こんにちは。TIGの伊藤です。
春の入門連載7日目です。
新しいこと、始めたい、知りたい
普段、私の仕事はTerraformを主としたIaCを書いてインフラを作ったり管理することなのですが、ふと考えると、IaC以外の部分に対して取り組むきっかけがなく今までやってきていたような気もしてきました。とはいえ、いきなり全然違うことをするのでもなく、自分の裾野を少し広げる方向で考えていたところ、こちらの勉強会を見つけました。
https://grafana-meetup-japan.connpass.com/event/314500/

知り合いが告知していたことや、登壇される方々に興味を持って参加しました。しかし、「Grafanaほぼ触ったことない」の丸腰で行っても得るものが少なくなりそうなので、せっかくならと記事を書いています。
動機としては上に書いた通りですが、監視システムとして同時に持ち上がってくるPrometheusもちょっとだけ入門して、取り組んでいきます。
今回のサンプル
今回のサンプルは以下に置いてあるので、このブログを読んで試してみたい方はぜひ使ってみてください。
https://github.com/kaedemalu/prometheus-grafana-blog
Prometheus
PrometheusはSoundCloud社によって開発されたオープンソースの監視ソフトウェアです。GoogleでKubernetesの前身となったBorgという分散システムがあり、これらを監視しているシステムであるBorgmonからも大いにインスパイアを受けており、いずれも分散システムのモニタリングに最適化されています。
現在ではCloudNative Computing Foundation(CNCF)のGraduatedプロジェクトとしており、多くのユーザを持つOSSとなりました。
仕組みとしては、従来の監視システムでよく使われるZabbixをはじめとしてエージェントを利用してメトリクスを取得、監視するものではなく、管理サーバ側が指定されたサーバに対しメトリクスを取得するPull型となっているのが大きな違いでしょう。
(今回の話では、だいたい下半分くらいが対象の記事となっています)。
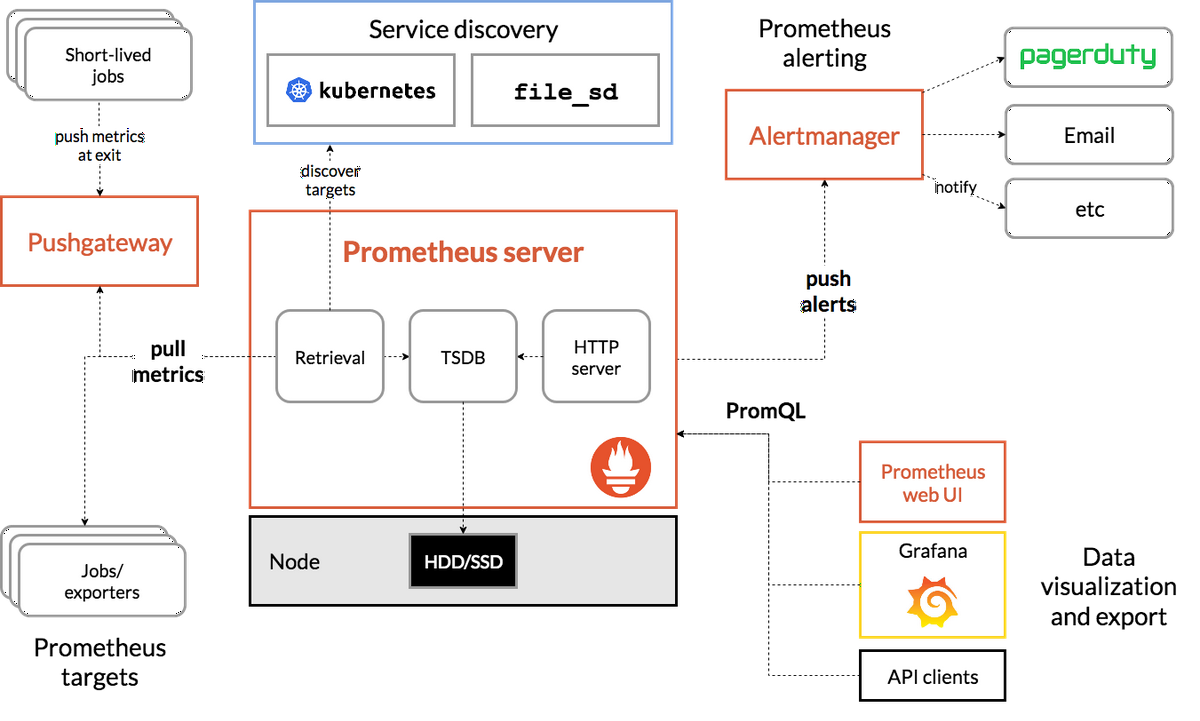
EC2などのIaaSレベルでは、EC2本体のメトリクスを取得して、サーバ自体のリソース監視を行えますが、コンテナアプリであればコンテナアプリから取得される必要があります。この時にPrometheusであればコンテナ自体のメトリクスを取得することが可能になります。エージェントレスであることで従来EC2にインストールしていたエージェント分のリソースを減らすことができます。
アプリケーションを動かしてみる
実際にアプリケーションから取れるメトリクスをPrometheusで見てみましょう。
今回、アプリケーションの言語はPythonを使用し、簡易なAPIサーバを立てるためにFastAPIを用いました。
アプリケーションは以下のようにヘルスチェックパスとPrometheusで/metricsのパスから情報を取得できるようにしました。
from fastapi import FastAPI |
FastAPIでPrometheusのメトリクスを取得可能にするため、以下のライブラリを使用しています。今回はカスタマイズをかけていないですが、がっつり使い込むことを考えるとさらに作り込める余地はありそうです。
https://github.com/trallnag/prometheus-fastapi-instrumentator
これでコンテナを起動させ、/metricsにcURLを実行すると以下のようにたくさん情報が出てきます。
$ curl http://localhost:8080/metrics |
それぞれメトリクスがさし示している情報が何なのかを示してくれていて、わかりやすさを感じました。
次にPrometheus自体の設定です。Prometheusの設定にはprometheus.ymlを用いて読み込ませる必要があります。
今回使用したYAMLファイルは以下です。
global: |
job_name以下でメトリクスを取得する対象や取得するためのパスを指定しています。
ソースレベルの設定、確認はここまでで、具体的にPrometheusの設定をしていきましょう。
コンテナを立ち上げた状態で http://localhost:9090/graphにアクセスすると、以下のような画面になります。
そして、検索バーにFastAPIのコンテナの/healthに対して受けたパスの合計が出力される http_requests_totalを入れてみてみましょう。
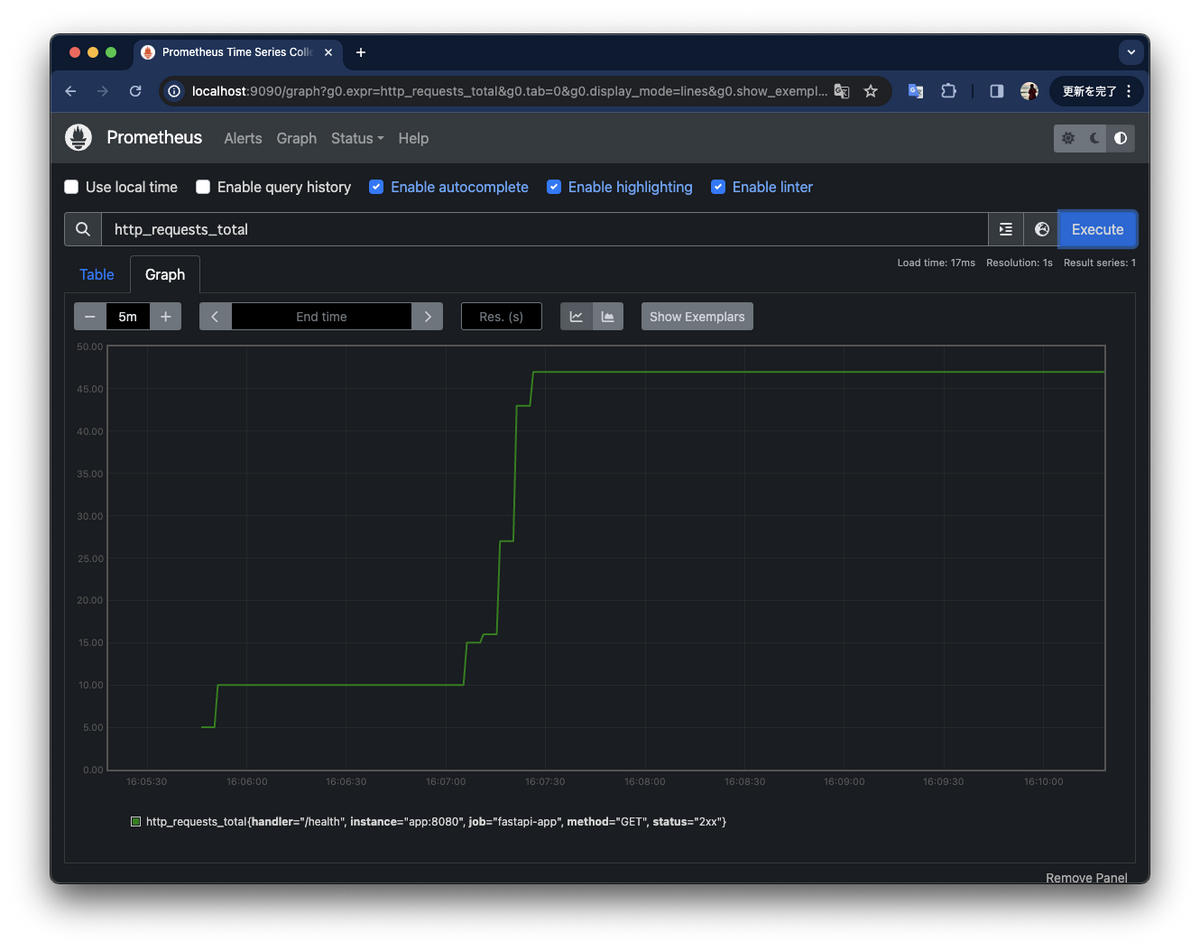
手打ちでcURLを実行してはいますが、リクエストした数だけグラフが上がってきていることがわかります。
このようにアプリケーションから出力されたメトリクスを取得できました。
Grafana
GrafanaはGrafana Labsによって開発されている可視化ツールであり、ダッシュボードの作成はもちろんのことながら前述したPrometheusで実行したクエリをGrafanaでも同等にサポートしています。
PrometheusでできることはわざわざGrafanaでまたやらなくていいのでは? と思いましたが、そこは一旦飲み込んで試してみることにします。
メトリクスの取得を行う
アプリケーションなどは先ほど使っていたものをそのまま利用します。
コンテナを立ち上げたあと http://localhost:3000/loginにアクセスすると、ログイン画面になるので、初期ユーザ/パスワードである admin / adminを打ち込んで、ログインしましょう。(そのあと、初期パスワードの変更を求められますが、今回の検証の本題からは外れるので割愛します)
さて、ログインまでできたので、次はGrafanaからPrometheusを参照できるようにしましょう。サイドバーにある Connections > Add new connection を押下しましょう。たくさんのツールをデータソースにできることがわかります。今回は検索バーにPrometheusと入力し、必要なものを選択しましょう。
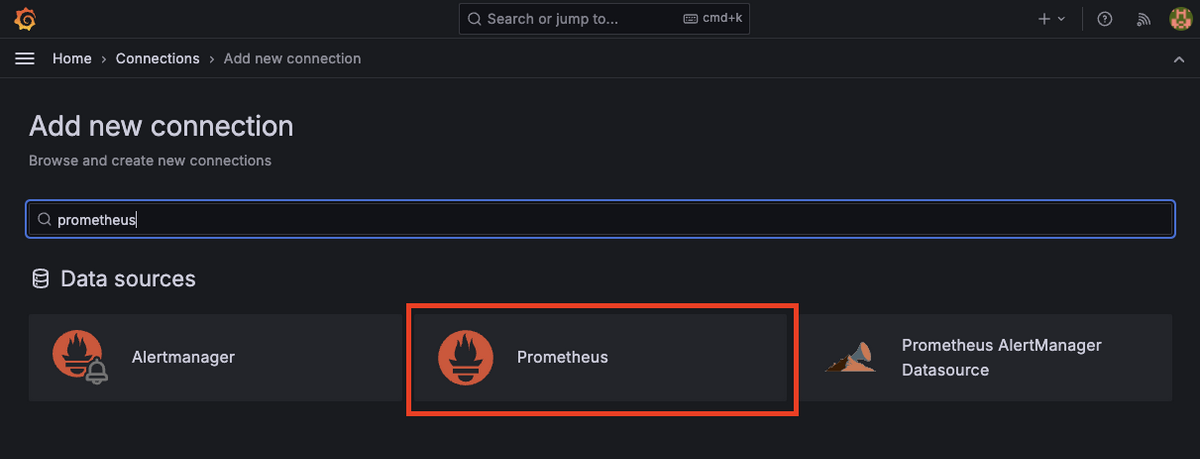
Promehteusを選択し、Add new data sourceを押下してホストの設定をしましょう。Prometheus Server URLに http://prometheus:9090を入力して画面下部にある Save & testを押下して保存しましょう。
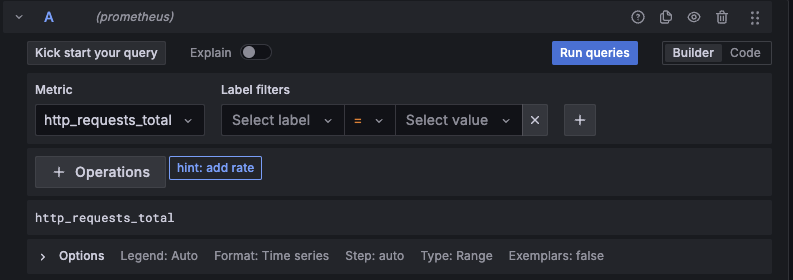
保存ができたら、今度はサイドバーにある、Dashboardsを押下し、Create Dashboard > Add visualization からダッシュボードを作りましょう。ここで、先ほど登録したデータソースが使えるようになります。メトリクスの追加ですが、下のスクリーンショットのように入力できる欄があるので、Metricに先ほどPrometheusでも利用した http_requests_totalを入力して Run queriesを押してみましょう。
そうすると、こちらでもグラフを表示できました(先ほどと概形が異なるのは取得時間が異なるためです)。
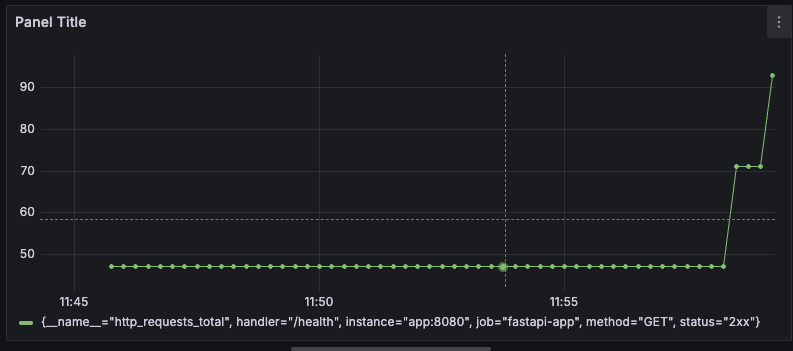
Metricの欄では、Prometheusが取得可能なすべてのメトリクスが使えるので、ものによっては2つ以上取得できるものがありますが、これは Label filtersで絞ることが可能です。
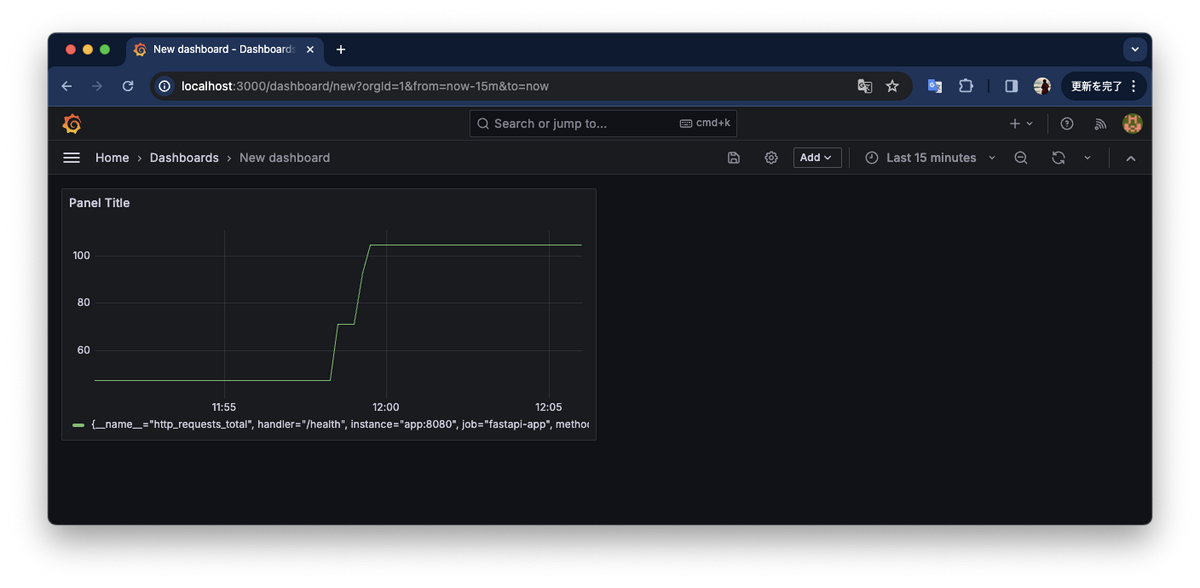
そして、右上の Apply を押下してダッシュボード化しましょう。
どんなことに使えそうか
Grafanaはデータソースの一覧からわかるように多様なソースをサポートしています。今回試したPrometheus以外にもPostgreSQLなどのRDB、各クラウドの監視ツールとの連携、Google Analyticsなどの可視化も行えます。それぞれで可視化の部分はサポートされているとは思いますが、可視化ツールの一元管理、という意味ではGrafanaに多様なデータソースを束ねるというのは良いのかもしれません。
参考)Grafana data sources > Built-in core data sources
まとめ
監視・可視化ツールであるPrometheus、Grafanaを触って動かし、知るきっかけに十分なりました。
今いるプロジェクトではGrafanaのデータソースとして使えるOpenSearchを利用しているので、継続して導入タイミングを伺いながら知見を貯めていきます!