はじめに
TIGの原木です。
最近、AWS Kinesis Data StreamとAWS Lambdaを組み合わせたデータストリーミングを扱うシステムで、Lambdaが処理に失敗した場合のリカバリー運用を考える機会がありました。
一般的に、Kinesisのようなメッセージングやイベント駆動型のシステムでは、DLQ(デッドレターキュー)という仕組みを設けます。DLQの目的は、メインアプリケーションが障害やバグにより正常に動かなかった場合、未処理のメッセージやイベントを、メインシステムとは”別口の”キューに隔離、保存することです。これにより、運用者はシステムデータのリカバリーを安全に行うことができます。
本記事では、KinesisとLambdaを組み合わせて使用する際に、DLQとしてDestinationsを使用したフェールセーフ機能を構築した際の知見を共有したいと思います。
3行まとめ
- LambdaのDestinationsの設定には「非同期呼び出し」と「ストリーム呼び出し」があります
- 設定したリトライ回数が超過しないとDestinations(Fail)は呼び出されません
- 「非同期呼び出し」と「ストリーム呼び出し」はFail時に渡されるメッセージの構造が違うため、再処理には注意が必要です
システム説明
アーキテクチャ図をベースにフェールセーフ機能の全体概要について説明します。
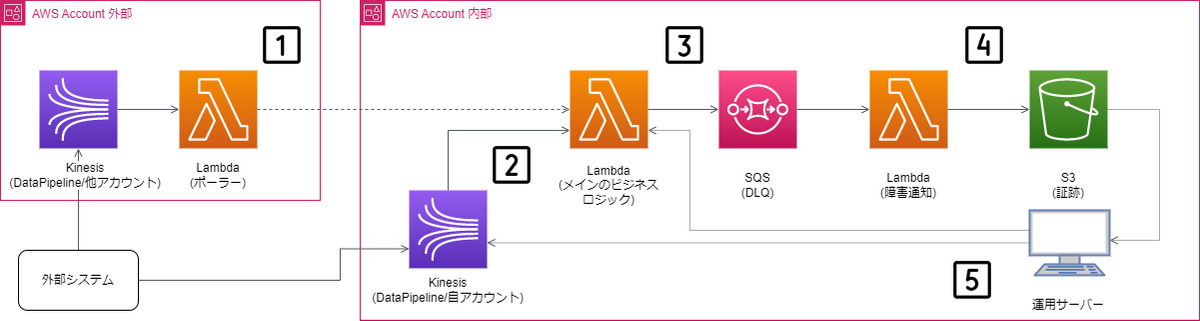
1~2. Kinesisからのデータ連携
システムで利用するデータは外部システムからKinesisを通じて送られてきます。
ここで着目してほしいのがKinesisは、内部アカウントと外部アカウントの両方に存在することです。本来なら、アカウントの違いなど気にせず、同じ設定を持ちまわしたいのですが、現状Kinesisのクロスアカウントはサポートしておらず、異なるアカウントのKinesisストリームから直接Lambdaに接続することはできません(2023年4月現在)
この問題を解決するために、外部アカウントには中間にLambda(ポーラー)を配置して、ポーラーが他のアカウントのKinesisストリームからデータを受信し、Lambda(メインのビジネスロジック)に非同期でデータを渡すようにします。つまり、ポーラーは異なるアカウントのKinesisとLambdaを接続する橋渡しの役割を果たします。
内部アカウントでは、そのような仕組みは必要ないため、直接KinesisとLambda(メインのビジネスロジック)を接続しています。
中継用のLambdaを設けて、データの橋渡しをするやり方はAWSの情報センターにある下記の情報を参考にしています。
「クロスアカウントの Kinesis ストリームを使用して、私の Lambda 関数を呼び出す方法を教えてください?」
https://repost.aws/ja/knowledge-center/lambda-cross-account-kinesis-stream
本文の警告にあるように、この方法が決してベストというわけではありませんが、本案件では様々な事情を鑑みたうえで採用させていただきました。
本文の警告:
この設定により、Kinesis Data Streams を使用する利点の多くがなくなります。この手順の完了後は、シャード内でレコードをブロックしたり、順序付けを作成したりすることはできません。アプリケーションがこれらの特徴を使用する必要がない場合にのみ、この回避策を使用することをお勧めします。
3. Lambdaで処理が失敗した時にSQSへ処理データを送る
Kinesisから送られたデータは、Lambda(メインのビジネスロジック)で処理されます。
Lambda(メインのビジネスロジック)で処理に失敗した場合、LambdaのDestinations(Failure)経由でAWS SQSに処理しようとしていたデータが送られます。 1
SQSはDLQの役割をし、正常に処理できないデータを受け取ります。
4. 失敗した処理データを永続化する
Lambda(運用監視)は、SQSから呼ばれて、Lambda(メイン)で処理に失敗したデータを受け取り、S3に出力します。
5. リカバリー: 運用サーバーからデータを再送する
障害発生の諸々のプロセスを踏んで、状況解消後、S3に出力したデータは運用サーバーから再送されます。
システムの設計で迷ったところ/嵌ったところ
LambdaからDestinations(SQS)が呼ばれない?
Lambdaで処理に失敗してもDestinationsが呼ばれないように見えるケースがあります。
下記項目が適切に設定できているか確認してください。
- LambdaのIAM RoleにSQSへの書き込み権限が付与されているか?
- Lambdaの呼び出し元に応じて「非同期呼び出し」と「ストリーム呼び出し」を適切に設定できているか?
- Lambdaの「リトライ」回数に上限が設定されているか?
これらの設定をしていないとDestinationsが期待通りに動作しません。
ここでは一番最後のリトライ回数について詳細を見ていきます。
Lambdaのリトライ回数を明示的に設定しなかったら?
LambdaのDestinationsはリトライ回数を超過しないと呼ばれません。
AWS側の仕様で、「非同期呼び出し」は上限が2回までと決まっているのですが「ストリーム呼び出し」には上限がありません。そのため、リトライ回数のパラメータを明示的に設定しなかった場合の挙動も違います。
ここで、AWSのリソースをTerraformから操作するためのプラグインであるTerraform Provider for AWSのコードを見てみましょう。
「非同期呼び出し」では次の通りになっています。
"maximum_retry_attempts": { |
リトライ回数は0~2回が選択できること、デフォルトが2回であることが読み取れます。
一方で、「ストリーム呼び出し」では次の通りになっています。
"maximum_retry_attempts": { |
デフォルトの設定が見当たりませんね。明文化されているわけではありませんが、この裏でリトライ回数は「-1」回=無限回が設定されます。したがって、デフォルト設定ではストリーム呼び出しをする側(AWS Kinesis等)のデータ保持期間が切れるまでリトライし続けるため、その間、Destinationsが呼ばれることはありません。
この辺を意識せずに、非同期呼び出しのDestinationsとして作りこんでいた箇所をそのままストリーム呼び出し用に持って行った結果、自分はドはまりすることになりました。
同じKinesisなのにデータが異なる?
非同期呼び出しとストリーム呼び出しでは、処理に失敗してDestinationsを介して渡されるエラーメッセージの形式は異なります。
実際にビジネスロジックでFailして、SQSに渡されたメッセージデータを横取りして確認してみましょう。
{ |
SQSのフォーマット自体は非同期呼び出しとストリーム呼び出しで違いはありません。両者が異なるのはこのメッセージデータのうち、 Body の内容です。 Body には文字列として入っているので、元のJSONデータとして扱うには復元処理が必要です。
# 復元処理と書くと大仰ですが、Pythonで書いたら実際はこんな感じです。 |
こうやって取り出したメッセージデータの違いについてみていきましょう。「非同期呼び出し」では次のようになっています。
{ |
ここで、着目したいのが requestPayload 配下です。この要素には、本来ビジネスロジックで処理する予定だったデータが渡されます。
したがって、このデータを元にリカバリーしたいと思った場合、requestPayload.KinesisRecord を取り出してAWS Lambdaに渡せば、再実行できます。
しかし、「ストリーム呼び出し」では同じ手段ではうまくいきません。Bodyの内容を同様に見てみましょう。
{ |
先ほど要素として存在した requestPayload (と responsePayload) が消えて
代わりに KinesisBatchInfo が追加されていることがわかります。
requestPayload と KinesisBatchInfo の違いは何でしょうか?
requestPayload には、AWS Lambdaを実行時に渡されるデータがそのまま入っています。したがって、requestPayload の下のデータをAWS Lambdaに再送すればそのまま再実行できます。
しかし、 KinesisBatchInfo には Kinesisから渡されたデータは入っていません。代わりに、Kinesis内のデータ=レコードを示すいわゆる “ポインタ” にあたる情報が入っており、この情報を元に、Kinesisからレコードを見つけて再送する必要があります。
この辺の手順は AWSの公式ドキュメント「AWS CLI を使用した基本的な Kinesis Data Stream オペレーションの実行-ステップ 3: レコードを取得する」に詳しい記載があります。
リカバリー処理の実装は、両者の違いを踏まえて行う必要があります。
まとめ
以上、AWS Kinesisから呼び出されるLambdaのリカバリー処理についての解説でした。最後に、比較表を掲載します。
| No | AWS Lambda(メインロジック)の呼び出し方 | 自システムでの利用シーン | リトライ処理(デフォルト) | リカバリー処理を実装するために必要な要素 | リカバリー処理の実装方法 |
|---|---|---|---|---|---|
| 1 | 非同期呼び出し | 異なるAWSアカウントからのKinesisデータ連携 | 2回 | requestPayload | Lambda(メインロジック)を呼び出して requestPayloadを渡す |
| 2 | ストリーム呼び出し | 同じAWSアカウントからのKinesisデータ連携 | 無限 | KinesisBatchInfo | KinesisからKinesisBatchInfoを元にシャードイテレーターを通じてレコードを取得し、 再びKinesisに送信する |
運用側では当然両者のデータの違いを意識したくなかったのでリカバリー処理のためにツールを実装しました。二種類の異なるコードを書きつつ、両者とも元はKinesisのデータなんだけどなっていう、もったいない? 気持ちがありつつも、違いについて勉強になりました。
Kinesisのクロスアカウントサポート来てほしいです…
- 1.私信なのでコメントで補足します: そもそも、Lambdaを非同期で呼び出して処理に失敗した場合、データの送信先として「DLQ」と「Destinations」を選ぶことができます。どちらを使ってよいかAWSを最近使いだしたユーザーには判断が難しいところだと思います。両者を比較しても「DLQでできることは全部Destinationsでできるよ」という推しの弱い結論しか出てこないのではないでしょうか。そもそも両者が似たような機能なのは必然なのかもしれません。時系列でみてみると、DLQが2016年、Destinationsが2019年と、Destinationsが後発組です。そのためか、DLQの既存ユーザーのためにDLQとDestinationsが両方利用できるように残してるのでは? (だから、似た機能なのか)と読み取れる記述がテックブログにあります。「Destinations and DLQs can be used together and at the same time although Destinations should be considered a more preferred solution. 」(DestinationsとDLQは同時に使用できますが、Destinationsの方がより好ましいソリューションです) これを見る限りでは「AWS公式の資料でもういっそ、DLQの後継機能がDestinationsだから、Destinationsを使いましょう」ってはっきり言いきっちゃってほしい、とぼやきたいところです。あえて機能面に踏み込むなら、Destinations経由で渡されるメッセージにはAWS LambdaのARNが入っているのでコールバックが楽だし、失敗時だけでなく成功時でもハンドリングやメトリクスを取得したい機会が来るから機能拡張の容易な「Destinations」を選択しようというのが今できる説明かなと存じます。 ↩