秋のブログ週間の9本目のエントリーになります。この企画もこんなに書く人が出てくるように育っていいですね。
「中間層を増やして柔軟性を高めるのがソフトウェアの歴史」
これは大学時代に2つ上の先輩が言っていた言葉です。例えばマシン語を直接書くのではなく、アセンブラで書けば、変換(コンパイル)の手間はかかりますが、他のCPUへの移植はしやすくなります。高級アセンブラと名高いC言語を使えばさらに移植性は上がります。C言語で書かれたVMを使う言語、例えばJava、Python、Rubyなんかはさらに移植性は上がります。
ストレージもそうです。最終的にストレージはビット列を保存するものですが、それにOSのファイルシステムというレイヤーがあり、そこにスキーマで管理されたデータを入れるDBMSが乗っかり、SQLなどの問い合わせ言語でデータ取得できるようにします。DBMSを挟むことで、レプリケーションでバックアップを勝手に別マシンに取ってくれたり、複数のマシンを透過的に扱い、1台のマシンに収まらないデータを透過的に扱うことができるパーティショニングといった機能が得られます。
ウェブのフロントエンドもリッチ化の流れでどんどん高機能に、そしてバンドルされる.jsファイルのサイズもどんどん大きくなってきました。ウェブフロントエンドでは、DHTMLと呼ばれた時代、prototype.js、jQueryの時代から徐々にリッチにデスクトップGUI的な思想で重厚な開発が行われるようになり、Knockout.js、Backbone.jsとMustacheなどのテンプレートエンジンを使ったMVCがしばらく行われていました。データ保持のレイヤーと表示のレイヤーをきちんと用意する、通信とチェックなどのビジネス知識の層を分けるなどです。Angularもコンポーネントとサービスというレイヤー分けの仕組みがありますし、Vue.jsや Reactでも、ストアを用意する使い方をみんなしていました。ストアを使うと、Reduxがモデル層、Reactがビューというレイヤー分けとなります。
時々起きる中間層を壊すムーブメント
とはいえ、中間層を増やしていくコストはゼロではありません。MS-DOS時代にちょっとコンソールに色付けする2桁バイトのバイナリを作ったことがありますが、Cを使えばそのサイズでは収まりませんし、PythonやRubyはCと比べてどうしても速度ではかないません。
そのため、時々中間層を壊すイノベーションが起きています。イノベーションのジレンマの文脈で説明すると、中間層を足すことは、より複雑に、より便利に、より遅い方向への持続的イノベーションの進化ですが、中間層の破壊は、より単機能で、より手軽に、より速く、さらに新しい価値観が付与された方向への破壊的イノベーションです。例えば、JITは高級言語の「便利だが遅くて重い」インタプリタという層を破壊してC言語やアセンブラといった言語で作られる世界へのポータルを作るものです。
ウェブフロントエンドも近年は層を破壊する方向に進歩しています。モデルのレイヤーをブラウザ上で作り上げてビューがそれを使うという方向性だったのが、GraphQLやSWRといったデータアクセスライブラリが登場してきました。これらのライブラリが実現する世界は、サーバー側である程度フロントが期待するレスポンスを返し、それをそのままフロントエンドが表示に利用するということで、ブラウザ上でのモデル層がなくなり、ブラウザはビューとコントローラのみ、モデルはサーバー上にあり、そのキャッシュがブラウザ上にもある、という状態になります。
JavaScriptはES4でクラスを入れるので大騒ぎし、ES6でようやくクラスを導入しました。ES3→6ではJavaやPythonをお手本にJavaScriptがリッチな言語へと進化しましたが、その苦労の末入ったクラスは、現在ではあまり使われていません。Angularはクラスを使いますが、Reactはクラスベースのコンポーネントから関数を使ったコンポーネントが主流になりました。Vue.jsも一時期クラス形式がありましたが、Vue3になったときにクラスAPIのメンテナーがコアメンバーから外れました。
現在主流なのはオブジェクトや配列など、言語標準のデータをそのまま使います。クラスのようなSetter/Getterといったアクセッサで正しい状態を保証するという考えはウェブフロントエンドでは完全に過去のものです。Reduxでは前の状態をもとに、新しい状態を新規に作るという動きになり、関数型チックに状態を扱います。しかし、Redux-ToolkitではImmer.jsを使い、それと同じような処理を、直接値を書き換えるようにコーディングできます。なんか時代が巻き戻っているような書き心地です。
もう1つのムーブメントはTypeScriptです。Facebook(現Meta)のFlowもありましたが、これは型情報を外から与えるものです。JavaScriptの「直接オブジェクトや配列を使う」使い方に合わせて、かなりマニアックな型定義もできるようになっています。これで直接いじるにしても想定外の型を入れようとすればコンパイラで検知できます。
中間層を壊すといっても、完全に過去に作られたものが消えるわけではなく、「あたかもなかったかのように振る舞う透明な層」に化けるという感じですね。仮想DOMにしても、SWRやGraphQLにしても、Immer.jsにしても、TypeScriptにしても。TypeScriptの前にはAltJSブームがありましたが、覇権を握ったのはBabelでした。これもリッチな言語を作るのではなく、リッチな文法を使ってJSを書いたら、ポータビリティの高いJSに書き換えますよ、というのもこれに近い思想かな、と思います。CSSのprefixerとかもですね。
中間層がなくなることで、隠される対象の底レイヤーだったDOMを開発者が意識して書くことになり、本来のセマンティクスや、アクセサビリティを大事にしよう、というところに業界全体が向かっている気がします。
クラウドネイティブとデータ中心アプローチの未来
僕がフューチャーに入って学びたいと思っているのがデータベースをしっかり使う開発です。まあ、まだあまりその機会には恵まれてはいませんが・・・フューチャーではデータベースを第一に設計を固めようという開発を行います。ソフトウェア開発の試験だとオブジェクト指向と並んで紹介されるのがデータ中心アプローチです。しかし、本屋に行くと、データ中心アプローチ(DOA)を解説した本はほとんどありません。まあ、といってもオブジェクト指向も新しい本は出ておらず、ここ15年ぐらいは設計の本は不作の時代ですし、出版社がいくつか技術書から撤退したり、ということもあって過去の本も手に入らなくなっています。
しかし、この今やオープンには学べないDOAは、実はいわゆるSIerではしっかりと生きています。フューチャーはSIerではなくてITコンサルである、というのが会社の公式見解ですが、実装までやるのでSIerを内包しています。社内ポータルには動画やスライドやらのDBの教育コンテンツなどが充実しています。最近は時間を見つけて学習しています。
最近はいろいろクラウドの時代になっていますが、いろいろやっていると、データベース設計力が大事だな、と思うことが多くなってきました。たとえば、Firebaseはウェブフロントエンドから直接データストアにクエリーを投げられます。先ほど、ウェブフロントエンドはモデル層をサーバー側に持っていこうとしていると紹介しましたが、その場合、Firebase側でフロントエンドから使いやすいデータ構造が実現できればばっちりアプリ開発が決まる、ということです。例えばデータベースはアドホックに設計していき、BFFのような層を作ってフロントに優しいデータに変換するとなると、一層増えてしまうためにバックエンドレスにできるFirebaseのメリットが減ってしまいます。
DOAのツールとしてはそのようなデータ構造のためのERDという設計のツールがありますが、もう1つはDFDがあります。これもクラウドネイティブ時代にはかなり役立つツールなのではないかと思っています。DFDでは、データストアとプロセスを線で繋げた図です。処理の流れではなくてデータの流れを表現するものです。クラウドネイティブな大規模アプリケーションだと、LambdaなどのFaaSがトリガーなどで起動されたりと、「ピタゴラスイッチ」として表現されることが多いのですが、コンテナで実現されたアプリやFaaSといったサーバーレスでは、アプリが状態を持たない「関数」的な部品になります。各種ストレージやPub/Subはデータストアとして扱うと、DFDはサーバーレスのアプリケーションの設計に最適なツールなんじゃないかと思っています。クラウドサービスを並べたブロック図をよく見かけますが、あれを物理設計とすると、ネットワーク系のサービスを抜いて、compute系とストレージ系だけを並べたような図となり、論理設計的になるかと思います。
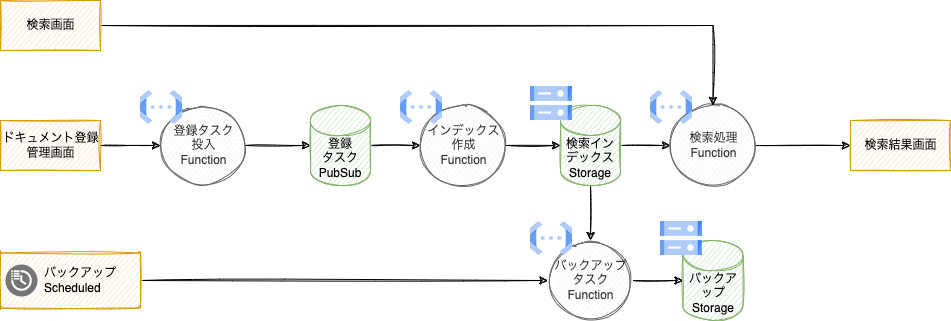
CRUD表も、現代のクラウドデータベースのパフォーマンス問題を洗い出すときに役にたつという話も聞きます。どでかいデータを持つテーブルに大量データをスキャンするようなクエリーを投げていると問題になりがちなので、テーブルに対してだれが処理を投げているかがわかれば、だいたい当たりはつきますしね。
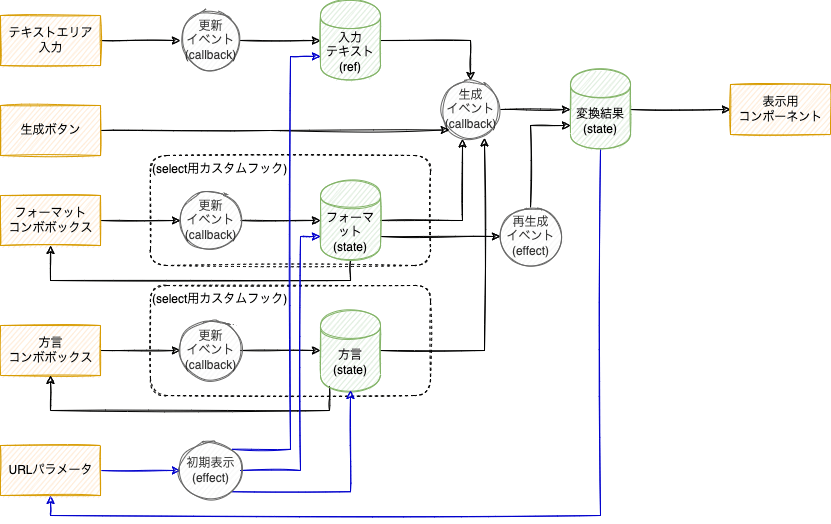
あと、余談ですが、 ReactアプリケーションのuseEffectとuseStateの連鎖も、DFDで表現すると綺麗にいけるんじゃないかな、というのも最近ぼんやり考えているところです。あとで紹介するSQL生成ツールはウェブインターフェイスをReactで作ったのですが、そのフックの関係をDFDで図示するとこんな感じです。useState/useRefのストアと、useCallback/useEffectのプロセスで表現できますね。テキスト入力はuncontrolled、コンボボックスはcontrolled、青線は生成したデータをURLに反映してシェアできる仕組み・・・みたいにうまく設計情報が反映できていますよね?
そろそろSQL嫌いを卒業する時期が来たのではないか
僕自身はMongoDBだったりの案件が多く、RDBを直接扱う経験は数えるほどしかなく、経験値が足りないな、というのは実感していました。アプリ作るときもO/Rマッパーを使ったりもしていましたが、どうも動きが気に入らなくて、直接コントロールしたいな、と思うことの方が増えてきています。
かつては(20年ぐらい前)はスケールアウトのようなものが一般的ではなく、CPU数に応じたライセンス料がかかるDBMSを使うことが多かったと思います。元オラクルの人から聞いたのですが、当時はソート処理など、アプリ側でもできる処理は貴重なサーバーリソースを節約するために非推奨というのがベストプラクティスとされていたそうです。しかし、近年はスケールアウトが組み込まれたマネージドなDBMSが増えてきて、フューチャーの案件でも当たり前のように選択されています。クエリー処理でCPUリソースが足りない、という時代ではなくなっています(帯域や書き込み性能は足りないということは聞きますが)。N+1問題も、本来はSQLを書けば解決する問題を、SQLを避けるために発生してしまっている問題といえます。
DBを直接扱わない理由としてはDBMSを切り替えてもアプリケーションの書き換えが不要にするという20年ぐらい前のエンタープライズアーキテクチャ的な思想もあると思います。しかし、実稼働すると、アプリケーションよりもデータベース、その特定のバージョンのデータベースよりも中のデータの方が寿命が長くなることはざらです。そもそも現代においては高額なライセンスは本番環境だけで、ローカルはH2を使う、みたいなことをする必要は少なく、本番はAWS Auroraで、ローカルはPostgreSQLで、と言った感じの開発をしているところがほとんどでしょう。もはやDB依存を毛嫌いする時代ではなくなってきていると思います。
また、データサイエンティストを中心に、SQLを使ってデータ分析をしようという本はたくさん出ていますし、SQLは当たり前の道具になってきています。開発者もSQLを書ける方が良いですよね。また、データ保持部分と、加工部分が別のサーバーにあると、毎度転送するコストが発生します。それに対して、安いノードをたくさん並べてデータを持つノードにバイトコードにした処理を投げつけて並列処理させるという方式も使われています。Apache Sparkで使われるようになった処理方式ですが、ビッグデータを扱う人がSQLを使うのも、このネットワークコストを削減するためでしょう。これも、DBサーバーにおけるコスト構造の変化に対する連続的な進化の流れに見えます。
最近いろいろチャレンジしているもの
僕自身、SQLと向かい合ってこなかったので、最近はいろいろチャレンジしながらDBやSQLとの距離を縮めようとしているところです。あと、ウェブフロントエンドとかのツール群と比べると、もうちょっとスモールステップで作業を勧められるようなものがあったらいいなと思ってツールを作ったりしています。
例えば、僕が最近作っているのが、箇条書きでざっと書いたテーブル情報から、DDLやらERDを作るツールです。概念設計やら論理設計あたりで使えたら便利かなって。論物変換(日本だと日本語の名前から実際に使うシンボル名への変換)とかも乗せたいな、と思っているところです。
https://shibukawa.github.io/md2sql/
テーブル構造が決まり、インデックスを貼る場所が決まればクエリーはある程度自動生成できそうです。データ量が少ないことがわかっているテーブル以外は、インデックス以外で検索することはないはずですからね。
もう1つはtwowaysql周りです。
https://future-architect.github.io/articles/20220531a/
SQLは直接テストされることがなく、だいたいそれをラップしたリポジトリ層を使ってテストしたりします。SQLを直接テストできれば便利かな、と思い、twowaysqlにCLIツールを追加し、テストケースをYAMLで書いてテストできるようなテストランナーを実装してみました。十分にテストされた信頼されたSQLがあればレイヤードアーキテクチャのリポジトリ層っていらなくなって、プログラムをさらにシンプルにできるんじゃないかと思っているところです。
フロントエンドで関数型とかを意識する時代、OOPですべて統一する時代はもう過去のものと考えれば、バックエンドコードにSQLがいてもいいですよね? Goの場合は、だいたい他の言語経験者がO/Rマッパを探してgormを触って絶望する、というのが「あーあ、またか」という感じでよく発生しますが、最近はsqlcやsqlxなど、SQLを書ける前提の良いライブラリが増えていますし、不便になることはありません。O/Rマッパーはオブジェクトのマッピングと、クエリービルダーで構成されますが、前者の構造体へのマッピングさえあれば十分かと思います。
ウェブフロントエンドではBabelやらCSSのprefixerがありましたが、 SQLも便利方言を吸収してくれるものはなんか欲しいですよね。::typeでキャストできるPostgreSQLの記法をCAST()という標準SQLに直してくれるようなやつとか、欲しいですよね。いつか作りたい。
まとめ
ぼんやりと考えてきたことを紹介してきました。
- 中間層をなくす進化というものが最近は多くなってきている。
- クラウドネイティブな開発をスムーズに行うためには古のDOAが役に立つのではないか
- O/Rマッパーも技術の進歩とベクトルが合わないもので、将来なくなるべきものと考えている
自分で作っているツールはどれもまだ未熟だし、構想段階のものもありますが、ツールを作りながら自分なりの開発スタイルを磨いていきたいなと思っています。
今の仕事をしているとお客さんから「こんな新しいアーキテクチャは他のベンダーから提案されたことがなかった」と言われたりもするのですが、DOAを使っているSIerが本気でクラウドネイティブに取り組むと、ものすごいポテンシャルを発揮できるんじゃないかな、というのも将来期待しているところです。