本記事は、CI/CD連載 の6本目の記事となります。
はじめに こんにちは。HealthCare Innovation Group(HIG)の山本竜玄です。
本記事では、Gemma3とUnslothを組み合わせて、完全オンプレミス環境でのAIコードレビューができる環境を構築してみました。
フューチャーでは社内開発基盤運用チームが構築・運用するオンプレミス版GitLabを利用していますが、近年注目されるAIエージェントを導入する際に課題がありました。外部APIを利用する場合、セキュリティ審査プロセス、従量課金による予算管理の複雑さ、機密データの外部送信への懸念などが発生します。
そこで、LLMモデルを自前の環境に組み込み、プロジェクト固有のデータで追加学習を行うアプローチを試しました。Gemma3とUnslothの組み合わせにより、RTX 3060 12GBという家庭用レベルなGPU環境でもファインチューニングをしてみました。
結果として、プロジェクト固有のコードレビューAIを構築し、Merge Request連動での自動レビューするというフローを実装できました。本記事では、GitLab CE環境での具体的な構築手順などを紹介します。
背景 オンプレミス環境でのAI活用の難しさ 最近、GitHub Copilot Agent ModeやClaude Code ActionなどのワークフローレベルのAIエージェントが注目される中、企業のオンプレミス環境では以下のような側面があるのではないでしょうか?
上記の課題については、トレードオフな点もあり、悩ましいものです。
しかしながら、2025年時点ではでオープンソースLLMの性能向上、ファインチューニング技術の成熟などがあり、今までよりは低いスペックでのマシンでも利用が現実的になってきました。
これにより、ワークフローレベルのAIエージェントについても自前のオンプレミス環境へ導入が現実的になってきたとも感じます。
技術選定 Gemma3 Gemma3は、Googleが2025年に発表した最新のオープンソース大規模言語モデルです。
Gemma3の主な特徴:
ライセンス: Apache 2.0(商用利用制約なし)
モデルサイズ: 10億〜270億パラメータの豊富な選択肢
多言語対応: 140以上の言語、日本語性能も良好
長文処理: 12万8000のコンテキストウィンドウ
ライブラリ対応: Hugging Face、Ollama、UnSloth等に対応
商用利用も可能なApache2.0ライセンスで提供されていることや、Unslothとの公式サポートによる安定性、あとは公開されてまもなかったので触って見たかったというのが今回の選択理由です。
Unsloth Unsloth 、大規模言語モデルのファインチューニングを効率化するオープンソースライブラリです。名前は「Un-sloth(ナマケモノではない)」に由来します。
Unslothの主な特徴:
ファインチューニング速度を約2倍に向上
GPUメモリ使用量を最大80%削減
通常40GB以上必要なモデルを8GBのGPUで学習可能
近似手法を使わないため、精度の低下なし
バックプロパゲーション(逆伝播)の手動最適化により、無駄な中間計算結果の保存を削減。「Unsloth gradient checkpointing」により中間的な活性化値をシステムRAMに非同期でオフロードし、GPUメモリ使用を大幅に削減していることが特に大きな特徴です。
ローカルPCのGPUリソース(RTX 3060 12GB)でもGemma3-4Bモデルの学習が現実的な時間で完了しそうであったため、今回利用しました。
GitLab環境 GitLabには以下のように複数の提供形態があり、それぞれ異なる特徴を持ちます。
各形態の詳細:
GitLab Community Edition (CE)
無料のオープンソース版
基本的なGit、CI/CD、イシュー管理機能を提供
セルフホストのため完全なデータ管理が可能
商用サポートなし、コミュニティサポートのみ
GitLab.com (SaaS)
GitLab社が運営するクラウドサービス
インフラ管理不要で即座に利用開始可能
データはGitLab社のクラウドに保存
GitLab Self-Managed (Premium/Ultimate)
有料機能付きのセルフホスト版
CE機能 + Premium/Ultimate機能
商用サポート、高可用性、災害復旧機能
また、プランも以下のようなものがあります。
GitLab Duo AI機能の詳細 GitLab Duoは2023年6月にローンチされたAI支援機能スイートで、Code Suggestions(20以上の言語でのコード補完・生成)、Duo Chat(自然言語での対話式AI支援)、セキュリティ支援(脆弱性の詳細説明と自動的なマージリクエスト生成)、プロジェクト管理(イシューやエピックの大量テキスト解析・要約)などの機能を提供します。
▼AI機能のプラン比較
GitLab Duo Self-Hosted(Premium/Ultimate + Duo Enterprise)がとても魅力的ではありますが、以下の理由から既存のGitLab CE + 自前AI構築で今回はトライします。
コスト面: Ultimate + Duo Enterpriseで月額$99+ αは高額
承認プロセス: 社内での新規ツール導入承認に時間がかかる
セキュリティ要件: データが完全にオンプレミス環境内に留まる
既存資産活用: 既存のCI/CDパイプライン、MR連動、セキュリティポリシーをそのまま活用可能
環境構築 ここからは、実際にGitLab環境の構築から、Gemma3の組み込みなどを行っていきます。
紹介するコード例の一部は、AI(Claude)の助けを借りて作成しています。
内容の正確性には注意を払っていますが、AIによる生成物には意図しない誤りや、最適なコードではない可能性も含まれます。
検証環境(ローカルPC) 今回検証に使用した環境は以下の通りです。プライベートのローカルPC上に構築してみました。自作PCとしては、おおよそ15万円程度のものです。
実際の運用環境 本格的な運用では、AWS、GCP、Azureなどのクラウド環境でのGPUインスタンス使用をすることが想定されます。
その際には、大体以下の費用感となります。
これは会社によって異なるでしょうが、APIキーを使用した従量課金でコストが読めないことやセキュリティ懸念の検討をするよりは、説明がしやすい場合もあるのではないかと思っています。
実際の環境構築 ここから実際に手を動かして環境構築をしていきます。
GitLabのセルフホスト版であるCommunity Editionをインストールします。
sudo apt-get update sudo apt-get install -y curl openssh-server ca-certificates tzdata perl curl -sS https://packages.gitlab.com/install/repositories/gitlab/gitlab-ce/script.deb.sh | sudo bash sudo apt-get install gitlab-ce sudo gitlab-ctl reconfigure
上記の再設定には少々時間がかかりますが、完了すると、ブラウザでローカルホストへとアクセスできるようになります。
初期rootユーザーのパスワードを以下で確認します。
sudo cat /etc/gitlab/initial_root_password
これで出力されたパスワードによってログインができ、実際のリポジトリ操作などができるようになりました。
GitLab Runnerの登録 次に、CI/CDパイプラインを実行するために、GitLab Runnerをセットアップします。
GitLab Runnerのインストールを以下で行います。
curl -L "https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.deb.sh" | sudo bash sudo apt-get install gitlab-runner
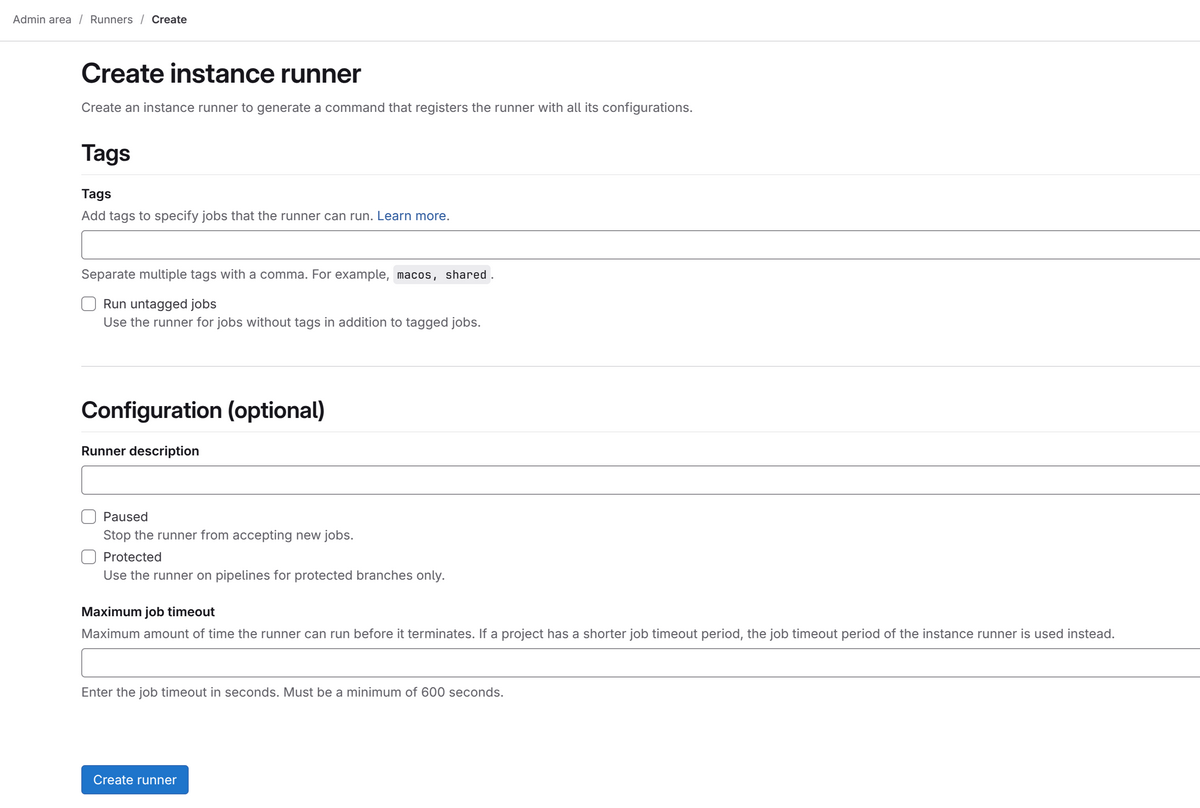
インストール後は、Runnerの登録を行っていきます。ブラウザの画面上で、以下の操作をします。
GitLab の Admin Area > Runners に移動
Create instance runner をクリック以下の設定を入力します
Tags(必須)
Configuration (optional)
Runner description: GPU Runner for AI Training
Maximum job timeout: 7200 (2時間、秒単位)
Run untagged jobs: チェックを入れる
Runner作成後、登録用のトークンが画面上に表示されます。それをもとに、以下のようにコンソールから登録を行います。
sudo gitlab-runner register \ --url "http://localhost" \ --token "glrt-xxxxxxxxxxxxxxxxx" \ --executor "docker" \ --docker-image "nvidia/cuda:12.0-devel-ubuntu22.04" \ --description "GPU Runner for AI Training"
Docker Executorの追加設定 次に、GPUを使用するため、GitLab Runnerの設定ファイルを編集します:
sudo nano /etc/gitlab-runner/config.toml
すでに設定情報が記入されているため、[[runners.docker]]セクションに以下を追加します。
[[runners.docker]] gpus = "all" devices = ["/dev/nvidia0" , "/dev/nvidiactl" , "/dev/nvidia-uvm" ]
設定変更後、Runnerを再起動します。
sudo gitlab-runner restart
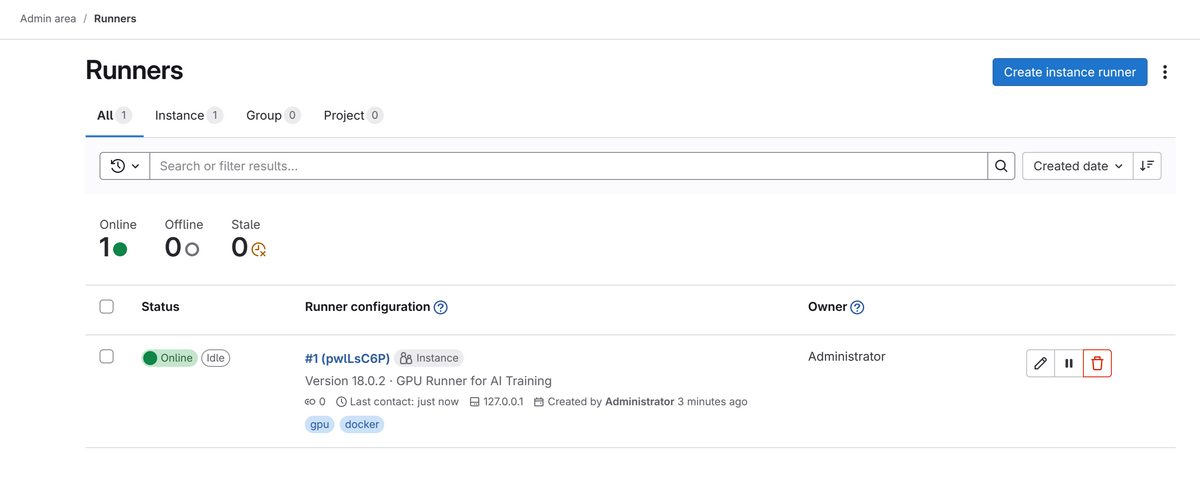
ここまででRunnerが登録できたはずなので、以下のようにGitLabの画面上で確認できます。
GPU対応のCI/CDパイプラインを実行するために、NVIDIA Container Toolkitをセットアップします。
Dockerのインストール sudo apt-get update sudo apt-get install -y docker.io sudo systemctl enable docker sudo systemctl start docker sudo usermod -aG docker $USER
sudo wget -qO /etc/apt/keyrings/nvidia-container-toolkit.asc \ https://nvidia.github.io/libnvidia-container/gpgkey echo "deb [signed-by=/etc/apt/keyrings/nvidia-container-toolkit.asc] https://nvidia.github.io/libnvidia-container/stable/deb/$(dpkg --print-architecture) /" | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list sudo apt-get update sudo apt-get install -y nvidia-container-toolkit sudo nvidia-ctk runtime configure --runtime=docker sudo systemctl restart docker
ここまででGitLabの設定、Runnerの設定周りは完了です!次からは、プロジェクト固有の設定をしていきます。
本記事では割愛しますが、Bot用のユーザー発行やAccess Tokenの作成、CI/CDの環境変数への設定なども追加で行っています。
プロジェクトの作成と学習データ準備 GitLabの新規構築からやっているため、記事用のサンプルを配置していきます。
プロジェクト構成 今回の記事用の構成ですが、以下のようにしてプロジェクトを作成しています。
src配下に、実際のアプリ周りのコードが置かれる想定です。
sample-project/ ├── .gitlab-ci.yml ├── src/ ├── training_data/ │ ├── code_examples.jsonl │ └── review_comments.jsonl ├── scripts/ │ ├── train_gemma3.py │ ├── code_reviewer.py │ └── requirements.txt └── docker/ └── Dockerfile
それっぽいwikiなども作成しておきます。
業界知識が問われそうなものも適当に作成してみます。
これらのソースコード、wiki、PRへのコメントなどをうまくできれば、リポジトリに特化したソースレビューができそうですよね。
GitLab APIを活用したデータ収集 プロジェクト固有のコードレビューAIを構築するため、GitLab APIを使用して以下のデータを自動収集します。
ソースコード: プロジェクト内のPython、JavaScript等のファイル
Wikiページ: 設計ドキュメントやコーディング規約
Merge Requestコメント: 過去のレビューコメントとディスカッション
GitLab APIのアクセスには、Personal Access Token(read_api権限)を使用します。CI/CD環境では、プロジェクト変数としてGITLAB_TOKENを設定することで自動実行が可能です。
詳細は以下などを確認ください。https://docs.gitlab.com/api/rest/
例えば、プロジェクト内の全てのMerge Request(オープン・クローズ問わず)の基本情報を取得するには以下のようなエンドポイントにリクエストします。
GET /api/v4/projects/{id }/merge_requests
上記のようなエンドポイントたちにリクエストして、WikiやMRコメントなども集めるようにしました。
実際の実装は以下のようなイメージとなります。
wiki_url = f"{self.api_base} /projects/{self.project_id} /wikis" response = requests.get(wiki_url, headers=self.headers)
長いので折りたたみますが、以下のようにしています。
データ収集スクリプトのPython実装例
import requestsimport jsonimport osfrom pathlib import Pathfrom typing import List , Dict import timeclass GitLabDataCollector : def __init__ (self, gitlab_url: str , access_token: str , project_id: int ): self.gitlab_url = gitlab_url.rstrip('/' ) self.project_id = project_id self.api_base = f"{gitlab_url} /api/v4" if os.environ.get('CI' , '' ) == 'true' : if os.environ.get('GITLAB_TOKEN' ): self.headers = {"PRIVATE-TOKEN" : os.environ['GITLAB_TOKEN' ]} else : self.headers = {"JOB-TOKEN" : access_token} else : self.headers = {"PRIVATE-TOKEN" : access_token} def collect_source_code (self, branch: str = "main" ) -> List [Dict ]: """ソースコードを収集""" tree_url = f"{self.api_base} /projects/{self.project_id} /repository/tree" params = {"ref" : branch, "recursive" : True , "per_page" : 100 } all_files = [] page = 1 while True : params["page" ] = page response = requests.get(tree_url, headers=self.headers, params=params) if response.status_code != 200 : print (f"ファイルツリー取得エラー: {response.status_code} " ) if response.status_code == 401 : print ("認証エラー: トークンの権限を確認してください" ) elif response.status_code == 403 : print ("アクセス権限エラー: プロジェクトへのアクセス権を確認してください" ) break files = response.json() if not files: break for file_info in files: if file_info["type" ] == "blob" : if self._is_code_file(file_info["path" ]): file_content = self._get_file_content(file_info["path" ], branch) if file_content: all_files.append({ "type" : "source_code" , "file_path" : file_info["path" ], "content" : file_content, "language" : self._detect_language(file_info["path" ]) }) page += 1 time.sleep(0.1 ) print (f"ソースコードファイル: {len (all_files)} 件" ) return all_files def collect_wiki_pages (self ) -> List [Dict ]: """Wikiページを収集""" wiki_url = f"{self.api_base} /projects/{self.project_id} /wikis" response = requests.get(wiki_url, headers=self.headers) wiki_data = [] if response.status_code == 200 : wikis = response.json() for wiki in wikis: wiki_detail_url = f"{wiki_url} /{wiki['slug' ]} " detail_response = requests.get(wiki_detail_url, headers=self.headers) if detail_response.status_code == 200 : wiki_detail = detail_response.json() wiki_data.append({ "type" : "wiki" , "title" : wiki_detail["title" ], "content" : wiki_detail["content" ], "format" : wiki_detail.get("format" , "markdown" ) }) elif detail_response.status_code == 403 : print (f"Wikiへのアクセスが拒否されました" ) time.sleep(0.1 ) elif response.status_code == 404 : print ("このプロジェクトにはWikiが設定されていません" ) elif response.status_code in [401 , 403 ]: print (f"Wiki取得エラー: {response.status_code} " ) print (f"Wikiページ: {len (wiki_data)} 件" ) return wiki_data def collect_merge_request_comments (self, limit: int = 100 ) -> List [Dict ]: """Merge Requestとそのコメントを収集""" print ("MRコメント収集中..." ) mr_url = f"{self.api_base} /projects/{self.project_id} /merge_requests" params = {"state" : "all" , "per_page" : 50 } mr_comments = [] page = 1 total_collected = 0 while total_collected < limit: params["page" ] = page response = requests.get(mr_url, headers=self.headers, params=params) if response.status_code != 200 : print (f"MR取得エラー: {response.status_code} " ) break merge_requests = response.json() if not merge_requests: break for mr in merge_requests: if total_collected >= limit: break mr_data = { "type" : "merge_request" , "mr_id" : mr["iid" ], "title" : mr["title" ], "description" : mr["description" ] or "" , "comments" : [] } comments_url = f"{self.api_base} /projects/{self.project_id} /merge_requests/{mr['iid' ]} /notes" comments_response = requests.get(comments_url, headers=self.headers) if comments_response.status_code == 200 : comments = comments_response.json() for comment in comments: if not comment.get("system" , False ): mr_data["comments" ].append({ "author" : comment["author" ]["name" ], "body" : comment["body" ], "created_at" : comment["created_at" ] }) mr_comments.append(mr_data) total_collected += 1 time.sleep(0.1 ) page += 1 print (f"MR: {len (mr_comments)} 件" ) return mr_comments def _get_file_content (self, file_path: str , branch: str ) -> str : """ファイルの内容を取得""" file_url = f"{self.api_base} /projects/{self.project_id} /repository/files/{file_path.replace('/' , '%2F' )} /raw" params = {"ref" : branch} response = requests.get(file_url, headers=self.headers, params=params) if response.status_code == 200 : try : return response.text except UnicodeDecodeError: return "" return "" def _is_code_file (self, file_path: str ) -> bool : """コードファイルかどうか判定""" code_extensions = { '.py' , '.js' , '.ts' , '.java' , '.cpp' , '.c' , '.h' , '.hpp' , '.go' , '.rs' , '.php' , '.rb' , '.scala' , '.kt' , '.swift' , '.cs' , '.fs' , '.clj' , '.hs' , '.ml' , '.r' , '.m' , '.sh' , '.sql' , '.html' , '.css' , '.scss' , '.less' , '.vue' , '.jsx' , '.tsx' , '.yaml' , '.yml' , '.json' , '.xml' } return Path(file_path).suffix.lower() in code_extensions def _detect_language (self, file_path: str ) -> str : """ファイル拡張子から言語を推定""" extension_map = { '.py' : 'python' , '.js' : 'javascript' , '.ts' : 'typescript' , '.java' : 'java' , '.cpp' : 'cpp' , '.c' : 'c' , '.go' : 'go' , '.rs' : 'rust' , '.php' : 'php' , '.rb' : 'ruby' , '.html' : 'html' , '.css' : 'css' , '.sql' : 'sql' , '.sh' : 'bash' , '.yaml' : 'yaml' , '.yml' : 'yaml' , '.json' : 'json' , '.xml' : 'xml' } ext = Path(file_path).suffix.lower() return extension_map.get(ext, 'text' ) def convert_to_training_data (source_code: List [Dict ], wiki_data: List [Dict ], mr_comments: List [Dict ] ) -> List [Dict ]: """収集したデータを学習用フォーマットに変換""" training_data = [] for code in source_code: if len (code['content' ]) > 100 : training_data.append({ 'instruction' : f'{code["file_path" ]} ({code["language" ]} )のコードをレビューしてください' , 'input' : code['content' ][:1500 ], 'output' : f'このコードは{code["language" ]} で書かれています。コードの品質向上のため、型ヒント、エラーハンドリング、パフォーマンスの観点でレビューします。' }) for wiki in wiki_data: if wiki['content' ]: training_data.append({ 'instruction' : f'{wiki["title" ]} について説明してください' , 'input' : '' , 'output' : wiki['content' ][:1000 ] }) for mr in mr_comments: if mr['comments' ]: for comment in mr['comments' ]: if len (comment['body' ]) > 20 : training_data.append({ 'instruction' : f'MR「{mr["title" ]} 」に対するレビューコメントを提供してください' , 'input' : mr['description' ][:500 ] if mr['description' ] else mr['title' ], 'output' : comment['body' ] }) return training_data def main (): GITLAB_URL = os.environ.get('GITLAB_URL' , 'http://localhost' ) ACCESS_TOKEN = os.environ.get('GITLAB_TOKEN' , '' ) PROJECT_ID = int (os.environ.get('GITLAB_PROJECT_ID' , '1' )) is_ci_environment = os.environ.get('CI' , '' ) == 'true' if not ACCESS_TOKEN: if is_ci_environment: return collector = GitLabDataCollector(GITLAB_URL, ACCESS_TOKEN, PROJECT_ID) print ("GitLab APIデータ収集開始" ) print (f"URL: {GITLAB_URL} " ) print (f"Project ID: {PROJECT_ID} " ) source_code = collector.collect_source_code() wiki_data = collector.collect_wiki_pages() mr_comments = collector.collect_merge_request_comments(limit=50 ) training_data = convert_to_training_data(source_code, wiki_data, mr_comments) os.makedirs("training_data" , exist_ok=True ) with open ("training_data/code_review_data.jsonl" , "w" , encoding="utf-8" ) as f: for item in training_data: f.write(json.dumps(item, ensure_ascii=False ) + "\n" ) with open ("training_data/raw_source_code.jsonl" , "w" , encoding="utf-8" ) as f: for item in source_code: f.write(json.dumps(item, ensure_ascii=False ) + "\n" ) with open ("training_data/raw_wiki.jsonl" , "w" , encoding="utf-8" ) as f: for item in wiki_data: f.write(json.dumps(item, ensure_ascii=False ) + "\n" ) with open ("training_data/raw_mr_comments.jsonl" , "w" , encoding="utf-8" ) as f: for item in mr_comments: f.write(json.dumps(item, ensure_ascii=False ) + "\n" ) stats = { 'total_training_examples' : len (training_data), 'source_code_files' : len (source_code), 'wiki_pages' : len (wiki_data), 'merge_requests' : len (mr_comments), 'collection_timestamp' : time.strftime('%Y-%m-%d %H:%M:%S' ), 'gitlab_url' : GITLAB_URL, 'project_id' : PROJECT_ID } with open ("training_data/collection_stats.json" , "w" , encoding="utf-8" ) as f: json.dump(stats, f, ensure_ascii=False , indent=2 ) print ("データ収集完了" ) print (f"ソースコード: {len (source_code)} 件" ) print (f"Wiki: {len (wiki_data)} 件" ) print (f"MRコメント: {len (mr_comments)} 件" ) print (f"学習データ: {len (training_data)} 件生成" ) print ("出力ファイル:" ) print ("- training_data/code_review_data.jsonl (学習用)" ) print ("- training_data/collection_stats.json (統計情報)" ) if __name__ == "__main__" : main()
収集したデータの加工 収集されたデータを、Unslothで学習させるためのJSONL形式に変換します。
{ "instruction" : "src/api/main.py(python)のコードをレビューしてください" , "input" : "def get_user(user_id: int):\n return db.query(User).filter(User.id == user_id).first()" , "output" : "型ヒントが適切に設定されていますが、エラーハンドリングの追加を推奨します。存在しないユーザーIDの場合の処理を明示的に行うことで、より堅牢なコードになります。" }
これらで加工したデータを学習させることで、プロジェクト固有のコーディング規約やレビュー観点を学習させることができます。
Gemma3のファインチューニング実装 収集したプロジェクトデータを使用して、Gemma3をファインチューニングします。UnslothライブラリとLoRA(Low-Rank Adaptation)技術を組み合わせることで、限られたGPUリソースでも効率的な学習を実現します。
ファインチューニング実装例
import osimport sysimport jsonimport torchfrom pathlib import Pathfrom datasets import load_datasetfrom unsloth import FastModelfrom trl import SFTTrainer, SFTConfigfrom unsloth.chat_templates import get_chat_template, train_on_responses_onlyos.environ["PYTORCH_CUDA_ALLOC_CONF" ] = "expandable_segments:True" os.environ["CUDA_VISIBLE_DEVICES" ] = "0" def setup_environment (): """環境設定""" torch.backends.cuda.matmul.allow_tf32 = True torch.backends.cudnn.allow_tf32 = True torch.set_float32_matmul_precision('medium' ) try : import unsloth print (f"Unsloth version: {unsloth.__version__} " ) except ImportError: print ("Unslothバージョン取得失敗" ) import transformers print (f"Transformers version: {transformers.__version__} " ) if torch.cuda.is_available(): gpu_name = torch.cuda.get_device_name(0 ) if "RTX" in gpu_name or "Tesla" in gpu_name or "A100" in gpu_name: print (f"GPU {gpu_name} supports bfloat16" ) else : print (f"GPU {gpu_name} precision support needs verification" ) def get_gpu_optimal_config (): """GPU最適設定を決定""" if not torch.cuda.is_available(): raise RuntimeError("CUDAが利用できません。GPUが必要です。" ) gpu_memory_gb = torch.cuda.get_device_properties(0 ).total_memory / 1e9 device_name = torch.cuda.get_device_name(0 ) print (f"GPU: {device_name} ({gpu_memory_gb:.1 f} GB)" ) config = { "model_name" : "unsloth/gemma-3-4b-it" , "model_size" : "4B" , "max_seq_length" : 1024 , "batch_size" : 1 , "gradient_accumulation" : 4 , "lora_rank" : 8 , "lora_alpha" : 8 } return config def load_model_and_tokenizer (config ): """Unsloth公式準拠のメモリ効率的モデル読み込み""" print (f"モデル読み込み中: {config['model_name' ]} " ) model, tokenizer = FastModel.from_pretrained( model_name=config["model_name" ], max_seq_length=config["max_seq_length" ], load_in_4bit=True , dtype=None , trust_remote_code=True , device_map={"" : 0 }, attn_implementation="eager" ) tokenizer = get_chat_template( tokenizer, chat_template="gemma-3" , ) print ("モデル読み込み完了" ) return model, tokenizer def setup_lora (model, config ): """Unsloth公式準拠LoRA設定""" print ("LoRA設定中..." ) model = FastModel.get_peft_model( model, r=config["lora_rank" ], lora_alpha=config["lora_alpha" ], lora_dropout=0 , bias="none" , use_gradient_checkpointing="unsloth" , random_state=3407 , target_modules=["q_proj" , "k_proj" , "v_proj" , "o_proj" , "gate_proj" , "up_proj" , "down_proj" ] ) trainable_params = sum (p.numel() for p in model.parameters() if p.requires_grad) total_params = sum (p.numel() for p in model.parameters()) print (f"学習可能パラメータ: {trainable_params:,} / {total_params:,} ({trainable_params/total_params*100 :.2 f} %)" ) return model def prepare_dataset (tokenizer, data_path="training_data/code_review_data.jsonl" ): """ Unsloth公式Gemma3準拠のデータセット準備 instruction/input/output → conversations → text (chat template applied) """ print (f"データセット読み込み: {data_path} " ) if not Path(data_path).exists(): raise FileNotFoundError(f"データファイルが見つかりません: {data_path} " ) dataset = load_dataset("json" , data_files=data_path, split="train" ) print (f"データ件数: {len (dataset)} " ) if len (dataset) > 0 : sample = dataset[0 ] required_fields = ["instruction" , "input" , "output" ] for field in required_fields: if field not in sample: raise ValueError(f"必須フィールドが見つかりません: {field} " ) print ("データ形式確認完了" ) def convert_to_conversations (examples ): """ Unsloth公式準拠: instruction/input/output → conversations形式 """ instructions = examples["instruction" ] inputs = examples["input" ] outputs = examples["output" ] conversations_list = [] if isinstance (instructions, list ): for inst, inp, out in zip (instructions, inputs, outputs): if inp and inp.strip(): user_content = f"{inst} \n\n{inp} " else : user_content = inst conversations = [ {"role" : "user" , "content" : user_content}, {"role" : "assistant" , "content" : out} ] conversations_list.append(conversations) else : if inputs and inputs.strip(): user_content = f"{instructions} \n\n{inputs} " else : user_content = instructions conversations = [ {"role" : "user" , "content" : user_content}, {"role" : "assistant" , "content" : outputs} ] conversations_list = [conversations] return {"conversations" : conversations_list} print ("Unsloth conversations形式に変換中..." ) dataset = dataset.map (convert_to_conversations, batched=True ) def formatting_prompts_func (examples ): """ Unsloth公式Gemma3準拠のフォーマット関数 conversations → text (Gemma3 chat template + <bos>除去) """ convos = examples["conversations" ] texts = [ tokenizer.apply_chat_template( convo, tokenize=False , add_generation_prompt=False ).removeprefix('<bos>' ) for convo in convos ] return {"text" : texts} print ("Gemma3チャットテンプレート適用中..." ) dataset = dataset.map (formatting_prompts_func, batched=True ) columns_to_remove = [col for col in dataset.column_names if col != "text" ] if columns_to_remove: dataset = dataset.remove_columns(columns_to_remove) print (f"最終データ件数: {len (dataset)} " ) if len (dataset) > 0 : sample = dataset[0 ] if not sample['text' ].startswith('<start_of_turn>' ): print (f"想定外の開始トークン: {sample['text' ][:50 ]} " ) if not isinstance (sample['text' ], str ): raise ValueError(f"データ型エラー: text={type (sample['text' ])} " ) print ("データセット準備完了" ) return dataset def create_training_config (config, output_dir="fine_tuned_gemma3" ): """Unsloth最適化学習設定""" training_config = SFTConfig( dataset_text_field="text" , per_device_train_batch_size=config["batch_size" ], gradient_accumulation_steps=config["gradient_accumulation" ], warmup_steps=5 , max_steps=20 , learning_rate=2e-4 , optim="adamw_8bit" , weight_decay=0.01 , lr_scheduler_type="linear" , fp16=False , bf16=True , dataloader_pin_memory=False , logging_steps=1 , output_dir=output_dir, save_steps=20 , save_strategy="steps" , save_total_limit=1 , seed=3407 , report_to="none" , dataset_num_proc=2 ) training_config.max_seq_length = config["max_seq_length" ] return training_config def train_model (model, tokenizer, dataset, training_args ): """Unsloth学習実行""" print ("学習開始..." ) trainer = SFTTrainer( model=model, tokenizer=tokenizer, train_dataset=dataset, eval_dataset=None , args=training_args, dataset_text_field="text" , max_seq_length=getattr (training_args, 'max_seq_length' , 1024 ), packing=False , ) trainer = train_on_responses_only( trainer, instruction_part="<start_of_turn>user\n" , response_part="<start_of_turn>model\n" , ) torch.cuda.empty_cache() try : trainer_stats = trainer.train() print ("学習完了" ) print (f"最終損失: {trainer_stats.training_loss:.4 f} " ) print (f"学習ステップ数: {trainer_stats.global_step} " ) except RuntimeError as e: if "out of memory" in str (e).lower(): print ("GPU メモリ不足: バッチサイズやLoRAランクを削減してください" ) raise finally : torch.cuda.empty_cache() return trainer def save_model (model, tokenizer, config, output_dir ): """ CI/CD対応モデル保存 推論スクリプトが正確に読み込めるように設定情報も保存 """ print (f"モデル保存中: {output_dir} " ) Path(output_dir).mkdir(parents=True , exist_ok=True ) model.save_pretrained(output_dir) tokenizer.save_pretrained(output_dir) model_config = { "model_type" : "unsloth_lora" , "base_model_name" : config["model_name" ], "base_model_size" : config["model_size" ], "max_seq_length" : config["max_seq_length" ], "lora_rank" : config["lora_rank" ], "lora_alpha" : config["lora_alpha" ], "chat_template" : "gemma-3" , "training_completed" : True , "inference_ready" : True } with open (f"{output_dir} /model_config.json" , 'w' ) as f: json.dump(model_config, f, indent=2 ) print (f"LoRAアダプター保存完了: {output_dir} " ) merged_dir = f"{output_dir} _merged" try : model.save_pretrained_merged(merged_dir, tokenizer) merged_config = model_config.copy() merged_config["model_type" ] = "merged_model" with open (f"{merged_dir} /model_config.json" , 'w' ) as f: json.dump(merged_config, f, indent=2 ) print (f"マージ済みモデル保存完了: {merged_dir} " ) except Exception as e: print (f"マージ済みモデル保存エラー: {e} " ) print (f"CI/CDアップロード対象: {output_dir} /" ) if Path(merged_dir).exists(): print (f"推論用モデル: {merged_dir} /" ) def main (): """メイン処理""" print ("=== Gemma 3 + Unsloth ファインチューニング ===" ) try : setup_environment() config = get_gpu_optimal_config() model, tokenizer = load_model_and_tokenizer(config) model = setup_lora(model, config) dataset = prepare_dataset(tokenizer) training_config = create_training_config(config) trainer = train_model(model, tokenizer, dataset, training_config) save_model(model, tokenizer, config, training_config.output_dir) if torch.cuda.is_available(): memory_used = torch.cuda.max_memory_allocated() / 1e9 print (f"最大GPU使用量: {memory_used:.2 f} GB" ) print ("すべての処理が完了しました" ) except Exception as e: print (f"エラー: {e} " ) print (f"エラータイプ: {type (e).__name__} " ) import traceback print ("詳細なスタックトレース:" ) traceback.print_exc() raise finally : if torch.cuda.is_available(): torch.cuda.empty_cache() if __name__ == "__main__" : main()
学習パラメータ
この設定により、RTX 3060 12GBという比較的手頃なGPU環境でも、約20分程度でプロジェクト固有のコードレビューAIを構築できました。
実際には、プロジェクトの規模やマシンスペックに応じたチューニングが必要になるとは思います。
AIコードレビューシステムの実装 ファインチューニング済みのGemma3を使用して、実際のコードレビューを自動実行するようにしていきます。GitLab CI/CD環境でMerge Request作成時に自動レビューを行い、結果をアーティファクトとして保存します。
推論最適化による高速化 学習済みモデルを推論用に最適化するため、FastLanguageModel.for_inference()を使用します。これにより、以下のメリットが得られます。
メモリ使用量削減: 学習時に不要な勾配計算関連の情報を削除
推論速度向上: KVキャッシュ最適化により生成速度を向上
GPU効率化: 推論専用の最適化でGPU使用率を改善
git diffとの連携による自動レビュー GitLab CI環境では、git diffコマンドでコード変更差分を取得し、AIレビューを実行します。
git diff HEAD~1 HEAD > code_diff.txt python scripts/code_reviewer.py code_diff.txt
生成パラメータの調整
コードレビューに適した応答を生成するため、上記のパラメータを調整しています。
実際には、プロジェクトの規模やマシンスペックに応じたチューニングが必要になるとは思います。
実行例 python scripts/code_reviewer.py code_diff.txt python scripts/code_reviewer.py
実装のイメージは以下のようになっています。実際には、もう少しGemma3の出力から対象行を特定したり、GitLabに投稿するような後処理をしています。
コードレビュースクリプト実装例
from unsloth import FastLanguageModelimport torchimport sysimport osdef load_fine_tuned_model (): """ファインチューニング済みモデルを読み込み""" model, tokenizer = FastLanguageModel.from_pretrained( model_name="fine_tuned_gemma3" , max_seq_length=2048 , dtype=None , load_in_4bit=True , ) FastLanguageModel.for_inference(model) return model, tokenizer def review_code (code_diff, model, tokenizer ): """コードの差分をレビューする""" prompt = f"""Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. ### Instruction: 以下のコード変更をレビューしてください。改善点があれば具体的に指摘してください。 ### Input: {code_diff} ### Response:""" inputs = tokenizer([prompt], return_tensors="pt" ).to("cuda" ) with torch.no_grad(): outputs = model.generate( **inputs, max_new_tokens=512 , temperature=0.7 , top_p=0.9 , do_sample=True , repetition_penalty=1.15 , ) response = tokenizer.decode(outputs[0 ], skip_special_tokens=True ) if "### Response:" in response: return response.split("### Response:" )[-1 ].strip() return response def review_from_gitlab_diff (): """GitLab CI環境でgit diffからレビューを実行""" print ("AI Code Review" ) import subprocess try : diff_output = subprocess.check_output( ["git" , "diff" , "HEAD~1" , "HEAD" ], text=True ) if not diff_output.strip(): print ("変更が検出されませんでした" ) return except subprocess.CalledProcessError: print ("エラー: git diffの取得に失敗しました" ) return model, tokenizer = load_fine_tuned_model() print ("レビューを生成中" ) review = review_code(diff_output, model, tokenizer) print ("【レビュー結果】" ) print ("-" * 50 ) print (review) print ("-" * 50 ) with open ("review_result.txt" , "w" , encoding="utf-8" ) as f: f.write(f"AI Code Review Result\n" ) f.write(f"{'=' * 50 } \n\n" ) f.write(review) def main (): if len (sys.argv) > 1 : diff_file = sys.argv[1 ] if not os.path.exists(diff_file): print (f"エラー: ファイルが見つかりません: {diff_file} " ) sys.exit(1 ) with open (diff_file, 'r' , encoding='utf-8' ) as f: code_diff = f.read() model, tokenizer = load_fine_tuned_model() review = review_code(code_diff, model, tokenizer) print ("AI Code Review" ) print (review) else : review_from_gitlab_diff() if __name__ == "__main__" : main()
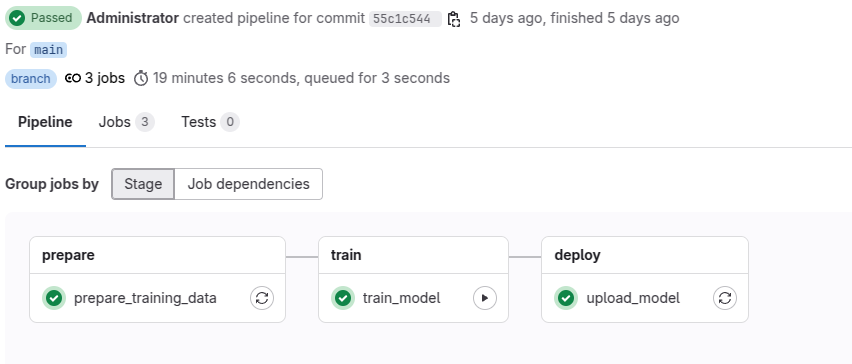
CI/CDパイプラインの構築 GitLab CI/CDパイプラインを使用して、データ収集からモデル学習、自動レビューまでの全工程を自動化します。パイプラインは5つのステージ、それぞれが独立して実行可能な形にしています。
パイプライン全体設計 パイプラインの各ステージと実行タイミングは以下です。
実装例は以下となります。
CI/CDパイプライン設定(.gitlab-ci.yml)
stages: - prepare - train - review - deploy variables: DOCKER_IMAGE: "nvidia/cuda:12.4.1-devel-ubuntu22.04" PIP_CACHE_DIR: "$CI_PROJECT_DIR/.cache/pip" cache: key: "$CI_JOB_NAME-$CI_COMMIT_REF_SLUG" paths: - .cache/pip - .cache/apt - ~/.cache/huggingface - /var/cache/apt/archives/*.deb policy: pull-push prepare_training_data: stage: prepare image: python:3.11 tags: [docker ] cache: key: "prepare-$CI_COMMIT_REF_SLUG" paths: - .cache/pip policy: pull-push script: - mkdir -p .cache/pip - pip3 install --cache-dir .cache/pip requests - python3 scripts/ci_collect_gitlab_data.py - python3 scripts/prepare_training_data.py artifacts: paths: - training_data/ expire_in: 1 day rules: - if: '$CI_COMMIT_BRANCH == "main"' train_model: stage: train image: nvidia/cuda:12.4.1-devel-ubuntu22.04 tags: [gpu , docker ] variables: NVIDIA_VISIBLE_DEVICES: all NVIDIA_DRIVER_CAPABILITIES: compute,utility PIP_CACHE_DIR: "$CI_PROJECT_DIR/.cache/pip" DOCKER_PULL_POLICY: "if-not-present" cache: paths: - .cache/pip - ~/.cache/huggingface before_script: - mkdir -p .cache/apt /var/cache/apt/archives - export DEBIAN_FRONTEND=noninteractive - apt-get update - apt-get install -y -o Dir::Cache::archives="/var/cache/apt/archives" python3 python3-pip git curl - mkdir -p .cache/pip ~/.cache/huggingface - pip3 install --upgrade --cache-dir .cache/pip pip - pip3 cache purge || true - pip3 install --cache-dir .cache/pip torch transformers==4.51.3 datasets trl accelerate peft bitsandbytes scipy sentencepiece protobuf requests - pip3 install --cache-dir .cache/pip unsloth unsloth-zoo script: - python3 scripts/train_gemma3.py - ls -la fine_tuned_gemma3/ artifacts: paths: - fine_tuned_gemma3/ expire_in: 7 days dependencies: - prepare_training_data needs: - job: prepare_training_data artifacts: true when: manual rules: - if: '$CI_COMMIT_BRANCH == "main"' - if: '$CI_PIPELINE_SOURCE == "schedule"' upload_model: stage: deploy image: python:3.11 script: - echo "学習済みモデルをパッケージレジストリにアップロード" - | # バージョン管理された学習済みモデルのアップロード MODEL_VERSION="$(date +%Y%m%d-%H%M%S)-${CI_COMMIT_SHORT_SHA}" echo "Model version: $MODEL_VERSION" tar -czf "fine_tuned_gemma3-${MODEL_VERSION}.tar.gz" fine_tuned_gemma3/ curl --header "JOB-TOKEN: $CI_JOB_TOKEN" \ --upload-file "fine_tuned_gemma3-${MODEL_VERSION}.tar.gz" \ "${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/packages/generic/gemma3-models/${MODEL_VERSION}/fine_tuned_gemma3-${MODEL_VERSION}.tar.gz" curl --header "JOB-TOKEN: $CI_JOB_TOKEN" \ --upload-file "fine_tuned_gemma3-${MODEL_VERSION}.tar.gz" \ "${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/packages/generic/gemma3-models/latest/fine_tuned_gemma3-latest.tar.gz" echo "Model uploaded as version: $MODEL_VERSION" echo "$MODEL_VERSION" > model_version.txt artifacts: paths: - model_version.txt expire_in: 30 days dependencies: - train_model needs: - job: train_model artifacts: true rules: - if: '$CI_COMMIT_BRANCH == "main"' when: on_success ai_code_review: stage: review image: nvidia/cuda:12.4.1-devel-ubuntu22.04 tags: [gpu , docker ] variables: NVIDIA_VISIBLE_DEVICES: all NVIDIA_DRIVER_CAPABILITIES: compute,utility PIP_CACHE_DIR: "$CI_PROJECT_DIR/.cache/pip" DOCKER_PULL_POLICY: "if-not-present" cache: key: "ai-review-$CI_COMMIT_REF_SLUG" paths: - .cache/pip - .cache/apt - ~/.cache/huggingface - /var/cache/apt/archives/*.deb policy: pull-push before_script: - mkdir -p .cache/apt .cache/pip ~/.cache/huggingface /var/cache/apt/archives - export DEBIAN_FRONTEND=noninteractive - apt-get update - apt-get install -y -o Dir::Cache::archives="/var/cache/apt/archives" python3 python3-pip git curl - pip3 install --upgrade --cache-dir .cache/pip pip - pip3 cache purge || true - pip3 install --cache-dir .cache/pip torch transformers==4.51.3 datasets trl accelerate peft bitsandbytes scipy sentencepiece protobuf requests - pip3 install --cache-dir .cache/pip unsloth unsloth-zoo - python3 --version - | # 学習済みモデルの確認・取得 if [ -d "fine_tuned_gemma3" ]; then echo "学習済みモデルが現在のディレクトリに存在します" MODEL_PATH="fine_tuned_gemma3" else echo "学習済みモデルが見つかりません。パッケージレジストリから取得を試みます" # パッケージレジストリから取得 if curl --fail --header "JOB-TOKEN: $CI_JOB_TOKEN" \ "${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/packages/generic/gemma3-models/latest/fine_tuned_gemma3-latest.tar.gz" \ -o fine_tuned_gemma3-latest.tar.gz; then tar -xzf fine_tuned_gemma3-latest.tar.gz MODEL_PATH="fine_tuned_gemma3" echo "パッケージレジストリからモデルを取得しました" else echo "学習済みモデルが見つかりません。train_model ジョブを先に実行してください。" exit 1 fi fi script: - | # デバッグモード設定 export AI_REVIEW_DEBUG=true if [ -n "$MODEL_PATH" ]; then python3 scripts/unified_ai_reviewer.py --debug --model $MODEL_PATH else python3 scripts/unified_ai_reviewer.py --debug fi ls -la *.txt *.json 2 >/dev/null || true artifacts: paths: - review_result.txt - review_result.json - debug_info.json - gemma3_output_failed.log when: always rules: - if: '$CI_PIPELINE_SOURCE == "merge_request_event"' when: manual allow_failure: true - if: '$CI_COMMIT_BRANCH == "feature/add-api-components-with-flaws"' when: manual allow_failure: true
実際にやってみる これでようやく一連の設定や実装が完了しました。
実際にやってみたときの流れをお見せしましょう。
学習データの準備としては、以下のようにPipelineを起動する形で実行していきます。
prepare_training_dataではGitLabからのデータ収集を行っています。ログを出力させると、以下のようになります。
無事リポジトリからデータが取得できています。
📊 GitLab APIデータ収集開始... Project ID: 2 🔍 ソースコード収集中... 📄 ソースコードファイル: 43件 📚 Wiki収集中... 📖 Wikiページ: 2件 💬 MRコメント収集中... 🔄 MR: 2件 ✅ データ収集完了! 📄 ソースコード: 43件 📚 Wiki: 2件 💬 MRコメント: 2件 🎯 学習データ: 46件 📁 出力ファイル: - training_data/gitlab_api_training_data.jsonl (学習用) - training_data/collection_stats.json (統計情報) 📁 training_data/gitlab_api_training_data.jsonl: 88,118 bytes 📁 training_data/collection_stats.json: 210 bytes ✅ GitLab APIから一部データの収集に成功しました === データ収集完了 ===
次のtrain_modelが本題、Gemma3のファインチューニングです。
実行ができると、以下のようなログが出力されていきます。
=== Gemma3 ファインチューニング開始 === GPU利用可能: NVIDIA GeForce RTX 3060 GPUメモリ: 11.75 GB モデルの読み込み中... Unsloth: WARNING `trust_remote_code` is True. Are you certain you want to do remote code execution? ==((====))== Unsloth 2025.5.7: Fast Gemma3 patching. Transformers: 4.51.3. \\ /| NVIDIA GeForce RTX 3060. Num GPUs = 1. Max memory: 11.747 GB. Platform: Linux. O^O/ \_/ \ Torch: 2.7.0+cu126. CUDA: 8.6. CUDA Toolkit: 12.6. Triton: 3.3.0 \ / Bfloat16 = TRUE. FA [Xformers = 0.0.30. FA2 = False] "-____-" Free license: http://github.com/unslothai/unsloth Unsloth: Fast downloading is enabled - ignore downloading bars which are red colored! Unsloth: Gemma3 does not support SDPA - switching to eager! 0%| | 0/10 [00:00<?, ?it/s]`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`. 100%|██████████| 10/10 [02:53<00:00, 17.32s/it]
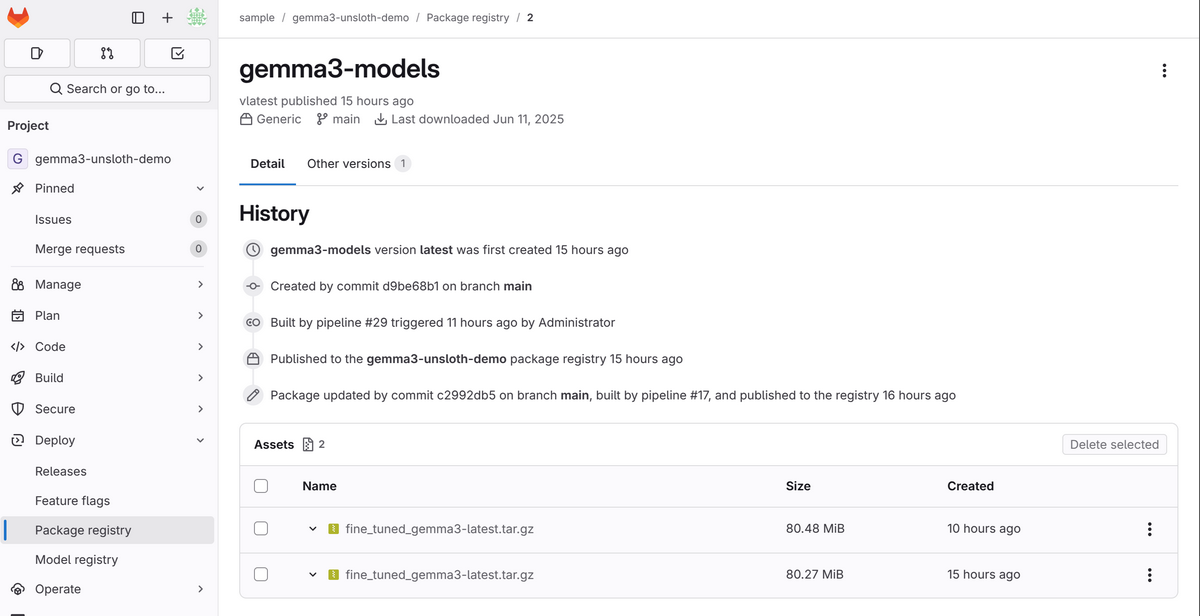
上記のジョブが完了し、upload_modelが実行されると、GitLabのPackageRegistryに以下のような形で配置がされます。
ここまででモデルの学習と配置は完了なので、あとはMRレビューなどでモデルを使用する形です。
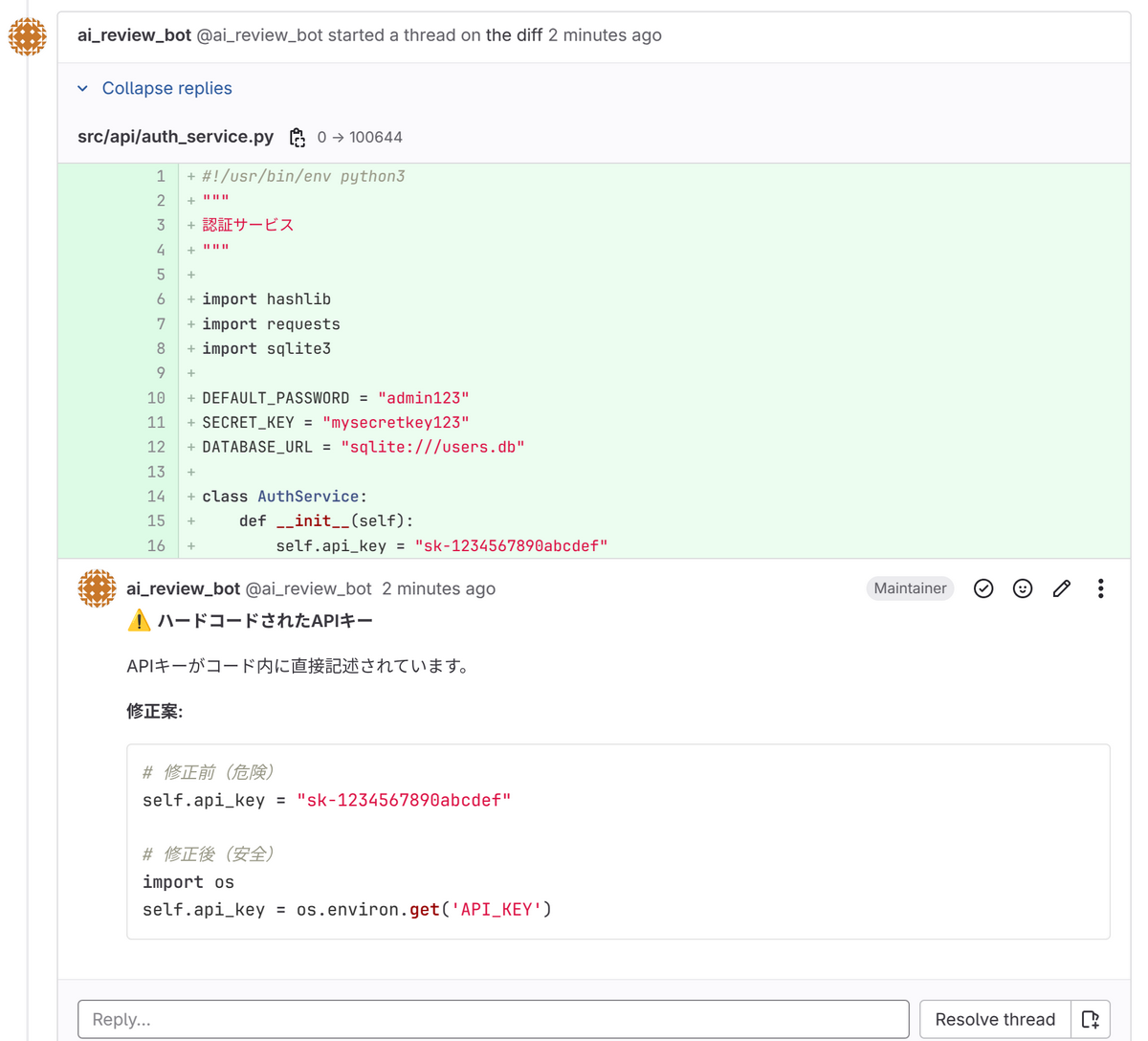
イメージとしては、このような形式でレビューコメントが投稿されます。
実際に動かしてみて分かったこと パフォーマンス 実際に動作確認してみた結果、以下のような数値が得られました。
今回はサンプルのプロジェクトで実行する形であったので、実用的にはより大規模なコードベースによって、時間がかかる可能性はあります。また、サンプルデータを十二分に用意できなかったので、追加学習の恩恵までを確認しきれていないのが正直なところです。
しかしながら、モデルの学習やアップロードなどは日次の夜間ジョブ、あるいは週次程度でも問題ないケースが多いと思うので、実際のプロジェクトのデータを利用して、段階的な導入が現実的なのではないかと感じました。
また、チューニングによってもまだまだ改善の余地があると感じています。
まとめ 本記事では、Gemma3 + Unsloth + GitLab CI/CDの組み合わせにより、外部依存なしで実用的なAIコードレビュー環境を構築してみました。
2025年の現在、オープンソースLLMの性能向上とファインチューニング技術の成熟により、セルフホストでのAI活用が現実的になってきています。セキュリティ要件が厳しい環境でも、適切な技術選定と段階的な導入により、AI活用の恩恵を受けることは十分可能ではないでしょうか。
同じような環境で働く方や、セルフホストAIに興味のある方の参考になれば幸いです。
技術の進歩は早いので、より良いアプローチがあれば積極的に取り入れていきたいと思います。
参考リンク