はじめに
こんにちは、SAIG/MLOpsチームでアルバイトをしている齋藤です。
MLflowは機械学習の管理を扱うツールとして、Optunaはハイパーパラメータを自動調整するツールとしてともに広く使用されているツールです。MLflowとOptunaを同時に利用した際に、Optunaが複数回試行することによってMLflow上にrunが大量に生成され、MLflow上で試行結果が見づらくなります。
本記事では、大量に生成されるrunに親のrunを付与することで、MLflowのWeb UIから見やすくする方法を提示します。
課題
Optunaは事前に指定した範囲の中からハイパーパラメータの組み合わせを自動的に選択してモデルを学習して評価するという試行を繰り返すことで、良いハイパーパラメータを探索するツールであり、これにより手作業でハイパーパラメータを調整するのを省けます。
MLflowは機械学習の管理について幅広く扱うツールであり、例えば各実験に使用されたハイパーパラメータや性能の記録などが出来るため、実験の再現などに役立ちます。
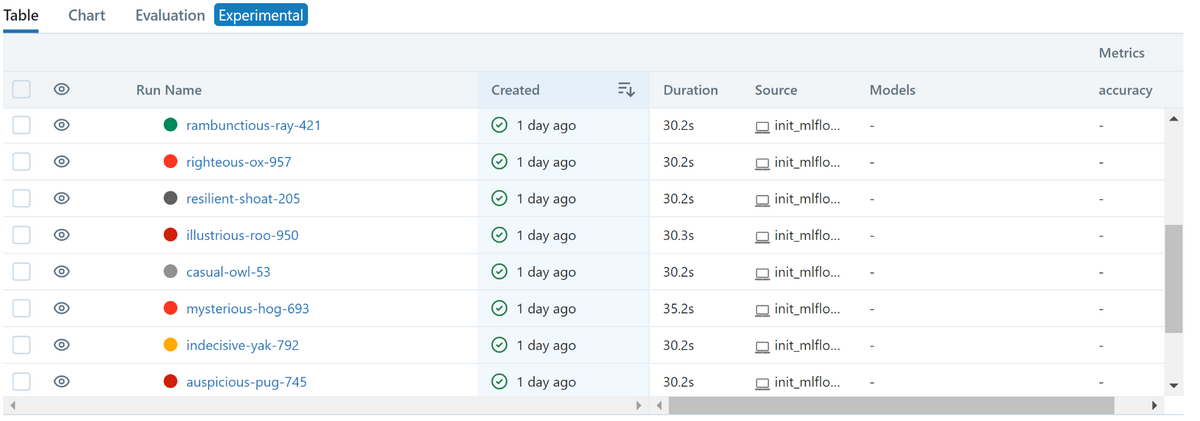
これらは大変便利なツールなのですが、これらを組み合わせて使用した際、画像のようにMLflow上で結果を見た際に大量のrunが生成されて、結果一覧が見づらくなります。特に、条件を変化させてOptunaによる最適化を実行させた場合に、前回までのOptunaによって生成されたrunと今回分のrunの見分けが付けにくくなるという問題が発生します。
課題の解決
方針
MLflowではrun毎にタグを設定できますが、その中でもシステムタグと呼ばれるタグがあり、MLflowの中で特殊な意味を持ちます。mlflow.parentRunIdというタグはシステムタグの1つで、このタグに親のrunのIDを設定すると、Web UI上で親子のrunがネストした形で表示されるようになります。
そのため…
- MLflowで空のrunを実行する。
- 1で実行したrunを目的関数の中で親のrunとして設定する。
…という2つの手順を踏めば、Optunaによって生成される大量のrunを1つの親runに結び付けることができます。
実装
1. MLflowで空のrunを実行する
まずMLflowで親のrunとなる空のrunを実行します。
この時のrun_idは次に必要になるため保存しておきます。
with mlflow.start_run(experiment_id=0) as run: |
2. 1で実行したrunを目的関数の中で親のrunとして設定する
runにタグを設定するにはmlflow.set_tag関数を使用すれば出来ます。
sklearnのSGDClassifierの最適化を例にすると、目的関数は次のようになります。
def objective(trial) -> float: |
実装全体として次のようになります。
import mlflow |
結果
上のコードを実行すると、Optunaによって実行された全ての試行がMLflowに送信されます。
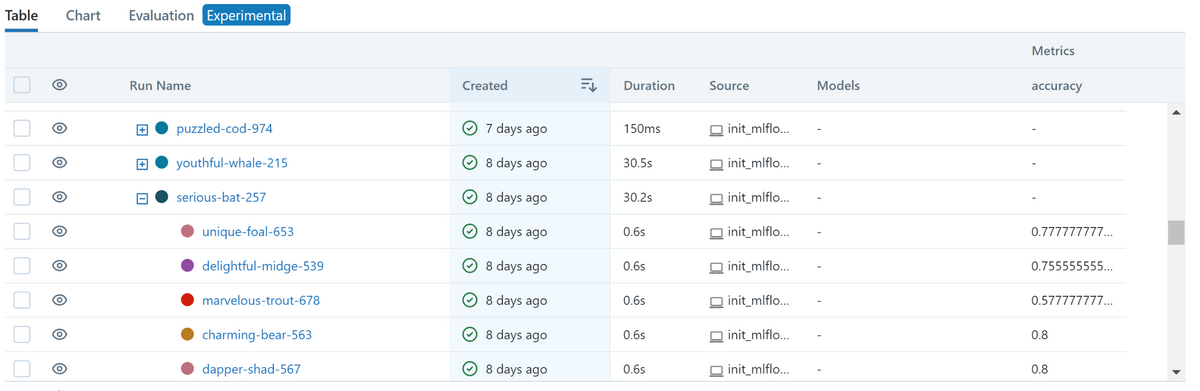
Web UI上では画像のように表示され、Optunaの実行単位ごとにrunがネストして表示されるので見やすくなりました。
おわりに
以上、mlflow.parentRunIdというシステムタグにrunIDを設定するとWeb UI上でrunがネストして表示されることを利用して、自動生成されるrunをUI上で整理して表示させるという話でした。
MLflowのシステムタグはmlflow.parentRunId以外にも存在するので、それらを利用するとUI上で更なる恩恵が得られるかもしれません。