はじめに
この記事は春の入門ブログ連載20236日目です。
新卒未経験でIT業界に飛び込んではや一年。だんだんと普段使うJavaに関しては余裕が出てきたところで他の言語にも手を出そうと思い、以前から気になっていた画像処理にチャレンジしました。
普段はコーディングしてもテストがうまくいく or いかないのどちらかでしか成果物を見ることができなかったので、視覚的に動いてる! を感じてみたく、新宿の紀伊國屋で分かりやすそうな書籍を買い、いろいろ試したので同じように画像処理にちょっと興味があるような人に読んでいてもらたらうれしいです(入門編ということでセットアップなどに具体的に触れるよりも、いじっていみた面白さを伝える方に寄せています)
参考書籍:実践 OpenCV 4 for Python 画像映像情報処理と機械学習
実際にPythonで画像処理を体験した感想
「めっちゃ簡単なのにめっちゃ楽しいじゃん!」
…素直にこの感想が最初に出てきます。笑
今までJavaしか触ったことがなく、数値や文字列をやりくりする処理は慣れ親しんでいたのですが、だからこそ、画像や映像を処理するのはあまり想像できていなくて、複雑なメソッドやロジックで処理が必要なのかなと漠然と考えていたら、真逆でした!
構文がシンプルで、ライブラリとして多数の関数が用意されているため、それらを使用することですぐにやりたいことができてしまうので学習がとてもスムーズに進みました。
驚いたのが、自動運転のCMなどで車を認識すると四角い枠で追う映像を見たことがあると思うのですが、あの処理を50行ほどのコードで実現できてしまうことです(書籍の最後の方に解説と一緒に載っています)
すごく遠いもののように感じていた実際に使われている技術を自分でできたのですごい興奮しました!!
画像処理の基本的な考え方
画像処理を学ぶ上で一番最初に身につけるべき考え方が、画像処理と言っても画像や映像を数字に変換して処理しているということです。
画像は小さいコマ(ピクセル)の集まりからなるもので、それらは色や明るさを数値化した情報を持っています。例えば、明るさの情報は最小値0が黒を表し、最大値255が白を表すといった具合です。色の場合は赤、緑、青の三原色の強弱を0〜255で表してそのピクセルの色の情報としています。
そのため画像一枚をどうこう処理する、というわけではなく、その小さいコマ(ピクセル)ごとに色や明るさを数値化し、それらに対して計算処理などを施すことによって画像処理などを行なっているのです。
例で言うと、中心線を軸に左右のピクセルが持つ数値を入れ替えることで「画像の左右反転」が実現できます。映像は我有の連続なので同じような考え方で処理できます。
正直、簡単ですが、この考え方さえ理解できていればあとはライブラリを使いこなすだけなので7割学習が終わったといっても過言ではありません(本当に)
OpenCVの基本的なアルゴリズム
OpenCVで実現できる画像処理をいくつか紹介します。
エッジ検出
輪郭を抽出する処理です。
内部で行われている処理としては、各ピクセルで左側のピクセルとの明るさの数値の差を出すことで差が大きな部分=輪郭という認識で差が大きいピクセルを明るさ255の白、それ以外を明るさ0の黒にすることで輪郭を抽出します。エッジ検出のアルゴリズムがいくつかある中で性能が高いものとしてcv2.Canny()が紹介されていました。
それぞれの引数の意味は、srcは読み込んだ画像、150が輪郭として認識するためのピクセルの明さの差、50が輪郭は繋がっているという前提で、どこまで差が小さくなっても輪郭として認識するかの設定です。
# 画像の読み込み処理 |
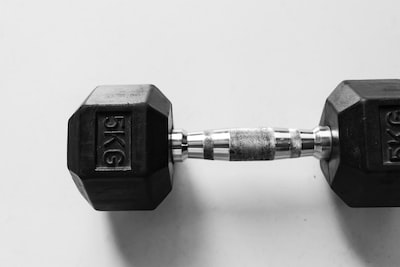
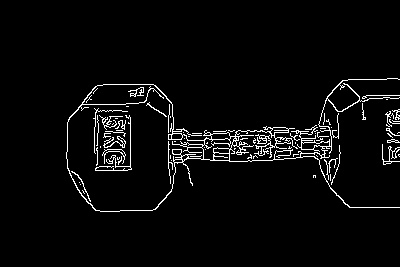
テンプレートマッチング
画像の中からテンプレートと完全に一致する物体を検出する処理です。
テンプレートマッチングの基本的な考え方としては、テンプレート画像をを対象の画像上でスライドさせながら、各位置におけるピクセルの値の類似度を計算し、最も類似した場所を見つけるというものです。
計算方法は難しかったので割愛させてもらいます(計算式がわからなくてもアルゴリズムを知っていれば超簡単に実践できます!)
以下の処理はcv2.matchTemplate()で類似度を算出、cv2.minMaxLoc()で類似度の最小値点、最大値点を取得し、その座標をもとにcv2.rectangle()でテンプレート画像の大きさの四角形を描画して一致する箇所を示しています。
# 画像の読み込み処理 |
↓対象画像
↓テンプレート画像
↓処理後
特徴点検出
テンプレートマッチングではピクセルの値の類似度で一致しているかどうかを確認しているため、対象が回転したり、サイズが変わるだけで正しく検出ができなくなります。その弱点を補うのが特徴点検出です。これは形状に着目し判別します。具体的には検出したい物の角(特徴点)を検出し、対象画像の中から同じ特徴点(特徴点が持つ情報を特徴量という)が多く発見されれば、検出するというロジックです。
(添付は画像ですが、実際には左の窓に動画が再生されながら特徴点を検出し、右の窓に表示されている動画内の1フレームに存在する特徴点と一致した際にその点が繋がるようになっっています)
orb.detectAndCompute()で特徴点と特徴量を取得し、matcher.match()で特徴点同士のマッチングを行ったあと、精度の高い特徴点のペアの数がどれほどあるかによって検出を判断するようになっています。
# 読み込み処理 |



物体認識
この書籍の最終章にはディープラーニングについても解説がありました。
ディープラーニングというと、とんでもなく複雑なプログラミングを組まなければいけないと思っていたのですが、用意されているフレームワークを利用することで簡単に実現できます。
ディープラーニングによる物体認識は、画像の入力値に重みをかけたり、バイアス値を足した結果がある数値よりも高い場合に特定のクラス(犬、車など)と判断する流れになっています。そのため、既に画像を何回も読み込み、計算を行うことで重みやバイアス値を調節したもの(ニューラルネットワーク)があればすぐに物体認識を行うことができます。
イメージ:以下画像の左の矢印が画像の入力値で丸部分が重みやバイアス値の計算部分、最終的に右の矢印に出力された値でクラスの判別を行う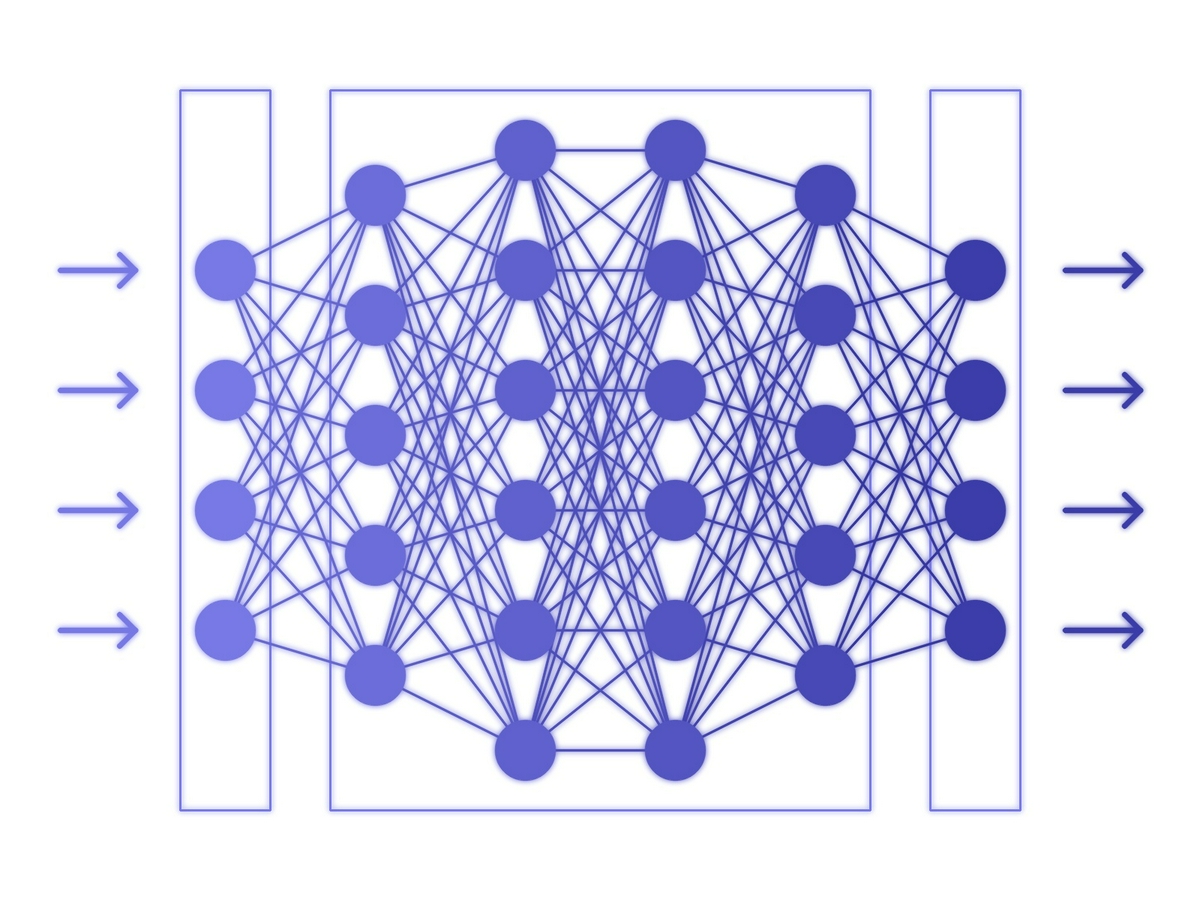
ではOpenCVを使って何をするか
アームカールフォームチェック
今回参考にした書籍でOpenCVの基本を抑えられたので、自分の普段している活動に落とし込めないかと思い、今までの処理紹介に使っている素材を見てもらえればわかるかもしれませんが、私は筋トレが好きなので、画像処理を使ってトレーニングの簡単なフォームチェックを実装してみました。
やっていることはアームカールをしっかりと最後まで追い込んでできているかチェックするプログラムです。
ロジックとしてはダンベルの赤を色範囲指定して輪郭を抽出、その輪郭に外接する矩形の底面が一定の高さを超えた場合にウィンドウに『OK』を表示するという流れです。
# 動画の読み込み処理 |
使用ライブラリ紹介:
- cv2.inRange()
- 引数の色範囲に該当するピクセルをマスクで戻してくれる
- cv2.findContours()
- オブジェクトの輪郭を返してくれる。第2、第3の引数は輪郭の検出モード、検出方法を指定する
- max()
- 最大の面積を持つ輪郭を返してくれる。第2引数は比較関数



体の仕上がりチェック(ボツ)
特徴点検出を使えば、体の仕上がりを憧れのプロのフィジーク選手と比較できるんじゃないかと思い、チャレンジしてみたのですが、以下のような要因で断念しました。。。
- 関係ない背景・髪型などで特徴点が出てしまう
- 比較したい筋肉とは関係ない背景・髪型などで特徴点を検出してしまい、一致率が下がることで正確な比較ができなくなってしまいました。
- 比較の基準設定が難しい
- 特徴点検出を行う場合は全く同じもの(例:前述のダンベル)であっても一致率は100%にならないため、それを考慮して一致と判断する基準を下げています。筋肉のように人それぞれでそもそも、そもそもつき方が違うようなものを比較する際にはどの程度の一致を基準にするかの設定が難しくなります
今回は試していませんが、先にHSV色空間などでマスキングして人体のみの検出を行い、さらには比較時にも、特徴点検出ではなく、体の仕上がりの良さについてS~Dまでラベル付したフィジーカーの画像を学習させて、一致率でなく、ランク付という方法ならうまくいくのかななどと考えておりました。機会があったら挑戦してみたいです。
まとめ
OpenCVで初めて画像処理に触ってみたということで画像処理の概念と基本的な処理がどのように機能するか、またそれらを使って著者がいじってみた体験を書かせていただきました。
先に述べたように、PythonもOpenCVも触ってみたのは初めてですが、Javaの経験が軽くあるだけの私でも1日で理解して、自分なりにいろいろ試すことができたのでとても初心者に優しい言語だったと感じました。
この記事を読んで興味を持って、OpenCVを触ってもらえたら嬉しいです!!
次は藤戸さんのHack The Box Oopsie を解いてみたです。