夏の自由研究2025ブログ連載の1日目です。
初めまして、コアテクノロジーグループに所属している二宮と申します。
私たちのチームでは普段Grafanaを利用していますが、Grafana Alloyはまだ使ったことがありませんでした。当初は、promtailの後継ツールとしての利用のみを考えていただけでしたが、ドキュメントを読み進める内にAlloyを使えばテレメトリデータの活用方法がさらに広がるのでは…? と感じました。
そこで今回は、Alloyの豊富な機能の一部を利用してEKSクラスタ外部のサーバ監視に挑戦してみました。本記事では、その設定手順や使ってみて分かったポイントを、初めてAlloyに触れた目線でご紹介します。
1. Grafana Alloyとは
Grafana Alloyは、Grafana Labsが開発するOSSのテレメトリ収集エージェントです。
メトリクス・ログ・トレース・プロファイルをこれ1つで統合的に扱うことができます。Grafana Agentの正式な後継製品であり、Promtailが担っていたログ収集機能もAlloyに統合されています。OpenTelemetryをベースに作られているため、柔軟で強力なデータパイプラインを構築できるのが特徴です。
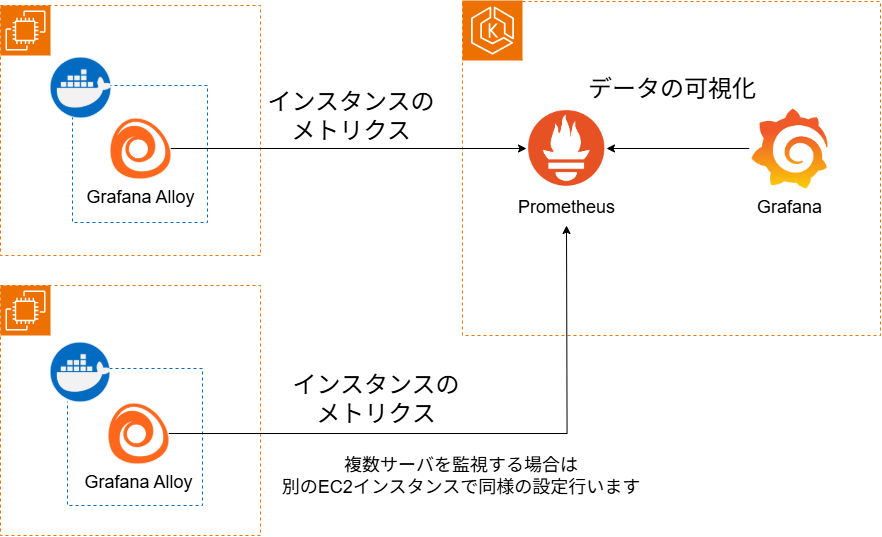
2. 構成説明
EKSクラスタ: メトリクスの管理先となるPrometheusと、可視化ツールであるGrafanaをすでに構築済みです
EC2インスタンス: 監視対象であるEKSクラスタ外部のサーバです。このサーバ上にGrafana Alloyをコンテナとして構築します
- EC2インスタンスの準備: Alloyをコンテナとして動かすため、監視対象のEC2インスタンスにはDockerおよびDocker Composeを事前にインストールしています。
通信経路の確保: 本記事では詳細を割愛しますが、AlloyからPrometheusへデータを送信できるよう、事前にセキュリティグループを設定します。
本記事作成時の環境: 今回の検証で使用した、主なソフトウェアの構成は以下の通りです
ツール バージョン Grafana 12.0.0 Grafana Alloy 1.8.3 Prometheus 3.4.1
3. 今回の検証で利用するAlloyコンポーネントの概要
本記事の中では以下のコンポーネントを利用しています。
実際の利用方法と記載内容は後述します。
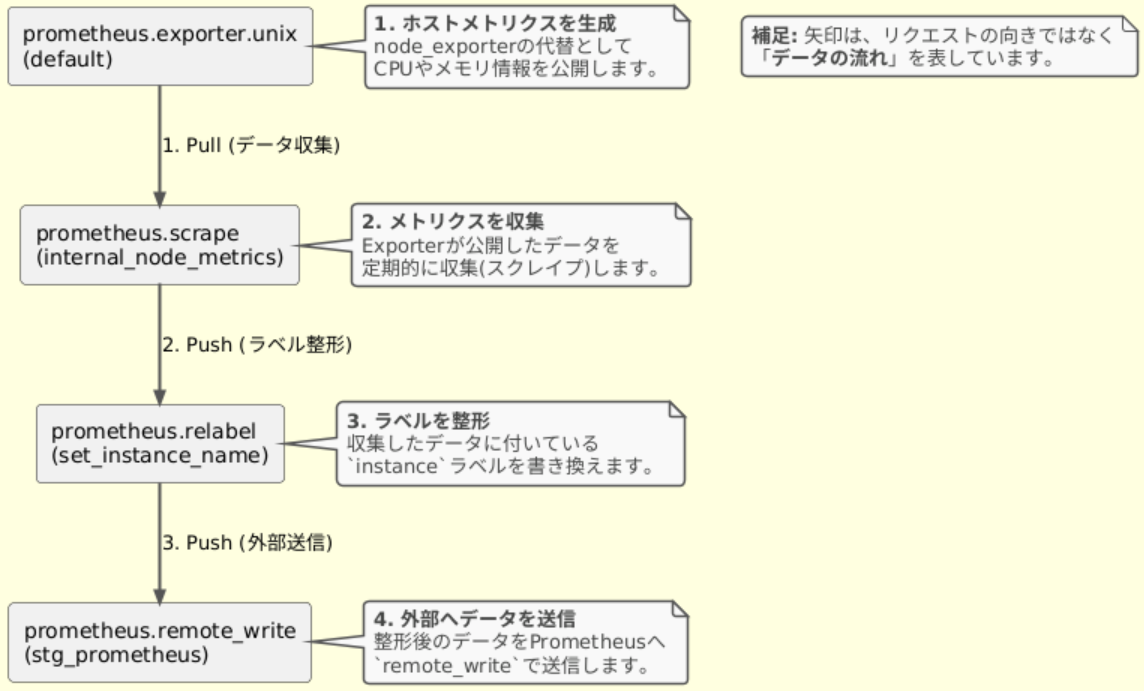
- prometheus.export.unix
メトリクスを生成します。
このコンポーネントを利用することで、別途node_exporterをインストールしなくても、CPU、メモリ、ディスクスペース、ディスクI/O、ネットワークなどUNIXシステムのメトリクスを公開できます。 - prometheus.scrape
exporterが公開したメトリクスを定期的に収集(スクレイプ)します。
指定されたtargetsのHTTPエンドポイントにアクセスしてデータを取得します。
収集したメトリクスは、forward_toで指定された次のコンポーネントに渡されます。 - prometheus.relabel
Prometheus形式のメトリクスが持つラベルを、動的なルールに基づいて書き換え・追加・削除します。
正規表現を使ったラベルの生成や、不要なメタデータラベルの削除など、メトリクスの整形・加工を担います。 - prometheus.remote_write
収集・加工したメトリクスを、最終的な保存先であるPrometheus互換のバックエンドに送信します。
Prometheus Remote Writeプロトコルを使って、設定されたendpointのURLにデータをまとめて送信します。
今回、送信先はPrometheusにしていますが、Grafana MimirやGrafana Cloudなども指定可能です。
送信先のエンドポイントURLはIngressやNodePortまたはTargetGroupBinding等で設定したものを指定します。
4. 設定方法
4-1. コンポーネント同士の連携方法
Grafana Alloyではconfig.alloyという設定ファイルで、機能単位である「コンポーネント」を繋ぎ合わせ、テレメトリデータの取得ができます。
設定ファイルは、Grafana agentの設定言語であるriver言語をベースに記述され、宣言的に記述できるという特徴があります。
この連携には、データを次のコンポーネントに押し出すPush方式と、他のコンポーネントからデータを引き出すPull方式があります。
Push方式は、Alloy内部にてコンポーネント間でデータを渡す仕組みで、forward_to引数で出力先を指定し、データを受け取る側のコンポーネントはreceiverという入力口を持っています。Pull方式も、Alloy内部でコンポーネントが連携するための仕組みで、targets引数で入力元を指定します。データを提供する側のコンポーネントはtargetsという監視対象リストを公開しています。
他のコンポーネントを参照する際は、<コンポーネント種別>.<コンポーネント名>.<公開名>の形式で記述します。
- コンポーネント種別 : prometheus.scrapeやprometheus.exporter.unixなど
- コンポーネント名 : “internal_node_metrics”や”set_instance_name”など、自分で付けた名前
- 公開名 : receiverやtargetsなど、各コンポーネントが公開している名前
4-2. config.alloy
config.alloyの設定です。
// Node Exporter相当の機能をAlloy内部で提供 |
この設定によって構築される、メトリクスデータのパイプラインを図にすると以下のようになります。
4-3. その他のファイル、ディレクトリ構成
作成したconfig.alloyを読み込み、Alloyコンテナを起動するため、compose.ymlは以下のように記載しています。
services: |
- /data配下のディレクトリ構成
AlloyのWAL(Write-Ahead Log)機能によるデータ永続化のため、compose.ymlでホストOSのディレクトリマウントを行っています。
送信先のPrometheusがダウンしていても、Alloyは未送信のメトリクスをこのWALに一時的に保存します。
コンテナを再起動してもデータが消えないようにホストOSに保存し、メトリクスの損失を防ぎます。
マウント先のディレクトリまで作成後、ディレクトリ配下に作成されるファイルやディレクトリは、Alloyが自動で作成・削除します。
/data/app/grafana_alloy/ |
- Prometheus側の設定
Grafana Alloyからデータを受け取るには、送信先であるPrometheus側でremote-writeリクエストを有効にする必要があります。
今回、Prometheusはkube-prometheus-stackのHelm Chartを利用しているので、values.yamlを編集してこの設定を有効にしています。values.yamlの設定方法
values.yamlで--web.enable-remote-write-receiverという起動オプションを追記する必要があります。containers:
- name: prometheus
args:
# 下の行を追記
- "--web.enable-remote-write-receiver"この設定を追記し反映させることで、PrometheusがAlloyからのデータを受け付けられるようになりました。
5. Grafana上からダッシュボードを用いたメトリクス可視化
ダッシュボードにはGrafana Labsから提供されているNode Exporter Full を利用します。
上記URLからJSONをダウンロードして、Grafana上のDashdoardsを選択し、Import dashboardでJSONをアップロードしダッシュボードを作成します。
5-1. Variables(変数)の設定
GrafanaのVariablesを設定し、監視対象のサーバをドロップダウンで選択できるようにします。
- ダッシュボード右上の
editをクリックし、Settingsを選択します。 - Variablesタブに移動してnodeを選択します
- Label filtersに設定されているラベルを削除して、Label filtersに
cluster = externalを設定 - 画面下のRun Queryを押して対象のサーバが表示されたら、
Save dashboardから保存します。
5-2. 主なダッシュボードパネル
「Node Exporter Full」ダッシュボードには多くの情報が表示されますが、一部パネルについてご紹介します。
- CPU Basic: CPUの基本的な使用率をuser,system,iowaitなどのモード別に表示し、サーバの負荷状況を確認できます
- Memory Basic: システム全体のメモリ使用量、空き容量、バッファやキャッシュとして利用されている量が表示され、メモリ不足の兆候を把握できます
- ディスク Space Used Basic: ディスクごとの使用率(%)を確認できます
- Network Traffic Basic
ネットワークインタフェースごとの送受信トラフィック(MB/s)を表示し、通信量の急増や異常を検知できます。
インポートしたダッシュボードは自由にカスタマイズが可能なので、必要に応じてパネルの追加や削除ができます。
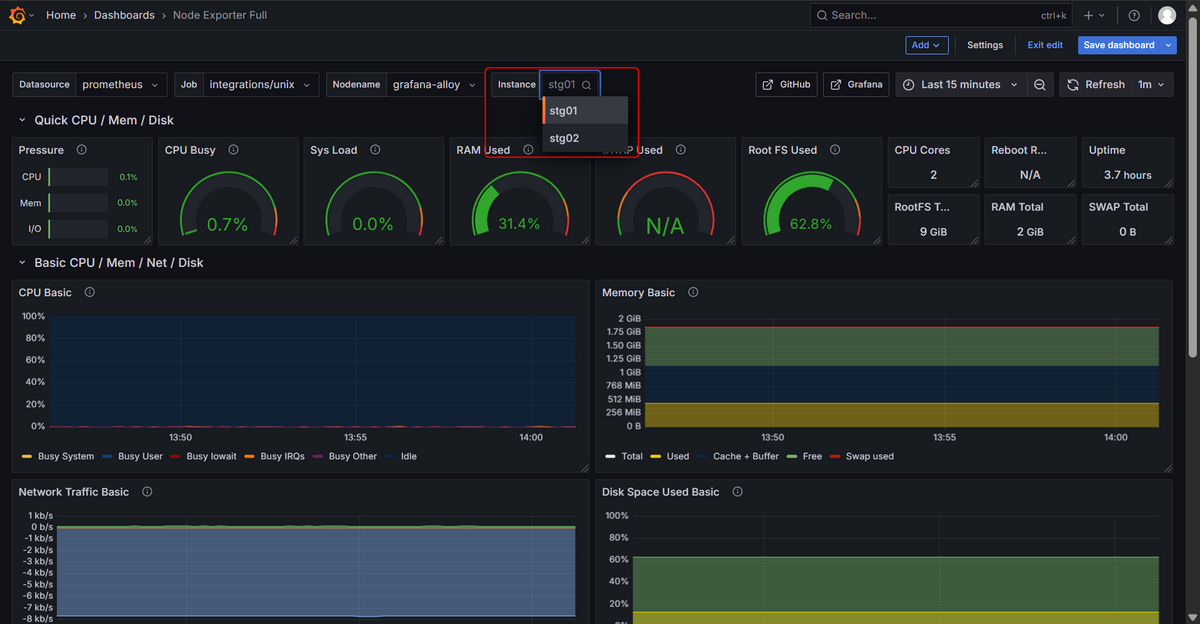
5-3. 複数サーバの監視
4. 設定方法に記載した設定のサーバを複数台構築した場合、instanceを切り替えることで監視対象サーバを切り替えることができます。
5-4. 監視設定
今回はメトリクスの可視化までを行いましたが、収集したメトリクスを元に閾値を設定し、アラート設定も可能です。
アラートの通知先として、Slackやメール等、様々なツールを指定できるため、システムの異常を迅速に検知する体制を構築できます。
6. まとめ
Grafana Alloyの機能の一部である、メトリクスの収集・送信設定を行い、複数サーバの監視にも対応できるダッシュボードを作成しました。
コンポーネントの記載方法は少し独特ですが、慣れたらパズルのように組み合わせて直感的に設定できそうと感じました。Alloyはメトリクス以外にもログ、トレース、プロファイルも収集できます。
今後はこれらの機能も試し、Grafanaを利用したデータ利活用をさらに広げていきたいです。