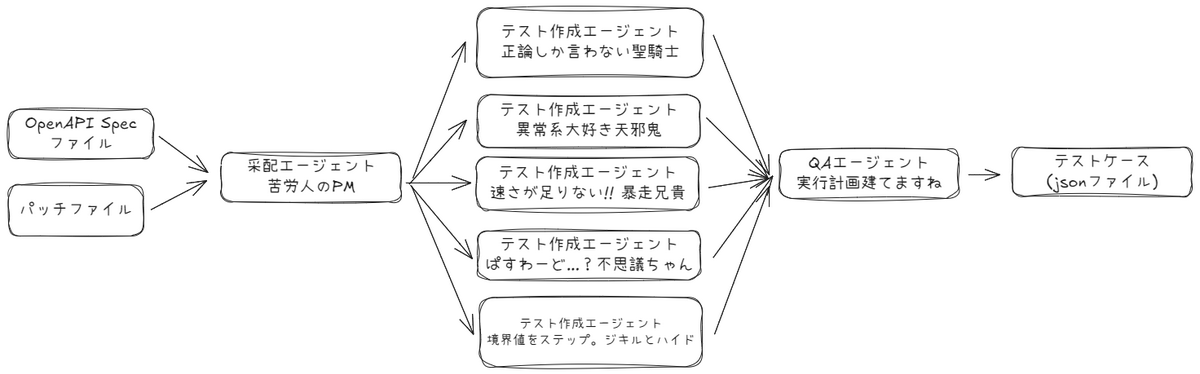
"""
オーケストレータ–ワーカー パターンのデモ:
1. 中央オーケストレータが動的にサブタスクを決定する
2. ワーカー LLM に動的タスクを委任する
3. 結果を統合して単一の最終結果を生成する
この処理では、
API Spec(OpenAPI YAML/JSON)及びパッチファイルを直接 input として渡すことで、
APIの実行テストケースを出力することができます。
"""
from pydantic import Field
from typing import List, Dict, Any, Optional, Union
from dapr_agents.types import UserMessage, AssistantMessage, ChatCompletion, AgentError
from dapr_agents.agent.patterns.toolcall.base import ToolCallAgent
import logging
import json
import asyncio
import dapr.ext.workflow as wf
from datetime import datetime
from typing import List, Dict, Any, Callable, Type
from enum import Enum
from dapr_agents.workflow import WorkflowApp, workflow, task
from dapr.ext.workflow import DaprWorkflowContext
from pydantic import BaseModel, Field, ConfigDict
from dotenv import load_dotenv
import yaml
from dapr_agents import tool, Agent
load_dotenv()
class StrictDict(BaseModel):
model_config = ConfigDict(extra="forbid")
class TestCase(BaseModel):
"""単一テストケースを表す。"""
name: str = Field(..., description="テストケース名")
description: str = Field(..., description="このテストケースで検証する内容")
method: str = Field(..., description="HTTP メソッド (GET, POST, など)")
endpoint: str = Field(..., description="テスト対象 API エンドポイント")
headers: StrictDict = Field(
default_factory=StrictDict, description="送信する HTTP ヘッダ")
body: StrictDict = Field(
default_factory=StrictDict, description="リクエストボディ (POST/PUT)")
expected_status: int = Field(..., description="期待 HTTP ステータスコード")
expected_response: StrictDict = Field(
default_factory=StrictDict, description="期待レスポンス構造/内容")
class TestPlan(BaseModel):
"""テストケース集合(プラン)"""
title: str
description: str
test_cases: List[TestCase]
class APITestScenarioBase(BaseModel):
"""統合した API テストシナリオ(メタデータなし)"""
api_name: str
api_description: str
test_summary: str
tests: List[TestCase]
execution_order: List[str]
class APITestScenario(APITestScenarioBase):
"""最終的な API テストシナリオ(メタデータ付き)"""
metadata: Dict[str, Any] = Field(
default_factory=dict, description="メタデータ(使用エージェント情報など)")
class AgentReasonPair(BaseModel):
"""エージェントとその選択理由のペア"""
agent_name: str = Field(..., description="エージェント名")
reason: str = Field(..., description="このエージェントを選択した理由")
class AgentSelection(BaseModel):
"""選択されたエージェントとその理由"""
agent_pairs: List[AgentReasonPair] = Field(
..., description="選択されたエージェントとその理由のリスト")
class TestAgent(Enum):
"""利用可能なテストエージェントの定義"""
SUNNY_PATH_PALADIN = "sunny_path_paladin_agent"
LATENCY_GREMLIN = "latency_gremlin_agent"
HEADER_HACKER = "header_hacker_agent"
PAYLOAD_JUGGLER = "payload_juggler_agent"
RATE_LIMIT_REBEL = "rate_limit_rebel_agent"
AUTH_AMNESIAC = "auth_amnesiac_agent"
CHAOS_CARTOGRAPHER = "chaos_cartographer_agent"
VERSION_TIME_TRAVELER = "version_time_traveler_agent"
CIRCUIT_BREAKER_BULLY = "circuit_breaker_bully_agent"
DATA_LEECH = "data_leech_agent"
CHAOS_CONDUCTOR = "chaos_conductor_agent"
AGENT_REGISTRY: Dict[TestAgent, Callable] = {}
class GetApiSpecSchema(BaseModel):
"""API仕様ファイル取得用のスキーマ"""
file_path: str = Field(description="読み込むAPI仕様ファイルのパス",
default="api_spec.yaml")
@tool(args_model=GetApiSpecSchema)
def get_api_spec(file_path: str = "api_spec.yaml") -> Dict[str, Any]:
"""
API仕様ファイル(OpenAPI YAML/JSON)を読み込んで返す。
Args:
file_path: API仕様ファイルのパス(デフォルト: api_spec.yaml)
Returns:
API仕様のディクショナリ形式
"""
try:
with open(file_path, "r", encoding="utf-8") as f:
if file_path.endswith(".yaml") or file_path.endswith(".yml"):
return yaml.safe_load(f)
elif file_path.endswith(".json"):
return json.load(f)
else:
raise ValueError(f"Unsupported file format: {file_path}")
except Exception as e:
logging.error(f"Failed to load API spec from {file_path}: {e}")
return {}
class GetDiffPatchSchema(BaseModel):
"""差分パッチファイル取得用のスキーマ"""
file_path: str = Field(description="読み込む差分パッチファイルのパス",
default="api_spec.patch")
@tool(args_model=GetDiffPatchSchema)
def get_diff_patch(file_path: str = "api_spec.patch") -> str:
"""
差分パッチファイルを読み込んで返す。
Args:
file_path: 差分パッチファイルのパス(デフォルト: api_spec.patch)
Returns:
差分パッチの内容(文字列)
"""
try:
with open(file_path, "r", encoding="utf-8") as f:
return f.read()
except Exception as e:
logging.error(f"Failed to load diff patch from {file_path}: {e}")
return ""
def get_agent_list_description() -> str:
"""エージェントリストの説明を生成"""
descriptions = {
TestAgent.LATENCY_GREMLIN: "レイテンシ注入/タイムアウト境界",
TestAgent.HEADER_HACKER: "ヘッダー改ざん・CORS/CSRF 系",
TestAgent.PAYLOAD_JUGGLER: "ボディ構造破壊・巨大/欠落/型不一致",
TestAgent.RATE_LIMIT_REBEL: "高負荷・スロットリング突破",
TestAgent.AUTH_AMNESIAC: "認証・認可エラー/トークン誤用",
TestAgent.CHAOS_CARTOGRAPHER: "パス・クエリ探索/ページネーション境界",
TestAgent.VERSION_TIME_TRAVELER: "前方・後方互換/バージョン切替",
TestAgent.CIRCUIT_BREAKER_BULLY: "依存サービス停止・フォールバック検証",
TestAgent.DATA_LEECH: "情報漏えい/PII チェック",
}
agent_list = []
for agent in TestAgent:
if agent != TestAgent.SUNNY_PATH_PALADIN and agent != TestAgent.CHAOS_CONDUCTOR:
desc = descriptions.get(agent, "")
agent_list.append(f"- {agent.value:<30} # {desc}")
return "\n".join(agent_list)
logger = logging.getLogger(__name__)
class StructuredToolCallAgent(ToolCallAgent):
"""
ツール呼び出しと構造化出力の両方をサポートするエージェント。
"""
response_format: Optional[Any] = Field(
default=None, description="構造化出力のためのPydanticモデル")
async def process_iterations(self, messages: List[Dict[str, Any]]) -> Any:
"""
構造化出力に対応したプロセス反復処理。
ツールと構造化出力の両方をサポート。
"""
for iteration in range(self.max_iterations):
logger.info(
f"Iteration {iteration + 1}/{self.max_iterations} started.")
messages += self.tool_history
try:
if self.tools and iteration < self.max_iterations - 1:
tool_params = {
"messages": messages,
"tools": self.tools,
"tool_choice": self.tool_choice,
}
response = self.llm.generate(**tool_params)
if isinstance(response, ChatCompletion):
response_message = response.get_message()
self.text_formatter.print_message(response_message)
if response.get_reason() == "tool_calls":
self.tool_history.append(response_message)
await self.process_response(response.get_tool_calls())
continue
if self.response_format:
structured_params = {
"messages": messages + self.tool_history,
"response_format": self.response_format,
"structured_mode": "json"
}
response = self.llm.generate(**structured_params)
if not isinstance(response, ChatCompletion):
return response
else:
content = response.get_content()
self.memory.add_message(AssistantMessage(content))
self.tool_history.clear()
return content
else:
params = {
"messages": messages,
"tools": self.tools if self.tools else None,
"tool_choice": self.tool_choice if self.tools else None,
}
params = {k: v for k, v in params.items() if v is not None}
response = self.llm.generate(**params)
response_message = response.get_message()
self.text_formatter.print_message(response_message)
if response.get_reason() == "tool_calls":
self.tool_history.append(response_message)
await self.process_response(response.get_tool_calls())
else:
content = response.get_content()
self.memory.add_message(AssistantMessage(content))
self.tool_history.clear()
return content
except Exception as e:
logger.error(f"Error during chat generation: {e}")
raise AgentError(f"Failed during chat generation: {e}") from e
if self.response_format:
try:
structured_params = {
"messages": messages + self.tool_history,
"response_format": self.response_format,
"structured_mode": "json"
}
response = self.llm.generate(**structured_params)
if not isinstance(response, ChatCompletion):
return response
else:
return response.get_content()
except Exception as e:
logger.error(f"Failed to generate structured output: {e}")
raise
logger.info("Max iterations reached. Agent has stopped.")
test_generator_agent = StructuredToolCallAgent(
response_format=TestPlan,
role="Test Case Generator",
verbose=True
)
patch_analyzer_agent = StructuredToolCallAgent(
response_format=AgentSelection,
role="API Patch Analysis Expert",
tools=[get_api_spec, get_diff_patch],
verbose=True
)
consolidate_agent = StructuredToolCallAgent(
response_format=APITestScenarioBase,
role="Test Scenario Consolidator",
verbose=True
)
_AGENT_LIST_DESC = get_agent_list_description()
@task(
agent=patch_analyzer_agent,
description=f"""
パッチアナライザーエージェント: OpenAPI仕様の差分パッチを詳細にCoTで分析し、どのテストエージェントを使用すべきか決定してください。
# 分析手順
1. diff_patchをapi_specに適用した後、どのエンドポイント・スキーマ・セキュリティ要件等がどのように変更されたかをstep-by-stepで一覧にしてください。
2. それぞれの変更点ごとに「どのテスト観点(正常系/異常系/認証/CRUD/エラー系など)」が影響を受けるかを具体的にリストアップしてください。
3. 利用可能なエージェント(下記リスト)の説明を参照し、各観点に最も適切なエージェントを理由付きで選定してください。
4. 各エージェントの選択理由は、「どの差分がどのテスト観点に影響し、なぜそのエージェントが必要か」を必ず明示してください。
5. 理由は英語で書いてください。
# 利用可能なエージェント
{_AGENT_LIST_DESC}
# ツール
- get_api_spec: OpenAPIの仕様書を全ファイル取得します
- get_diff_patch: OpenAPIのパッチファイルを取得します
# 重要な注意事項
- agent_name フィールドには、上記のリストにある正確なエージェント名(例: latency_gremlin_agent, header_hacker_agent など)を使用してください
- 他の名前(StaticAnalysisAgent、UnitTestAgent など)は使用しないでください
- 必ず上記リストから選択してください
""")
def analyze_patch_and_select_agents(api_name: str) -> AgentSelection:
pass
@workflow(name="api_test_workflow")
def api_test_workflow(ctx: DaprWorkflowContext, input_params: dict):
api_name = input_params.get("api_name")
api_description = input_params.get("api_description")
logging.info(f"\n=== WORKFLOW START: {api_name.upper()} のテスト生成 ===")
agent_selection_result = yield ctx.call_activity(
analyze_patch_and_select_agents,
input={
"api_name": api_name
}
)
if not isinstance(agent_selection_result, AgentSelection):
try:
agent_selection_result = AgentSelection(**agent_selection_result)
except Exception as e:
logging.error(f"Error converting agent selection result: {e}")
agent_selection_result = AgentSelection(agent_pairs=[
AgentReasonPair(agent_name=TestAgent.HEADER_HACKER.value,
reason="Error fallback selection"),
])
agent_pairs = agent_selection_result.agent_pairs
selected_agents = [pair.agent_name for pair in agent_pairs]
logging.info(f"選択されたエージェント: {selected_agents}")
for pair in agent_pairs:
logging.info(f" - {pair.agent_name}: {pair.reason}")
agent_tasks = []
used_agents_final = []
agent_tasks.append(
ctx.call_activity(sunny_path_paladin_tests,
input={"api_name": api_name, "api_description": api_description})
)
used_agents_final.append(TestAgent.SUNNY_PATH_PALADIN.value)
agent_name_map = {agent.value: agent for agent in TestAgent}
for agent_name in selected_agents:
if agent_name in agent_name_map:
agent_enum = agent_name_map[agent_name]
if agent_enum in AGENT_REGISTRY and agent_enum != TestAgent.SUNNY_PATH_PALADIN:
agent_func = AGENT_REGISTRY[agent_enum]
agent_tasks.append(
ctx.call_activity(agent_func,
input={"api_name": api_name, "api_description": api_description})
)
used_agents_final.append(agent_name)
logging.info("テスト生成エージェントを待機中...")
test_plans = yield wf.when_all(agent_tasks)
logging.info("すべてのテストプラン生成完了")
final_scenario = yield ctx.call_activity(agent_a_consolidate_tests,
input={
"api_name": api_name,
"api_description": api_description,
"test_plans": test_plans,
"used_agents": used_agents_final,
"agent_selection_reasons": {pair.agent_name: pair.reason for pair in agent_pairs}
})
if hasattr(final_scenario, "dict"):
scenario_dict = final_scenario.dict()
else:
scenario_dict = final_scenario
metadata_info = {
"used_agents": used_agents_final,
"agent_selection_reasons": {pair.agent_name: pair.reason for pair in agent_pairs},
"generated_at": datetime.now().isoformat(),
"workflow_type": "api_test_workflow"
}
scenario_dict["metadata"] = metadata_info
final_scenario_with_metadata = APITestScenario(**scenario_dict)
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
output_filename = f"test_scenario_{api_name.replace(' ', '_')}_{timestamp}.json"
try:
with open(output_filename, "w", encoding="utf-8") as f:
if hasattr(final_scenario_with_metadata, "model_dump"):
scenario_dict = final_scenario_with_metadata.model_dump()
elif hasattr(final_scenario_with_metadata, "dict"):
scenario_dict = final_scenario_with_metadata.dict()
else:
scenario_dict = final_scenario_with_metadata
json.dump(scenario_dict, f, ensure_ascii=False, indent=2)
logging.info(f"テストシナリオを保存しました: {output_filename}")
except Exception as e:
logging.error(f"ファイル保存エラー: {e}")
logging.info("=== WORKFLOW 完了 ===")
return final_scenario_with_metadata
@task(
agent=test_generator_agent,
description="""
🛡 **Sunny Path Paladin**: {api_name} の王道正常系テストを生成します。
API説明: {api_description}
テスト観点
• 有効な入力と期待出力
• CRUD 正常動作
• 認証フロー正常シナリオ
• ビジネスロジックの必須ハッピーケース
# ツール
- get_api_spec: OpenAPIの仕様書を全ファイル取得します
- get_diff_patch: OpenAPIのパッチファイルを取得します
""")
def sunny_path_paladin_tests(api_name: str,
api_description: str) -> TestPlan:
pass
@task(
agent=test_generator_agent,
description="""
🦥 **Latency Gremlin**: {api_name} のレスポンス遅延耐性を調べます。
API説明: {api_description}
テスト観点
• ランダム遅延 (10 ms–10 s) 注入
• 階段状に遅延を増幅させる(パーセンタイル別)
• クライアント側 / サーバ側タイムアウト境界の特定
• Keep‑Alive/コネクションプールの影響
# ツール
- get_api_spec: OpenAPIの仕様書を全ファイル取得します
- get_diff_patch: OpenAPIのパッチファイルを取得します
""")
def latency_gremlin_tests(api_name: str,
api_description: str) -> TestPlan:
pass
@task(
agent=test_generator_agent,
description="""
🛠 **Header Hacker**: {api_name} へあらゆるヘッダー改ざんを行います。
API説明: {api_description}
テスト観点
• Content‑Type / Accept をランダム化・矛盾させる
• Authorization 欄を欠落/破損/サイズ膨張させる
• 重複ヘッダー・大文字小文字揺らぎ・CRLF インジェクション
• 不正 CORS ヘッダーでブラウザ経由 CSRF を再現
# ツール
- get_api_spec: OpenAPIの仕様書を全ファイル取得します
- get_diff_patch: OpenAPIのパッチファイルを取得します
""")
def header_hacker_tests(api_name: str,
api_description: str) -> TestPlan:
pass
@task(
agent=test_generator_agent,
description="""
🎪 **Payload Juggler**: {api_name} のボディ構造を撹乱します。
API説明: {api_description}
テスト観点
• 必須フィールド欠落・追加フィールド混入
• 極端なサイズ(0 B/10 MB 以上)の JSON・XML
• 型不一致(数値↔文字列、配列↔オブジェクト)
• Base64/gzip/multipart など異種エンコード
# ツール
- get_api_spec: OpenAPIの仕様書を全ファイル取得します
- get_diff_patch: OpenAPIのパッチファイルを取得します
""")
def payload_juggler_tests(api_name: str,
api_description: str) -> TestPlan:
pass
@task(
agent=test_generator_agent,
description="""
🚀 **Rate‑Limit Rebel**: {api_name} のスロットリング境界を突破します。
API説明: {api_description}
テスト観点
• RPS バースト (10→1000) と持続高負荷
• ユーザ別/IP 別/トークン別に同時攻撃
• HTTP 429 と Retry‑After の整合性
• グローバル制限と per‑method 制限の相互作用
# ツール
- get_api_spec: OpenAPIの仕様書を全ファイル取得します
- get_diff_patch: OpenAPIのパッチファイルを取得します
""")
def rate_limit_rebel_tests(api_name: str,
api_description: str) -> TestPlan:
pass
@task(
agent=test_generator_agent,
description="""
🔑 **Auth Amnesiac**: {api_name} の認証・認可を忘れっぽくテストします。
API説明: {api_description}
テスト観点
• 有効期限切れ/偽造/スコープ不足のトークン
• refresh token 連打によるセッション固定
• 認証方式切替 (JWT ↔ Basic ↔ mTLS) の誤用
• 多段プロキシ時の X‑Forwarded-* 改ざん
# ツール
- get_api_spec: OpenAPIの仕様書を全ファイル取得します
- get_diff_patch: OpenAPIのパッチファイルを取得します
""")
def auth_amnesiac_tests(api_name: str,
api_description: str) -> TestPlan:
pass
@task(
agent=test_generator_agent,
description="""
🗺 **Chaos Cartographer**: {api_name} のパス・クエリ空間を探索します。
API説明: {api_description}
テスト観点
• スキーマ外エンドポイントを合成し 404/405 を収集
• ページネーション (limit, offset, cursor) 境界値および空ページ
• 組合せ爆発 (path param × query × header) で振る舞い差分を計測
• 空リスト・最終ページ・高速スクロール時の一貫性
# ツール
- get_api_spec: OpenAPIの仕様書を全ファイル取得します
- get_diff_patch: OpenAPIのパッチファイルを取得します
""")
def chaos_cartographer_tests(api_name: str,
api_description: str) -> TestPlan:
pass
@task(
agent=test_generator_agent,
description="""
⏲ **Version Time‑Traveler**: {api_name} の前方・後方互換を検証します。
API説明: {api_description}
テスト観点
• Accept‑Version / X‑API‑Version を旧版・未来版に切替
• Deprecation Header や Sunset Policy の遵守
• スキーマ移行中フィールドの default/nullable 挙動
• β/preview タグ付きエンドポイントの安定性
# ツール
- get_api_spec: OpenAPIの仕様書を全ファイル取得します
- get_diff_patch: OpenAPIのパッチファイルを取得します
""")
def version_time_traveler_tests(api_name: str,
api_description: str) -> TestPlan:
pass
@task(
agent=test_generator_agent,
description="""
⚡ **Circuit‑Breaker Bully**: {api_name} が依存する外部サービスを疑似停止させます。
API説明: {api_description}
テスト観点
• DB/メッセージブローカ/3rd‑party API のダウンを模倣
• 半開→再閉ループ時のフォールバック挙動
• スロースタート・ヒステリシス(感度調整)設定値の検証
• フェイルファスト vs 再試行バックオフを比較
# ツール
- get_api_spec: OpenAPIの仕様書を全ファイル取得します
- get_diff_patch: OpenAPIのパッチファイルを取得します
""")
def circuit_breaker_bully_tests(api_name: str,
api_description: str) -> TestPlan:
pass
@task(
agent=test_generator_agent,
description="""
🩸 **Data Leech**: {api_name} からの情報漏えいを吸い上げます。
API説明: {api_description}
テスト観点
• 詳細エラー/スタックトレースに PII が混入しないか
• クエリ文字列/ログ/メトリクスの不適切なマスキング
• GraphQL↔REST/Batch API 周りでの over‑fetch / under‑fetch
• JSON スキーマ違反での fallback 値に秘密情報が漏れないか
# ツール
- get_api_spec: OpenAPIの仕様書を全ファイル取得します
- get_diff_patch: OpenAPIのパッチファイルを取得します
""")
def data_leech_tests(api_name: str,
api_description: str) -> TestPlan:
pass
@task(
agent=test_generator_agent,
description="""
🎻 **Chaos Conductor**: 上記エージェントをオーケストレーションし複合障害を生成します。
API説明: {api_description}
テスト観点
• 遅延+ヘッダ改ざん+高負荷など同時多発障害
• 時系列シナリオ (障害→回復→再障害) を生成
• SLO 逸脱率をメトリクス化し JSON レポートへ整形
# ツール
- get_api_spec: OpenAPIの仕様書を全ファイル取得します
- get_diff_patch: OpenAPIのパッチファイルを取得します
""")
def chaos_conductor_plan(api_name: str,
api_description: str) -> TestPlan:
pass
@task(
agent=consolidate_agent,
description="""
リードエージェント: 複数のテストプランを統合し、実行順序を含む包括的な
API テストシナリオを作成してください ({api_name})。
API説明: {api_description}
手順:
1. 重複テストを排除
2. 認証 → CRUD → エラー の順で並べ替え
3. 重要エンドポイントが抜けていないか確認
# 統合するテストプラン
{test_plans}
# 注意事項
- used_agents: {used_agents} (メタデータ用、統合処理では使用しない)
- agent_selection_reasons: {agent_selection_reasons} (メタデータ用、統合処理では使用しない)
""")
def agent_a_consolidate_tests(api_name: str, api_description: str,
test_plans: List[TestPlan],
used_agents: List[str] = None,
agent_selection_reasons: Dict[str, str] = None) -> APITestScenarioBase:
pass
AGENT_REGISTRY.update({
TestAgent.SUNNY_PATH_PALADIN: sunny_path_paladin_tests,
TestAgent.LATENCY_GREMLIN: latency_gremlin_tests,
TestAgent.HEADER_HACKER: header_hacker_tests,
TestAgent.PAYLOAD_JUGGLER: payload_juggler_tests,
TestAgent.RATE_LIMIT_REBEL: rate_limit_rebel_tests,
TestAgent.AUTH_AMNESIAC: auth_amnesiac_tests,
TestAgent.CHAOS_CARTOGRAPHER: chaos_cartographer_tests,
TestAgent.VERSION_TIME_TRAVELER: version_time_traveler_tests,
TestAgent.CIRCUIT_BREAKER_BULLY: circuit_breaker_bully_tests,
TestAgent.DATA_LEECH: data_leech_tests,
TestAgent.CHAOS_CONDUCTOR: chaos_conductor_plan,
})
async def main():
load_dotenv()
logging.basicConfig(level=logging.INFO)
wfapp = WorkflowApp(timeout=600)
with open("api_spec.yaml", encoding="utf-8") as fp:
api_spec = yaml.safe_load(fp)
api_name = api_spec["info"]["title"]
api_desc = api_spec["info"].get("description", "")
print("\n=== API TEST WORKFLOW デモ ===")
print(f"対象 API: {api_name}")
print("ステップ:")
print(" 1. Diffパッチ分析 (Agent クラス使用)")
print(" 2. 動的エージェント選択")
print(" 3. 選択されたエージェントによる追加テスト生成")
print(" 4. 統合 & 実行順序決定")
result = await wfapp.run_and_monitor_workflow_async(
api_test_workflow,
input={
"api_name": api_name,
"api_description": api_desc
}
)
if result:
print("\n=== 最終テストシナリオ ===")
if hasattr(result, "dict"):
scenario_dict = result.dict()
else:
scenario_dict = result
formatted_json = json.dumps(
scenario_dict, ensure_ascii=False, indent=2)
print(formatted_json)
print("\n=== ワークフロー完了 ===")
import sys
sys.exit(0)
if __name__ == "__main__":
asyncio.run(main())
|