$ npx wrangler d1 execute dev-d1-futuretechblog --local --file=./schema.sql Proxy environment variables detected. We'll use your proxy for fetch requests. ⛅️ wrangler 3.57.2 ------------------- 🌀 Executing on local database dev-d1-futuretechblog (x-x-x-x-x) from .wrangler/state/v3/d1: 🌀 To execute on your remote database, add a --remote flag to your wrangler command.
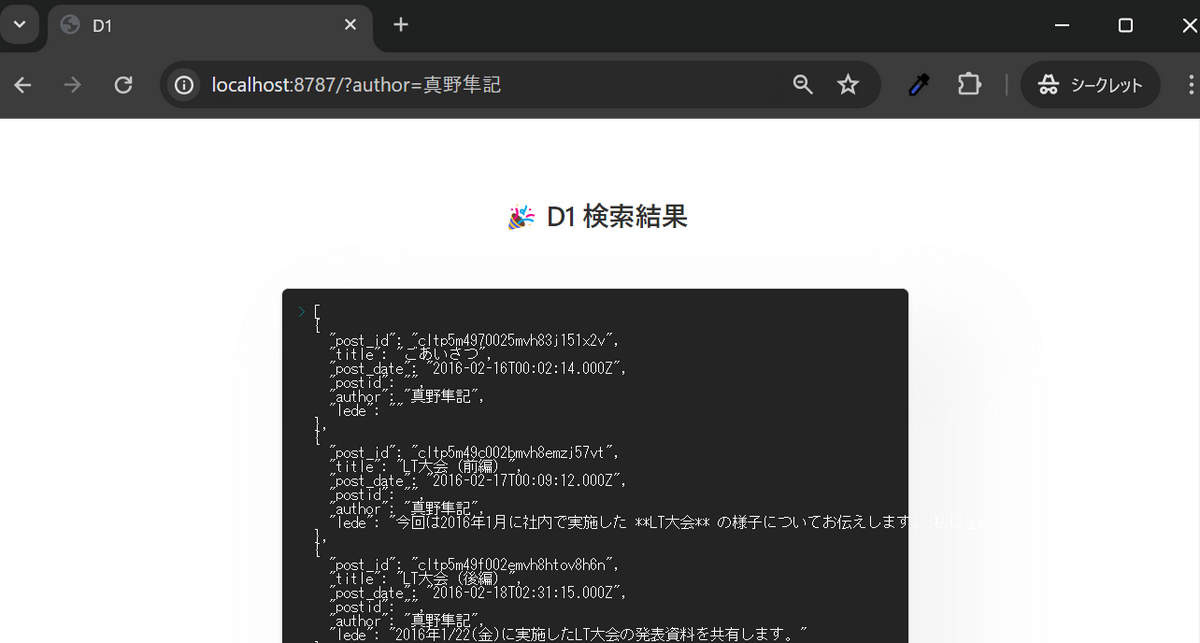
postテーブルの件数を確認すると 1089件と、今の記事件数と一致します。
$ npx wrangler d1 execute dev-d1-futuretechblog --local --command="SELECT count(*) FROM post" Proxy environment variables detected. We'll use your proxy for fetch requests. ⛅️ wrangler 3.57.2 ------------------- 🌀 Executing on local database dev-d1-futuretechblog (x-x-x-x-x) from .wrangler/state/v3/d1: 🌀 To execute on your remote database, add a --remote flag to your wrangler command. ┌──────────┐ │ count(*) │ ├──────────┤ │ 1089 │ └──────────┘
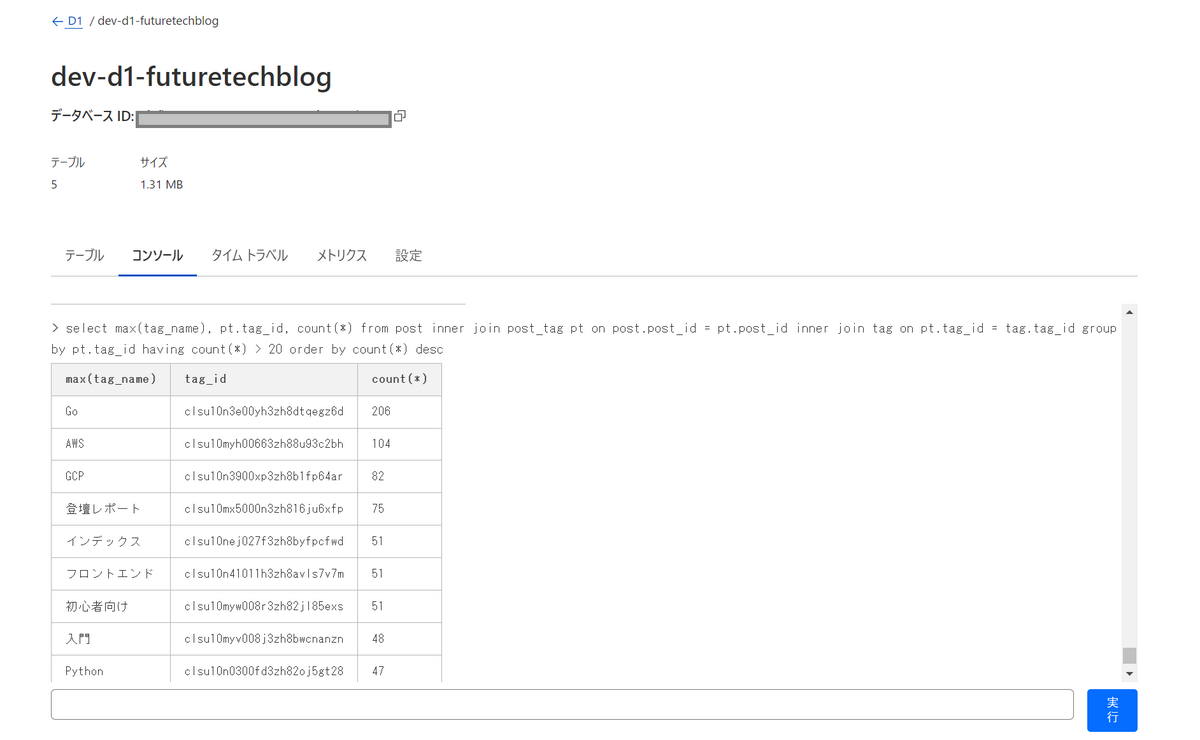
$ npx wrangler d1 execute dev-d1-futuretechblog --remote --file=./schema.sql Proxy environment variables detected. We'll use your proxy for fetch requests. ⛅️ wrangler 3.57.2 ------------------- ✔ ⚠️ This process may take some time, during which your D1 database will be unavailable to serve queries. Ok to proceed? … yes 🌀 Executing on remote database dev-d1-futuretechblog (xxxx-xxxx-xxxx-xxxx-xxxxxxxx): 🌀 To execute on your local development database, remove the --remote flag from your wrangler command. Note: if the execution fails to complete, your DB will return to its original state and you can safely retry. ├ 🌀 Uploading xxxx-xxxx-xxxx-xxxx-xxxxxxxx.xxxx.sql │ 🌀 Uploading complete. │ 🌀 Starting import... 🌀 Processed 7043 queries. 🚣 Executed 7043 queries in 0.18 seconds (5 rows read, 14081 rows written) Database is currently at bookmark 00000001-00000000-00000000-xxxx. ┌────────────────────────┬───────────┬──────────────┬───────────────────┐ │ Total queries executed │ Rows read │ Rows written │ Databas size (MB) │ ├────────────────────────┼───────────┼──────────────┼───────────────────┤ │ 7043 │ 5 │ 14081 │ 1.31 │ └────────────────────────┴───────────┴──────────────┴───────────────────┘ $ npx wrangler d1 execute dev-d1-futuretechblog --remote --command="SELECT count(*) FROM post" Proxy environment variables detected. We'll use your proxy for fetch requests. ⛅️ wrangler 3.57.2 ------------------- 🌀 Executing on remote database dev-d1-futuretechblog (x-x-x-x-x): 🌀 To execute on your local development database, remove the --remote flag from your wrangler command. 🚣 Executed 1 commands in 0.2655ms ┌──────────┐ │ count(*) │ ├──────────┤ │ 1089 │ └──────────┘