はじめに
こんにちは。TIGの村上です。
私のプロジェクトではライフライン系の案件を扱っています。燃料(灯油や軽油など)を配送するために、なくなりそうなタイミングを知りたいという需要があるため、エネルギー使用量の予測モデルを開発し、運用しています。
本記事では、予測モデルの開発から運用まで手掛けるにあたって、重要なことやノウハウをご共有しようと思います。
※ 本記事では、「電気」「灯油」「ガス」「水」などのライフラインに関わるものを、「エネルギー」とひとくくりに呼称します。
大まかな流れ
リリースまでの大まかな流れは以下のようになります。
- アルゴリズムの考案
- アルゴリズムの評価と関係者との合意
- プロダクト版の開発、テスト、リリース
- リリース後の性能評価
今回は私の実際の経験をもとに各フェーズについて説明します。
1. アルゴリズムの考案
予測モデルを考える過程でとくに重要なのは、「予測精度」「説明性」「運用コスト」になります。これらがそれぞれ、どの程度求められるのかをよく考えながらアルゴリズムを練っていきます。
モデルの種類
一般的に予測モデルを構築する場合、以下のようなモデルの種類を考えます。
- a. 線形予測モデル
- b. 非線形予測モデル
- c. ルールベースモデル
各モデルの特徴をしっかりと把握し、運用まで行えるかを吟味した上で、アルゴリズムの詳細を考えていく必要があります。
a. 線形予測モデル
線形予測モデルは、単純かつ説明性も高い方法です。線形回帰で十分な予測精度が出る場合もあります。運用コストも問題になることはあまりないと思われます。社会実装の例も数多く存在するため、選択肢としてかなり上位に来ます。
一方で、シンプル過ぎる(というか古典的すぎる)がゆえに、現代の機械学習などのイメージとはギャップが大きく、関係者(特にプロダクトオーナーやエグゼクティブ層)にはウケが悪いことがしばしばあります。「こんなのモデルじゃない!」とか「ディープラーニングはどこ?」みたな反応が返ってきたりします。このような場面もあるため、そのモデルの優位性などを慎重に、丁寧に説明することも、プロジェクトを円滑に進める上で重要になります。
b. 非線形予測モデル
非線形予測モデルは、決定木やニューラルネットワークなどの機械学習を用いた方法がメジャーだと思います。これらは人間には捉えられないような未知の特徴を、機械が自動的に抽出し、卓越した予測精度を発揮する可能性があります。
一方で、説明性が低く、なぜそのような結果が出力されたのかを解明したくても、諦めざるをおえない状態になることが多々あります(決定木はこの点、かなりましではあります)。また、学習や推論を行うときに膨大な計算機リソースが必要になり、運用時のコストも膨大になる可能性があります。
ちなみに世間一般でいうところの最新のAIとは、全てディープラーニングのことを指します。経営者なども頭の中では「AI = ディープラーニング」となっている印象があります。視野が狭くなりがちな部分なので、プロジェクトを進める上で注意が必要です。
c. ルールベースモデル
ルールベースモデルは、人間が頑張ってルールを決めてそれに基づいて出力を行うため、関係者間でのアルゴリズムの納得度は最も高いものになると思います。また、説明性の観点でも優れており、少なくともアルゴリズムの開発者であれば、必ずなぜそのような出力になったのかを解明できます。
一方で、高次元データを扱うことは現実的に難しくなります。また、数学的な根拠に乏しくなりがちというデメリットがあり、いわゆる職人技のような側面が出てしまいます。このため、予測精度は良くも悪くも開発者次第になります。運用コストは上記3モデルの中では最も小さくなると思われます。
また、ここまでで紹介した3種類のモデルの中で、最も近年のAIのイメージとの乖離が大きいモデルになります。平たく言うと、ロマンに欠けます。AIに夢見がちな状態の人にルールベースモデルを提案すると、そのギャップからがっかりされることもしばしばあります。プロジェクトを円滑に進めるためにも、事前に十分な説明が必要です。
データセットの性質
ここまで各モデルの特徴についてみてきましたが、肝心の予測精度の観点では、予測の元となるデータセットの性質を理解することがとても重要になります。
この世界のデータは以下の2種類に分けられます。
- a. 非時系列データ
- b. 時系列データ
これら2種類の違いを理解し、適切なアルゴリズムを考える必要があります。
また、実世界のデータ処理について、当ブログに記事がありますので、こちらも合わせてご覧ください。
https://future-architect.github.io/articles/20210423b/
a. 非時系列データ
データに時間的な相関関係がないものです。例えば犬猫の写真を分類する問題を考える場合、いつ撮影した写真なのかは関係ありません。非時系列データの問題を解くことは比較的簡単になりつつあり、特に近年の機械学習技術を用いることで卓越したパフォーマンスを得られる可能性があります。
b. 時系列データ
データに時間的な相関関係があるものです。今回の予測モデルはこちらに該当します。というのも、エネルギー使用量は過去の実績が非常に参考になるためです。例えば、「今日、電気を7[kWh]使ったから明日も7[kWh]くらい使うだろう。明日は少し気温が下がるみたいだから、エアコンを使いそうなので8[kWh]くらいを予測値としておくか」といったことが考えられます。
一方で、一般的に時系列データは機械学習をもってしても予測が難しいことで知られています。それは以下の3点によるものが大きいと考えています。
- 時系列的な相関に着目して特徴量を抽出できるアルゴリズムが発展途上である
- データを集めることが難しい
- データの分布が時間とともに変化する
時系列的な特徴を抽出するアルゴリズム
時系列データ向けのアルゴリズムは古くから研究されてきた背景があります。従来はARIMAモデルなどが活躍し、近年は2017年に誕生したTransformerが最先端技術として用いられています。Transformerは主に自然言語処理の分野で用いられ、ChatGPTなどの代表的な製品の基礎アルゴリズムとなっています。これによって、自然言語の時系列的特徴量の抽出については大きな飛躍を遂げましたが、他の分野の時系列データに関してはもう一押し進歩が欲しいような状況です。
データ収集
時系列データはその性質上、その時にそのデータを観測する必要があります。今日発生したデータを1年前に発生したものとして扱うことは原則できません。従って、膨大なデータを集めるためには、日々コツコツとデータを蓄積させておく必要があります。
データ分布が変化する
現代のデータサイエンス、特に機械学習は、学習に使ったデータセットの分布が今後変わらないことが前提となります。例えば犬猫の分類問題を解く場合は、多様な犬猫データを大量に用意して学習すれば、1年後もそのモデルで精度の高い予測ができます。これは、犬や猫の姿およびその写真データが1年ではほとんど変化しないためです。
分析結果を関係者と議論し、合意が得られればプロダクト版の実装に着手します。
一方で、時系列データは1年後のデータは学習データとは大きく異なっている可能性があります。明日のデータ分布がかなり違うことだって十分考えられます。また、一定周期で定常性が確認できればまだ良いのですが、非定常の場合は最悪です。このように、時系列データはその性質上、非時系列データのように高精度な予測を行うことは困難になります。
エネルギー使用量データの分析
まずはエネルギー使用量データがどのように発生するのかを考えます。当然ですが、人間がエネルギーを使用すると、使用量データが0より大きい値として得られるため、未来の使用量を予測するには、人間にどのようなエネルギーのユースケースがあるのかを考える必要があります。
例: 風呂、料理、暖房、農業、畜産業 etc…
ここで重要なポイントが2つあります。
- その人のライフスタイルによってユースケースが異なる
- 一般家庭と事業所で使い方やその規模が異なる
それぞれについて深く考察していきます。
ライフスタイルによる違い
エネルギーをどれくらい使うかは、その人のライフスタイルにかなり依存します。例えばお風呂が好きな人は、何時間も風呂に入り、おいだきもするかもしれません。一方で、別の人は自宅の風呂は一切使わず、銭湯やジムでシャワーなどで済ませる人もいます。料理をするかどうかも人によって大きく分かれるところです。
さらに、これらのライフスタイルは時とともに変化したり、その日の「気分」によって変化する可能性があります。このように、その人のライフスタイルに依存する部分が大きいことに起因して、使用量データに非定常性が現れていると考えられます。
一般家庭と事業所の違い
これも広義にはライフスタイルの違いに包含できるかもしれませんが、事業所の方が膨大なエネルギーを使うということと、定休日や年末年始休業など、事業所ならではの特徴があります。
また、事業所ではエネルギーの利用用途を2つに分けて考えることができます。
- 事業所で働く人間のために使う
- 製品を作るために使う
このように分けると、前者は一般家庭と同じような使われ方になると考えるのが自然かと思います。一方で後者は、完全にその事業所の都合に依存します。これが大きな不確定要素であり、使用量のボラティリティとスケールが、事業所で特に大きくなる要因だと考えらえます。
エネルギー使用量予測モデル
上記の内容を踏まえて、エネルギー使用量予測モデルにはルールベースモデルを採用しました。主な理由は以下になります。
- エネルギー使用量を予測することは難しい
- 予測精度も大事だが、エネルギーが底をついたり、灯油などのエネルギー源を配送しすぎることを避けられれば問題ない
- 業務上、予測値の計算結果に高い説明性が求められる
- 使える特徴量は少ない
また、モデルは一般家庭と事業所で分けて構築します。それぞれに別々のアルゴリズムを適用し、予測値を計算します。さらに、人それぞれのライフスタイルに依存することから、できるだけその人自身のデータのみを利用して予測を行います。
2. アルゴリズムの評価と関係者との合意
モデルを実装出来たらその予測精度を評価します。この時、目的を改めてはっきりと確認することが大切です。
例えば今回の場合は「エネルギーが底をついたり、灯油などのエネルギー源を配送しすぎないこと」でした。つまり、「予測値は実際の使用量より大きすぎても小さすぎてもダメ」という制約が付きます。従って、どれくらいの誤差まで許容できるのかを考えた上で、どれくらいの誤差がどのような頻度で発生するのかを確認し、あらかじめリスクを把握しておく必要があります。
例えば以下のように、誤差をヒストグラムにplotするのはとても有効な方法です。
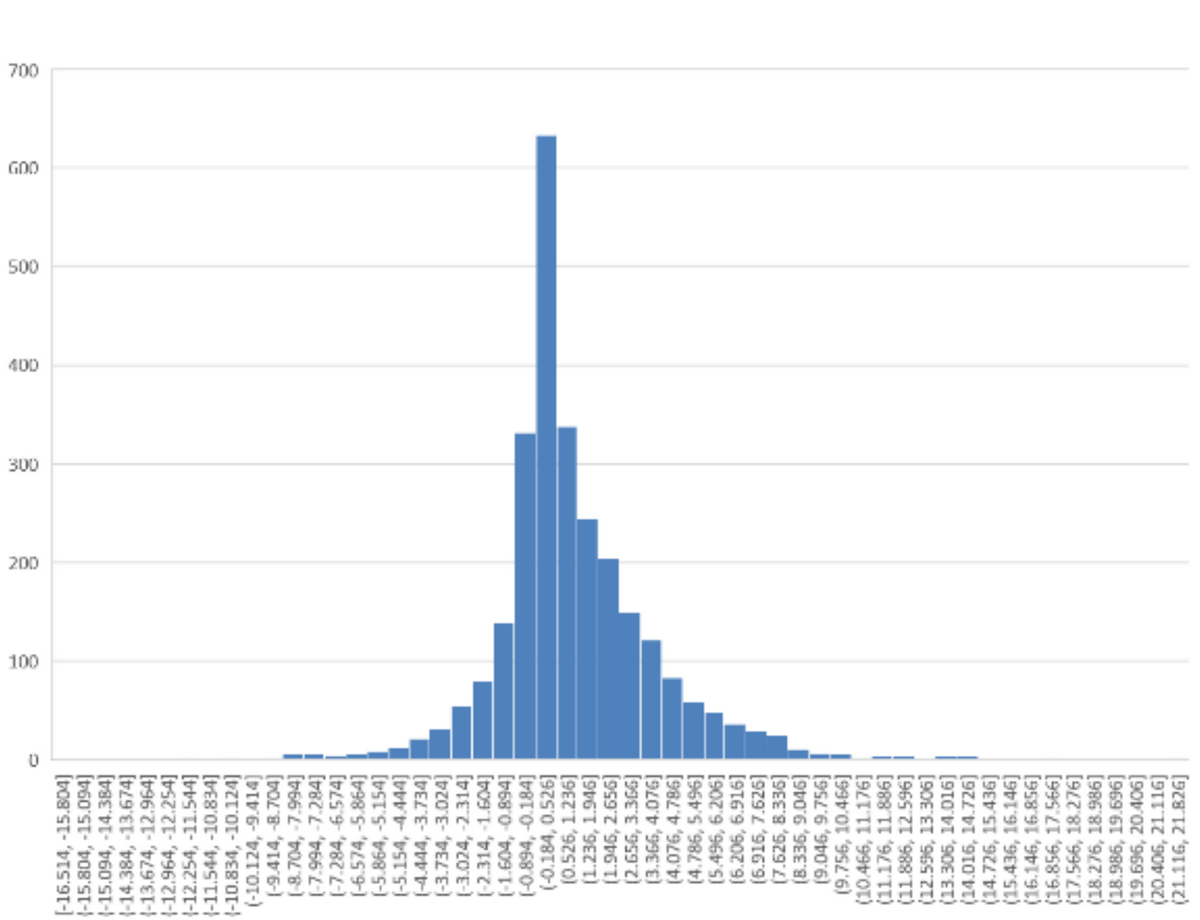
ヒストグラムから許容できない誤差がどれくらいの割合で発生しそうかを見積ります。また、外れ値のデータはどのような理由から発生したのかを分析します。
分析結果を関係者と議論し、合意が得られればプロダクト版の実装に着手します。
評価データとして、アルゴリズムを調整する際に用いたデータ(学習データ)と同じデータを用いてはいけません。これは機械学習でよく言われる過学習を回避するためです。
加えて、学習データよりも未来のデータで評価を行う必要があります。これは上記で説明した、時系列データは分布が変化することに起因します。評価データを学習データよりも未来のデータにすることで、分布の変化に対する頑健性も同時に確認します。ここで未来のデータに対する予測が全くできていない場合は、アルゴリズムを根本的に見直す必要があります。
3. プロダクト版の開発、テスト、リリース
モデルの予測結果に合意が得られたら、プロダクト版を開発します。
大量のデータを処理する必要があるため、例として、私の所属していたプロジェクトでは、インフラ構成を以下のようにしました。
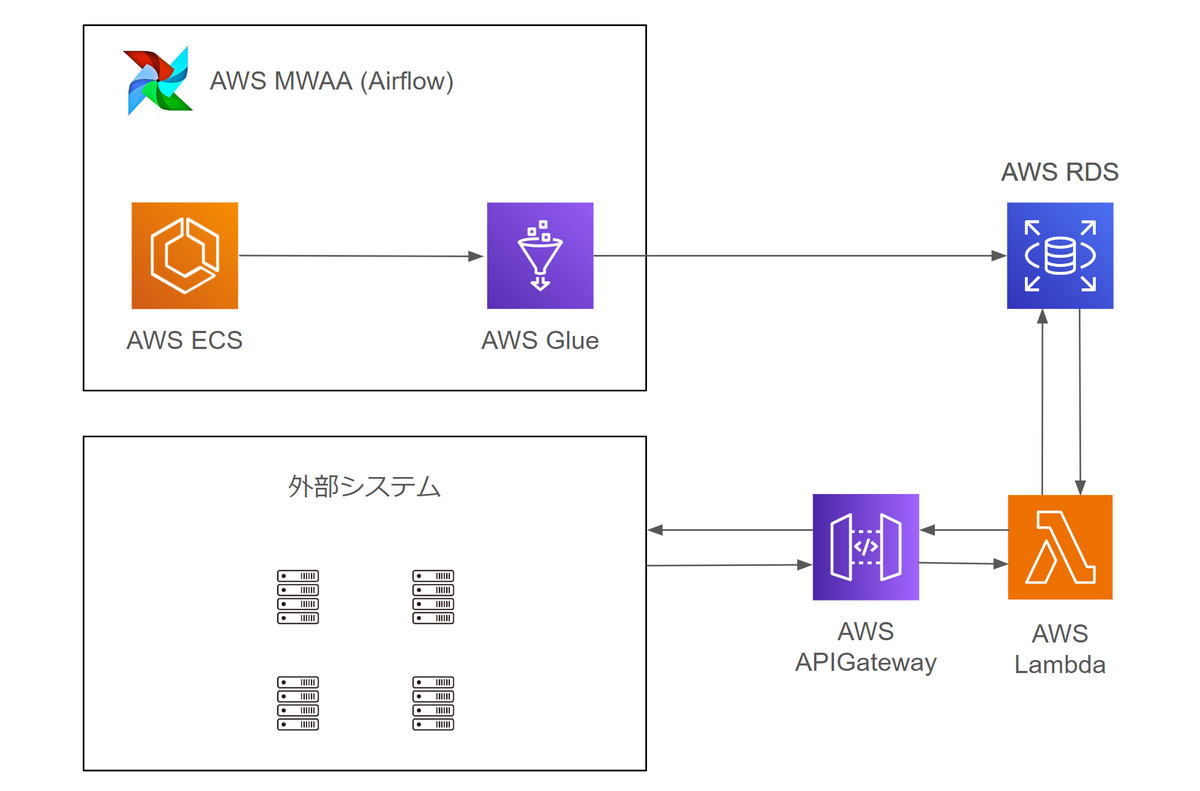
ECSではデータの前処理を担当し、Glueで計算対象の全配送先のエネルギー使用量予測値を計算し、RDSに書き込みます。
予測値を利用したい外部システムから、予測値を返すAPIを呼び出す仕組みです。また、モデルのハイパーパラメータは運用していく過程で変更される可能性があるため、定数を管理する用のファイルに切り出したり、DBで管理するなどの工夫をするのがおすすめです。
Glueではデータ量によっては多くの計算時間が必要になります。特にRDSからデータを読み込む際に多くの時間を要することがあるため、注意が必要です。
開発が終わったらテストを行います。通常の動作確認に加えて、プロダクト版の予測精度が、事前の評価と乖離していないかを確認することも重要なポイントになります。
ここで大きな乖離があった場合は、プロダクト版と事前検証したアルゴリズムに大きな違いがあることになります。入力データが想定と違っていたり、実装ミスなどの可能性があるため、注意深く検証を進める必要があります。また、時系列データであることから、できるだけ長い期間、実際のデータで検証を行った後、リリース判断を行うのが無難です。
4. リリース後の性能評価
リリースした後、一定期間の予測実績が得られた時点で実際の性能評価を行います。リリース前後の決定的な違いは、実際にそのモデルの出力した予測値に基づいて業務が行われることです。
例えば今回のプロジェクトですと、実際に出力された予測値に基づいてエネルギーの残量を計算し、配送を行うため、実環境との相互作用が発生します。この時、得られるエネルギー使用量データの分布が変わる可能性があります。 これはどういうことか、以下のようなエネルギー使用傾向を持った人物を想定して考えてみたいと思います。
- 主に部屋や風呂を温めるために灯油を使う
- 灯油が配送されてからしばらくすると、灯油が底をつくのが不安になり、節約するようになる
- 節約志向になってくると、風呂のおいだきをしなくなる
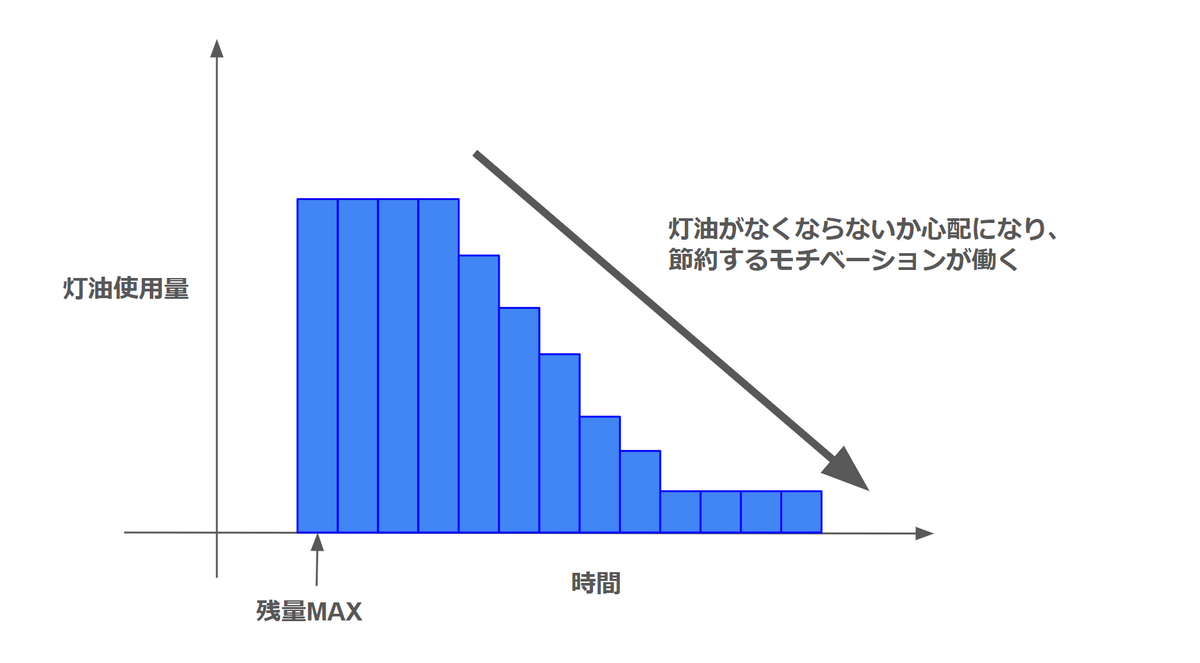
この人の場合、注目すべきポイントは、灯油の残量が灯油の使用量に影響を与えるということです。
この時、予測モデルが予測値を実際よりも大きめに出力する傾向がある場合、この人が灯油を節約しようと思う段階へ入る前に、灯油が配送される可能性があります。その場合、この人からは、節約を頑張った結果である少ない灯油の使用量データが得られなくなります。従って、リリース前とリリース後で得られるデータの分布が異なることになります。
リリース後の性能評価には、このような実環境との相互作用も織り込んだ結果が現れるため、最終的な評価結果として重要な意味を持ちます。最悪の場合、実環境との相互作用が、激しいデータ分布の変化を引き起こし、モデルが使い物にならなくなる可能性もあるので注意が必要です。逆に、この最終的な評価で納得のいく結果が得られた場合、今後も安定した運用が続けられる可能性が高いと考えられます。
おわりに
最後まで読んでいただき、ありがとうございました!
データサイエンスは数学的なバックグラウンドや高度な専門知識が必要な分野ではありますが、その分とても面白くてやりがいがあると思います。加えて、プロジェクトとしてデータサイエンスを取り入れる場合は、関係者への丁寧な説明など、コミュニケーション面でも重要なポイントが多々あります。
昨今もChatGPTなどの登場によってAIの社会実装が次々と進んでいるので、実際のプロジェクトの進め方として参考になれば幸いです!