送られてくる Content-Type フィールドに書かれたファイルの種別を見て判断します。最近のブラウザはPDFはインラインで表示してくれますが、Excelファイルなんかはダウンロードになります。Firefoxは設定に次のようなファイル種別ごとにダウンロードするか表示するかを持っています。
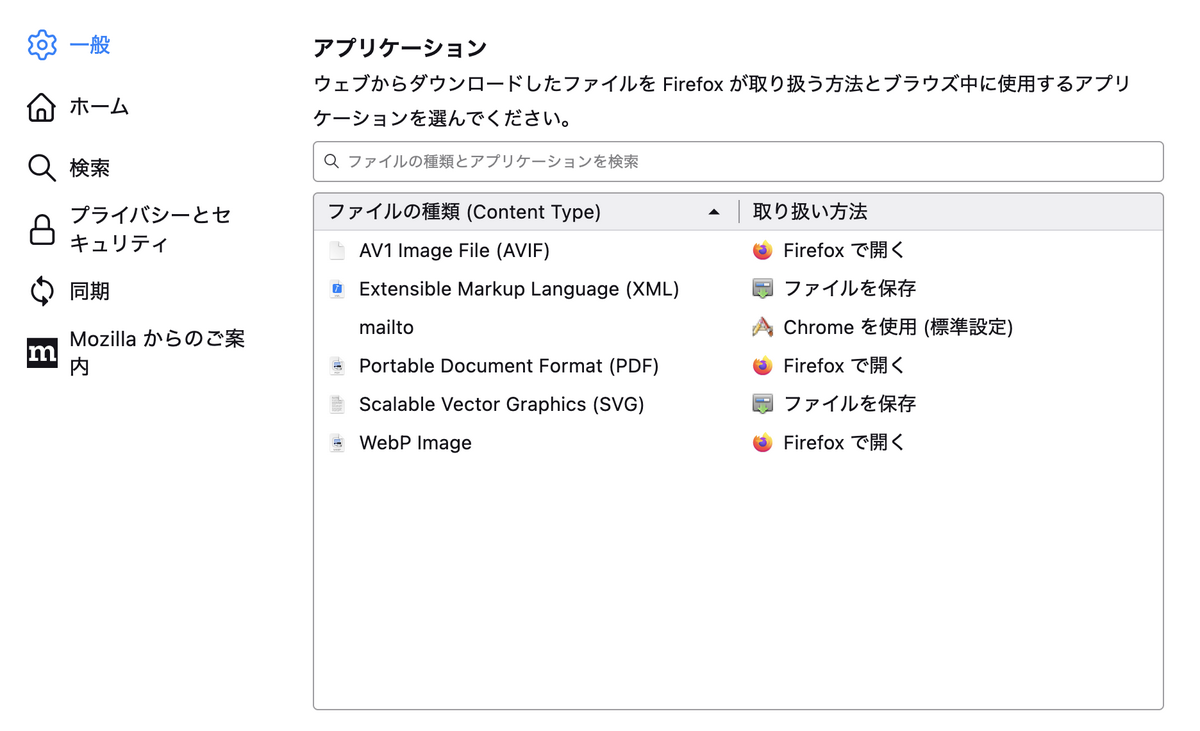
このようなリスト(ブラウザによって多少違うはず)にあって、インライン表示(ここではFirefoxで開く)の場合には表示しますし、ファイルを保存が指定されている、あるいはリストにない種類の場合は保存しようとします。
実験してみましょう。次は普通のHTMLのコンテンツを返すエンドポイントです。次のファイルを作って、ブラウザからhttp://localhost:3000/api/download にアクセスしてみましょう。
export default function download(req: NextApiRequest, res: NextApiResponse) { |
普通に表示されましたね? 実験で普通ではない絶対登録されてないContent-Typeを持たせてみると、ダウンロードになることがわかります。
export default function download(req: NextApiRequest, res: NextApiResponse) { |
サーバー: サーバーの返すContent-Dispositionフィールドで、ファイル保存指定されている
RFC-6266で定義されているのがContent-Dispositionフィールドです。これを使うと、サーバーの指示で、ブラウザの内部の表示設定を無視してダウンロードを強制させられます。また、ファイル保存時のファイル名を設定できます。MDNの説明がわかりやすいです。
Content-Disposition: inline |
MDNによると、inlineだとブラウザ内部に表示され、attachmentだとダイアログを出して保存される、filenameをつけると、それがダイアログのデフォルト値として入れられるブラウザが多い、と書かれています。ただし、ChromeやSafariは保存ダイアログは出さず、attachmentだけの場合はContent-Typeから類推される拡張子が勝手に付与され、filenameもつけるとその指定のファイル名で保存されるという感じでした。
先ほどのサンプルにContent-Dispositionヘッダーもつけて、MDNにあるように値を変えて試してみましょう。
export default function download(req: NextApiRequest, res: NextApiResponse) { |
なお、MDNのサンプルにはありませんが、inlineにfilenameをつけるのもRFCの文法説明的にはOKです。この場合、Chromeで試すと、ブラウザがインライン表示できるContent-Typeなら表示し、そうでなければ指定されたファイル名で保存する、という動作になっているように思います。
ブラウザ: <a>タグのdownload属性で制御する
次はフロントエンド側で制御する方法です。 先ほど作った、ダウンロードにならない普通のコンテンツを返すURL先のリソースを強制的にダウンロードにするするリンクをフロントエンドで作ります。<a>タグにdownload属性をつけるとブラウザは通常のコンテンツもブラウザで表示しないでダウンロードになります。
export default function ForceDownload() { |
もちろん、download属性がなくてもインライン表示ができないファイル形式など、サーバー側から返されるフィールドでダウンロードと判定されるとダウンロードになります。
ブラウザ: JavaScriptで強制ダウンロードを行わせる
上記のサンプルは<a>タグでしたが、確認ダイアログでOKを押して、権限をチェックしてからダウンロードするなど、ダウンロード開始の制御をフロントのスクリプトでやりたいこともあると思います。
その時に使える方法がJavaScriptで実行する方法ですが、やっていることは<a>タグを動的に作ってクリックを人為的に起こしてから終了しているだけなので、実質的にはHTML版の焼き直しでしかありません。簡単ですね。
import { useCallback } from "react" |
なお、hrefをいじればフロント側で動的に作ったコンテンツをダウンロードさせることも可能です。
anchor.href = URL.createObjectURL( |
実際にどれを使えば良いか?
いろいろ手法がありますが、どれを選択すべきかは要件しだいです。以下にあげる項目は、どれかひとつを排他的に選ぶものではありません。もしかしたら全部に合うかもしれないし、1つだけの場合もあります。どちらにしても、ここの組み合わせでかなりのニーズは説明できる気がしています。
絶対にダウンロードさせたい
サーバー側で動的に契約書のPDFを作って、ユーザー保存用として強制ダウンロードさせておきたい場合とかは、中途半端に中が見れてしまうと閲覧だけで満足してしまってダウンロードするのを忘れたり、そのために何度もPDF実行処理をサーバーが行わされたりするとうれしくないので、確実にダウンロードさせたい、みたいなケースがあると思います。
Content-Typeでダウンロードになるかどうかはブラウザの登録次第です。ユーザーが入れたブラウザ拡張機能でも変化する可能性があります。確実なのはContent-Dispositionを使う方法、あるいは、<a>タグのdownload属性を使う方法のどちらかですね。
S3のオブジェクトストレージに保存しているファイルを提供したいか否か
S3に保存しているファイルをユーザーにダウンロードさせるなら、おそらくはサーバー側のAPIでSigned URLを発行して、それをフロントに返し、ブラウザが直接S3からダウンロードとさせることが多いと思います。一旦サーバーを経由させるのも、単に帯域とCPUを無駄に消費するだけでSDGsじゃないですし。直接S3から返す方がいいですよね?
その場合、サーバーリクエストでダウンロード開始をフロントからサーバーに宣言し、サーバーAPIから帰ってきたURLをフロント側に戻し、フロント側でダウンロードを開始することになるため、JavaScriptを使ってダウンロードさせる手法を使うことになるでしょう。以下のサンプルは↓実際には動かしてないけどこんな感じでいけるかと。
export default async function downloadFromS3(req: NextApiRequest, res: NextApiResponse) { |
まずはこのAPIを呼んで、その結果帰ってくる URLからダウンロードします。
const download = useCallback(async function() { |
S3以外の、例えばRDBのBLOB型みたいなやつに保存しているデータを返すならサーバー側でContent-Dispositionヘッダーをつけて返すとかそういう感じになるかと思いますが、今時はS3なりCloud Storageなりのオブジェクトストレージを使う方が多いんじゃないか、という気はします。
添付ファイル閲覧機能をつけたい
ファイルのダウンロード機能というのは、ダウンロード以外させたくない場合以外に、ファイルアップロード機能があったときに確認用にユーザーにダウンロードして中身を見る機能の提供と2種類ユースケースがあると思います。確認用だと2つのフローがありえます。
- ブラウザが対応していて閲覧する場合はコンテンツ表示
- 対応しているなら、いちいちダウンロードして開き直すといった不要な手間は省きたい
- 新しいタブを開いてそこに表示したい。いちいち見た後に戻るをしたくない(スクロール位置がずれたり)し、間違って閉じちゃったら面倒なので。
- 対応していない場合はファイルダウンロード
- ダウンロードする場合は適切なファイル名を付与してほしい
ブラウザが対応しているかどうかはサーバーは知る由もないので、どちらにでも対応できるレスポンスを行う必要があります。
まず、強制ダウンロードではないがファイル名を指定する必要があるため、サーバーとしては次のフィールドをレスポンスにつけます。
Content-Disposition: inline; filename="filename.jpg" |
S3でSignedURLを発行するときは、多分こんな感じで上書き設定してあげれば良いはず。
const command = new GetObjectCommand({ |
つぎに、JavaScriptを使って開きますが、これも強制ではない&新しいタブを開いて表示なので、download属性の設定を外す代わりに、target属性を設定します。
const download = useCallback(function() { |
これでダウンロードしたいけどダウンロードしたくない、でもちょっとダウンロードしたい場合に対応可能です。
まとめ
まず、サーバーx2、ブラウザx2と、ダウンロードするかどうかを制御する方法を合計4つ紹介しました。
また、最後によくあるケースとして絶対にダウンロードさせたいとか、S3を使う場合とか、サーバー側のファイルを閲覧する(可能ならダウンロードフォルダからファイルを探していちいちローカルで開く手間は減らしたい)というケースについても紹介しました。
Real World HTTPで紹介していなかったのは、S3のSigned URL周りと、可能ならインラインで表示したいがもしダウンロードするならファイル名も指定したい、の2つでした。書籍の方は今後も、リアルな要件の裏で「どのようなHTTP通信が行われるのか」を明らかにしていく方向で進化させたいので、生々しい技術相談を仕事で受けるのは楽しいですね。趣味と実益を兼ねている。
画像はraphaelsilvaによるPixabayを利用しました。