はじめに
私が所属しているチームでは、ERDの管理およびDDL生成のために、A5:SQL Mk-2(以下A5M2)を利用しています。全員がそこまで使ったことがあるわけでなく、徐々にかゆいところに手が届く機能を知り利用してよかったと思っています。
そこで、開発を通して最初から知っていれば嬉しかったなという機能をまとめます。使いこなしているチーム(人)に確認したら全て当たり前に使っていたので、常識レベルらしいです。
なお、a5m2 ってどのような機能があるんだという方は、宮崎さんの A5:SQL Mk-2に回帰した話 を参照ください。また、SQLクライアントとして a5m2 を使う話はしません。余談ですが個人的にはSQLクライアントとしてはJetBrainsで特に有料製品を使っている方はDatabase Tools and SQLプラグインをおすすめしています。
共通列(システム共通カラム)
全テーブルに共通して付与したいカラムのことです。よく目にしそうなのが以下です。
- created_at: 作成日時
- created_by: 作成ユーザーID、作成プログラムID
- created_trace_id: 作成トレースID
- updated_at: 更新日時
- updated_by: 更新ユーザーID、更新プログラムID
- updated_trace_id: 作成トレースID
- revision: 更新番号
- delete_flg: 削除フラグ(※是非については要議論)
通常、運用観点から全テーブルに対して一律、横断的に付与させるため、個々のテーブル定義で設定するのは手間だし、管理の上でも省略したくなります。
a5m2 には共通列という機能が存在します。
「ER図タブ>共通列を表示」から設定します。
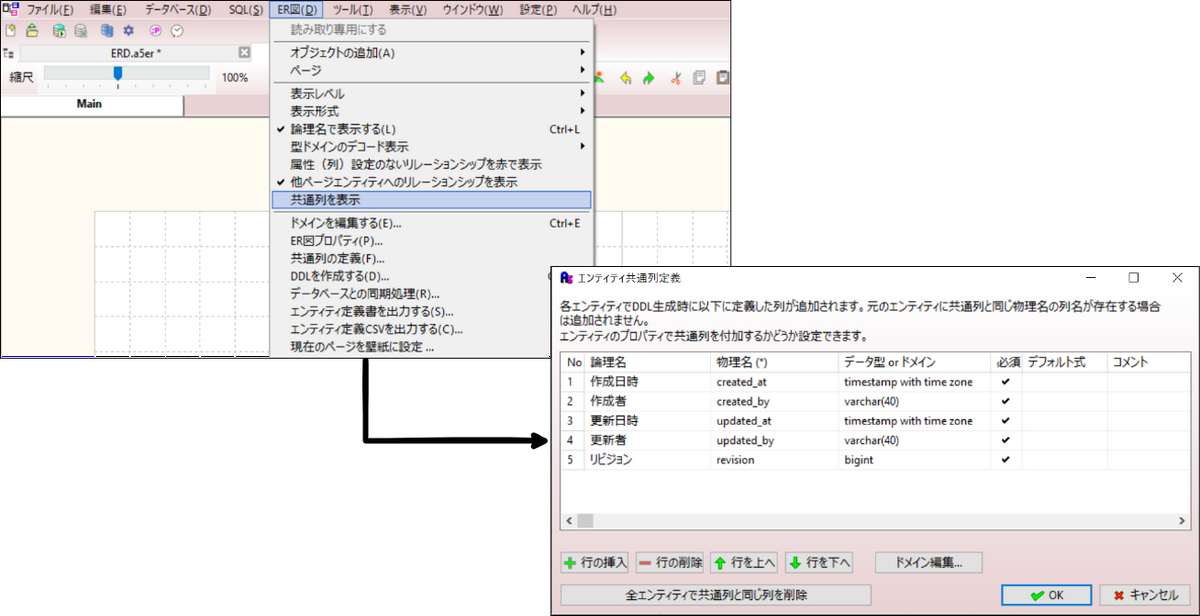
これにより全テーブルの一律設定が可能となります。
なお、共通列というだけあって、あるテーブルは追記オンリーである(更新がない)ため、updated_xx 系が不要にしたいといったことはできないです。その場合はa5m2のブックを分けるとか、DDLを生成した後に 何かしらのスクリプトで削除するといった作り込みになりそうです。
型ドメイン
公式ドキュメントにもしっかりと記載がある、型ドメインについてです。
テーブル数が増えてくると、同じデータが入るにもかかわらず、データ型の定義が揺れてしまうときが多々あります。
例えば以下のようなケースです。
- 論理的には同じ営業店コード VARCHAR(12) の体系で登録されるべきだが、名称は別のカラムが複数ある
- 移管先営業店コード、配送先営業店コードなど派生的な別名で登録する際に、誤ってVARCHAR(14)などと定義し揺れてしまう
こういった状況を防ぐために取られるのが 型ドメイン の機能です。基本的には個別で VARCHARやINTEGERなどを定義するのをやめ、全てドメイン定義で指定すると良いでしょう。
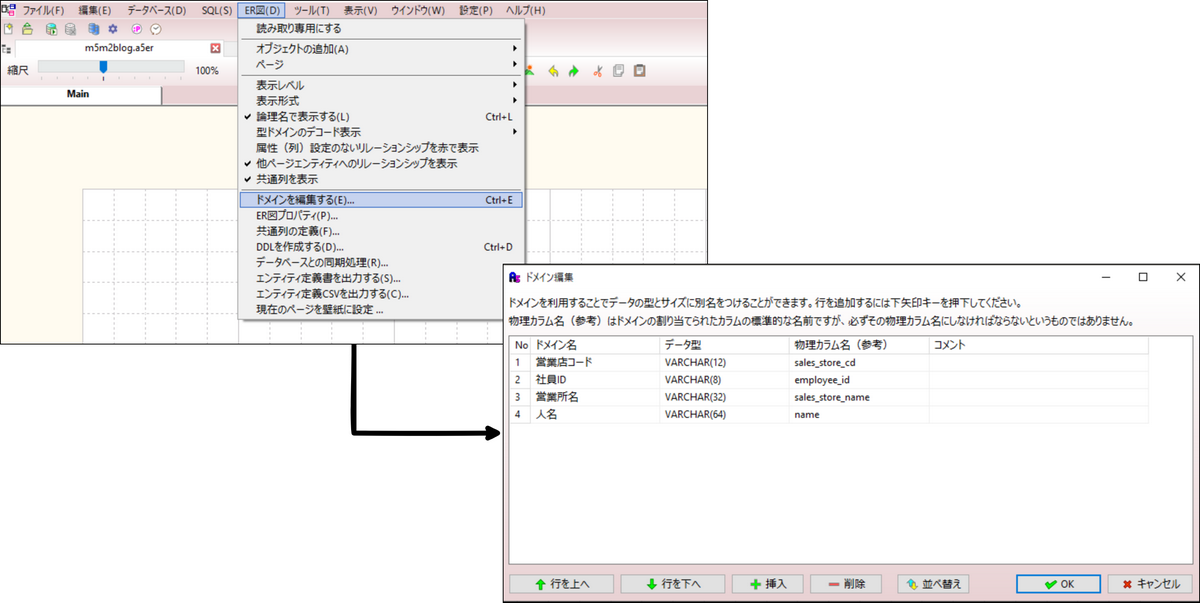
当然ですが、型ドメインで個別の方を指定すると、DDLなどの出力時には指定された型桁で置換されます。ERDの大枠を作成する人が最初にいかに整えられるかが鍵になるかなと思います。
型ドメインですが、どれくらい汎化して用いるかは少しコツが必要だと思います。個別の営業店コードといったレベル感でいくのか、実は支社・支店も同じコード体型で存在するよというのであれば、 「店コード」 といったより抽象的な型ドメインを適用スべきかもしれません。システムで扱いたいエンティティをよく見極めて設計すると良いかなと思います。
コマンドラインツール
a5m2を用いるとGUIからDDLを生成できますが、コマンドラインツールも整備されておりこちらもうまく活用できると、CIやローカルでのタスクランナーでの実行に便利です。
上記をインストールしてPATHを通すと、大体の自動化ができます。使い方ですが、 /Help でみると用意されているコマンドの説明が出てきますので助かります。
>A5M2cmd /Help |
DDLの出力ですが、例えば次のようなコマンドで可能です。
> A5M2cmd.exe /ERDDL /Encoding=UTF-8 /ERD=erd.a5er /OutFileName=ddl.sql |
出力の改行コードの設定はできないようなので、次のようなMakefileでカバーしたりしました。WSLで実行するイメージです(WSL側からWindows側のexeを叩くのがどうなんだというのはあります)。
ddl.sql: erd.a5er |
なお、コマンドラインツールですが、Wine/Macだと動かないという話もあり(私は未検証)、もし何か追加で手順が必要であれば教えてください。
他にも、ERDのPDFを生成したりします。PDFではなくPNGなどの画像ファイルを出力を自動化するのも良いかなと思います。
erd.png: erd.a5er |
まとめて generate タスクのようにしても良いかなと思います。
.PHONY : generate |
他にも、今回は割愛しますがSQLフォーマッタやImport/ExportなどもCLIで呼び出せます。この手のツールでコマンドラインを用意されているところが、痒いところに手が届いて素晴らしいのでぜひ活用していきましょう。
DDLオプション
例えばPostgreSQLにおけるパーティション設定をどこで設定するか、迷った方も多いのではないでしょうか(私です)。
こういったRDBMS固有の設定は、CREATE TABLEオプションに記載します。次の例は、注文テーブルに対して、注文日でRANGEパーティションを設定する例です。
.png)
これが設定されると次のようにDDL出力時に差し込まれます。シンプルな仕組みに感じますが、私の周辺ではこれが逆に良いんだという声が続出している拡張機能です。
create table order ( |
論物変換
型ドメインと類似ですが、同じ論理名なのに、物理名が揺れるケースがあります。よく見る例は次のようなケースです。
- 注文番号(order_number)と処理番号(process_num)のように、 number と num で揺れるケース
- 開始日、終了日が start, end または from, to で揺れるケース
- Xxx装置といったドメインで扱う名称が、 device と equipment で揺れるケース
a5m2において標準で論物管理するような機能は存在しません。
そこでサードパーティ製のツールですが、 future-architect/a5er-dictionary を用いると便利です(同僚の辻さんが開発してくれました)。 a5er-dictionary は論理名でカラムを指定すると、辞書をもとに物理名を自動で組み立ててくれる便利ツールです。
例えば、以下のような辞書を用意します。
ID,id |
これを用いて、各カラムの論理名から辞書を用いて、物理名を振り下ろすMakefileを用いると次のような感じで使えます。
|
これを実行すると、辞書が不完全であれば次のようなメッセージが出力されます。
$ make a5er-dictionary |
これは、「注文」に一致する「物理名」が無いため、論物変換できなかったということです。
その場合、次のようにdict.txt にレコードを追加していくことで、辞書自体を育てつつ論理名と物理名の揺れを防ぐ仕組みです。
注文,order |
注意ですが、論理名自体が揺れてしまうと意味がないの注意です(装置ID:equipment_id、デバイスID:device_idなど論理名で揺れると防ぎようが無いです)。
a5er-dictionary はまだ v0.2.0 であるため、不具合、ご要望などあればコメント貰えればです(こういったdict.txtの辞書自体も、オープン化したいですね)。
ERDレビュー
機能でもなんでも無いですが、a5m2 の良いところの1つに、定義ファイルがテキストファイルであるということです。
そのため、何かしらの修正が発生した場合にはGitHub上で差分を見てレビューできることは非常に良いです(もちろん ddl.sql を見てレビューでも良いと思いますが、本体側に予期せぬ変更が加えられていないか見れるのが良いです)。
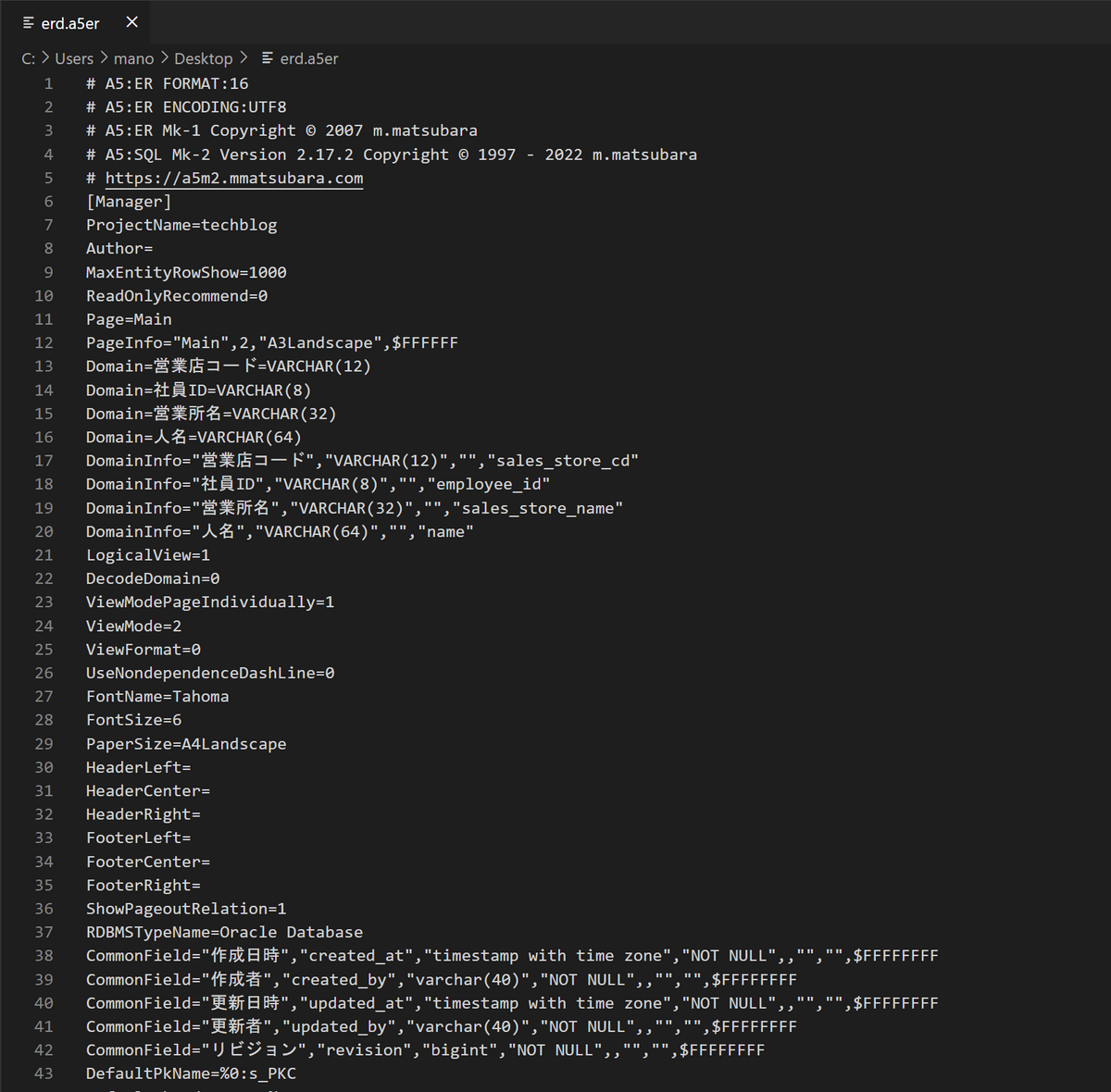
a5er 拡張子のファイルをエディタで開くとフラットな構造であることがわかり、Diffも取りやすいことが分かります。
その他
データモデリングのテーマからは外れますが、テスト用ダミーデータ作成 機能はかなり便利と私の周囲で評判です。なんというか痒いところに届く感じが凄いです。
まとめ
a5m2のデータモデリング周りの便利な機能、使い方を紹介しました。
個人的には開発者10人程度までであれば、今回のようなa5m2の機能を用いて十分に設計開発が進められると感じています。
もっと他にもこういった機能が便利だよというのがありましたら、Twitterなどでコメントを貰えると幸いです。