最近読んだ書籍の中で非常に良質な内容でしたので紹介したいと思います。少しでも多くの方に興味を持ってもらえることを期待しています。

はじめに
私自身がデータ管理(データマネジメント)という観点でここ数年様々な検討を行ってきていますので前提としてその背景について簡単にまとめてみます。
かつてオンプレミスで運用を行っていた時は企業内のデータは完全に管理されていました。データウェアハウスを導入してデータの集約・加工は行われていましたが、専門チームがデータ仕様確認やデータ提供までもすべての責任を担っていました。品質は高いのですが利用者からの要望(新しいデータの提供、仕様の変更)の対応についてはスピード大きな制約がありました。また大規模なデータを扱うためには多大なコストが必要という制約もあります。
クラウド技術による「スモールスタートを可能とするインフラ」「大規模なデータを扱うための適切な技術要素」を利用して一気にクラウドアーキテクチャの利用が増えました。クラウドベンダーからの積極的な情報展開もあってデータ基盤としてデータレイクアーキテクチャを利用するという考えが普及した感があります。データレイクではデータを集中して管理するのではなく、利用者が自分たちで自由に安全に利用できるための基盤を整備するという考え方です。
これによりDX化のスピード要求に答えることができてめでたしと思いたいところですが、発展的、継続的に利用ができるのかという点については課題があります。多くの場合「生データそのまま配置しておくので利用者(システム)が自由に使ってください」というアプローチですが、それだけだと「誰(チーム)がそのデータに責任を持つのか」というものが不明確になりがちです。ここがあいまいだとビジネスの変化(データの変化)が発生した際に、データ利用者が追従していくことが難しく足かせになることが容易に想像できます。関係者が少人数であれば密なコミュニケーションが可能なため「データ集めておいたのでご自由にどうぞ」というのは成立しますが、関係者が増えていくとそれは難しくなります。
クラウド前、クラウド後という環境の変化に関するこれらの背景は本書の1章「データ管理の崩壊」でも触れられています。この点の問題意識は私の感覚に非常に近いものがあります。
本書では共通基盤としてのデータレイクプロジェクトの6割が失敗してしまうという言葉が引用されていますが、あながち間違いでもないかもしれません。
エンタープライズアーキテクチャのベストプラクティス
本書のサブタイトルである「エンタープライズアーキテクチャのベストプラクティス」で目指すものは一言でいうと以下です。
すべてのデータを1つのサイロに集めるのではなく、ユーザーが自分たちで簡単かつ安全にデータを流通、利用、活用できるような方法に移行する
これを実現するためのデータ管理についてのフレーム(知識体系)については、DAMA(Data Management Association) によって、DMBOK(Data Management Body of Knowledge)があります。DAMAホイール図として11個の知識体系が示されていてその図は見たことがある方も多いのではないかと思います。
The Global Data Management Community
本書もそのフレームは活用して議論が展開されていますが、DAMAホイール図の項目についてなぞっているだけの内容にはなっていません。DMBOKについてはデータ基盤を整備するエンジニアにとってはとらえどころのない話が多く、理解が難しいのが実情ではないかと思われます。ついついモノづくりが先行してしまい今見えている課題(やりたいこと)だけの個別最適化となる例が多いように思われます。
本書では、「データ統合と相互運用性(Data Integration & Interoperability)」にかなりの重点(むしろそこがメインとして)をおいて記載されています。
- データ統合
3つのアーキテクチャの活用について紹介されています- RDS(Read-Only Data Store)アーキテクチャ
- APIアーキテクチャ
- ストリーミングアーキテクチャ
- 相互運用性
データ提供側からデータ利用側の一連のフローの中ででどこを責任範疇とするのかという責任分界点についての解説
データ統合はクラウドアーキテクチャをベースとした概要の解説となります。論理モデルの解説で具体的なプロダクトについては本書では深く触れられていません。こちらは様々な資料もネット上で公開されているのでデータ連携に携わった人であれば改めて確認する必要はないかもしれません。ここでの紹介は省略します。
データの相互運用性
本書の一番の読みどころは2つ目の「相互運用性」についての解説であると考えます。「誰がそのデータに責任を持つのか」というデータの責任範囲(境界)についての考察です。
本書で紹介されている概念図を1枚だけ引用させてもらいます(少し改変しています)。
データレイヤはデータ流通を行う要素となる、RDS(Read-Only Data Store)、API基盤、メッセージング基盤、その組み合わせを包含するもので、論理的なものを表しています。
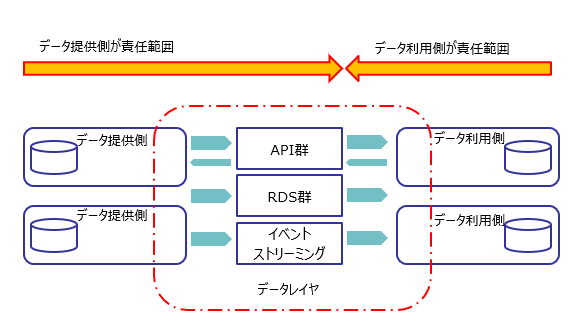
ここでのポイントは2つです。
- データの流通はデータレイヤを通じて行われる
- データ提供チーム(すなわちオリジナルデータの所有者)は データレイヤを通じてデータ利用側に渡すところまで責任を持つ
本書はこれらを基本原則として、一貫性をもってまとめられています。
この考えはある意味当たり前という印象を受けるかもしれませんが、現実の場面であいまいになりがちな「データはだれが管理すべきか」という点を重視してアーキテクチャ設計の基本原則に組み入れる形で紹介してくれている点が本書の優れた点であると考えます。
本書ではDDD(ドメイン駆動設計)の概念を引用して説明しています。アプリケーションの境界(ドメイン)を明確に(強制的に)定義するのと同じく、データについても責任範囲を明確化してガバナンスの基本方針とします。具体的はデータ提供チームがデータ利用チームが利用しやすいようにデータを提供するところまでが責任範囲として定義するという考え方です。データを提供する手段(アーキテクチャ)はデータ要件により決定すれば良いのですが、提供内容(利用しやすいデータモデル、データ仕様)についても責任を持つことになります(責任を持つのはデータ基盤の整備チームでもデータを利用するチームではないということです)。データレイヤを通じてデータを流通させますが、データレイヤの具体的な実装は責任範囲に従い厳密に分離します。
データ基盤におけるアーキテクチャ設計をするにあたってデータマネジメント( データの相互運用性)方針が重要であるということが腹に落ちるのではないかと思います。現実の場面においては、個別の事情や実態に合わせた考え方が当然必要にはなるのですが、方針検討において参考になるはずです。
しみじみとする文を引用しておきます。
- 「このような中央機能を構築するためには、個々のチームが統合パターンやツールに関する決定権を放棄する必要があります。これには抵抗があるでしょう。社内政治的な選択が必要になるかもしれません」
- 「このようなデータランドスケープの近代化には、現実的なアプローチが必要です。なぜなら、密結合されたランドスケープからの移行は非常に難しいからです。単純なデータフローから小さく始めて、徐々に拡大していくことでドメインやユーザーはメリットを意識し、組織の競争力を高める新しいアーキテクチャに貢献したいと考えるようになります」
- 「データサービスを自分たちで導入し、データサイロを他のサービスで置き換えるだけのチームは「データスプロール(補足:無計画なデータ量とその種類の広がり)」のリスクを抱えるようになります」
- 「スケールアップのためには絶え間ないコミュニケーション、貢献、そして強力なデータガバナンスが必要です」
最後に
本書はタイトルの「大規模データ管理(エンタープライズアーキテクチャのベストプラクティス)」あるように、システムアーキテクチャではなく、エンタープライズ領域のデータマネジメントについて本質的な話をまとめてくれている良書です。
以下のようなDAMAホイール図にあるデータマネジメントの一通りについても(エンジニア目線で)紹介されています。
- データガバナンス
- データセキュリティ
- データの価値化(データ利用)
- マスタデータ管理(MDM)
- メタデータの活用
データマネジメントについて自分のかかわっているプロジェクトにあてはめて思考してみるのも有意義ではないかと思います。ただしあくまでも参考文献なので自分自身での解釈が必要であるという点は忘れなく。