前回のエントリーで、コンポーネント単位のステートをがちゃがちゃ更新していくという、オブジェクト指向型(オブジェクトの境界がコンポーネント)の考え方から、より小さな状態のインタラクションになっていくよ、という話を紹介しました。
ビジネスロジックのアーキテクチャとしては、DDD本には以下の2つが書かれています。
- ドメインオブジェクト(オブジェクト指向)
- トランザクションスクリプト(手続き型)
DDD本はご存知のようにドメインオブジェクト押しなのですが、現実にはトランザクションスクリプトもよく使われますね。ただ、リアクティブな設計はこの2つとも違いますね。2つの要素A, Bがあって、Aの処理の結果を受けて処理Bを走らせる場合。だれがこの関連を知っているか、というところが違います。
オブジェクト指向だと、AがBを知っていて、AからBに通知します。「オブザーバーパターン」というのはありますが、あれもBがAを監視していると見せかけて、結局中身を分解するとAがBに伝達しているに過ぎません。
トランザクションスクリプトだと、A→Bの順序を知っている神オブジェクトGがいます。
で、Recoilのリアクティブプログラミングですが、Bが処理にはAが必要だ、というのを知っていて、Aが終わったらBのロジックが実行されます。
| 方式 | 流れを制御する主体 |
|---|---|
| オブジェクト指向 | A→BならA |
| トランザクションスクリプト | AとBの両方を知るS |
| リアクティブ | A→BならB |
クリーンアーキテクチャ的には、情報源を知っていないといけない、ということで不安で動悸と眩暈がする人もいるかもしれませんが↓の次の図を見てもらえれば次の2つの参照に分かれていることがわかります。
- サイドバーコンポーネント→検索条件のselector
- 検索条件のselector→検索処理のselector
検索処理にあたって、上流のサイドバーのパネルへの依存が発生しているわけではなく、その緩衝地帯のオブジェクトがいて、相互にそれが依存している形になりますので、酷いことにはならなそうです。
なお、リアクティブプログラミングはパフォーマンス重視で並列性のための仕組みとしても発展してきています。その中には、publisher/subscriberの仕組みで通信するものもあり、必ずしもRecoilとは依存の考え方が同じにはならないこともあります。
DFDを書いてみる
雑にざっと作ったコードですが、こんな感じになりました。atom/selectorのうち、いくつかを公開APIとしてexportして、他のコンポーネントから触れるようにしています(非公開のものはほとんどは省略しています)。
完全にコンポーネントに閉じていて、外からアクセスしないのでhooksのstateを使っているのはAppコンポーネントのGraphvizのソースとレンダリング表示の切り替えぐらいでした。
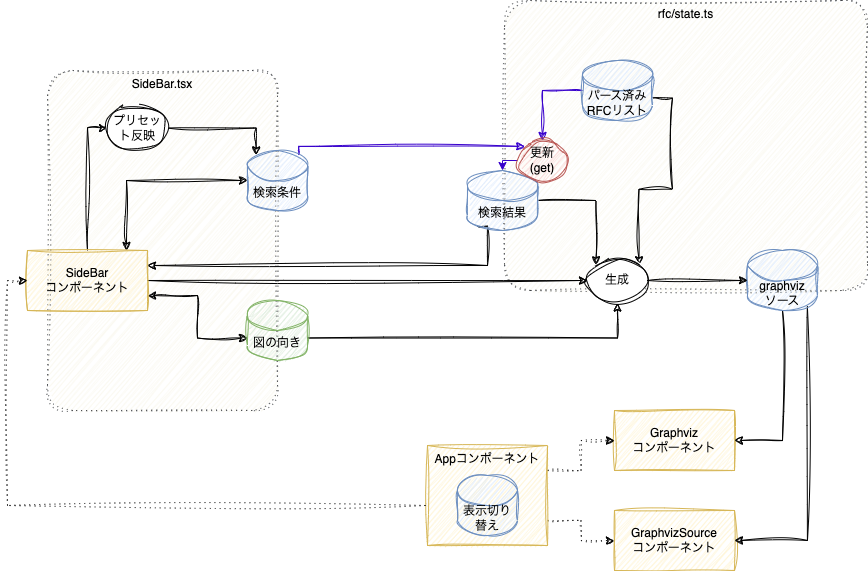
「図の向き」はシンプルにatomをそのまま公開してしまっていますが、読み込み専用のselectorと、外部から変更をトリガーするイベント(Reactで使えるようにuseCallback()を作成するカスタムフック)をいくつか公開し、変更はそれぞれが属するモジュール(Reactコンポーネントやら、データロジックのコード)の中に閉じさせると、カプセル化的によさそうです。コンポーネントとRecoilの要素はファイルを分ける、というのはやる必要はない気がします。コンポーネントが読み書きの主体となっているRecoilの状態はコンポーネントの中に定義してしまった方が編集とかはしやすいです。
Reduxと比べると、他のコンポーネントから触らせるためにわざわざストアを作ってreducerを作ったりしなくてもいいのでとても楽ですね。
相互依存なのではないか?
単純に図だけを見ると、相互に依存しあっていて、「依存は一方通行にしよう」とか「相互参照は良くない」というよく言われる原則に反しているように思うかもしれません。
ですが、この層を新しい「レイヤー」として考えてしまえば、逆にシンプルな構成に見えるんじゃないかと思います。たとえReduxのようなものを作っても結局同じようなグローバルなデータストアが1つでき、全員がそこに依存関係で結びつくので、結局は同じことです。
むしろ、コンポーネントに閉じたこま細かいリアクティブな処理はそのままコンポーネントの中に閉じ込めておけるので、グローバルなストアのようにレイヤーが余計に太ることはありませんし、必要な相手との間にのみ依存が発生するので必要な要素同士に限定される分、「おおきな1つのストア」よりも依存度は小さくなります。
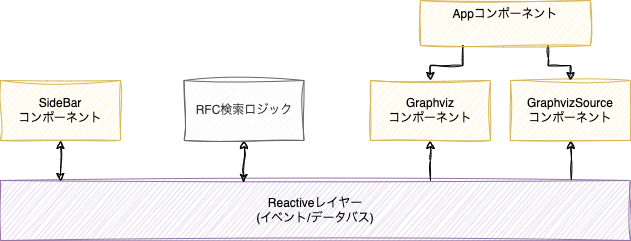
まあ大規模開発するなら、DFDのようなものは書き残しておいた方が良いですね。あるいは、コード解析してグラフ構造を図示するようなものを作るか。
機能の量の割にコード量が少ない秘密
Recoilの場合は、すでに説明したように、ストアへの読み書きではストアの宣言だけをすればよく、ストアの内容変更のサンクなどを逐一実装する必要がない点がボイラープレートのコード量を減らしています。
サーバー通信に関して言えば、エラー処理、ローディング中かどうかの判断なども組み込まれた状態なのでエラー処理とか本流以外のコードが大幅に減ります。SWRを使えばコード量の増加ゼロでstale-while-revalidationという高速化&自動更新の仕組みが得られます。
サーバー実装でもこのアーキテクチャは使われるのか?
サーバー実装の中でこれらの考え方が活用できるかというと、3つの視点があると思います。
1つ目は通常のController/Handler/Service(UseCase)/Repositoryといったよくあるウェブフレームワークの構成上で活用できるかどうかです。ここに関してはまず使えないでしょう。フロントから送られてくる情報をもとにクエリーを組み立ててDBアクセスして返すだけですので、リアクティブな層を作ってやりとりをするのはCPUと電力の無駄かと思います。
2つ目はチャットなどのリアルタイムの同期処理で、この場合はオンメモリで状態を持ち続けていてやり取りをするのでリアクティブな仕組みがあると助かる気がします。複数繋がっているウェブフロントエンドに的確に情報伝達させる仕組みとか、だいたい毎回手作りになると思うので、リアクティブな考えは役にたつんじゃないかと思います。Go用のRecoilみたいなの作ってみたい気持ちがあります。
3つ目はウェブフロントエンドのリクエストを起点に、連鎖的にバッチ処理などを起動していくなど、1つのリクエストに閉じない連携では当然ありな気がします。もともとDFDもそちらからの由来なので、むしろこちらが本流で、そことシームレスにウェブフロントエンドも繋がっていくような設計になると面白そうだな、と思います。
実装Tips
フォームイベント処理
フォームと関係ないロジックはがしがし繋いでいけば良いのですが、フォームと繋ぐところは多少コードが必要です。
フォームと繋げるのはuseState()と基本的に同じです。atomを作って、それに対する書き込みイベントを呼ぶだけです。ただ、useCallback()でコールバックを作って変更処理を行う・・・みたいなのを何個もやるのは面倒なのでカスタムフックを1つ作りました。
function useRecoilWithReact<T extends string|boolean>(state: RecoilState<T>): [T, (e: React.ChangeEvent<HTMLInputElement>) => void] { |
これがあれば、atomを作って、その値取得&変更コールバックを取り出して、<input>に設定するところはかなり薄くできます。
const includesState = atom({ |
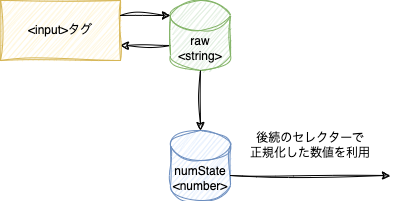
型変換
atomは型を決めたらそれと同じ型でないと入力ができません。effectで変換もできません。フォームは文字列で情報を扱うが、取り出す値は数値にしたい、というのはよくあると思いますが、その場合はフォームとやりとりする文字列のatomと、それを受けて数値に変換するselectorをペアにすればよさそうです。
実際に書いてみたコードでは無効な値の時のnullも返すのでコードがちょっと複雑になっていますが、シンプルにするとこんな感じです。
// 数値にできる文字以外がきたら過去の値を入れて元に戻すeffect。不正な文字を除外 |
こんな感じの構成ですね。全角半角変換とかも組み込んだりできますね。
Recoilが安定版ではない問題
もっとも、Recoilはまだバージョンが0.7.7だし、リポジトリのOrganizationが facebookexperimental だし、それが元で敬遠されたり、という話も聞きます。ただ、Reactも16.xになる前は0.16.xのままだったし、セマンティックバージョニングなにそれ? という世界であるし、APIもUNSTABLEなものは区別されていて、なおかつほぼデバッグ目的のものばかりなので、もう使ってもいいのでは? という気はしています。
ReactiveXとの違い
ReactiveXもリアクティブで、要素間のつながりをプログラミングする必要があります。すごい大量のデータが少しずつ流れてきてそれを間引く必要があるとか、途中で加工するとか、そいういうのに便利なオペレーターや関数はたくさんありますが、以前Angularで触った時は使いにくいしわかりにくいな、と思った記憶があり、同じリアクティブでもだいぶ体験が違うな、と思いました。改めてRecoilの使いやすさと比較して、ReactiveXを使いつつRecoilチックに使うには以下のような制約を加えればいい気がします。
- 完了というステータスは使わない
- 流れる1つ1つのデータが完全なデータ(配列を分解して流したりはしない)という制約を課す
- atomは
BehaviorSubjectを使って実現。next()で値を投入するだけ(他のものは使わない)しか値の投入は認めない - seledtorは
Subjectで、他の要素に.pipe()で繋いだ上で、.subscribe()に上流の値が変更されたときの処理を実装(selectorのgetの処理) - selectorで上流の値が複数ある場合は
combineLatest().subscribe()だけを使う
これでだいぶ使い勝手が近づけられそうな気がします。もちろん、Suspense対応とかErrorBaundaryなどの機能はないので、ローディング中とかは別途作り込みが必要になりますが・・・rxjsを触ったことがありますが、ちょっとの違いでプログラミングのしやすさがだいぶ違うな、というのは印象的でした。
まとめ
Reactでちょっと大規模な開発というと、たくさんの状態管理の仕組みが混ざりがちです。Recoilを使えば、既存のhooksと同じような構成の状態管理の仕組みを使いつつ、アプリケーション全体に簡単に展開できます。UIの状態管理も、ロジック内のデータの流れも、同じ仕組みの中で構成できるのは良いです。コンポーネントを跨いで状態のやりとりをするところでボイラープレートのバケツリレーコードや、中央集権のストアの読み書きをしなくても良くなります。
また、全部を同じ仕組みに載せたとしても、可視性・不可視性を考えて、exportするかしないかをきちんと定義すれば、そんなにスパゲティにならずに済みそうです。もちろん、DFDはきちんと書いてあげる方がさらに良いとは思います。hooksのstateを他のコンポーネントに渡したり、イベントで変更を行ったりするコードで、うっかり変更が無限ループになったりとかしていたのと比べると、トラブルは少ないんじゃないかな、と思います。
今回は小さいプログラムでしたが、大きなプロジェクトへの展開も問題なさそうです。ぜひ今後も使っていきたいと思います。