
はじめに
TIG (Technology Innovation Group)の市川です。
春の入門祭り4日目の記事です。
本日の入門記事は「Cloud Data Fusionで始めるETL入門」ということで、Google CloudでETL/ELTを構築できる「Cloud Data Fusion」を利用して、ETLを作成します。
ETLとは
そもそもETLとはなんでしょうか。
ETLはExtract Transform Loadの略で、データ分析のプロセスの中で重要な役割を果たしています。
データ分析は一般的には、「収集」「加工」「蓄積」「利活用」の順序で行われます。
| プロセス | 内容 | 利用する主なサービス |
|---|---|---|
| 収集 | 企業が保有するさまざまなデータソース(主にRAWデータ)をデータレイクに格納 | Cloud Stoarge, S3 等 |
| 加工 | データレイクに格納されているデータのクレンジング、整形、および変換を行い、ビジネス上有用な情報を得るためのデータを生成する | Cloud Data Fusion, Dataflow 等 |
| 蓄積 | 加工されたデータをデータウェアハウス(DWH)に格納する | BigQuery, Redshift 等 |
| 利活用 | DWHのデータを利用してBIから参照したり、マーケティング等に利用する。 | 各種MAツール |
この流れの中で、ETLを利用するのは「加工」のフェーズです。
「収集」フェーズでデータレイクに格納されたRAWデータを、データウェアハウスにETLでに取り込みやすいようデータを加工します。
Cloud Data Fusionとは何か
Cloud Data FusionはGoogle Cloudが提供しているETL/ELTを行うためのサービスです。
特徴は以下の通りです。
- OSSのCDAPを使って構築されたサーバーレスかつフルマネージドなサービスを提供
- 視覚的に操作できるGUIでエンジニアでなくてもデータ加工パイプラインが作成できる
- プラグインが豊富に用意されていて、拡張性が高い
Google Cloudでは、ETLツールとしてDataflowやDataprep、Dataform等多くのサービスが提供されていますが、Dataflowは基本的にコーディングが必要であるためエンジニアがいないと構築が難しかったりします。
Cloud Data FusionはGUIベースでETL/ELT処理を作成できるため、普段開発作業を担当しないような方にもとっつきやすく、プラグインが豊富なので拡張性が高いのが他のサービスと異なる特徴です。
簡単なパイプラインを作ってみよう
それでは、早速簡単なパイプラインを作ってみましょう。
セットアップ
セットアップ方法はGoogle Cloudのドキュメントをご参照ください。
https://cloud.google.com/data-fusion/docs/how-to/create-instance?hl=ja
注意点
CLoud Data Fusionは少しデプロイに時間がかかり、大体立ち上がるまでに20分~30分ほどかかります。
また、Cloud Data Fusionでは3つのエディションが展開されていますが、使用感を試してみたい程度であれば月120時間の無料枠が用意されている「Basic」を選ぶと費用が抑えられると思います(Developer Editionには無料枠が存在しないため)
参考:https://cloud.google.com/data-fusion/pricing?hl=ja
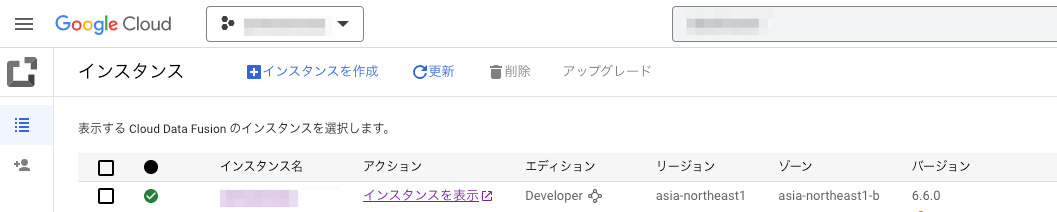
以下のようにインスタンスが立ち上がったら準備完了です。
パイプラインを作ってみる
今回は入門編ということで、すでに用意されているパイプラインを利用したいと思います。
コンソール画面から「インスタンスを表示」をクリックし、Cloud Data Fusionの画面にアクセスし、ヘッダーの「HUB」をクリックします
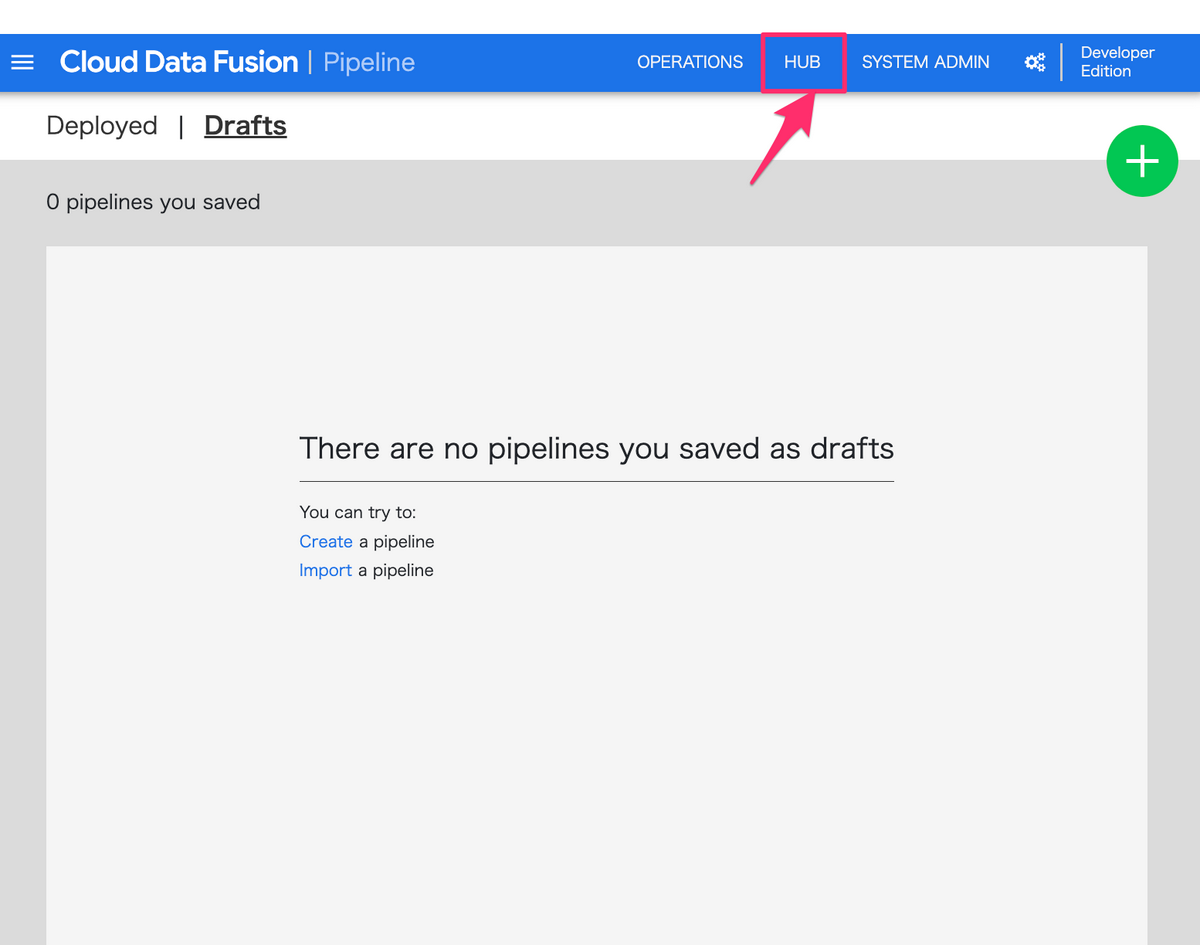
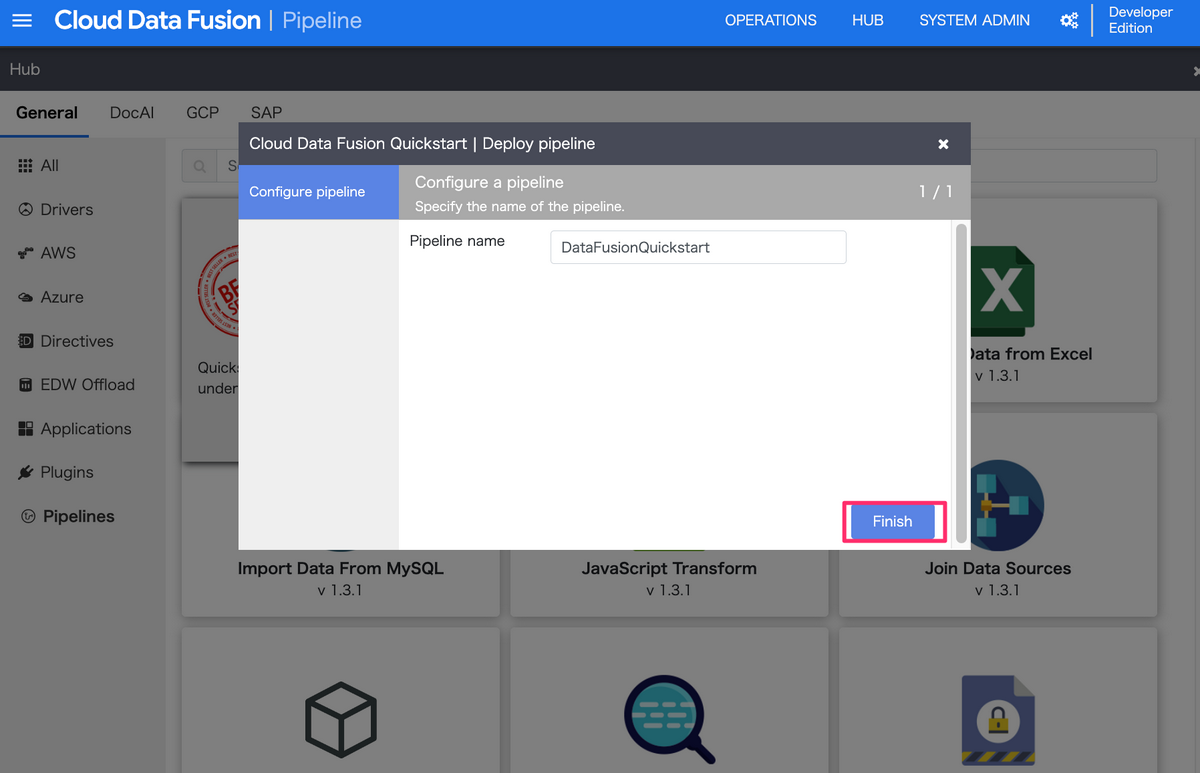
その後、「Pipelines」の「Cloud Data Fusion Quickstart」をクリックし、

Finishを押下して、パイプラインを作成します。
すると、以下のような画面にアクセスできるようになります。
この画面はPipelineのStudioの画面で、GUI形式でパイプラインを作成/編集できます。
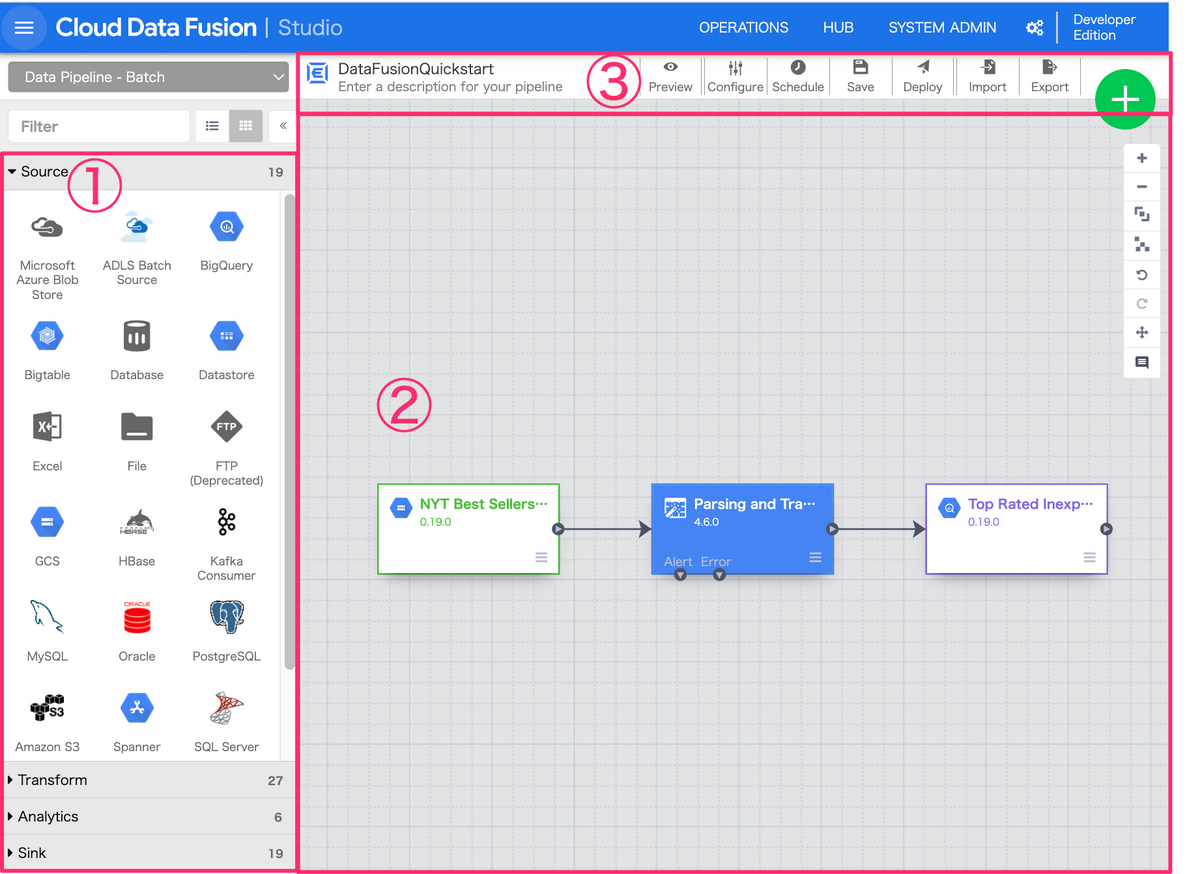
Studio画面の構成を大きく3つに分けて説明します。
(1)ノードに使うプラグインを選択
サイドバーにはData Fusionで利用できるプラグインを選択し、利用できます。
プラグインは大きく分けて、以下のような種類が用意されています。
- Source: 起点となるデータソースを指定するプラグイン
- Transform・Analytics:各種データ変換を行うプラグイン
- Sink:データの流れの終端として、データの格納先を指定するプラグイン
- Conditions and Actions:データ変換とは関係ない何らかのアクション(ファイル移動や削除 等)を行えるプラグイン
- Error Handlers and Alerts:エラーハンドリングを行うプラグイン
(2)Studio
メインとなるStudioでパイプラインを組み立てます。
- パイプラインの編集エリア。
- 1つ1つの箱が、データソースや変換処理、データの格納先を示す”ノード”であり、実行順に線で繋がっている。
- ノードは上述したプラグインの種別ごとに色分けされている
(3)各種設定
ここでは、作成したパイプラインの設定やデプロイを行うことができます。
- パイプライン定義をJSON形式でImport&Export
- プレビュー(テスト)の実行メニューを開く
- 編集中のパイプラインをDraftとして保存
- Draftのパイプラインをデプロイ
各ノードの処理内容
GCSからファイルを読み込み
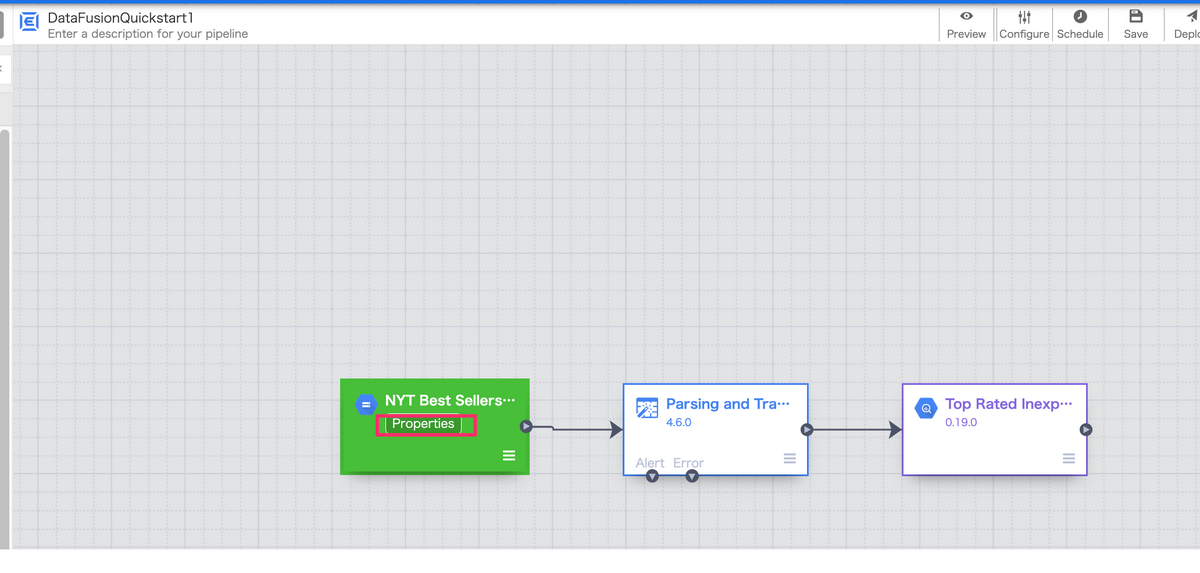
各ノードの設定内容を確認する際は、マウスオーバーした際に表示される「Properties」をクリックして内容を確認します。
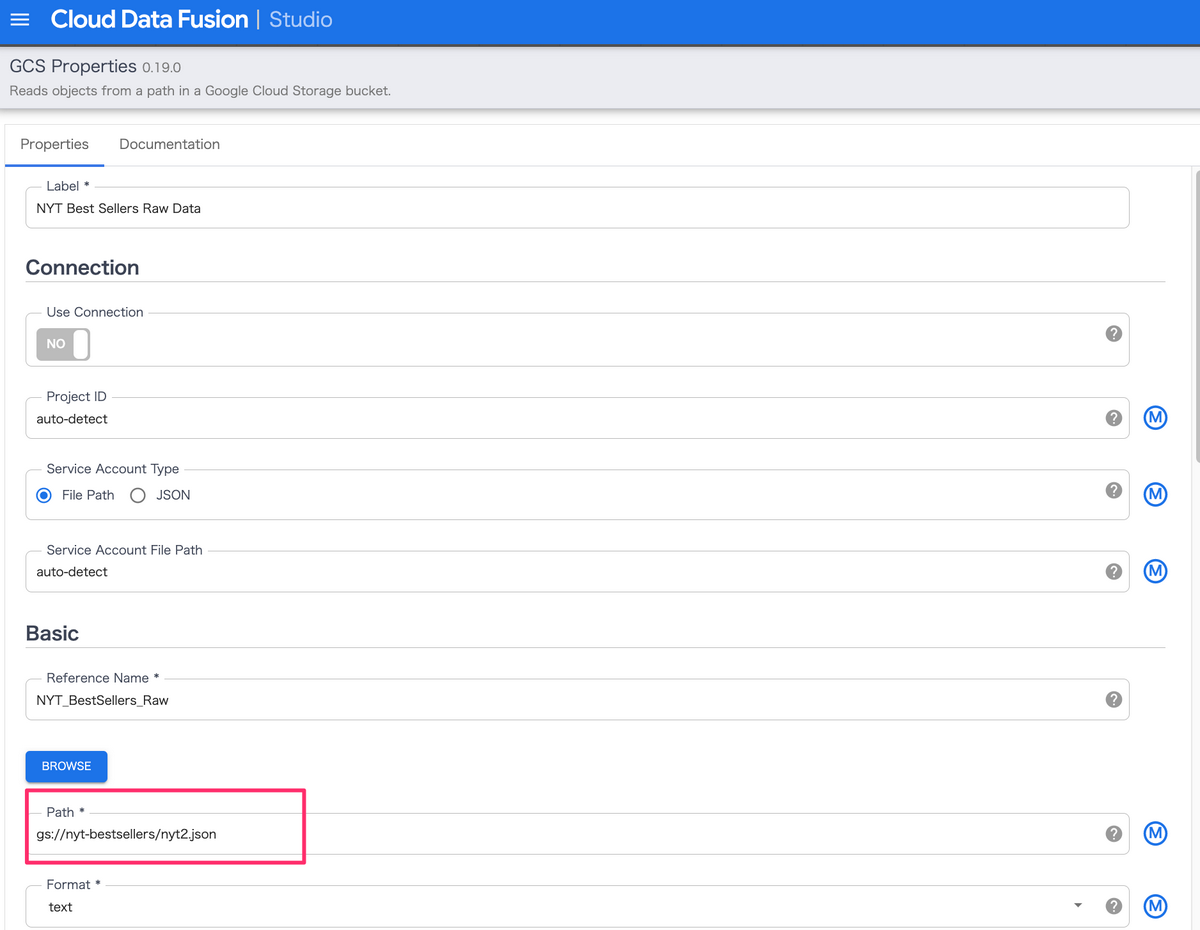
GCS Propertiesをクリックすると以下のような画面が表示されます。
以下のパス」部分でGCSのオブジェクトを指定しています。
(デフォルトで設定されているファイルはサンプルファイルとして公開されているため、動かす上で変更の必要はありません)
データ加工
データ加工は主に、Wranglerと呼ばれるプラグインで行います。
Wranglerでは、記載されたDirectivesを元にデータ加工を行います。
(個人的にこれがCloud Data Fusionの一番便利な機能だと思っています)。
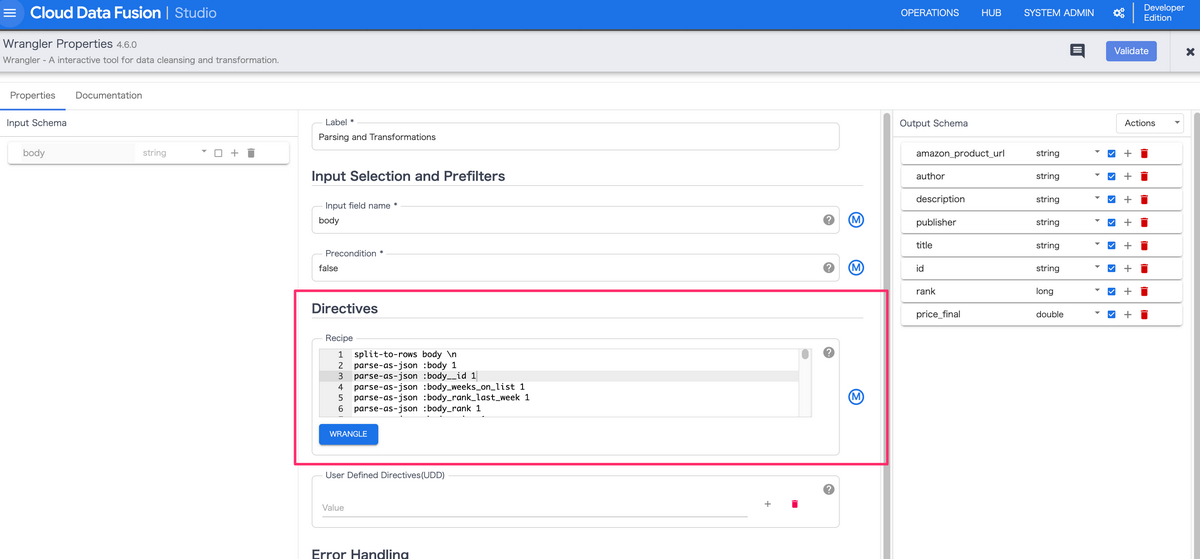
Directivesを作成する際は、以下のような形でクリックをするだけでファイルの加工(Parse処理やデータ型の変換等)を行うことができます。
以下のようなファイルをWranglerで読み込んだ際に、
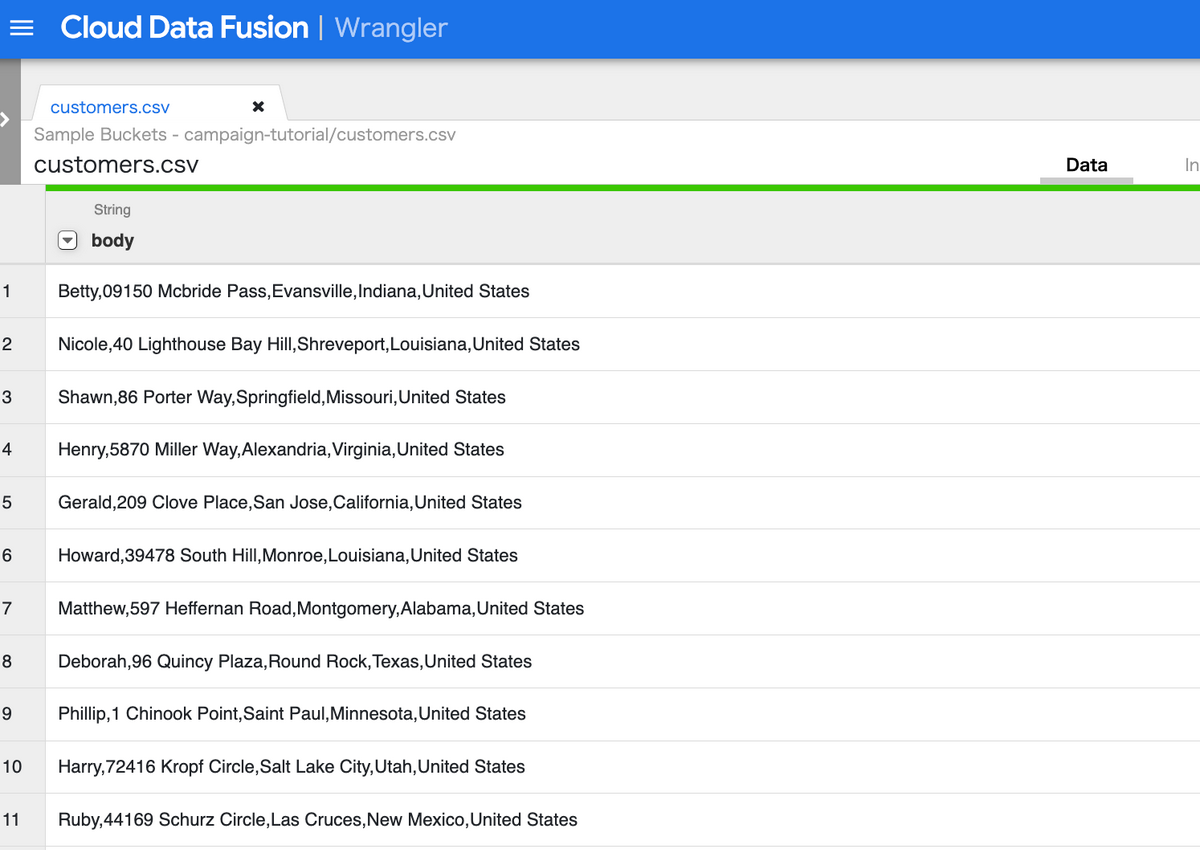
次の画像のように操作することで、
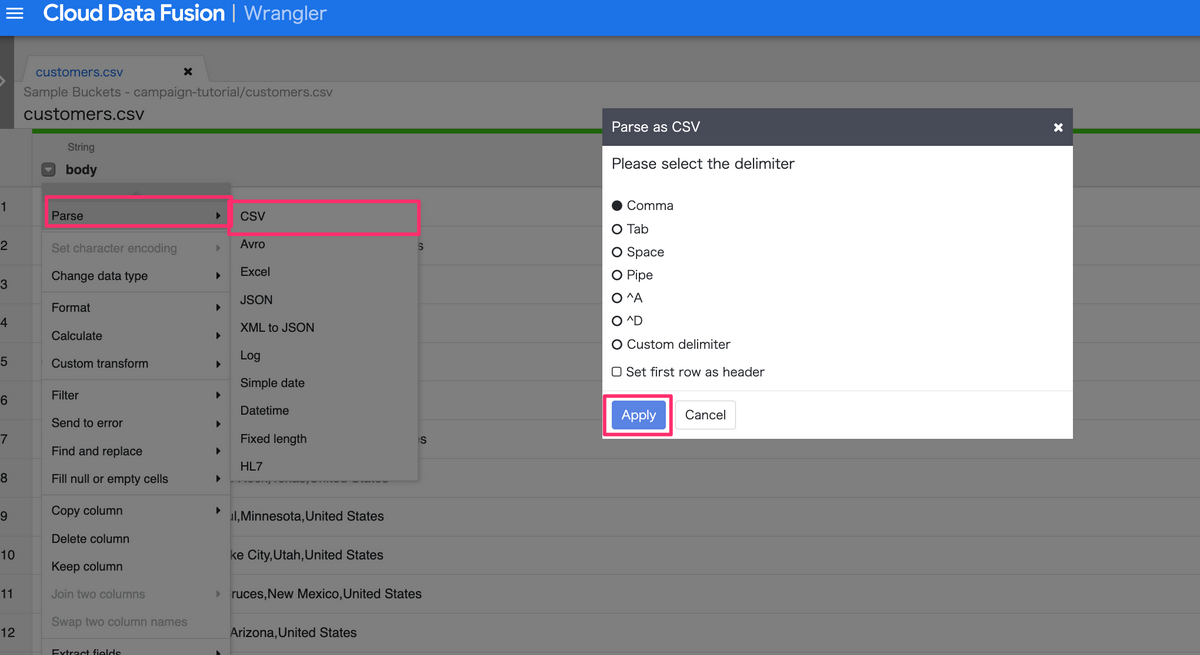
データ加工した際のイメージと、先ほど定義されたDirectivesが画面上に作成されます。
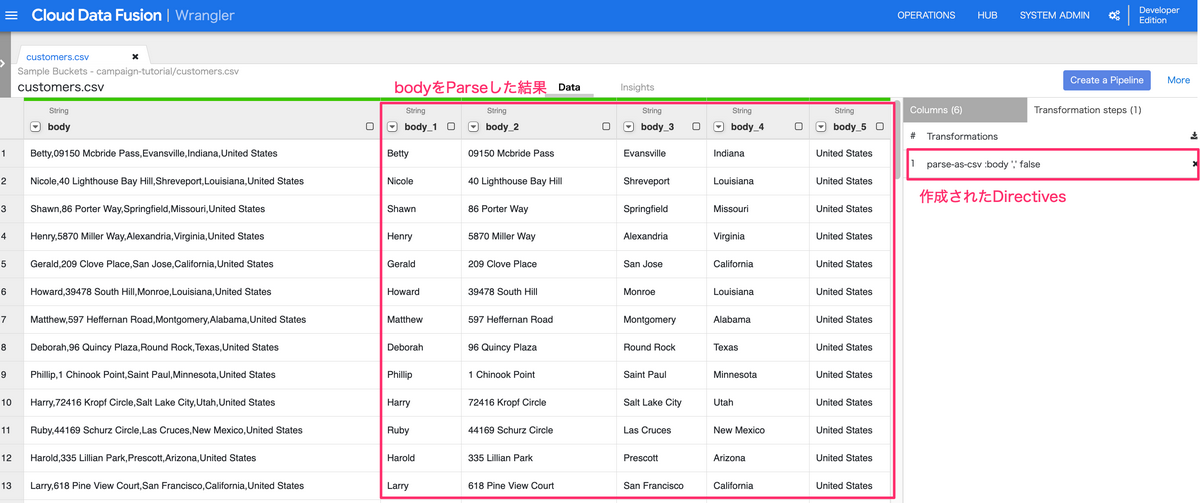
このように、Wranglerを利用することで、実際にどのようなデータ加工が行われるかをイメージしながら、簡単にETLの処理を作成できます。
BigQueryへのインサート
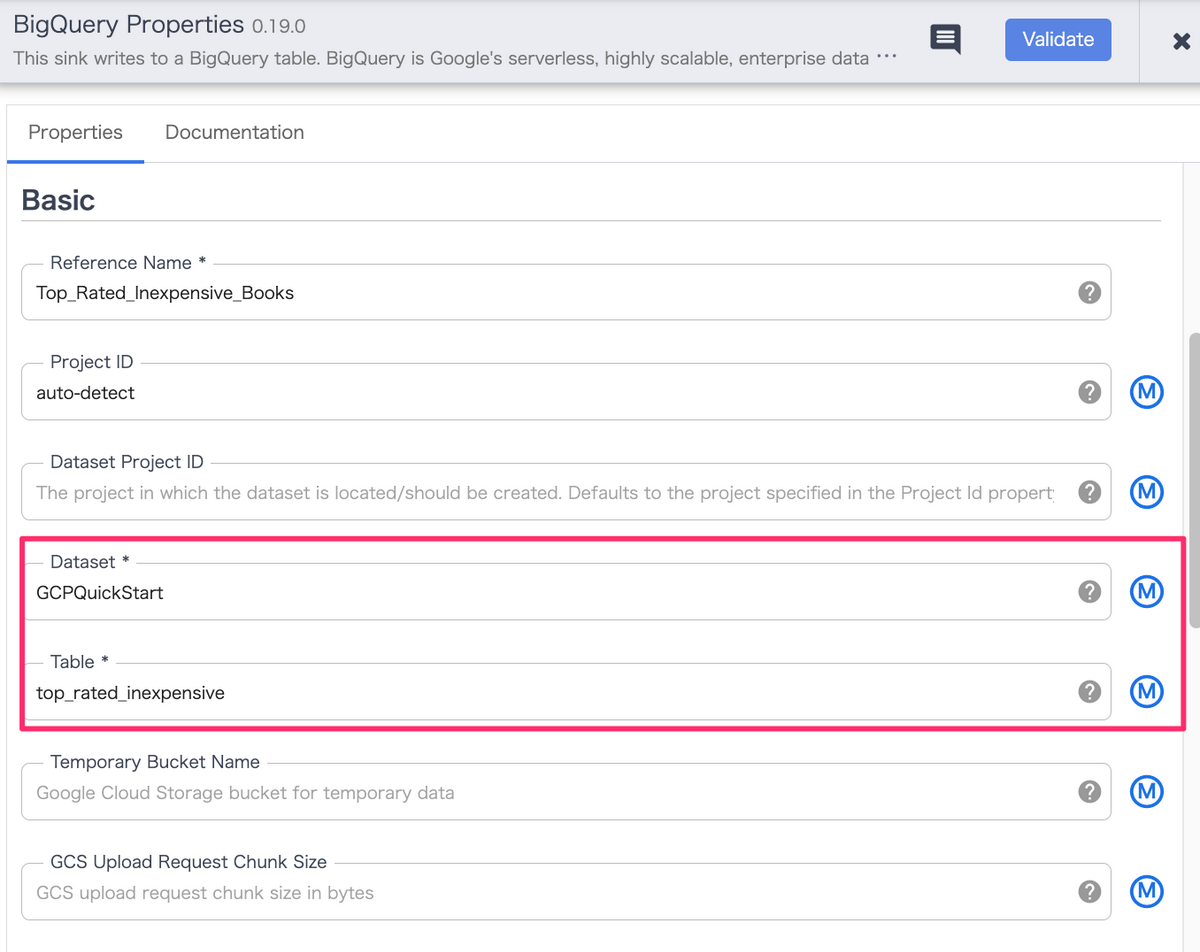
加工したデータは最終的にデータウェアハウスであるBigQueryにInsertされます。
サンプルでは、「GCPQuickStart」というデータセットの「top_rated_inexpensive」というテーブルにデータがInsertされるような設定になっています。
今回はデータセット/テーブルが既存の環境に存在しない場合に新規作成されるような形になっているので、別途作成する対応は不要です。
デプロイ
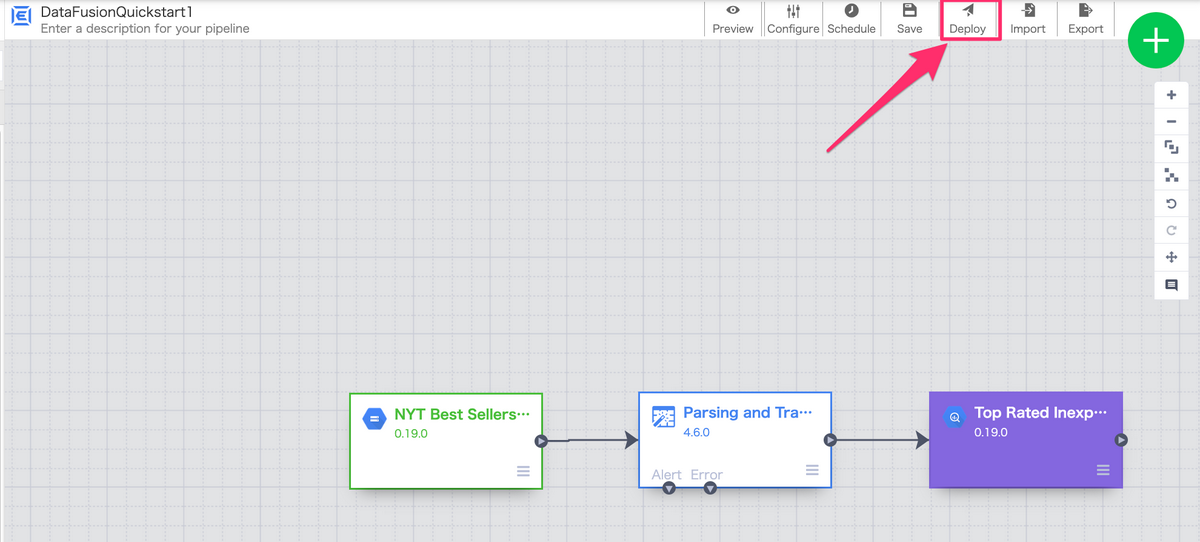
今回は入門編ということもあるので設定値はデフォルトのままで、
以下画像の「Deploy」をを押下し、パイプラインをデプロイします。
実行してみる
デプロイしたパイプラインを実行してみましょう。
以下画像で差している「Run」を押下する事で、パイプラインが実行できます。
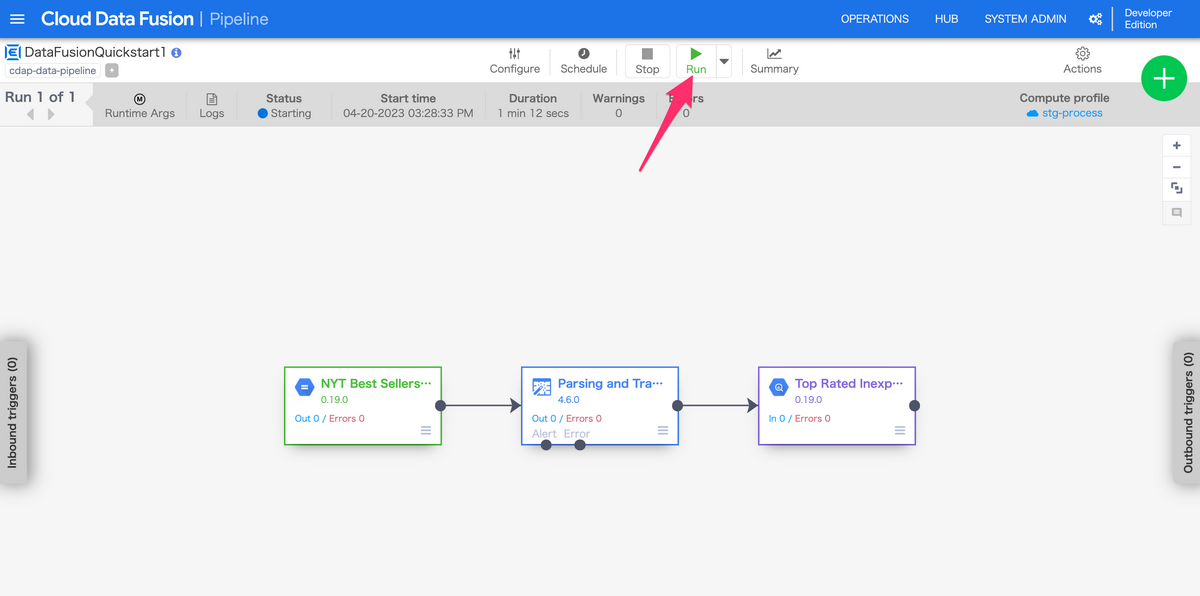
BigQueryにInsertされた結果を確認する
パイプラインのStatusが「Succeed」になったら処理は成功です。
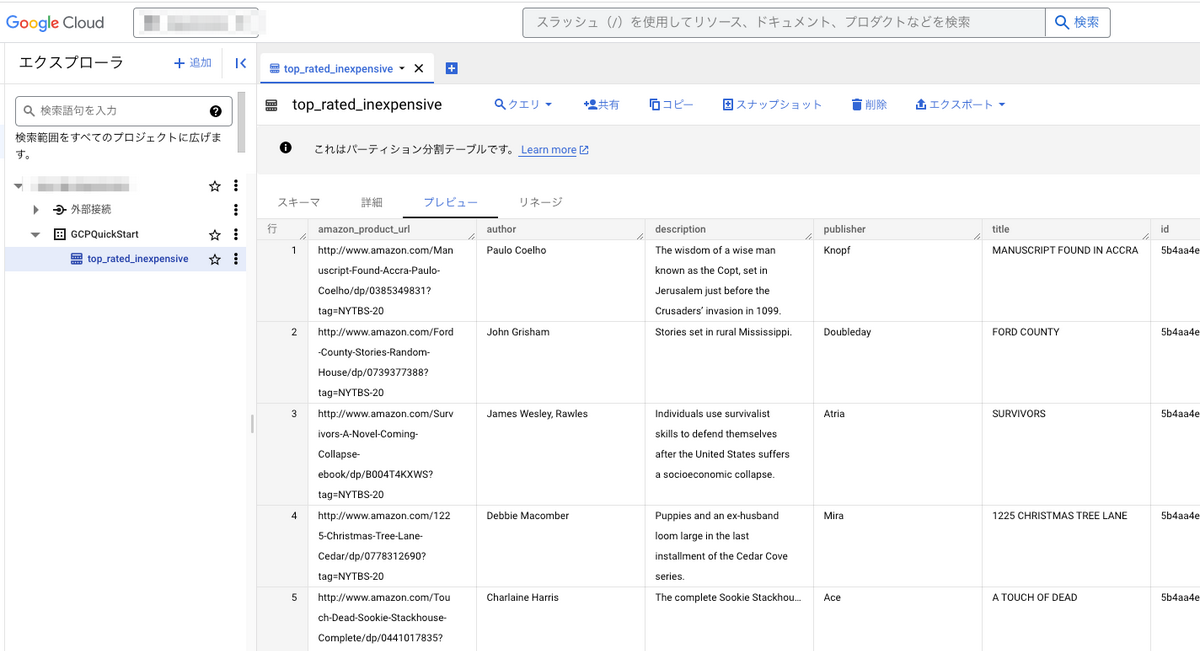
Cloud Data Fusionを作成したプロジェクトのBigQueryの画面にアクセスしてみましょう。
すると、BigQuery側でデータがInsertされていることが確認できました。
開発する際のちょっとしたTips
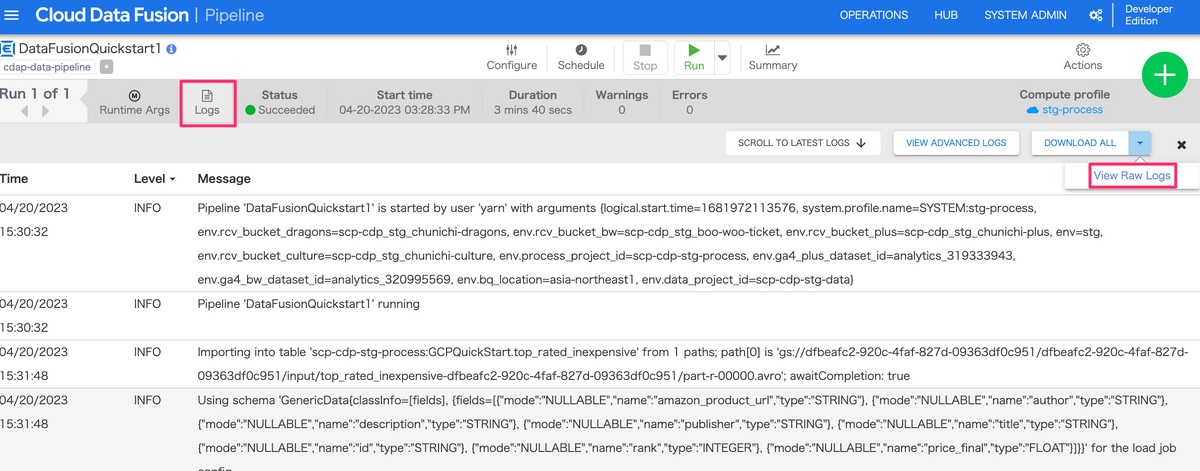
Cloud Data Fusionの画面から実行した際のログを確認したい時があります。
その際に、「Logs」という部分をクリックしても一部のログのみしか確認できないため、
少し見にくいのですが、以下画像の「View Raw Logs」をクリックすると、ログの全量を確認できます。
最後に
今回はCloud Data Fusionを利用して、簡単に使用感を確認してみました。
ETL/ELTの作成を非エンジニアが担当する場合、GUI形式でパイプラインが組めるので、そういった際には採用候補になりうるサービスだと感じました。
明日は永井優斗さんの、「技術書」の読書術 読書感想文 です。