春の入門連載2023、17日ぶり2回目の寄稿、23日目を担当します齊藤です。よろしくお願いします。
運良く2個目の記事をアップできることになりました! (やったね)
業務でAmazon OpenSearch Service (Serviceのほう) を触る機会があり、興味があったのでプレビューで公開されていたServerless版でいろいろ試しました。
触っていた内容を入門向けにまとめて、ぜひ参考にしつつ入門していただければです。
Black Belt の資料が大変参考になりました。こちらを適宜引用しています。
AWS BLACK BELT ONLINE SEMINAR Amazon OpenSearch Serverless
引用:[AWS Black Belt Online Seminar 2023/01] Amazon OpenSearch Serverless
注意!
Serverless版は、無料利用枠がないため、入門のために少し触るだけでも費用がかかります。
参考までに自分の場合は、5,6回コレクションを作成したり消したりAPI叩いたりで、800円くらいの請求でした。無料枠で OpenSearch を試したい場合は、Service版を使ってください。
いくらかかかってもいいけどとりあえず触って感触掴みたい! みたいな方はServerless版をどうぞ。
Amazon OpenSearch Serverless
プレビュー版から一般提供開始にかわりました。
https://aws.amazon.com/jp/about-aws/whats-new/2023/01/amazon-opensearch-serverless-available/
そもそも OpenSearch とは?
OpenSearch は、リアルタイムのアプリケーションモニタリング、ログ分析、ウェブサイト検索などの幅広いユースケースにご利用いただける分散型、コミュニティ主導型、Apache 2.0 ライセンス、100% オープンソースの検索および分析スイートです。
引用:[AWS公式] OpenSearch とは https://aws.amazon.com/jp/what-is/opensearch/
検索・分析ができる、いわゆる全文検索エンジンと呼ばれるものになります。
次に出てくる、全文検索とは何か?
全文検索(ぜんぶんけんさく、英: Full text search)とは、コンピュータにおいて、複数の文書(ファイル)から特定の文字列を検索すること。「ファイル名検索」や「単一ファイル内の文字列検索」と異なり、「複数文書にまたがって、文書に含まれる全文を対象とした検索」という意味で使用される。
引用:[ウィキペディア (Wikipedia): フリー百科事典] 全文検索(2023年5月24日取得,https://ja.wikipedia.org/w/index.php?title=全文検索&oldid=94342252)
OpenSearch では、引用元のページにも出てくる「転置インデックス」を使っています。
詳しく知りたい方は、以下を参照ください。
[Amazon OpenSearch Service Intro Workshop] 逐次検索と転置インデックス
とりあえず触りたい人向けに個人的にまとめると、全文検索というSQLのLike句よりめっちゃ速く文字列を検索できるというもの。その速さを活かして、例えば、アプリケーションが出す大量のログからエラーを検知させたり、ユーザーの動向を調べたり、といった分析とその結果のレポート出力などなど周りの機能も提供しているという印象。
補足
他にも有名な全文検索エンジンで「Elasticsearch」があります。
元々は、「Amazon Elasticsearch Service」として「オープンソースのElasticsearch」がAWS上でマネージドサービスとして提供されていましたが、バージョン7.10以降において別のライセンス体系となりAWS上でこれまで通り利用できなくなることから「オープンソースのElasticsearch」から派生し「OpenSearch」が作られました。この成り立ちにより「Elasticsearch」と「OpenSearch」は類似点が多くあります。実際にバージョン7.10までは互換性がありAWS側では当該バージョンまではサポートする旨が記載されています。しかし、それ以降のバージョンについては、互換性が保証されておらず、別のソフトウェアとして位置付けられているため、互換性や機能有無についてはご注意ください。
(上記にはライセンス変更や名称変更には背景があるのですが……何があったのか気になる方は、このあたりの記事から色々見てみてください……)
https://www.elastic.co/jp/blog/elastic-and-amazon-reach-agreement-on-trademark-infringement-lawsuit
Amazon OpenSearch Serverless 概要
- Amazon OpenSearch Service のサーバーレス版
- クライアントは Amazon OpenSearch Service と同様の方法で操作可能
- OpenSearch のクラスタのスケーリングなどの管理が不要
データの投入や検索の負荷増大に合わせて勝手にスケールアウトしてくれるらしい - 少しの手順、数分で構築が可能 (入門におすすめの理由)
- Hot node、UltraWarm node とノードに種類があり、時系列コレクションの場合に直近24時間のデータはHot nodeにいれ、それ以降はUltraWarm nodeにいれることでノードの増大を防ぐ (Serverless版のいいところと思われ)
 [引用元 2023/01 [AWS Black Belt Online Seminar] Amazon OpenSearch Serverless 27スライド目](https://pages.awscloud.com/rs/112-TZM-766/images/AWS-Black-Belt_2023_AmazonOpenSearchServerless_0131_v1.pdf)
[引用元 2023/01 [AWS Black Belt Online Seminar] Amazon OpenSearch Serverless 27スライド目](https://pages.awscloud.com/rs/112-TZM-766/images/AWS-Black-Belt_2023_AmazonOpenSearchServerless_0131_v1.pdf)
公式ページはこちら
公式ページでは、以下の情報がまとまっています
リソース
- ポッドキャスト
- Amazon OpenSearch Serverless の紹介
- ワークショップ
- Amazon OpenSearch Serverless を実際に体験する
- ブログ
- Amazon OpenSearch Serverless の簡単な方法によるログ分析
- 動画
- re:Invent 2022: Provision and scale OpenSearch resources with serverless
- デモ: Searching with Amazon OpenSearch Serverless
- デモ: Log analytics with Amazon OpenSearch Service
お試し
Amazon OpenSearch Serverless の TOP
- Amazon OpenSearch Service のトップにサーバーレスのメニューが追加されておりそこからサーバーレス版にアクセスができる
※画像のオレンジ枠が該当箇所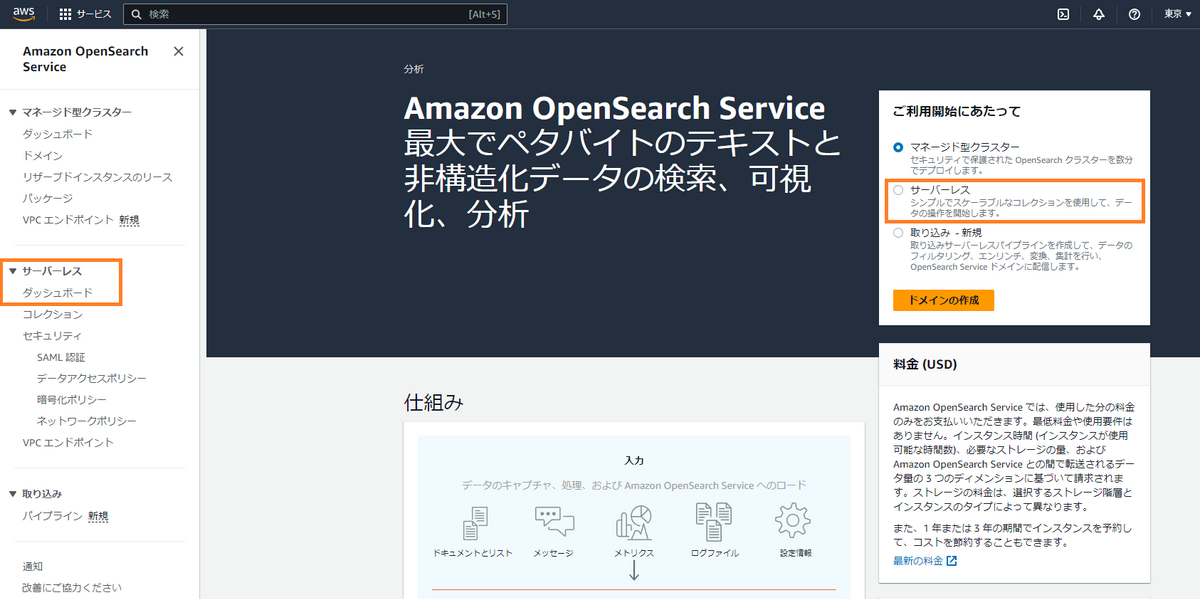
- Amazon OpenSearch Service のトップにサーバーレスのメニューが追加されておりそこからサーバーレス版にアクセスができる
インデックスを格納するのはコレクション
- インデックスというのは、RDBで言うところのテーブルのようなもの。OpenSearch Service では、EC2インスタンスに対しインデックスを格納する
- OpenSearch Serverlessでは、コレクションという単位で作成しコレクションに対しインデックスを作成する
コレクションを作成してみる
- コレクションの名前、説明、コレクションタイプの設定ができる。コレクションタイプは、時系列と検索の2種類から選べる。
名前と説明はいい感じのものを入れて、コレクションタイプは検索を選びましょう。
(時系列を選ぶと、前述の通り直近24時間分のデータしか検索対象とならない)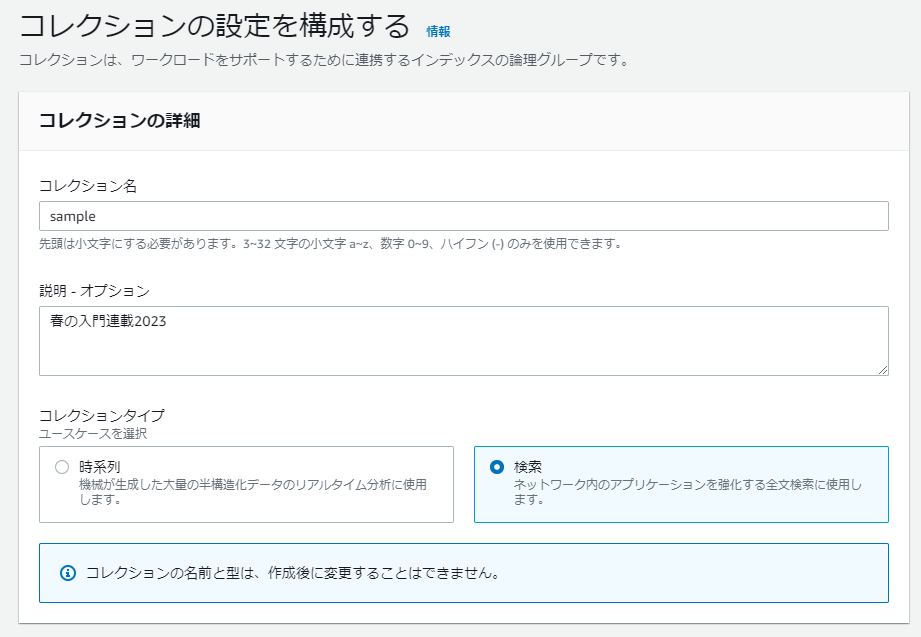
- 暗号化
初学者の方は、「AWS 所有キーを使用する」でAWSにおまかせしましょう。自前で用意したい方は、もう1つの方で。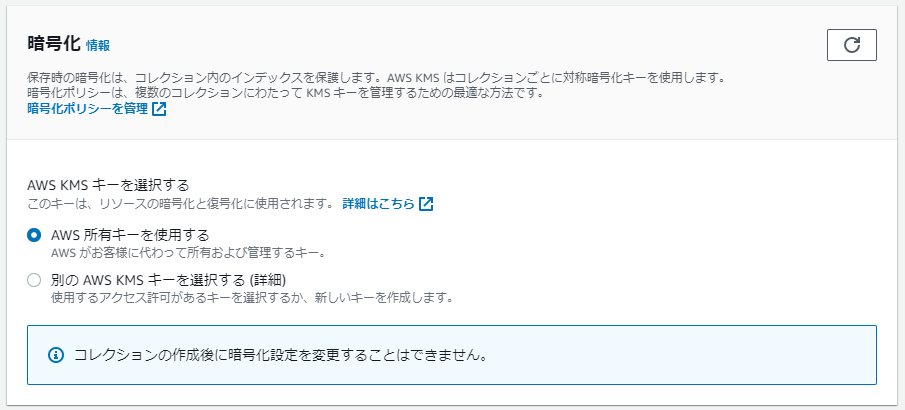
- ネットワークアクセス
今回はアクセスタイプにVPCは使わずにパブリックを利用します。VPCの説明までするとめんどくさいのでOpenSearch に絞って学べるようパブリックです。後ほどアクセスポリシー内でIAMユーザーでのアクセスとするので、誰でも触れる! というわけではないので安心してください。
※説明でAPIのエンドポイントとダッシュボードのエンドポイントで異なるネットワーク設定をできるような記述があるが、注釈の方で同じ設定にするよう記載がある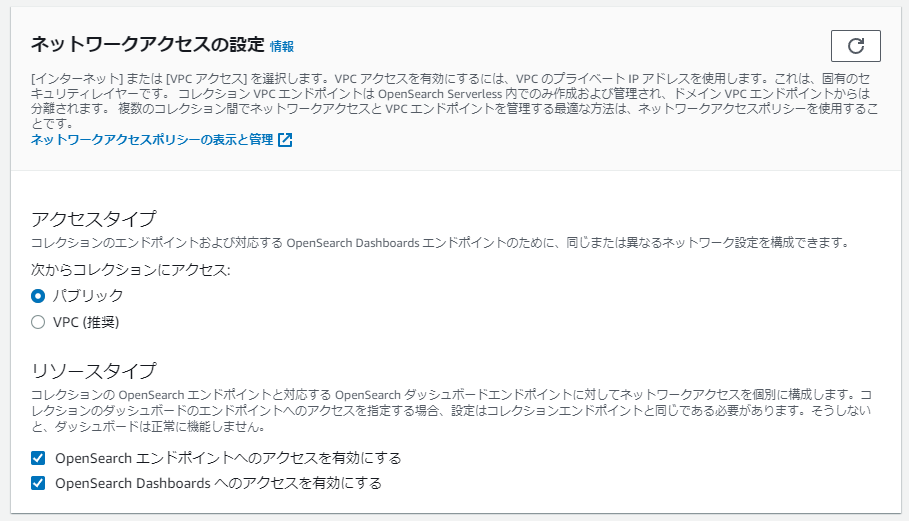
- データのアクセスポリシー
データへのアクセス権のルールを作成できます。
わかりやすくビジュアルエディタで作成していきます。
- テンプレートやインデックス、ドキュメントに対し権限を付与できます
「エイリアスとテンプレートの許可」「インデックスの許可」どちらもすべてチェックします。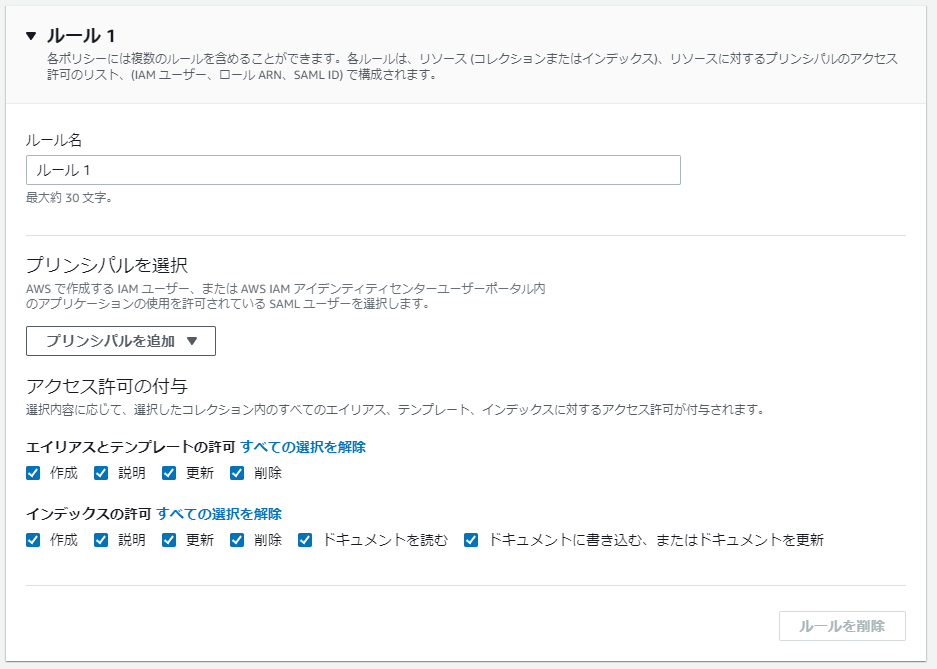
- プリンシパルにはIAMとSAMLを選択できる。

- 「IAM ユーザーとロール」を選択するとダイアログが開かれます
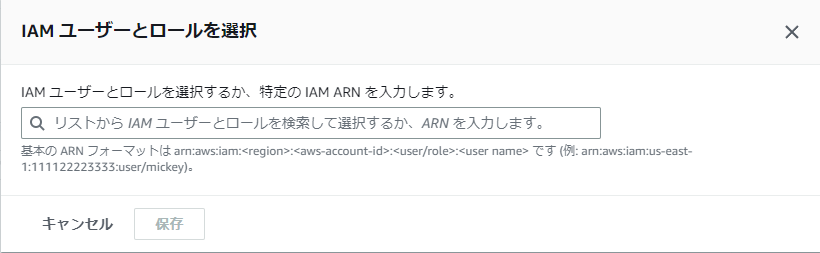
- 「ユーザー」を選択すると……
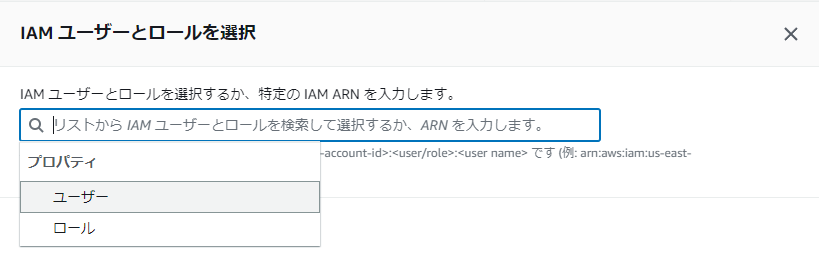
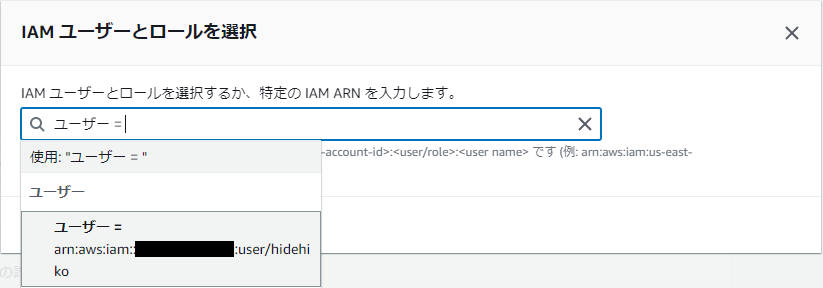
- IAMユーザーの一覧が表示されるので、そこから選んでください
ビジュアルエディタの場合、最後にアクセス権のルールに名前をつける模様。あとから名前を変えたり、削除したりできるので「新しいデータアクセスポリシーとして作成する」を選択し、いい感じのアクセスポリシー名をつけてください。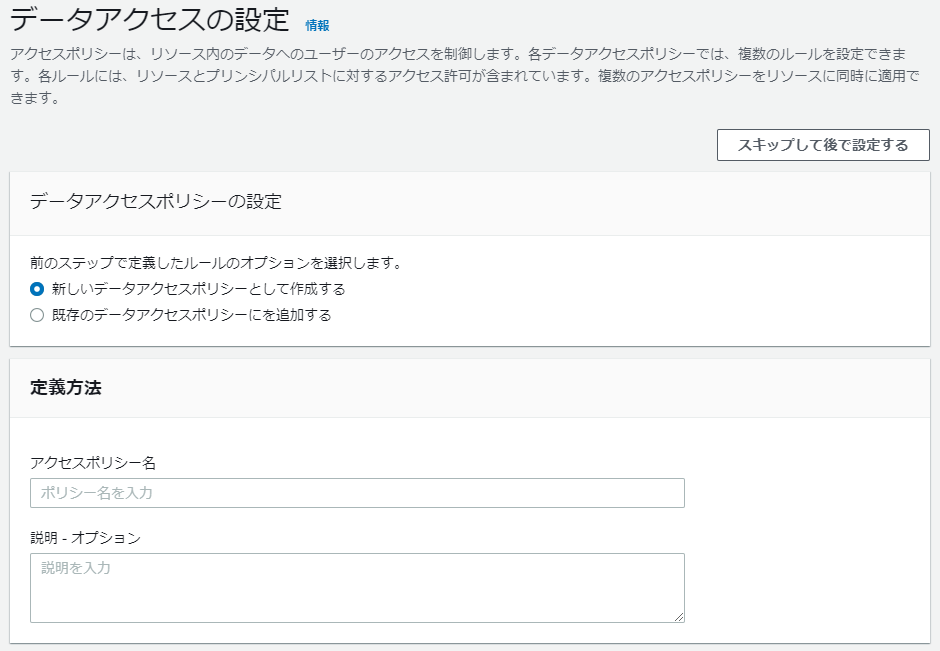 最後に確認画面が出るので、「送信」ボタンを押して続行!数分でステータスがアクティブになり、あちこちにダッシュボードへのリンクが表示されました。
最後に確認画面が出るので、「送信」ボタンを押して続行!数分でステータスがアクティブになり、あちこちにダッシュボードへのリンクが表示されました。
- コレクションの名前、説明、コレクションタイプの設定ができる。コレクションタイプは、時系列と検索の2種類から選べる。
作成したコレクションのOpenSearchダッシュボードにアクセスする
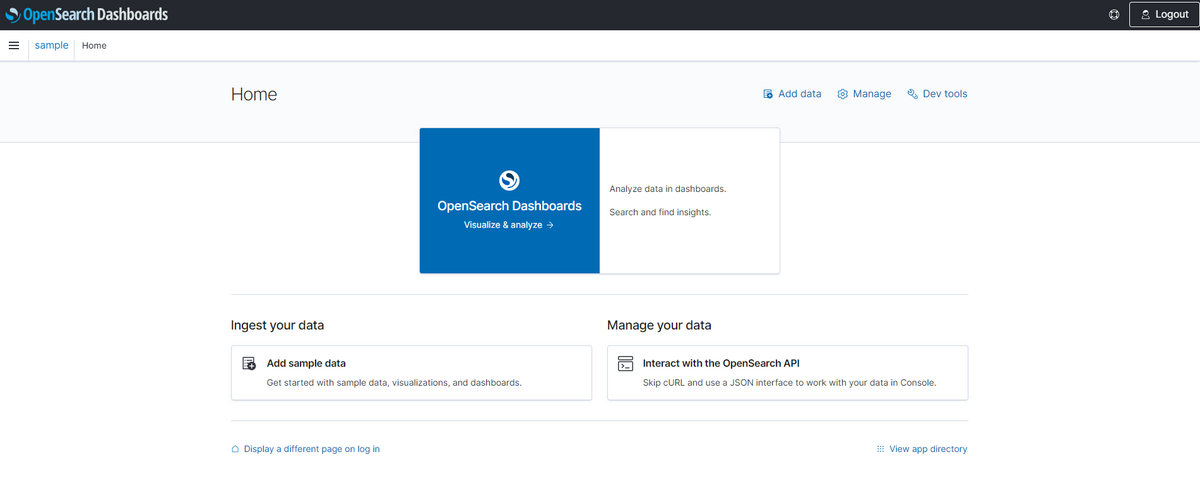
- ダッシュボードにアクセス
オレンジ枠の各所をクリックしましたが、画面が表示されず……
青枠のURLをコピーして「https://xxxxxxxxxxxxxxxxxxxx.ap-northeast-1.aoss.amazonaws.com/_dashboards」とURLの末尾に「/_dashboards」をつけることでアクセスできました。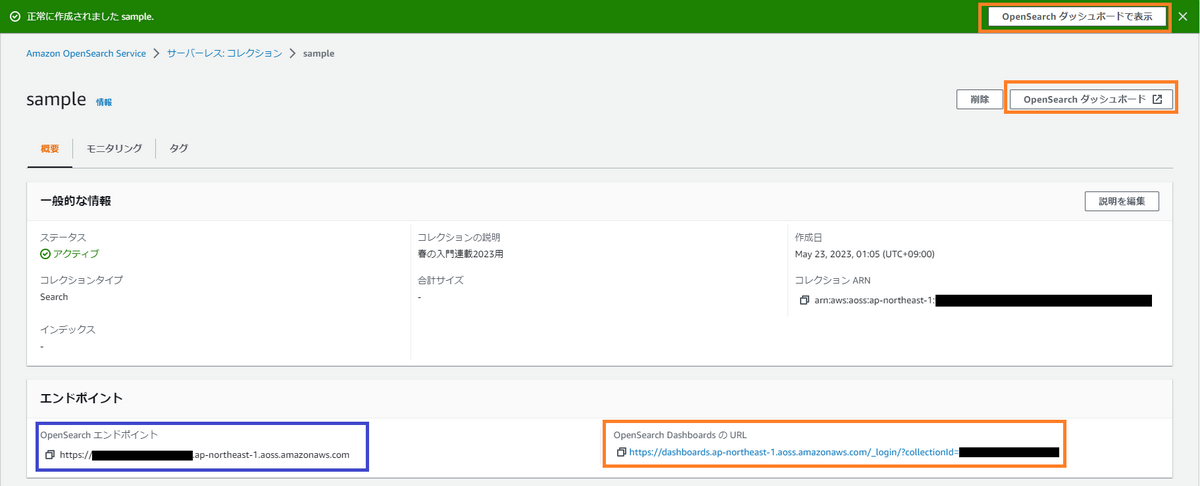 こんな感じでOpenSearchダッシュボードが表示されます。
(以前はログイン画面が出ていたのですが、AWSにログインしていると自動でログインされました。便利)
こんな感じでOpenSearchダッシュボードが表示されます。
(以前はログイン画面が出ていたのですが、AWSにログインしていると自動でログインされました。便利)
- ダッシュボードにアクセス
Dev Tools から OpenSearch API を実行する
- DevToolsからAPI実行
先程のOpenSearchダッシュボードの画面にて、右上の「Dev tools」のリンクをクリックします。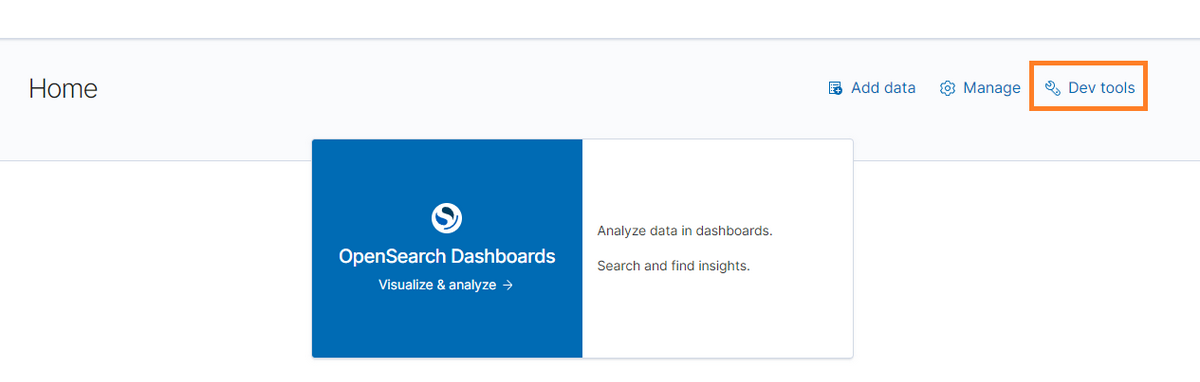
DevToolsの画面が開くので好きにAPIを実行しちゃってください。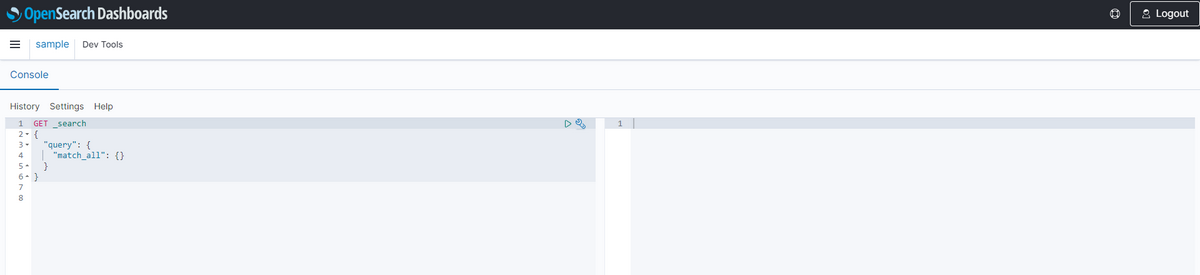
- 試しにデベロッパーガイドのチュートリアルの「ステップ3: データをアップロードして検索する」にならってインデックスの作成を行う
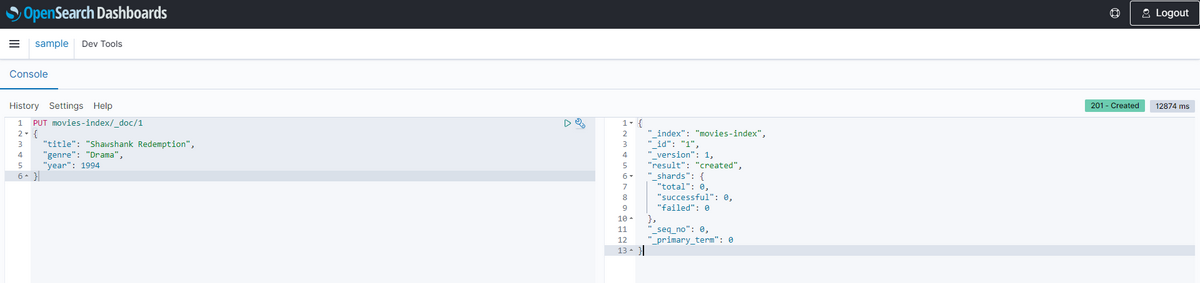
以下を入力し、列の右側に再生ボタンのようなアイコンが出るのでクリック
PUT movies-index/_doc/1
{
"title": "Shawshank Redemption",
"genre": "Drama",
"year": 1994
}作成できた旨のメッセージが出ます。
GET /movies-index/_doc/1を入力、実行してデータが登録できることを確認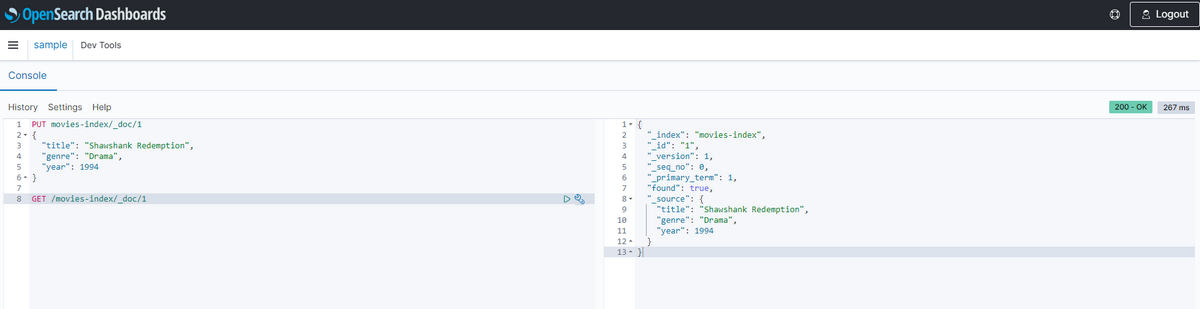 いい感じですね。
いい感じですね。
- DevToolsからAPI実行
あとかたづけ
- 作ったコレクションの削除
削除は簡単で、AWS コンソールの画面に戻りトップにある削除ボタンから押し確認ダイアログで削除すれば完了!
アカウントとパスワードで制御されておりアクセスできないとは言え、インターネット上に公開状態のままなのは良くないため、不要であれば必ず消しましょう。
- 作ったコレクションの削除
まとめ
個人的に、ぱっとOpenSearchが使えるので入門で使うにはちょうどいいのでは? と思っており、まとめられて非常に満足です。
サービス自体としては、OpenSearchダッシュボードがそのまま使えたり、VPC経由ではService版と同様にコンソールアクセスが可能とのことで、移行はスムーズに行えそう。
中でも勝手にスケールアウトしてくれるのは場合により大変楽になるのではと期待しています。例えば、これまでEBSボリュームを度々拡張しなければいけないような運用をしていた場合にもろもろの作業が減るのは幸せですね(本番環境触るの怖い)