SAIGの小橋です。
春の入門ブログ連載の21日目です。
IT業界に身を置いていると、今の技術トレンドが気になるときがありますよね。業界の潮流を把握する方法の1つとしてTechnology Radarという文書があるので、今回紹介します。
Technology Radar とは何か
公式の説明では「ソフトウェア開発において現在興味深いと考える変化についてまとめた文書」と書かれています。大雑把に言えば技術トレンドのまとめ文章と思って良いでしょう。このTechnology Radarをまとめているのは20人ほどのチームで、多くの技術書を書いているマーティン・ファウラーもその一員です。
発表のペースについては、年2回メンバーが一堂に会してミーティングをしてRadarを作成するとしています。ここ数年は、毎年春と秋に発表されています。最新のTechnology Radarは2023年4月に発表された volume 28です。
Technology Radarではその名の通り、レーダー状の円の中に個々の注目する技術を表記しています。
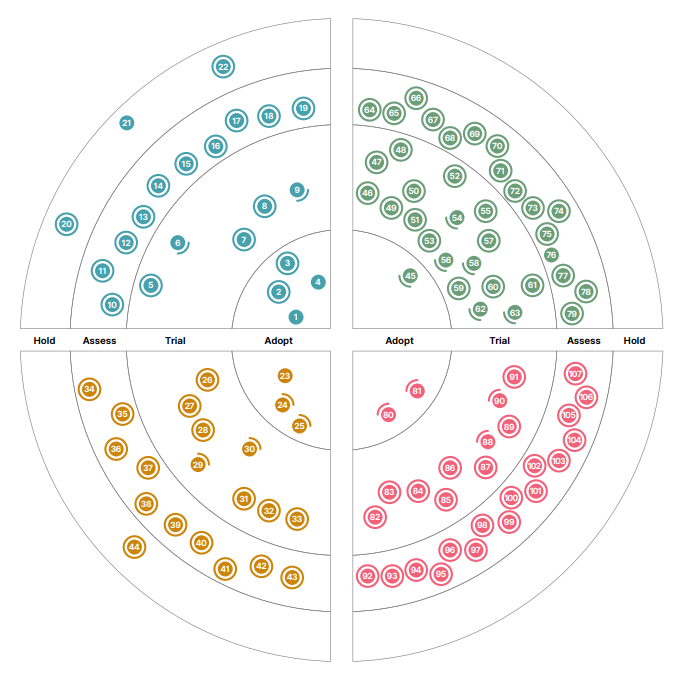
分野と層
各項目はレーダー中の位置によって、Techniques, Tools, Platforms, Languages & Frameworksという4つの分野に分かれています。
また、レーダーの中心から、Adopt、Trial、Assess、Holdの4つの層に分かれています。
Adoptが一番推奨度合いが高く「採用を真剣に検討すべき技術」という位置づけです。そこから外側に行くほど推奨度合いが低くなり、Assessは「注目すべき技術だが、特に自分に合うと思わない場合は試してみなくて良いだろう」という評価です(一番外側のHoldに分類されるものはほとんどありません)。ある項目が次回以降のvolumeで評価が変わることもあります。例えばVue.jsの履歴を見ると、2016年に最初にAssessとして扱われ、2017年にはTrial、2020年にはAdoptに格上げされています。
注意すべきは、あるvolumeで取り上げられた技術でも、次のvolumeで特に動きが無ければRadarには載っていないという点です。そのため、最新版に限らず直近でいくつかのvolumeを見ると良いかもしれません。
今回は最新のvolume 28を見てみましょう。最新の全部で107項目もあり、全てを解説するのは困難なので、私の普段の業務分野に近い 機械学習/AI関連のところを適宜リストアップしています。
28. Ax
機械学習実験、A/Bテスト、シミュレーションなど、多くの実験を最適化するためのプラットフォームです。離散的な目的変数については多腕バンディットを用いて、連続的な目的変数についてはベイズ最適化を用いて最適化を実施できるようです。
30. Feature Store
Technology Radarの解説には「Feature Storeとは、与えられたドメインやビジネス問題に関連する特徴量の識別、発見、監視を容易にするためのアーキテクチャの概念です」と書いてありますが、個々の具体的なツールではなく抽象的な概念のようで、何のことやら……。featurestore.orgの解説を読むと、生データからの特徴量抽出・モデルの訓練・モデルのデプロイと本番での推論と、モデルのライフサイクルによってチームが分かれるときも、データエンジニア・データサイエンティスト・機械学習エンジニアの全員が参照できるようなプラットフォームを作るのがFeature Storeのようです。
Feature Storeの具体例としてはAmazon SageMaker Feature Store, Vertex AI Feature Storeなどがあります。Vertex AIについては技術ブログ内の他の記事もご覧ください。
39. Modal
GPUリソースの計算環境を提供するサービスで、機械学習モデルや並列計算ジョブやWebアプリケーションをデプロイできるようです。アプリケーション例を見てみると、Stable Diffusionによる画像生成、LLMとLangChainを用いた質疑応答システムなど、かなり新しい例が多く面白そうですね。volume 27に載っているGradient (paperspace) に近いものだと思われます。
54. Kubeflow
KubeflowはKubernates上の機械学習プラットフォームで、モデルのビルド・訓練・デプロイまでを実行できます。機械学習パイプラインに加えて、パラメータチューニングを行うKubeflow Katibなどのコンポーネントがあるようです。
70. Evidently
機械学習モデルの性能の評価・テスト・監視に使えるPythonライブラリです。本番環境用のダッシュボード画面があります。モデルのドリフトを検出することに重点を置き、データドリフト(入力データの傾向が時間とともに変わること)、コンセプトドリフト(説明変数と目的変数の関係が時間とともに変わること)の検出に役立つとしています。
技術ブログ内でも最近取り扱っていますのでご覧ください。本番環境投入後のドリフトや性能劣化の検出するためのツールは多く開発されており、同じvolume 28でDeepchecks、Giskardという他のツールも紹介されています。
81. PyTorch
なぜ今更このタイミングでPyTorch……? と思って履歴を見てみると、2020年にはTrialとして紹介されていましたが、3年後の今回Adoptに昇格しています。
他のフレームワークと比べたとき、以下を主な利点として挙げています。
- TensorFlowでは機械学習の内部動作が見えないのに対してPytorchは内部動作を把握できるため、デバッグが容易であること
- 動的な計算グラフを用いているためモデル最適化がしやすいこと
- State-of-the-Art (SOTA) を達成しているモデルが多く利用できること
88. River
オンライン学習(1つずつ順番に入力データが与えられ、それに対して機械学習モデルを順次更新していく方法)に対応したPythonライブラリです。
103. pandera
https://github.com/unionai-oss/pandera
データのバリデーションツールです。1つ前のvolume 27では同様のツールとしてGreat Expectationsが紹介されました(Great Expectationsについては、フューチャー技術ブログのMLシステムにおけるモデル・データの監視【概要編】でも触れています。また、もうすぐGreat Expectationsについての記事が出るので併せてご参照ください)。
panderaも入力データに対してバリデーションを行うPythonライブラリです。Radarの説明や両者の比較記事などを読むと、機能が多く本番環境まで考慮に入れるならばGreat Expectations、比較的シンプルですぐに使いやすいのがpandera、という違いがあるようです。
おわりに
くぅ~疲れました。普段馴染みのないツールについて調べるのは面白いですが、説明を書くのが難しいですね。
このvolume 28には、有名どころですとChatGPTやGitHub Copilot、Prompt engineeringについても取り上げられていますので、読んでみることをお勧めします。機械学習関係だとLLM(大規模言語モデル)関連の項目もいくつかありましたが、今回は割愛します。皆さんの気になる技術領域で最近何が熱いトピックなのか、Technology Radarで探してみてはいかがでしょうか。
次は清水さんのiOSアプリのCI入門 です。