はじめに
こんにちは、2022年4月入社・流通製造グループ所属の高世です。
春の入門ブログ連載の14日目です。
みなさん、正規表現は使っていますか?
正規表現とはテキストデータの検索やパターンマッチングに用いれるツールで、様々な場所で使用できます。身近なところだとテキストエディタ(VSCodeなど)などで使用可能で、通常の文字列検索・置換よりも柔軟で効率的な作業を可能とします。
この記事では「正規表現は聞いたことあるけど何ができるかよくわからない」という方や「使っているけど毎回調べてコピーしている」という方向けに、基本的なものから少し高度な構文まで例文も合わせて紹介したいと思います。
正規表現チェッカーサイト
正規表現を作成する際、指定した文章とマッチするか・構文として誤っていないかをチェックしながら作成すると効率的です。
その際にWeb上で正規表現をチェックしてくれるサイトがあるので、おすすめを2つ紹介します。
- 正規表現チェッカー
正規表現・対象文字列に対して、どうマッチするか結果を表示してくれます。
表示が見やすいので本記事ではこちらのサイトの結果のスクショを貼っています。 - Debuggex: Online visual regex tester
上記のサイト同様、正規表現によるマッチの結果の表示に加えて、作成した正規表現をビジュアライズしてくれます。
デバッグを行うとき便利です!
基本的な正規表現文法
| 正規表現 | 意味 |
|---|---|
| . | 任意の1文字 |
| [] | 角括弧に含まれるいずれか1文字([abc]の場合、a,b,cのいずれか) |
| * | 0回以上の繰り返し |
| + | 1回以上の繰り返し |
| ? | 0回か1回 |
| {N} | N回の繰り返し |
| {N,M} | N回以上、M回以下の繰り返し |
| ^ | 行の先頭 |
| $ | 行の末尾 |
| \d | 数字 [0-9] |
| \w | 英数字とアンダースコア [0-9a-zA-Z_] |
| \s | 空白文字 [ \f\n\r\t\v] |
| (?=) | 肯定先読み(指定した文字列の先頭にマッチ) |
| (?<=) | 肯定後読み(指定した文字列の末尾にマッチ) |
以下ではそれぞれの構文について、コード例も載せながら紹介していきます。
任意の1文字【.】
ドット【.】は任意の1文字を表します。
任意の文字数をマッチさせたいときは【.】を繰り返します。
F....e |
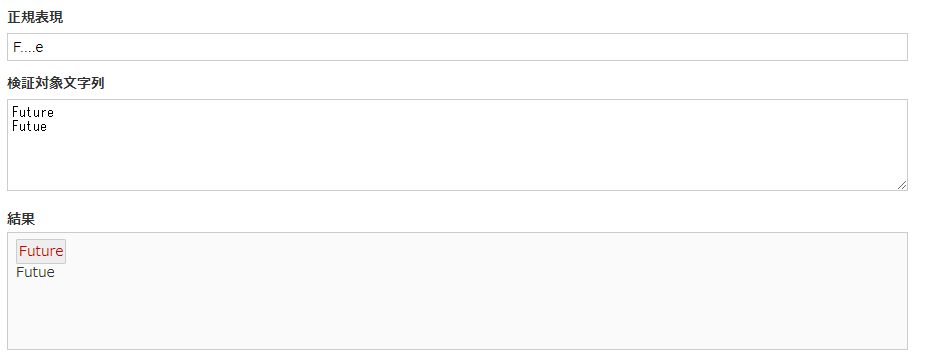
上記の例では、ドット【.】を4回繰り返すことでFutureのutur部分を表しています。
任意の4文字にマッチするため、FigureやFiddleなどにもマッチします。
いずれかの1文字【[]】
角括弧【[]】の内部に記述された文字からいずれかの1文字とマッチします。
F[ABC] |
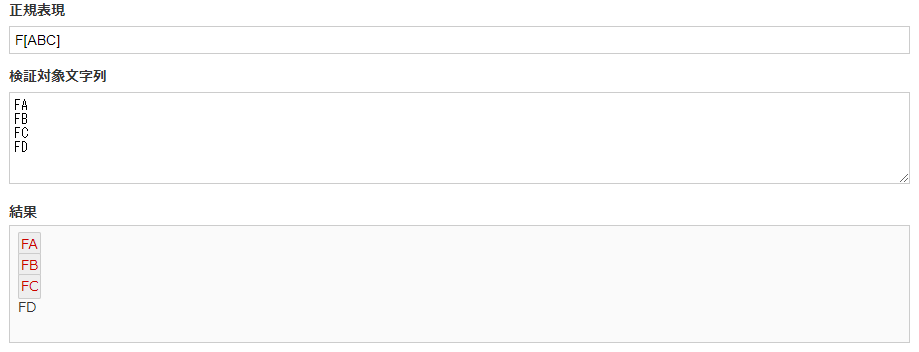
上記の例では[ABC]という正規表現がAかBかCのいずれかを表します。
範囲指定【-】
例えば0~9の数値のいずれか1文字をマッチさせたい場合、単純に[0123456789]と記述することもできますが、ハイフン【-】を使用することで[0-9]と短縮できます。
201[0-9]年 |
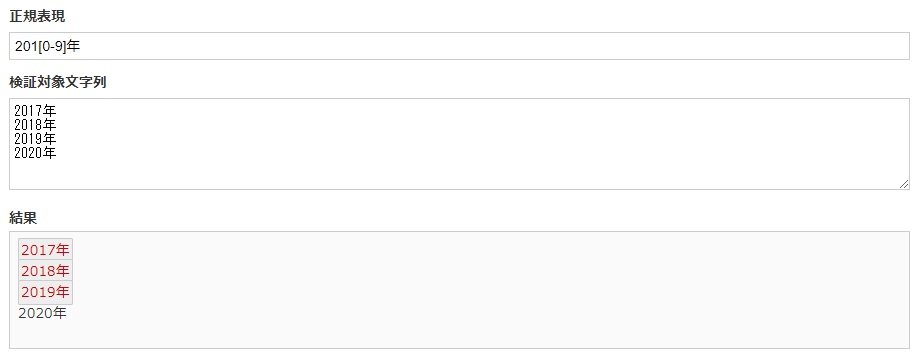
以下の表のようにアルファベットでも同様に範囲指定できます。
| 範囲指定の正規表現 | 意味 |
|---|---|
| [0-9] | 0から9までの数値 |
| [a-z] | aからzまでの小文字のアルファベット |
| [A-Z] | AからZまでの大文字のアルファベット |
また、数値とアルファベットのいずれかにマッチさせたい場合[0-9a-zA-Z]と組み合わせることで表現できます。
複数パターンのいずれかにマッチ【|】
縦棒【|】を使用することで【|】で区切られた複数のパターンのいずれかの文字列にマッチします。
(2020|令和2)年 |
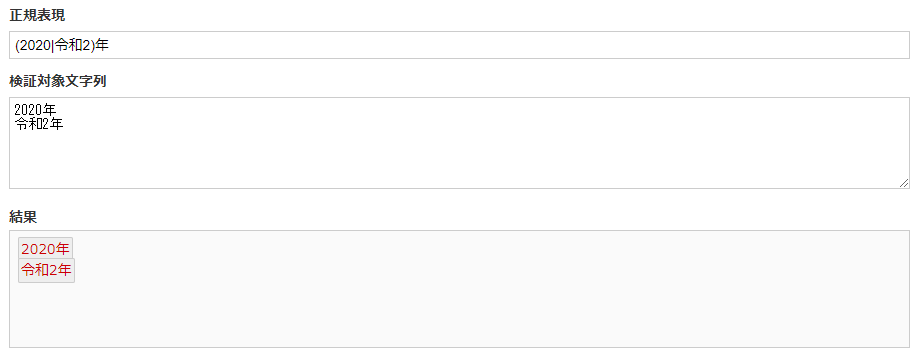
()でグループ化することでパターンの中で選択する部分を指定できるようになります。
【|】の優先順位が低いため 2020|令和2年 というパターンの場合は 2020 または 令和2年 にマッチします。上記例のように【()】でグループ化するとグループ内に限定でき、 2020年 または 令和2年 にマッチするようになります。
直前の文字の繰り返し【*+?】
【*+?】はそれぞれ、下記のように繰り返しを表します。
| 繰り返しの正規表現 | 意味 |
|---|---|
| * | 0回以上の繰り返し |
| + | 1回以上の繰り返し |
| ? | 0回か1回 |
o+ |
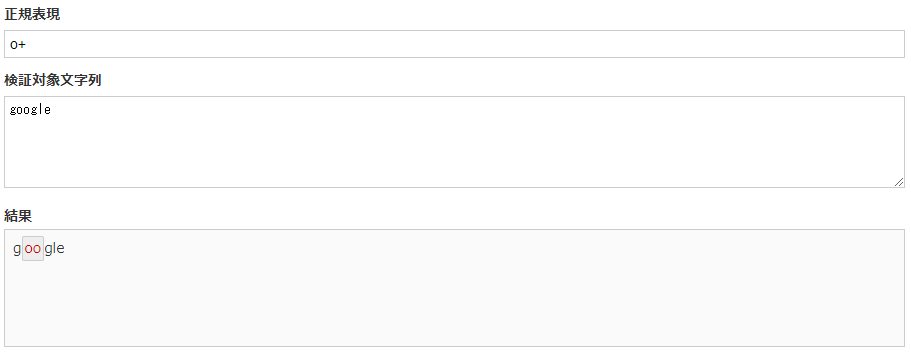
o+と記述することでoが1回以上繰り返されている箇所にマッチします。ちなみに単なる * + ? は繰り返しが最大になるようにマッチします。
最小量指定子 *? +? ?? を用いることで繰り返しが最小の文字列と合致させることもできます。詳細はこちらを参照してください。
繰り返しの回数指定【{N},{N,M}】
*や+では繰り返されうる最大の文字列と合致してしまいますが、繰り返しの回数を制限することも可能です。
こちらは波括弧を用いて【{N},{N,M}】と記述します。
| 回数指定ができる繰り返しの正規表現 | 意味 |
|---|---|
| {N} | N回の繰り返し |
| {N,M} | N回以上、M回以下の繰り返し |
o{3} |
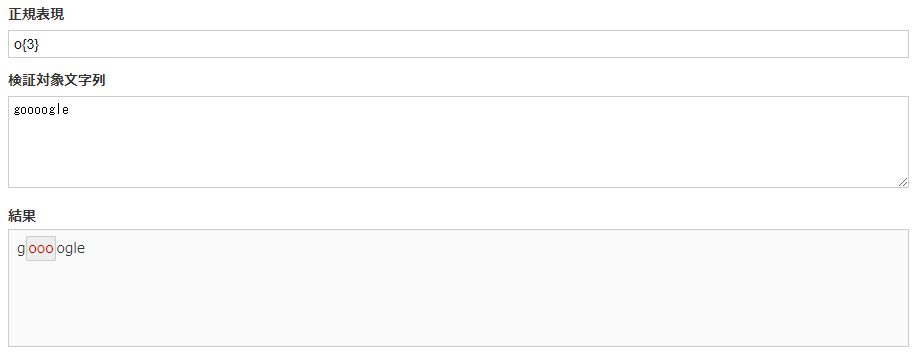
行の先頭・末尾を指定【^,$】
ハット【^】は行の先頭、ドルマーク【$】は行の末尾を表します。
^Future |
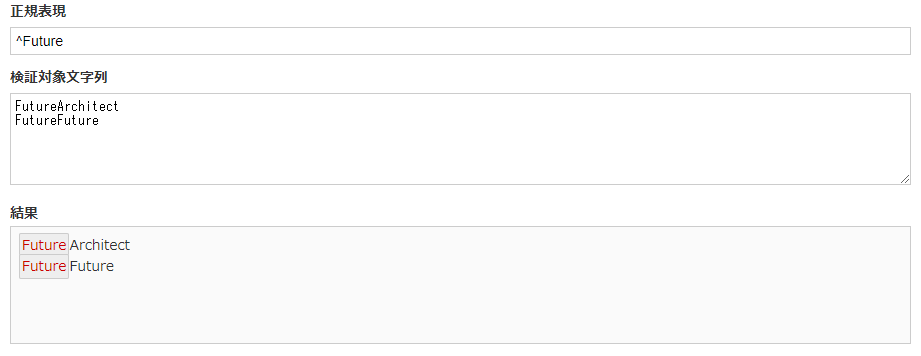
ハット【^】を正規表現の先頭に記述することで行の先頭にFutureの記載があるもののみがマッチします。
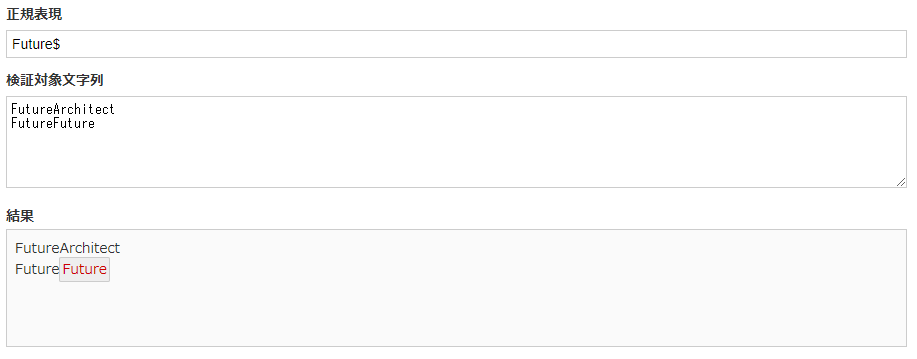
ドルマーク【$】はその逆で末尾に記述することで、行末のFutureのみにマッチします。
ハット【^】とドルマーク【$】がそれぞれ、行頭・行末を位置を表していると考えるとわかりやすいですね。
【\】を使用した略記法
環境にもよりますが、バックスラッシュ【\】に特定の文字を組み合わせることで、特定の文字集合を表すことができます。
| 【\】を使用した正規表現の略記法 | 意味 |
|---|---|
| \d | 数字 [0-9] |
| \w | 英数字とアンダースコア [0-9a-zA-Z_] |
| \s | 空白文字 [ \f\n\r\t\v] |
090-\d{4}-\d{4} |
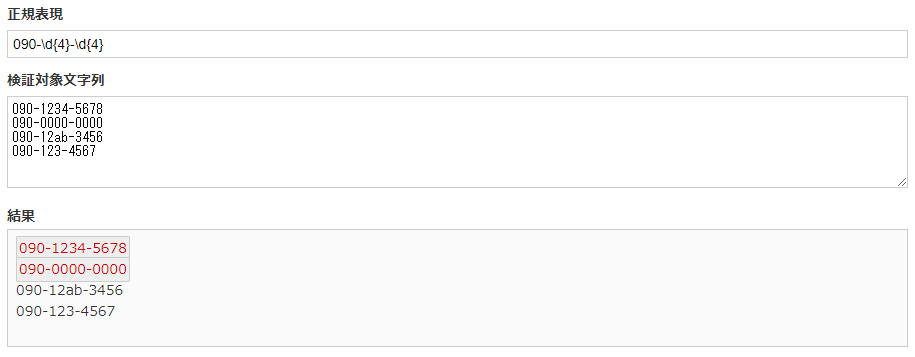
上記の正規表現では携帯電話の番号を正規表現に表したものです。
繰り返し表現と合わせることで、アルファベットが混入した行や、文字数が足りない行を排除することが出来ています。
また前述した[0-9]という記法よりも、短く視認性も良くなっています。
先読み・後読み【(?=),(?<=)】
上記で紹介した正規表現では対象の文字列にマッチするかどうか・マッチする箇所があるかないかをチェックしますが、例えばマッチした文字列以前・以降の文字列を取得したい場合など、これから紹介する先読み・後読みが使用できます!
肯定先読み【(?=)】
肯定先読みは【(?=xxx)】と記述し、xxxにマッチした文字列の先頭位置にマッチします。
言葉では分かりづらいので具体例を見ると、下記のような〇〇Scriptという文字列からScript以前の文字列(JavaやType)などとマッチさせたい場合に使用できます。
JavaScript
TypeScript
CoffeeScript
.*(?=Script) |
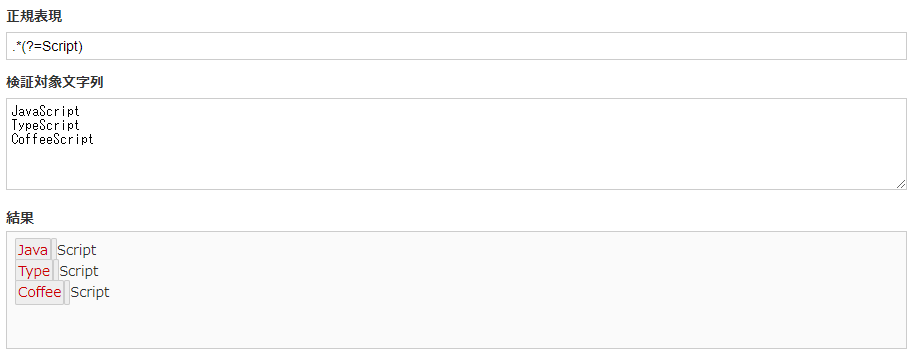
Script以前の文字列(Java,Type,Coffee)を取得できました。
肯定先読みを使用することで、上記のような単純にパターンマッチで取得できないような文字列を抽出できます。
肯定後読み【(?<=)】
肯定先読みではマッチした文字列の先頭位置にマッチしましたが、肯定後読みではその逆で文末にマッチします。
(?<=Future).* |
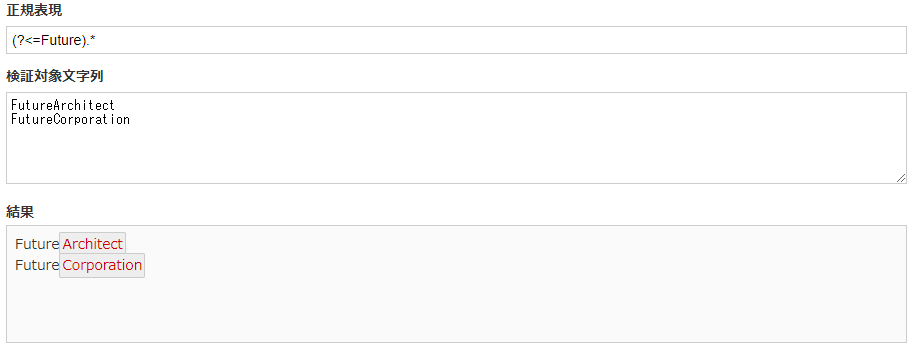
上記の正規表現では、Futureという文字列の後ろの位置にマッチしそこから.*で残りの文字列にマッチさせています。
肯定先読み・後読みを組み合わせた例
最後に補足で肯定先読み・後読みを組み合わせた例を紹介します。
2つを組み合わせることで、特定の文字列で囲まれた文字列を抽出できます。
(?<=Future).*(?=Inc) |
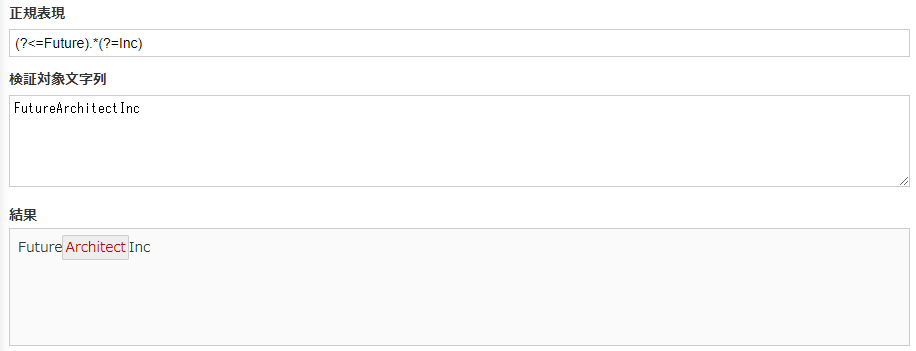
FutureとIncに囲まれたArchitectを抽出できました。
おわりに
正規表現をマスタすることで、日々の文章を扱うような作業を効率化できます。
注意点として、本記事で紹介した正規表現の構文は個人的に使う頻度が高いと思うものを選んでいるため、こちらが全量ではありません。また環境によって使用できる正規表現が異なる場合があるため気をつける必要があります。
最後に紹介した先読み・後読みの正規表現が記述できることで、表現の幅が広がると思うので存在だけでも覚えていただけたら嬉しいです。正規表現を使用することで、日々の作業の生産性を向上させて行きましょう!
明日の入門記事は栗栖さんのOS自作入門本に触れたのでOS起動までの処理概要をまとめてみたです!